We are on the brink of an innovation explosion.
Author: Teng Yan
Translated by: Deep Tide TechFlow

Good morning! It has finally arrived.
The content of our entire paper is quite rich, and to make it easier for everyone to understand (while avoiding exceeding the size limits of email service providers), I decided to break it into several parts and share them gradually over the next month. Now, let’s get started!
A huge missed opportunity that I can never forget.
This matter has haunted me to this day because it was an obvious opportunity that anyone paying attention to the market could see, yet I missed it and didn’t invest a single penny.
No, this is not the next Solana killer, nor is it a memecoin featuring a dog wearing a funny hat.
It is… NVIDIA.
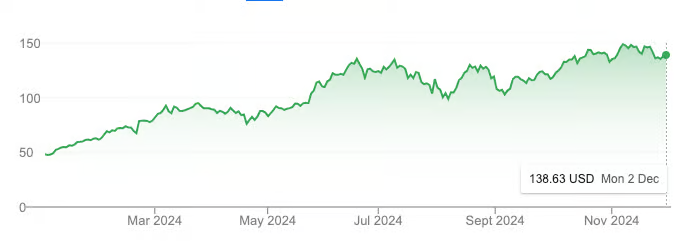
NVDA's stock performance year-to-date. Source: Google
In just one year, NVIDIA's market capitalization skyrocketed from $1 trillion to $3 trillion, with its stock price tripling, even outperforming Bitcoin during the same period.
Of course, part of this was driven by the AI boom. But more importantly, this growth has a solid real-world foundation. NVIDIA's revenue for the fiscal year 2024 reached $60 billion, a 126% increase from 2023. Behind this astonishing growth is a global race among major tech companies to purchase GPUs to gain an edge in the arms race for Artificial General Intelligence (AGI).
Why did I miss it?
For the past two years, my attention has been completely focused on the cryptocurrency space, without paying attention to developments in AI. This was a huge mistake that I still regret.
But this time, I will not make the same error.
Today's Crypto AI feels eerily familiar.
We are on the brink of an innovation explosion. It bears an astonishing resemblance to the California Gold Rush of the mid-19th century—industries and cities rising overnight, infrastructure rapidly developing, and those willing to take risks reaping substantial rewards.
Just like early NVIDIA, Crypto AI will seem so obvious in hindsight.
Crypto AI: An Investment Opportunity with Unlimited Potential
In the first part of my paper, I explained why Crypto AI is one of the most exciting potential opportunities today, both for investors and developers. Here are the key points:
Many still see it as a "castle in the air."
Crypto AI is currently in its early stages, and it may be 1-2 years away from the peak of hype.
This field has at least $230 billion in growth potential.
At the core of Crypto AI is the combination of artificial intelligence with cryptocurrency infrastructure. This makes it more likely to develop along the exponential growth trajectory of AI rather than following the broader cryptocurrency market. Therefore, to stay ahead, you need to keep an eye on the latest AI research on Arxiv and engage with founders who believe they are building the next big event.
Four Core Areas of Crypto AI
In the second part of my paper, I will focus on analyzing the four most promising subfields within Crypto AI:
Decentralized Computing: Model Training, Inference, and GPU Trading Markets
Data Networks
Verifiable AI
On-Chain AI Agents
This article is the result of weeks of in-depth research and discussions with founders and teams in the Crypto AI space. It is not a detailed analysis of each area but rather a high-level roadmap designed to spark your curiosity, help you optimize your research direction, and guide your investment decisions.
The Ecological Blueprint of Crypto AI
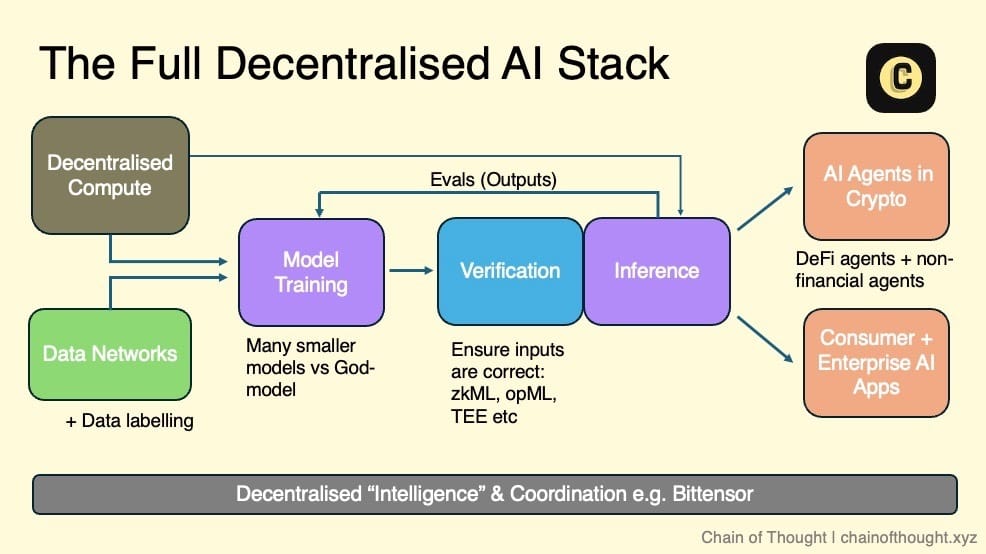
I envision the ecosystem of decentralized AI as a layered structure: starting from decentralized computing and open data networks at one end, which provide the foundation for training decentralized AI models.
