AI technology has permeated every aspect of our lives. The growing dependency is eroding our control. Sovereign AI has become crucial, rather than optional. The challenge posed by Gradient demonstrates whether we can achieve true AI independence.
Key Points
- Gradient connects global idle computing resources into a distributed network. This challenges the AI industry structure dominated by a few large tech companies.
- The open intelligence stack allows anyone to train and run large language models without their own infrastructure.
- Team members include researchers from the University of California, Berkeley, the Hong Kong University of Science and Technology, and ETH Zurich. They collaborate with Google DeepMind and Meta to drive continuous progress.
1. Dependency Trap: The Risks Behind AI Convenience
Now anyone can prototype by conversing with large language models or generate images without design experience.
However, this capability could disappear at any moment. We do not fully own or control it. A few large companies (OpenAI, Anthropic, etc.) provide the infrastructure that most services rely on. We depend on their systems.
Imagine what would happen if these companies revoked access to large language models. Server outages could halt services. Companies might block specific regions or users for various reasons. Price increases could push individuals and small businesses out of the market.

Source: Tiger Research
When this happens, the "all-powerful" capability instantly turns into "powerless" helplessness. The growing dependency amplifies this risk.

Source: Varun Mohan, Co-founder and CEO, Windsurf
This risk already exists. In 2025, after news of a competitor's acquisition, Anthropic blocked access to the Claude API for the AI coding startup Windsurf without notice. This incident limited model access for some users and forced the company to undertake emergency infrastructure restructuring. The decision of one company immediately impacted the service operations of another.
This may seem to only affect some companies like Windsurf today. As dependency grows, everyone will face this issue.
2. Gradient: Unlocking the Future with Open Intelligence

Source: Gradient
Gradient addresses this issue. The solution is simple: provide an environment where anyone can develop and run large language models in a decentralized manner, free from the control of a few companies like OpenAI or Anthropic.
How does Gradient achieve this? Understanding how large language models work can clarify this. Training creates large language models, while inference runs them.
Training: The phase of creating AI models. The model analyzes vast datasets to learn patterns and rules, such as which words might follow others and which answers fit which questions.
Inference: The phase of using the trained model. The model receives user questions and generates the most likely responses based on learned patterns. When you chat with ChatGPT or Claude, you are engaging in inference.
Both phases require enormous costs and computing resources.
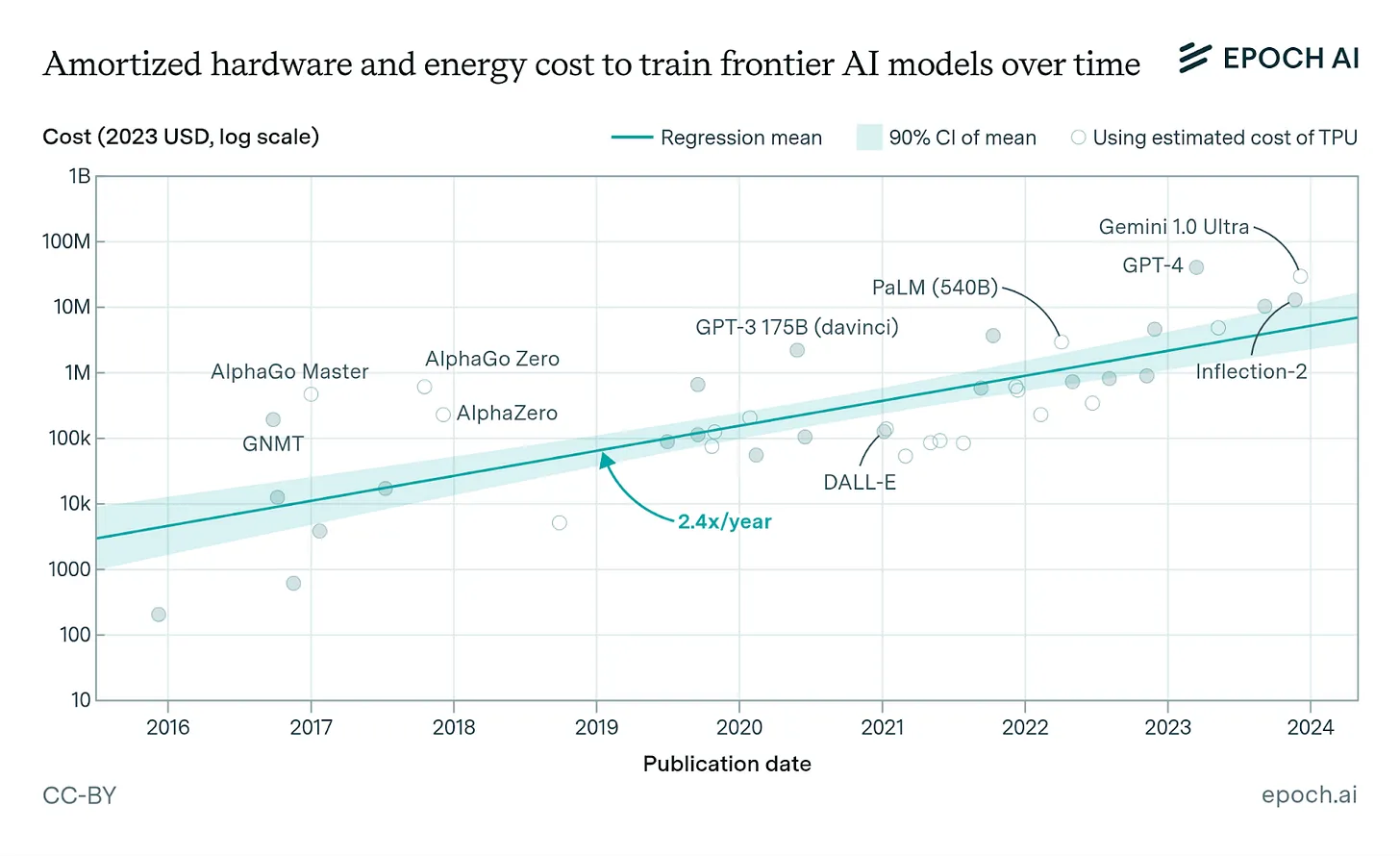
Source: Epoch.ai
Training GPT-4 alone is estimated to have cost over $40 million and required tens of thousands of GPUs running for months. Inference also requires high-performance GPUs to generate each response. These high-cost barriers force the AI industry to consolidate around capital-rich large tech companies.
