Author: Mohit Pandit, IOSG Ventures
Abstract
GPU shortages are a reality, with tight supply and demand, but the underutilized GPU capacity can meet today's supply-constrained demand.
An incentive layer is needed to promote participation in cloud computing, and then ultimately coordinate computing tasks for inference or training. The DePIN model is perfect for this purpose.
Due to the incentives from the supply side and the low computing costs, the demand side finds this very attractive.
Not everything is rosy, and certain trade-offs must be made when choosing Web3 cloud: such as 'latency'. In addition to traditional GPU clouds, trade-offs also include insurance, Service Level Agreements, and more.
The DePIN model has the potential to address the GPU availability issue, but a fragmented model will not make the situation better. For situations with exponentially growing demand, fragmented supply is just as bad as no supply.
Given the number of new market participants, market aggregation is inevitable.
Introduction
We are on the cusp of a new era of machine learning and artificial intelligence. While AI has existed in various forms for some time (AI being computer devices informed to perform tasks that require human intelligence, such as washing machines), we are now witnessing the emergence of complex cognitive models capable of performing tasks that require intelligent human behavior. Notable examples include OpenAI's GPT-4 and DALL-E 2, as well as Google's Gemini.
In the rapidly growing field of artificial intelligence (AI), we must recognize the dual aspects of development: model training and inference. Inference involves the functionality and output of AI models, while training involves the complex process of building intelligent models (including machine learning algorithms, datasets, and computing power).
Take GPT-4, for example, where end users are only concerned with inference: obtaining output from the model based on text input. However, the quality of this inference depends on model training. To train effective AI models, developers need access to comprehensive foundational datasets and immense computing power. These resources are primarily concentrated in the hands of industry giants including OpenAI, Google, Microsoft, and AWS.
The formula is simple: better model training >> enhanced inference capabilities of AI models >> attracting more users >> generating more revenue, which in turn increases resources for further training.
These major players have access to large foundational datasets, and more crucially, control significant computing power, creating barriers to entry for emerging developers. Consequently, newcomers often struggle to obtain sufficient data or access necessary computing power at an economically viable scale. In light of this, we see the value of networks in democratizing resource access, primarily related to large-scale access to computing resources and cost reduction.
GPU Supply Issue
NVIDIA's CEO Jensen Huang said at CES 2019, "Moore's Law has ended." Today's GPUs are severely underutilized. Even during deep learning/training cycles, GPUs are not fully utilized.
Here are typical GPU utilization figures for different workloads:
Idle (just booted into Windows operating system): 0-2% General productivity tasks (writing, simple browsing): 0-15% Video playback: 15 - 35% PC gaming: 25 - 95% Graphic design/photo editing active workloads (Photoshop, Illustrator): 15 - 55% Video editing (active): 15 - 55% Video editing (rendering): 33 - 100% 3D rendering (CUDA / OptiX): 33 - 100% (often incorrectly reported by Win Task Manager - use GPU-Z)
Most consumer devices with GPUs fall into the first three categories.
Image GPU utilization %. Source: Weights and Biases
The above situation points to a problem: poor utilization of computational resources.
There is a need to better utilize the capacity of consumer GPUs, even when GPU utilization peaks, it is suboptimal. This clearly indicates two things to be done in the future: Resource (GPU) aggregation Parallelization of training tasks
There are currently four types of hardware available for supply: · Data center GPUs (e.g., Nvidia A100s) · Consumer GPUs (e.g., Nvidia RTX3060) · Custom ASICs (e.g., Coreweave IPU) · Consumer SoCs (e.g., Apple M2)
Except for ASICs (as they are built for specific purposes), other hardware can be aggregated for most efficient utilization. With many such chips in the hands of consumers and data centers, an aggregated supply-side DePIN model may be a feasible path.
GPU production forms a volume pyramid; consumer-grade GPU production is the highest, while advanced GPUs like NVIDIA A100s and H100s have the lowest production volume (but higher performance). The cost of producing these advanced chips is 15 times that of consumer GPUs, but sometimes does not provide 15 times the performance.
The entire cloud computing market is currently valued at approximately $483 billion and is expected to grow at a compound annual growth rate of approximately 27% over the next few years. By 2023, there will be approximately 13 billion hours of ML computing demand, which at current standard rates is equivalent to approximately $56 billion in 2023 ML computing expenditure. This entire market is also growing rapidly, doubling every 3 months.