All inputs and outputs of inference are verified through cryptography, cryptoeconomic incentives, and evaluation networks. These verified results flow to on-chain autonomous AI agents, as well as consumer and enterprise-level AI applications that users can trust.
A coordinating network connects the entire ecosystem, enabling seamless communication and collaboration.
In this vision, any team engaged in AI development can access one or more layers of the ecosystem based on their needs. Whether utilizing decentralized computing for model training or ensuring high-quality output through evaluation networks, this ecosystem offers diverse options.
Thanks to the composability of blockchain, I believe we are moving towards a modular future. Each layer will be highly specialized, and protocols will be optimized for specific functions rather than adopting an integrated solution.
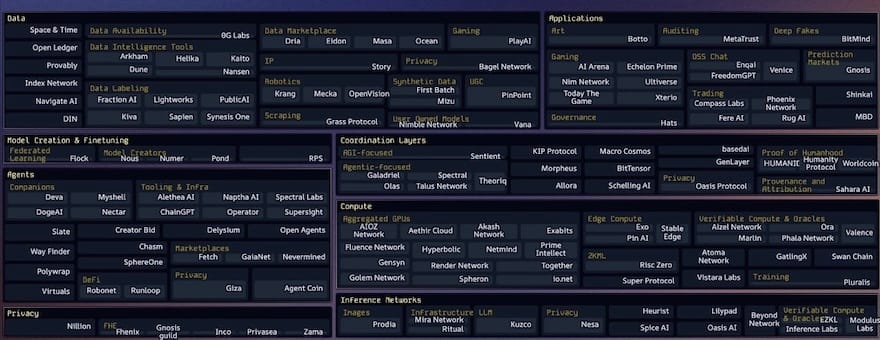
In recent years, a plethora of startups has emerged at every layer of the decentralized AI tech stack, exhibiting a "Cambrian explosion" of growth. Most of these companies were founded only 1-3 years ago. This indicates that we are still in the early stages of this industry.
Among the Crypto AI startup ecosystem maps I have seen, the most comprehensive and up-to-date version is maintained by topology.vc by Casey and her team. This is an indispensable resource for anyone wanting to track developments in this field.
As I delve into the various subfields of Crypto AI, I constantly think: how big are the opportunities here? I am not focused on small markets but rather on those massive opportunities that can scale to hundreds of billions of dollars.
- Market Size ----
When assessing market size, I ask myself: is this subfield creating an entirely new market, or is it disrupting an existing one?
Take decentralized computing as an example; this is a classic disruptive area. We can estimate its potential through the existing cloud computing market. Currently, the cloud computing market is approximately $680 billion and is expected to reach $2.5 trillion by 2032.
In contrast, entirely new markets like AI agents are harder to quantify. Due to the lack of historical data, we can only estimate based on intuitive judgments and reasonable speculations about their problem-solving capabilities. However, it is essential to be cautious, as sometimes products that seem to represent a new market may merely be the result of "finding solutions to problems."
- Timing --
Timing is key to success. While technology typically improves and becomes cheaper over time, the pace of progress varies significantly across different fields.
How mature is the technology in a particular subfield? Is it mature enough for large-scale application? Or is it still in the research phase, years away from practical application? Timing determines whether a field is worth immediate attention or if it should be observed for a while.
Take Fully Homomorphic Encryption (FHE) as an example: its potential is undeniable, but the current technological performance is still too slow for large-scale application. We may need a few more years to see it enter the mainstream market. Therefore, I prioritize fields where the technology is close to large-scale application, focusing my time and energy on opportunities that are gaining momentum.
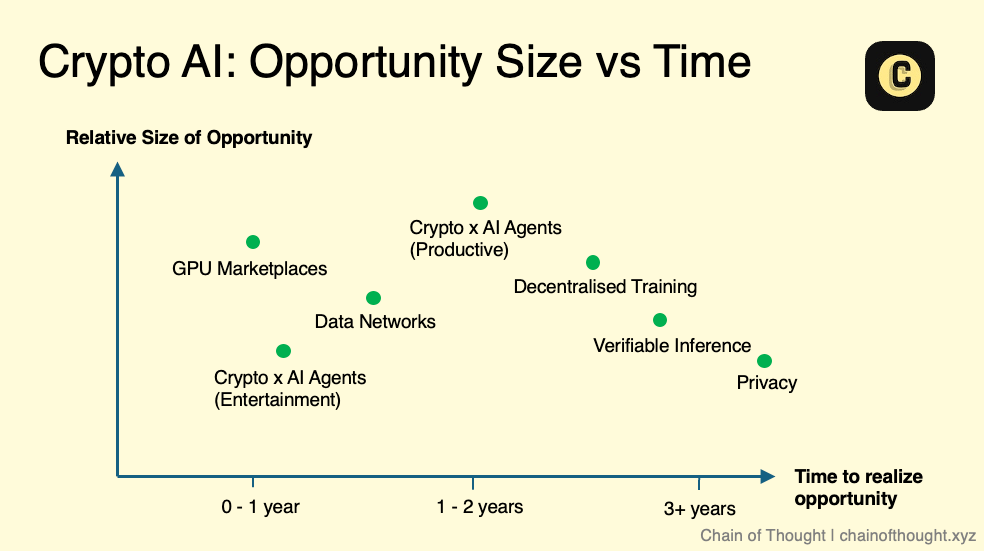
If we were to plot these subfields on a "market size vs. timing" chart, it might look something like this. It is important to note that this is just a conceptual sketch and not a strict guide. There is also complexity within each field—for example, in verifiable inference, different methods (such as zkML and opML) are at different stages of technological maturity.