Gradient addresses this issue differently. While large tech companies build massive data centers with tens of thousands of high-performance GPUs, Gradient connects global idle computing resources into a distributed network. Home computers, idle office servers, and lab GPUs operate as a massive cluster.
This enables individuals and small businesses to train and run large language models without their own infrastructure. Ultimately, Gradient achieves open intelligence: AI as a technology open to everyone, rather than an exclusive domain for a few.
3. Three Core Technologies for Achieving Open Intelligence
Gradient's open intelligence sounds appealing, but implementing it is complex. Global computing resources vary in performance and specifications. The system must reliably connect and coordinate them.
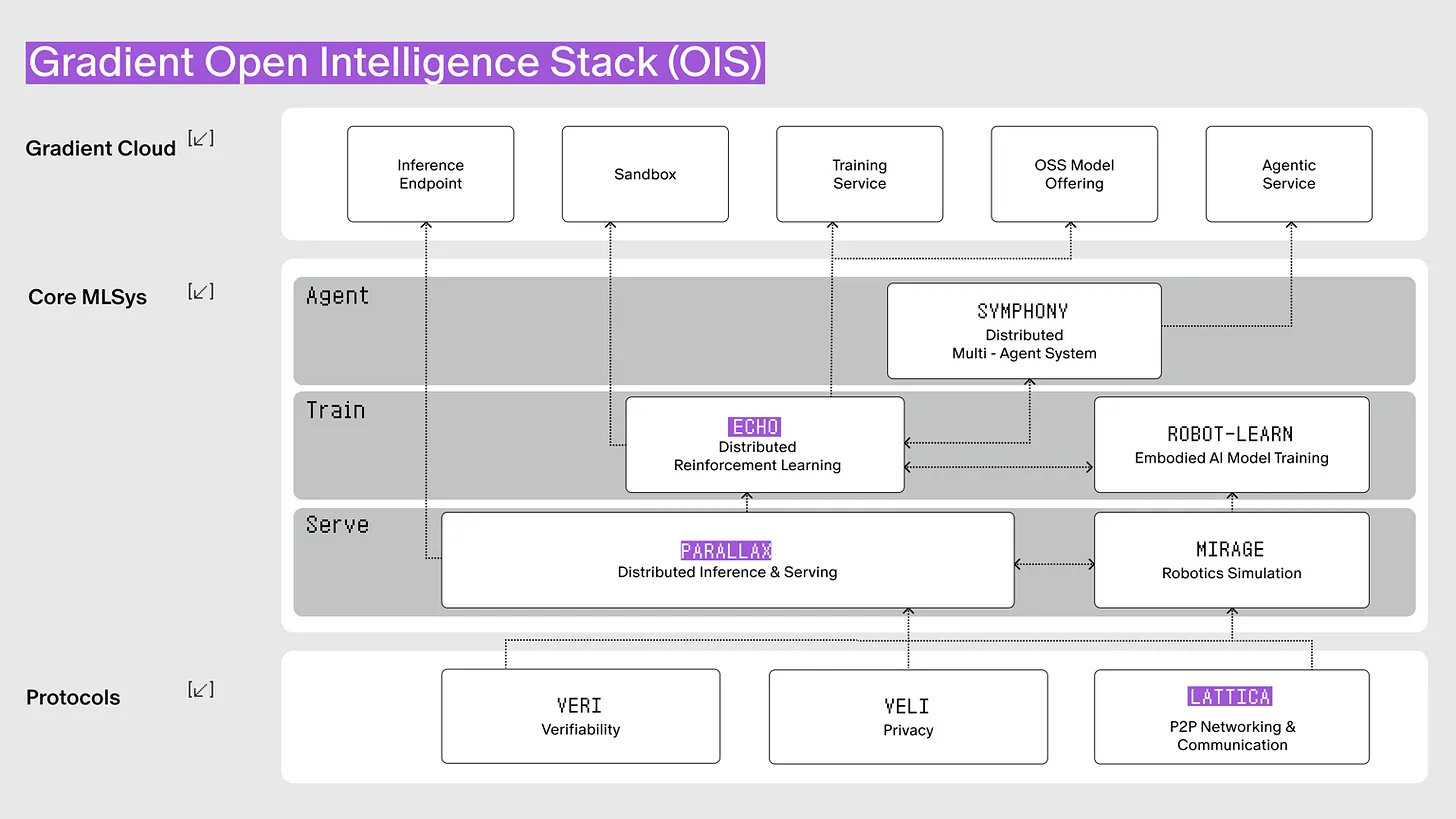
Source: Gradient
Gradient solves this problem with three core technologies. Lattica establishes a communication network in a distributed environment. Parallax handles inference within this network. Echo trains models through reinforcement learning. These three technologies are organically connected, forming the open intelligence stack.
3.1. Lattica: P2P Data Communication Protocol
Central servers connect typical internet services. Even when we use messaging apps, central servers forward our communications. A distributed network operates differently: each computer connects and communicates directly without a central server.
Most computers block direct connections and prevent external access. Routers route home internet connections, preventing external sources from directly locating individual computers. Finding a specific apartment unit using only the building address illustrates this challenge.