GPU Demand
The computing demand mainly comes from AI developers (researchers and engineers). Their primary requirements are: price (low-cost computing), scale (large-scale GPU computing), and user experience (easy access and use). In the past two years, due to the increasing demand for AI-based applications and the development of ML models, there has been a huge demand for GPUs. Developing and running ML models requires:
Large-scale computing (from accessing multiple GPUs or data centers)
The ability to perform model training, fine-tuning, and inference, with each task being deployed in parallel on a large number of GPUs
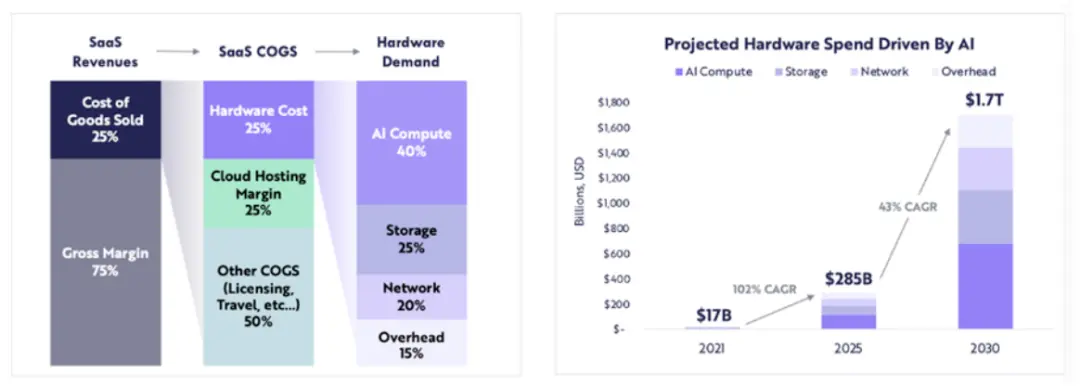
Expenditure on computing-related hardware is expected to grow from $17 billion in 2021 to $285 billion in 2025 (a compound annual growth rate of approximately 102%), and ARK expects computing-related hardware expenditure to reach $1.7 trillion by 2030 (a compound annual growth rate of 43%).
ARK Research
With a large number of LLMs in the innovation stage, competition drives the continuous demand for computing on more parameters, as well as retraining, and we can expect sustained demand for high-quality computing in the coming years.
Where Does Blockchain Come into Play with the New GPU Supply Tightening?
When resources are scarce, the DePIN model comes to the rescue:
Initiating the supply side, creating a large supply Coordinating and completing tasks Ensuring tasks are completed correctly Properly rewarding providers for completed work
Aggregating any type of GPU (consumer, enterprise, high-performance, etc.) may present challenges in utilization. When computing tasks are fragmented, A100 chips should not be performing simple calculations. GPU networks need to decide which types of GPUs they believe should be included in the network, based on their market entry strategy.
When computing resources themselves are dispersed (sometimes globally), the choice of which type of computing framework to use needs to be made by the user or the protocol itself. Providers like io.net allow users to choose from 3 computing frameworks: Ray, Mega-Ray, or deploy Kubernetes clusters to execute computing tasks in containers. There are more distributed computing frameworks, such as Apache Spark, but Ray is the most commonly used. Once the selected GPU completes the computing task, the output is restructured to yield a well-trained model.
A well-designed token model will subsidize computing costs for GPU providers, making such a scheme more attractive to many developers (demand side). Distributed computing systems inherently have latency. There is computing decomposition and output restructuring. So developers need to weigh the cost-effectiveness of training models against the required time.
Does a Distributed Computing System Need Its Own Chain?
There are two ways in which networks operate:
Charging by task (or computing cycle) or by time Charging per unit of time
In the first method, a proof-of-work chain similar to what Gensyn is attempting can be built, where different GPUs share "work" and are rewarded for it. For a more trustless model, they have the concept of validators and snitches who are rewarded for maintaining the integrity of the system, based on the proofs generated by solvers.
Another proof-of-work system is Exabits, which does not involve task segmentation but views its entire GPU network as a single supercomputer. This model seems more suitable for large-scale LLM.