Nevertheless, I firmly believe that the future scale of AI will be extraordinarily large. Even fields that seem "niche" today could evolve into significant markets in the future.
At the same time, we must recognize that technological progress is not always linear—it often advances in leaps. When new technological breakthroughs occur, my views on market timing and scale will also adjust accordingly.
Based on the framework above, we will next break down the various subfields of Crypto AI one by one, exploring their development potential and investment opportunities.
Field 1: Decentralized Computing
Summary
Decentralized computing is the core pillar of the entire decentralized AI ecosystem.
The GPU market, decentralized training, and decentralized inference are closely interconnected and develop in synergy.
The supply side mainly comes from small and medium-sized data centers and consumer GPU devices.
The demand side is currently small but gradually growing, primarily consisting of price-sensitive users with low latency requirements and some smaller AI startups.
The biggest challenge facing the current Web3 GPU market is how to make these networks operate efficiently.
Coordinating the use of GPUs in a decentralized network requires advanced engineering techniques and robust network architecture design.
1.1 GPU Market / Computing Network
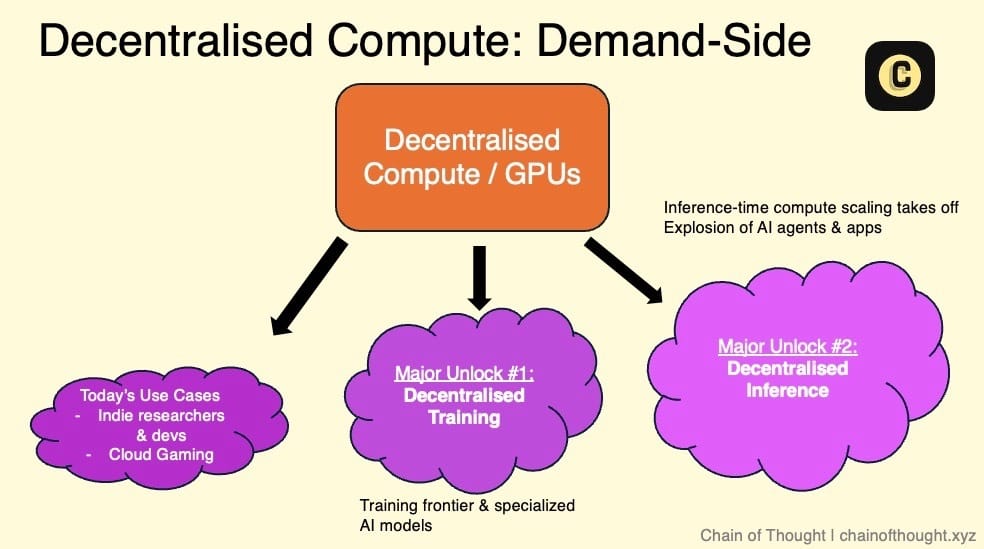
Currently, some Crypto AI teams are building decentralized GPU networks to leverage the globally underutilized pool of computing resources to address the situation where GPU demand far exceeds supply.
The core value of these GPU markets can be summarized in three points:
Computing costs can be up to 90% lower than AWS. This low cost comes from two aspects: eliminating intermediaries and opening up the supply side. These markets allow users to access computing resources at the lowest marginal cost globally.
No long-term contracts, no identity verification (KYC), and no waiting for approval.
Resistance to censorship.
To address the supply-side issues of the market, these markets source computing resources from the following:
Enterprise-grade GPUs: High-performance GPUs such as A100 and H100, which typically come from small and medium-sized data centers (which struggle to find enough customers when operating independently) or from Bitcoin miners looking to diversify their income sources. Additionally, some teams are leveraging large infrastructure projects funded by the government, which have built numerous data centers as part of technological development. These suppliers are often incentivized to continuously connect GPUs to the network to help offset the depreciation costs of their equipment.
Consumer-grade GPUs: Millions of gamers and home users connect their computers to the network and earn rewards through tokens.
Currently, the demand side for decentralized computing mainly includes the following types of users:
Price-sensitive users with low latency requirements: For example, budget-constrained researchers and independent AI developers. They are more concerned about costs than real-time processing capabilities. Due to budget constraints, they often find it difficult to afford the high costs of traditional cloud service giants (such as AWS or Azure). Targeted marketing for this group is crucial.