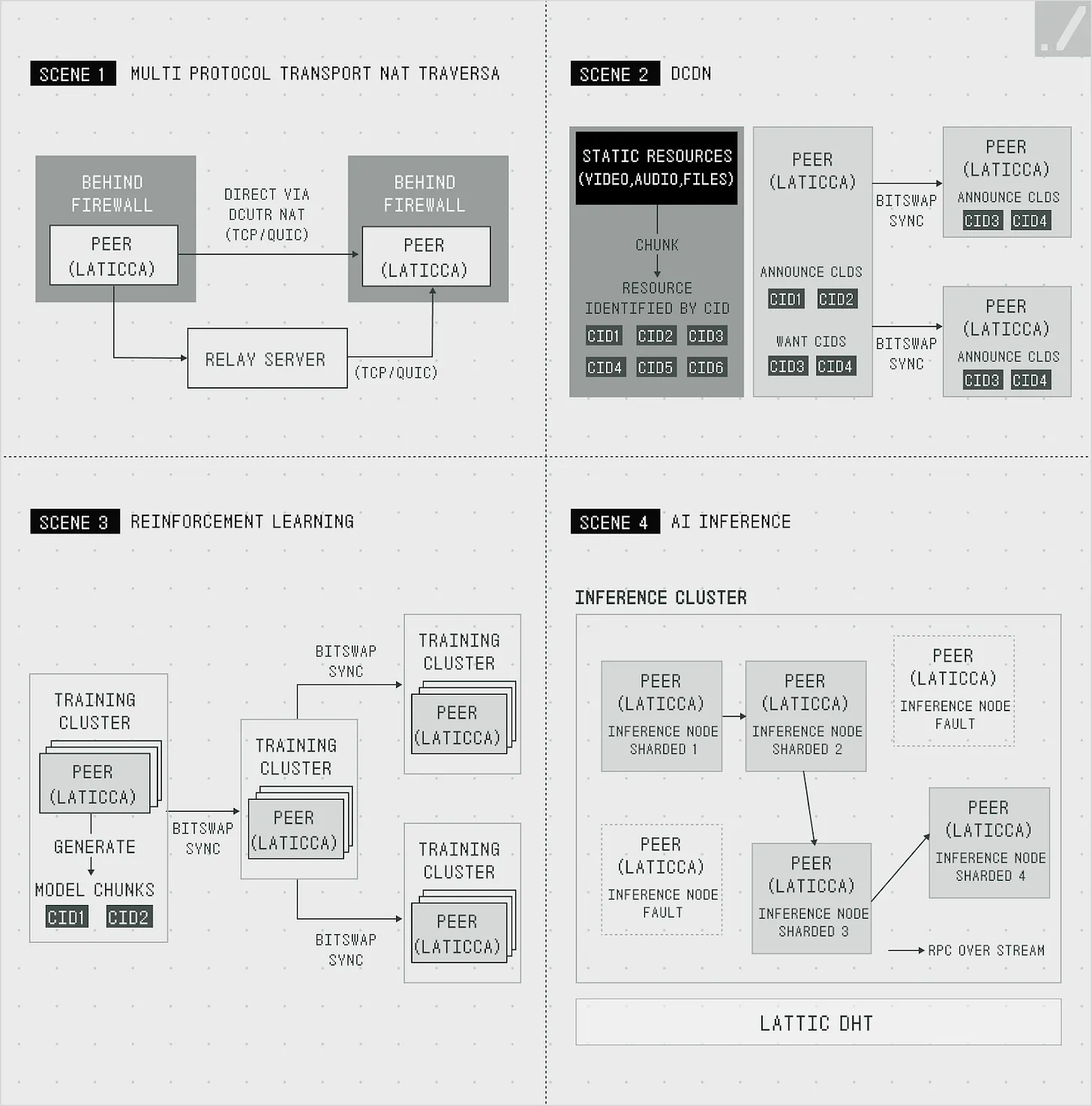
Source: Gradient
Lattica effectively addresses this issue. Hole-punching technology creates temporary "tunnels" through firewalls or NAT (Network Address Translation) to enable direct connections between computers. This builds a P2P network, allowing global computers to connect directly even in restricted and unpredictable environments. Once a connection is established, encryption protocols secure the communication.
A distributed environment requires simultaneous data exchange and rapid synchronization across multiple nodes to run large language models and deliver results. Lattica uses the BitSwap protocol (similar to torrenting) to efficiently transfer model files and intermediate processing results.
Source: Gradient
Lattica achieves stable and efficient data exchange in distributed environments. The protocol supports AI training and inference, as well as applications like distributed video streaming. Lattica's demo showcases how it works.
3.2. Parallax: Distributed Inference Engine
Lattica solves the problem of connecting global computers. Users face a remaining challenge: running large language models. Open-source models continue to improve, but most users still cannot run them directly. Large language models require substantial computing resources. Even DeepSeek's 60B model needs high-performance GPUs.
Parallax addresses this issue. Parallax partitions a large model into layers and distributes them across multiple devices. Each device processes its assigned layer and passes the results to the next device. This works similarly to an automotive assembly line: each stage processes a part to complete the final result.