Akash Network has added GPU support and started aggregating GPUs into this field. They have a base layer L1 for consensus on state (showing the work completed by GPU providers), a market layer, and container orchestration systems such as Kubernetes or Docker Swarm to manage the deployment and scaling of user applications.
If a system is to be trustless, a proof-of-work chain model will be most effective. This ensures the coordination and integrity of the protocol.
On the other hand, systems like io.net do not position themselves as a chain. They address the core issue of GPU availability and charge customers on a per-unit time (per hour) basis. They do not require a layer of verifiability because they essentially "rent" GPUs for arbitrary use within a specific lease period. The protocol itself does not involve task segmentation but is used by developers with open-source frameworks like Ray, Mega-Ray, or Kubernetes to complete their applications.
Web2 vs. Web3 GPU Cloud
There are many participants in the GPU cloud or GPU-as-a-Service field in Web2. The major players in this field include AWS, CoreWeave, PaperSpace, Jarvis Labs, Lambda Labs, Google Cloud, Microsoft Azure, and OVH Cloud.
This is a traditional cloud business model where customers can rent GPUs (or multiple GPUs) on a per-unit time basis (usually per hour) when they need computing power. There are many different solutions for different use cases.
The main differences between Web2 and Web3 GPU clouds are in the following parameters:
- Cloud setup costs
The cost of establishing a GPU cloud is significantly reduced due to token incentives. OpenAI is raising $1 trillion for the production of computing chips. It seems that without token incentives, beating market leaders would require at least $1 trillion.
- Computing time
Non-Web3 GPU clouds will be faster because the rented GPU clusters are located within a geographical region, while the Web3 model may have a more widely distributed system, with latency possibly arising from inefficient task segmentation, load balancing, and most importantly, bandwidth.
- Computing costs
Due to token incentives, the cost of Web3 computing will be significantly lower than the existing Web2 model.
Comparison of computing costs:
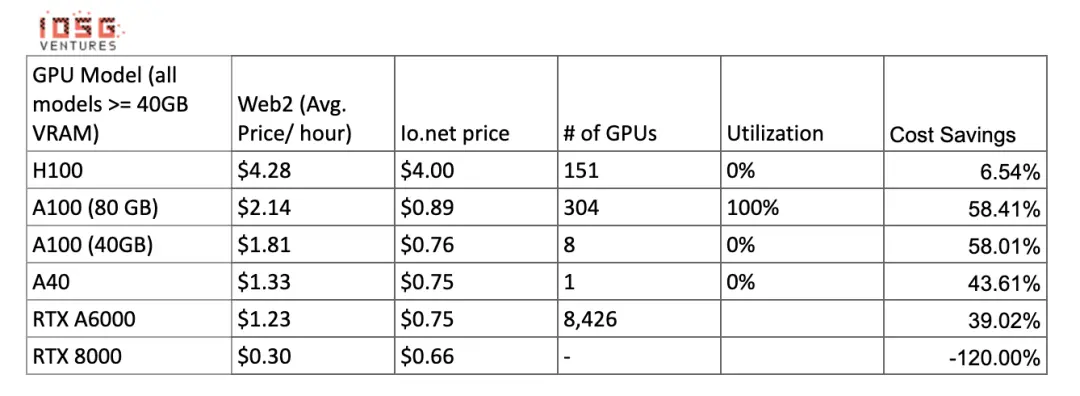
These numbers may change when there is more supply and utilization of clusters providing these GPUs. Gensyn claims to offer A100s (and their equivalents) for as low as $0.55 per hour, and Exabits promises similar cost savings structure.
4. Compliance
In permissionless systems, compliance is not easy. However, Web3 systems like io.net, Gensyn, etc., do not position themselves as permissionless systems. They address GDPR and HIPAA compliance issues during GPU onboarding, data loading, data sharing, and result sharing stages.