Small AI startups: These companies need flexible and scalable computing resources but do not want to sign long-term contracts with large cloud service providers. Attracting this group requires strengthening business cooperation, as they are actively seeking alternatives outside traditional cloud computing.
Crypto AI startups: These companies are developing decentralized AI products but need to rely on these decentralized networks if they do not have their own computing resources.
Cloud gaming: Although it has little direct connection to AI, the demand for GPU resources in cloud gaming is rapidly growing.
A key point to remember is: Developers always prioritize cost and reliability.
The Real Challenge: Demand, Not Supply
Many startups view the scale of the GPU supply network as a marker of success, but in reality, this is merely a "vanity metric."
The real bottleneck lies on the demand side, not the supply side. The key metrics for measuring success are not how many GPUs are in the network, but rather the utilization rate of the GPUs and the actual number of GPUs being rented.
Token incentive mechanisms are very effective in kickstarting the supply side, quickly attracting resources to join the network. However, they do not directly address the issue of insufficient demand. The real test lies in whether the product can be refined to a sufficiently good state to stimulate potential demand.
As Haseeb Qureshi from Dragonfly stated, this is where the key lies.
Making the Computing Network Operate Effectively
Currently, the biggest challenge facing the Web3 distributed GPU market is how to make these networks operate efficiently.
This is not a simple task.
Coordinating GPUs in a distributed network is an extremely complex task that involves multiple technical challenges, such as resource allocation, dynamic workload scaling, load balancing of nodes and GPUs, latency management, data transmission, fault tolerance, and how to handle diverse hardware devices distributed globally. These issues compound to create significant engineering challenges.
To solve these problems, solid engineering capabilities and a robust, well-designed network architecture are required.
To better understand this, one can refer to Google’s Kubernetes system. Kubernetes is widely regarded as the gold standard in container orchestration, automating tasks such as load balancing and scaling in distributed environments, which are very similar to the challenges faced by distributed GPU networks. Notably, Kubernetes was developed based on Google’s more than a decade of experience in distributed computing, and even so, it took years of continuous iteration to perfect.
Currently, some operational GPU computing markets can handle small-scale workloads, but once they attempt to scale up, issues will emerge. This may be due to fundamental flaws in their architectural design.
Credibility Issues: Challenges and Opportunities
Another important issue that decentralized computing networks need to address is how to ensure the credibility of nodes, specifically how to verify whether each node is genuinely providing the computing power it claims. Currently, this verification process largely relies on the reputation system of the network, where computing providers are sometimes ranked based on their reputation scores. Blockchain technology has a natural advantage in this area, as it can achieve trustless verification mechanisms. Some startups, such as Gensyn and Spheron, are exploring how to solve this problem through trustless methods.
Currently, many Web3 teams are still struggling to address these challenges, which means that there are still vast opportunities in this field.
Market Size of Decentralized Computing
So, how large is the market for decentralized computing networks?
Currently, it may only represent a tiny fraction of the global cloud computing market (which is approximately $680 billion to $2.5 trillion). However, as long as the costs of decentralized computing are lower than those of traditional cloud service providers, there will be demand, even if there are some additional frictions in user experience.
I believe that in the short to medium term, the costs of decentralized computing will remain low. This is mainly due to two factors: token subsidies and the unlocking of supply from non-price-sensitive users. For example, if I can rent out my gaming laptop to earn extra income, whether it’s $20 or $50 a month, I would be satisfied.
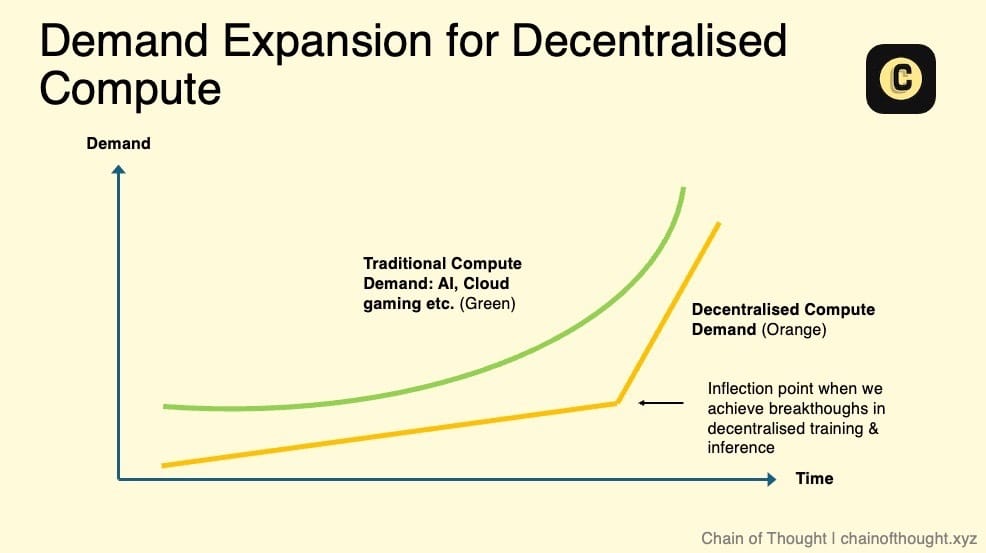
The true growth potential of decentralized computing networks and the significant expansion of their market size will depend on several key factors:
Feasibility of decentralized AI model training: When decentralized networks can support the training of AI models, it will create enormous market demand.