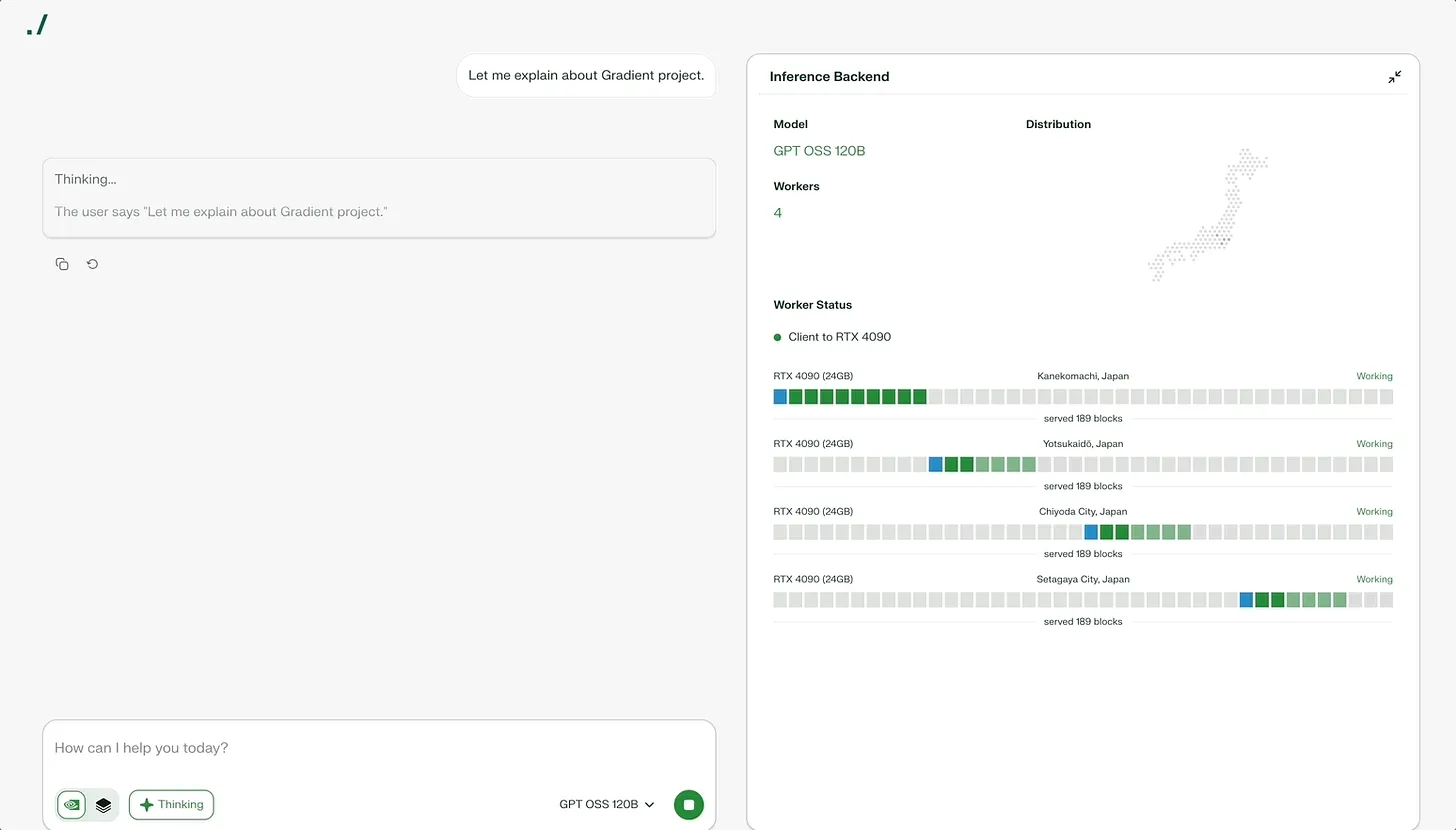
Gradient Chat, Source: Gradient
Simply partitioning is not enough for efficiency. The performance of participating devices varies. When a high-performance GPU processes quickly but the next device processes slowly, a bottleneck forms. Parallax analyzes the performance and speed of each device in real-time to find the optimal combination. The system minimizes bottlenecks and effectively utilizes all devices.
Source: Qwen
Parallax offers flexible options based on demand. The system currently supports over 40 open-source models, including Qwen and Kimi. Users can choose and run their preferred models. Users adjust execution methods based on model size. LocalHost runs small models (like Ollama) on personal computers. Co-Host connects multiple devices within a home or team. Global Host joins the global network.