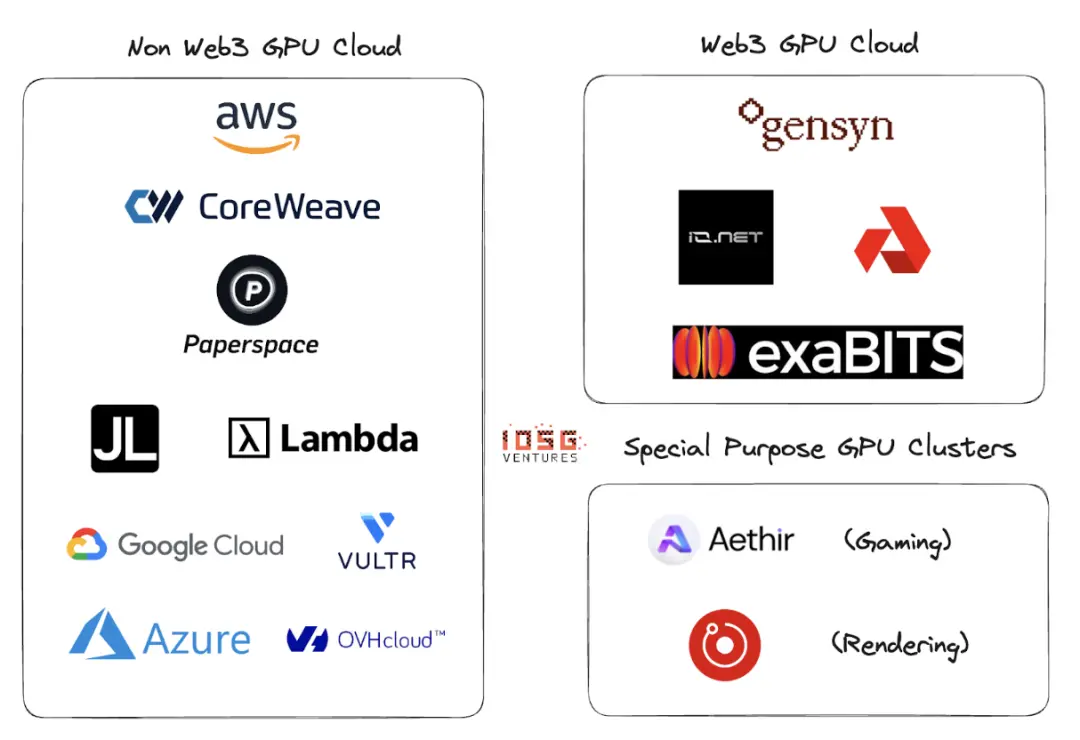
Ecosystem
Gensyn, io.net, Exabits, Akash
Risks
- Demand risk
I believe top LLM players will either continue to accumulate GPUs or use GPU clusters such as NVIDIA's Selene supercomputer, which has a peak performance of 2.8 exaFLOP/s. They will not rely on consumer or long-tail cloud providers to aggregate GPUs. Currently, the competition among top AI organizations is greater in quality than in cost.
For non-heavy ML models, they will seek cheaper computing resources, and token-incentivized GPU clusters based on blockchain can optimize existing GPUs while providing services (assuming that these organizations prefer to train their own models rather than use LLM).
- Supply risk
With significant capital investment in ASIC research and inventions like Tensor Processing Units (TPU), the GPU supply issue may resolve itself. If these ASICs can provide good performance: cost trade-offs, existing GPUs hoarded by large AI organizations may re-enter the market.
Does blockchain-based GPU clusters solve a long-standing problem? While blockchain can support any chip other than GPUs, the actions of the demand side will entirely determine the direction of projects in this field.
Conclusion
Fragmented networks with small GPU clusters will not solve the problem. There is no place for "long-tail" GPU clusters. GPU providers (retail or smaller cloud players) will tend towards larger networks because the incentives of the network are better. The functionality of a good token model and the ability of the supply side to support multiple types of computing will be key.
GPU clusters may see a similar aggregation fate as CDNs. If large players want to compete with existing leaders like AWS, they may start sharing resources to reduce network latency and geographical proximity of nodes.
If the demand side grows larger (more models to train, more parameters to train), Web3 players must be very proactive in the business development of the supply side. If too many clusters compete from the same customer base, fragmented supply (rendering the entire concept ineffective) will occur, while demand (measured in TFLOPs) grows exponentially.
Io.net has emerged as a winner among many competitors with its aggregator model. They have already aggregated GPUs from Render Network and Filecoin miners, providing capacity while also guiding supply on their platform. This may be the winning direction for DePIN GPU clusters.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