Surge in inference demand: As the demand for AI inference skyrockets, existing data centers may not be able to meet this demand. In fact, this trend has already begun to manifest. NVIDIA's Jensen Huang stated that inference demand will grow "a billion times".
Introduction of Service Level Agreements (SLAs): Currently, decentralized computing mainly provides services on a "best-effort" basis, and users may face uncertainties regarding service quality (such as uptime). With SLAs, these networks can offer standardized reliability and performance metrics, thereby breaking down key barriers to enterprise adoption and making decentralized computing a viable alternative to traditional cloud computing.
Decentralized, permissionless computing is the foundational layer of the decentralized AI ecosystem and one of its most critical infrastructures.
Although the supply chain for hardware like GPUs is continuously expanding, I believe we are still in the dawn of the "human intelligence era." In the future, the demand for computing power will be endless.
Please pay attention to the key inflection points that may trigger a repricing of the GPU market—this inflection point may come soon.
Other Notes:
The competition in the pure GPU market is very fierce, not only due to the rivalry between decentralized platforms but also facing the strong rise of Web2 AI emerging cloud platforms (such as Vast.ai and Lambda).
Small nodes (for example, 4 H100 GPUs) have limited use, resulting in low market demand. However, finding suppliers for large clusters is nearly impossible, as their demand remains very strong.
Will the computing resource supply of decentralized protocols be consolidated by a dominant player, or will it continue to be dispersed across multiple markets? I lean towards the former and believe the eventual outcome will exhibit a power-law distribution, as consolidation often enhances the efficiency of infrastructure. Of course, this process takes time, and during this period, market fragmentation and chaos will persist.
Developers prefer to focus on building applications rather than spending time dealing with deployment and configuration issues. Therefore, the computing market needs to simplify these complexities and minimize user friction when acquiring computing resources.
1.2 Decentralized Training
Summary
If scaling laws hold, training the next generation of cutting-edge AI models in a single data center will become physically unfeasible in the future.
Training AI models requires significant data transfer between GPUs, and the lower interconnect speeds of distributed GPU networks are often the biggest technical barrier.
Researchers are exploring various solutions and have made some breakthrough progress (such as Open DiLoCo and DisTrO). These technological innovations will have a cumulative effect, accelerating the development of decentralized training.
The future of decentralized training may focus more on small, specialized models designed for specific domains rather than cutting-edge models aimed at AGI.
With the popularization of models like OpenAI's o1, the demand for inference will experience explosive growth, creating significant opportunities for decentralized inference networks.
Imagine this: a massive, world-changing AI model, not developed by secretive top labs, but collaboratively completed by millions of ordinary people. Gamers' GPUs are no longer just used to render stunning graphics in Call of Duty, but are employed to support a grander goal—a collectively owned, open-source AI model without any centralized gatekeepers.
In such a future, foundational-scale AI models will no longer be the exclusive domain of top labs but will be the result of widespread participation.
But back to reality, most heavyweight AI training is still concentrated in centralized data centers, and this trend may not change for some time.
Companies like OpenAI are continuously expanding their massive GPU clusters. Elon Musk recently revealed that xAI is about to complete a data center with a total GPU count equivalent to 200,000 H100s.
But the issue is not just the number of GPUs. A key metric proposed in Google's 2022 PaLM paper is the Model FLOPS Utilization (MFU), which measures the actual utilization of the maximum computational capacity of GPUs. Surprisingly, this utilization is often only 35-40%.
Why is it so low? Despite the rapid improvement in GPU performance due to Moore's Law, advancements in networking, memory, and storage devices have lagged significantly, creating a notable bottleneck. As a result, GPUs often sit idle, waiting for data transfers to complete.
Currently, the fundamental reason for the high centralization of AI training is efficiency.
Training large models relies on the following key technologies:
Data Parallelism: Splitting datasets across multiple GPUs for parallel processing to accelerate the training process.
Model Parallelism: Distributing different parts of the model across multiple GPUs to overcome memory limitations.
These technologies require frequent data exchanges between GPUs, making interconnect speed (the rate of data transfer in the network) crucial.
When the training cost of cutting-edge AI models can reach up to $1 billion, every bit of efficiency improvement is vital.
Centralized data centers, with their high-speed interconnect technology, can achieve rapid data transfer between GPUs, significantly saving costs during training time. This is something decentralized networks currently struggle to match… at least for now.
Overcoming Slow Interconnect Speeds
If you talk to practitioners in the AI field, many may candidly say that decentralized training is unfeasible.
In a decentralized architecture, GPU clusters are not located in the same physical location, leading to slower data transfer speeds between them, which becomes a major bottleneck. The training process requires GPUs to synchronize and exchange data at every step. The farther apart they are, the higher the latency. Higher latency means slower training speeds and increased costs.