3.3. Echo: Distributed Reinforcement Learning Framework
Parallax enables anyone to run models. Echo addresses the issue of model training. Pre-trained large language models limit practical applications. AI needs additional training for specific tasks to be truly useful. Reinforcement learning (RL) provides this training.
Reinforcement learning teaches AI through trial and error. AI repeatedly solves mathematical problems, while the system rewards correct answers and punishes incorrect ones. Through this process, AI learns to produce accurate answers. Reinforcement learning allows ChatGPT to respond naturally to human preferences.
Large language model reinforcement learning requires substantial computing resources. Echo divides the reinforcement learning process into two phases and deploys optimized hardware for each phase.
First is the inference phase. AI solves mathematical problems 10,000 times and collects data on correct and incorrect answers. Echo prioritizes running many attempts simultaneously rather than complex calculations.
Next is the training phase. Echo analyzes the collected data to identify which methods produced good results. The system then adjusts the model so that AI follows these methods next time. Echo processes complex mathematical operations quickly in this phase.
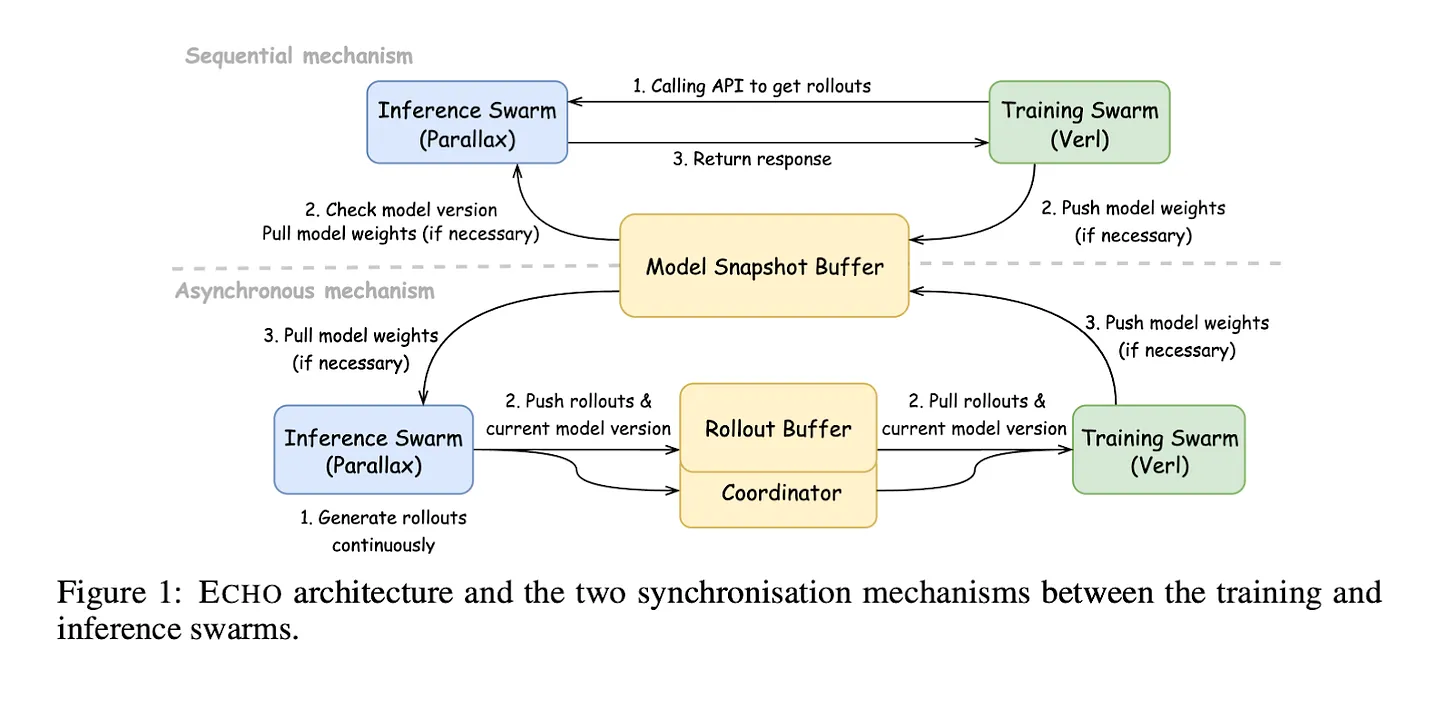
Source: Gradient
Echo deploys these two phases on different hardware. The inference cluster runs on consumer-grade computers worldwide using Parallax. Multiple consumer devices, such as the RTX 5090 or MacBook M4 Pro, simultaneously generate training samples. The training cluster uses high-performance GPUs like the A100 to rapidly improve the model.