A training task that takes only a few days in a centralized data center may take two weeks in a decentralized environment, with higher costs. This is clearly not feasible.
However, this situation is changing.
Excitingly, the research interest in distributed training is rapidly rising. Researchers are exploring from multiple directions simultaneously, and the recent surge of research results and papers is evidence of this. These technological advancements will create a cumulative effect, accelerating the development of decentralized training.
Moreover, testing in real production environments is also crucial, as it helps us break through existing technological boundaries.
Currently, some decentralized training technologies can handle smaller models in low-speed interconnect environments. Cutting-edge research is working to extend these methods to larger models.
- For example, Prime Intellect's Open DiCoLo paper proposes a practical method: by dividing GPUs into "islands," where each island completes 500 local computations before synchronization, thus reducing bandwidth requirements to 1/500 of the original. This technology was initially researched by Google DeepMind for small models and has now successfully scaled to train a model with 10 billion parameters, which has recently been fully open-sourced.
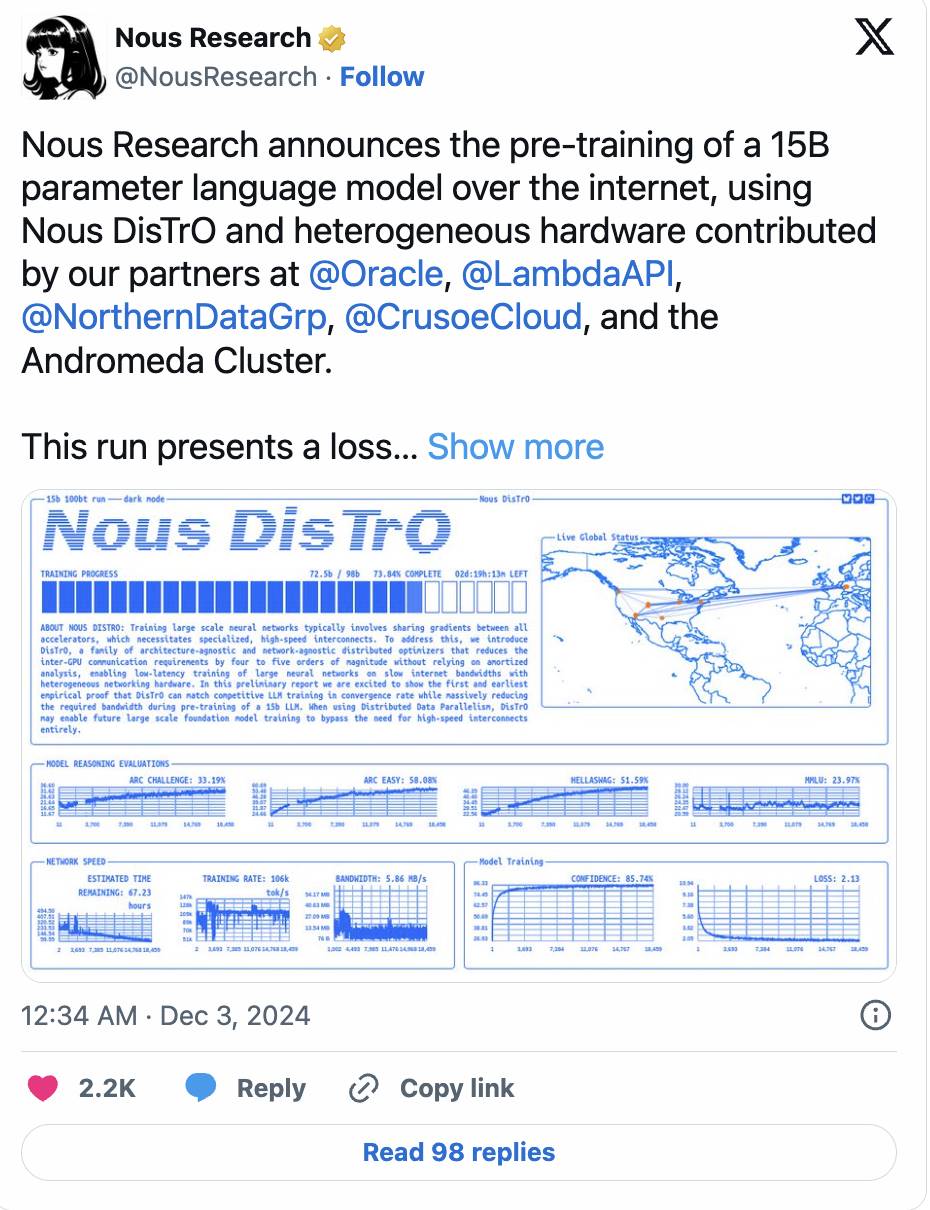
Nous Research's DisTrO framework further breaks through by reducing communication requirements between GPUs by up to 10,000 times through optimizer technology, successfully training a model with 1.2 billion parameters.
This momentum continues. Nous recently announced that they have completed pre-training a model with 15 billion parameters, with loss curves and convergence speeds that even surpass traditional centralized training performance.
- Additionally, methods like SWARM Parallelism and DTFMHE are also exploring how to train ultra-large-scale AI models across different types of devices, even when these devices have varying speeds and connection conditions.
Another challenge is how to manage diverse GPU hardware, especially consumer-grade GPUs commonly found in decentralized networks, which often have limited memory. This issue is gradually being addressed through model parallelism techniques (distributing different layers of the model across multiple devices).
The Future of Decentralized Training
Currently, the model scale of decentralized training methods still lags far behind the cutting-edge models (reportedly, GPT-4 has nearly a trillion parameters, which is 100 times that of Prime Intellect's 10 billion parameter model). To achieve true scalability, we need significant breakthroughs in model architecture design, network infrastructure, and task allocation strategies.
But we can boldly imagine: in the future, decentralized training may be able to aggregate more GPU computing power than the largest centralized data centers.
Pluralis Research (a team worth paying attention to in the field of decentralized training) believes that this is not only possible but inevitable. Centralized data centers are limited by physical conditions, such as space and power supply, while decentralized networks can leverage nearly unlimited resources globally.
Even NVIDIA's Jensen Huang has mentioned that asynchronous decentralized training could be key to unlocking AI's scaling potential. Additionally, distributed training networks have stronger fault tolerance.
Therefore, in one possible future, the world's most powerful AI models will be trained in a decentralized manner.
This vision is exciting, but I remain cautious for now. We need more compelling evidence to prove that decentralized training of large-scale models is technically and economically feasible.
I believe the best application scenario for decentralized training may lie in smaller, specialized open-source models designed for specific applications, rather than competing with ultra-large, AGI-targeted cutting-edge models. Certain architectures, especially non-Transformer models, have already proven to be very suitable for decentralized environments.
Moreover, token incentive mechanisms will also be an important part of the future. Once decentralized training becomes feasible at scale, tokens can effectively incentivize and reward contributors, thereby driving the development of these networks.
Although the road ahead is long, current progress is encouraging. Breakthroughs in decentralized training will not only benefit decentralized networks but also bring new possibilities for large tech companies and top AI labs…
1.3 Decentralized Inference
Currently, most of AI's computing resources are concentrated on training large models. There is an arms race among top AI labs to develop the strongest foundational models, ultimately aiming for AGI.
However, I believe that this concentrated investment in computational resources for training will gradually shift towards inference in the coming years. As AI technology increasingly integrates into the applications we use daily—from healthcare to entertainment—the computational resources required to support inference will become extremely vast.

This trend is not unfounded. Inference-time compute scaling has become a hot topic in the AI field. OpenAI recently released a preview/mini version of its latest model o1 (codename: Strawberry), which is notable for its ability to "take time to think." Specifically, it first analyzes what steps it needs to take to answer a question and then completes those steps incrementally.
This model is designed for more complex tasks that require planning, such as solving crossword puzzles, and can handle problems that require deep reasoning. While it generates responses more slowly, the results are more detailed and thoughtful. However, this design also comes with high operational costs, with inference costs being 25 times that of GPT-4.
From this trend, it is evident that the next leap in AI performance will rely not only on training larger models but also on expanding computational capabilities during the inference phase.
If you want to learn more, several studies have already demonstrated:
Significant performance improvements can be achieved in many tasks by expanding inference computation through repeated sampling.
The inference phase also follows an exponential scaling law.
Once powerful AI models are trained, their inference tasks (i.e., the actual application phase) can be offloaded to decentralized computing networks. This approach is very attractive for the following reasons:
The resource demands for inference are much lower than for training. After training is complete, models can be compressed and optimized using techniques such as quantization, pruning, or distillation. They can even be split using tensor parallelism or pipeline parallelism to run on ordinary consumer-grade devices. Inference does not require high-end GPUs.