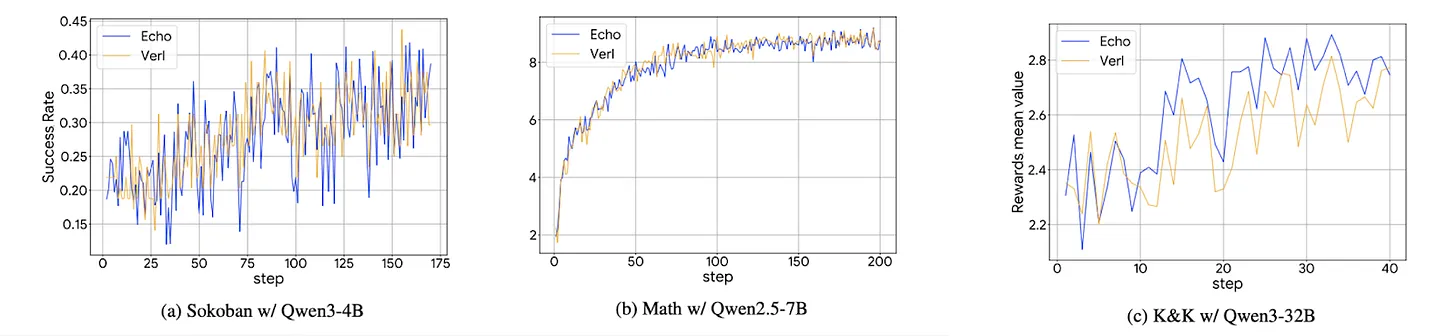
Source: Gradient
The results demonstrate Echo's effectiveness. Echo achieves performance comparable to the existing reinforcement learning framework VERL. Individuals and small businesses can now train large language models for their specific purposes in a distributed environment. Echo significantly lowers the barrier to entry for reinforcement learning.
4. Sovereign AI: New Possibilities Brought by Open Intelligence
AI has become essential, rather than optional. Sovereign AI is increasingly important. Sovereign AI means that individuals, companies, and nations independently own and control AI without relying on external sources.

Source: Tiger Research
The case of Windsurf clearly illustrates this point. Anthropic blocked access to the Claude API without notice. The company immediately faced service disruptions. When infrastructure providers block access, companies suffer immediate operational damage. The risk of data breaches complicates these issues further.
Nations face similar challenges. AI technology is rapidly developing around the United States and China, while other countries' dependency is increasing. Most large language models use 90% English in their pre-training data. This language imbalance poses the risk of non-English-speaking countries facing technological exclusion.
[Ongoing Research Projects]
Veil & Veri: Privacy protection and verification layers for AI (Inference Verification, Training Verification)
Mirage: A distributed simulation engine and robotic learning platform for physical world AI
Helix: A self-evolving learning framework for software agents (SRE)
Symphony: A multi-agent self-improvement coordination framework for collective intelligence
Gradient's open intelligence stack provides alternatives to this issue. Challenges remain. How does the system verify computational results in a distributed network? How does the system ensure quality and reliability in an open structure where anyone can participate? Gradient is conducting research and development to address these challenges.

Source: Gradient
Researchers from the University of California, Berkeley, the Hong Kong University of Science and Technology, and ETH Zurich continue to produce results in distributed AI systems. Collaborations with Google DeepMind and Meta accelerate technological progress. The investment market has recognized these efforts. Gradient raised $10 million in seed funding, co-led by Pantera Capital and Multicoin Capital, with participation from Sequoia China (now HSG).
AI technology will become increasingly important. Who owns and controls it becomes a critical question. Gradient is moving towards open intelligence that is accessible to everyone rather than monopolized by a few. The future they envision is worth paying attention to.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