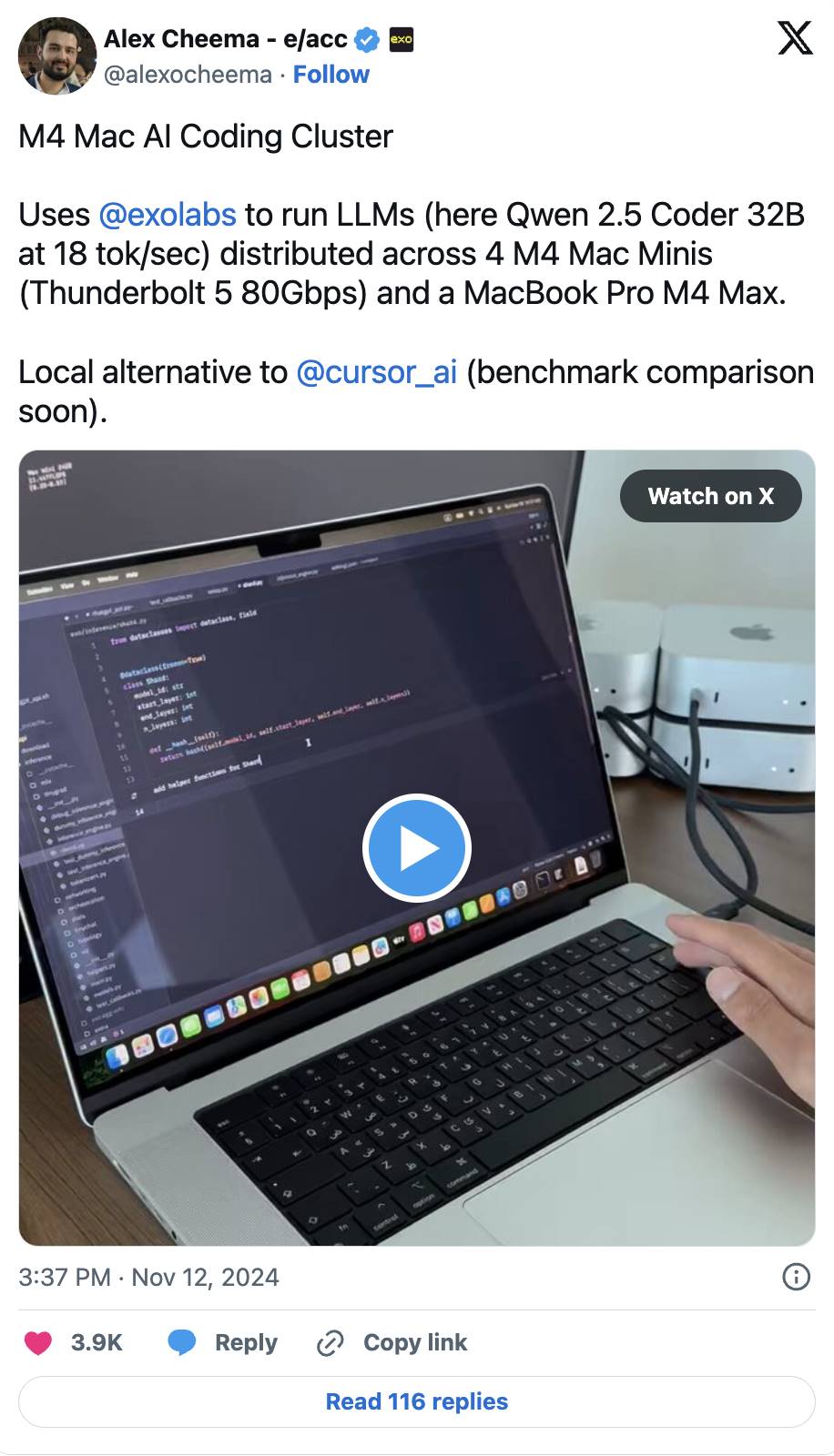
This trend is already becoming apparent. For example, Exo Labs has found a way to run a 450 billion parameter Llama3 model on consumer hardware like MacBook and Mac Mini. By distributing inference tasks across multiple devices, even large-scale computational demands can be efficiently and cost-effectively met.
- Better user experience: Deploying computing power closer to users can significantly reduce latency, which is crucial for real-time applications such as gaming, augmented reality (AR), or autonomous vehicles—where every millisecond of delay can lead to different user experiences.
We can liken decentralized inference to AI's CDN (Content Delivery Network). Traditional CDNs quickly deliver website content by connecting to nearby servers, while decentralized inference utilizes local computing resources to generate AI responses at high speed. This way, AI applications can become more efficient, responsive, and reliable.
This trend is already emerging. Apple's latest M4 Pro chip has performance close to NVIDIA RTX 3070 Ti—a high-performance GPU that was once exclusive to hardcore gamers. Now, the hardware we use daily is becoming increasingly capable of handling complex AI workloads.
Value Empowerment of Cryptocurrency
For decentralized inference networks to truly succeed, they must provide sufficiently attractive economic incentives for participants. Computing nodes in the network need to be reasonably compensated for their contributed computing power, while the system must also ensure fairness and efficiency in reward distribution. Additionally, geographical diversity is crucial. It not only reduces latency for inference tasks but also enhances the network's fault tolerance, thereby improving overall stability.
So, what is the best way to build a decentralized network? The answer is cryptocurrency.
Tokens are a powerful tool that can align the interests of all participants, ensuring that everyone is working towards the same goal: scaling the network and increasing the value of the tokens.
Moreover, tokens can significantly accelerate the growth of the network. They help solve the classic "chicken or egg" dilemma that many networks face in their early development. By rewarding early adopters, tokens can drive more people to participate in building the network from the outset.
The success of Bitcoin and Ethereum has already proven the effectiveness of this mechanism—they have gathered the largest pool of computing power on Earth.
Decentralized inference networks will be the next inheritors. With the characteristic of geographical diversity, these networks can reduce latency, enhance fault tolerance, and bring AI services closer to users. With the incentive mechanisms driven by cryptocurrency, the speed and efficiency of decentralized network expansion will far exceed that of traditional networks.
Acknowledgments
Teng Yan
In the upcoming series of articles, we will delve into data networks and explore how they help break through the data bottlenecks faced by AI.
Disclaimer
This article is for educational purposes only and does not constitute any financial advice. It is not an endorsement of asset trading or financial decisions. Please conduct your own research and exercise caution when making investment choices.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







