Source: Synced

Image Source: Generated by Wujie AI
For the computer vision field in 2023, the "Segment Anything Model" has become a highly anticipated research advancement.
Meta's "Segment Anything Model (SAM)" effect released in April, which can automatically segment all content in the image.
The key feature of Segment Anything is the prompt-based Visual Transformer (ViT) model, which is trained on a visual dataset SA-1B containing over 10 billion masks from 11 million images, capable of segmenting any object on a given image. This capability makes SAM a foundational model in the visual field and also applicable in areas beyond vision.
Despite the advantages mentioned above, the ViT-H image encoder in SAM has 632 million parameters (prompt-based decoder only requires 387 million parameters), making the computational and memory costs of using SAM for any segmentation task high, posing a challenge for real-time applications. Subsequently, researchers have proposed some improvement strategies: distilling the knowledge from the default ViT-H image encoder into a small ViT image encoder, or using CNN-based real-time architectures to reduce the computational cost for the Segment Anything task.
In a recent study, Meta researchers proposed another improvement approach—utilizing SAM's Mask Image Pretraining (SAMI). This is achieved by using the MAE pretraining method and the SAM model to obtain a high-quality pretraining ViT encoder.

- Paper link: https://arxiv.org/pdf/2312.00863.pdf
- Paper homepage: https://yformer.github.io/efficient-sam/
This method reduces the complexity of SAM while maintaining good performance. Specifically, SAMI uses the SAM encoder ViT-H to generate feature embeddings and trains a lightweight encoder for mask image models, thus reconstructing features from SAM's ViT-H rather than image patches, producing a universal ViT backbone for downstream tasks such as image classification, object detection, and segmentation, etc. Subsequently, researchers fine-tune the pretraining lightweight encoder using SAM's decoder to complete any segmentation task.
To evaluate this method, researchers adopted a transfer learning setting for mask image pretraining, i.e., first pretraining the model on ImageNet at an image resolution of 224 × 224 using reconstruction loss, and then fine-tuning the model on the target task using supervised data.
Through SAMI pretraining, ViT-Tiny/-Small/-Base models can be trained on ImageNet-1K and improve generalization performance. For the ViT-Small model, after 100 fine-tuning on ImageNet-1K, the Top-1 accuracy reached 82.7%, surpassing other state-of-the-art image pretraining baselines.
Researchers fine-tuned the pretraining models on object detection, instance segmentation, and semantic segmentation. In all these tasks, the method in this paper achieved better results than other pretraining baselines, and more importantly, significant gains were obtained on small models.
The paper's author Yunyang Xiong stated: The EfficientSAM proposed in this paper reduces parameters by 20 times, while running 20 times faster, with a difference of only 2 percentage points from the original SAM model, greatly outperforming MobileSAM/FastSAM.

In the demo, by clicking on the animals in the image, EfficientSAM can quickly segment the objects:

EfficientSAM can also accurately label the people in the image:
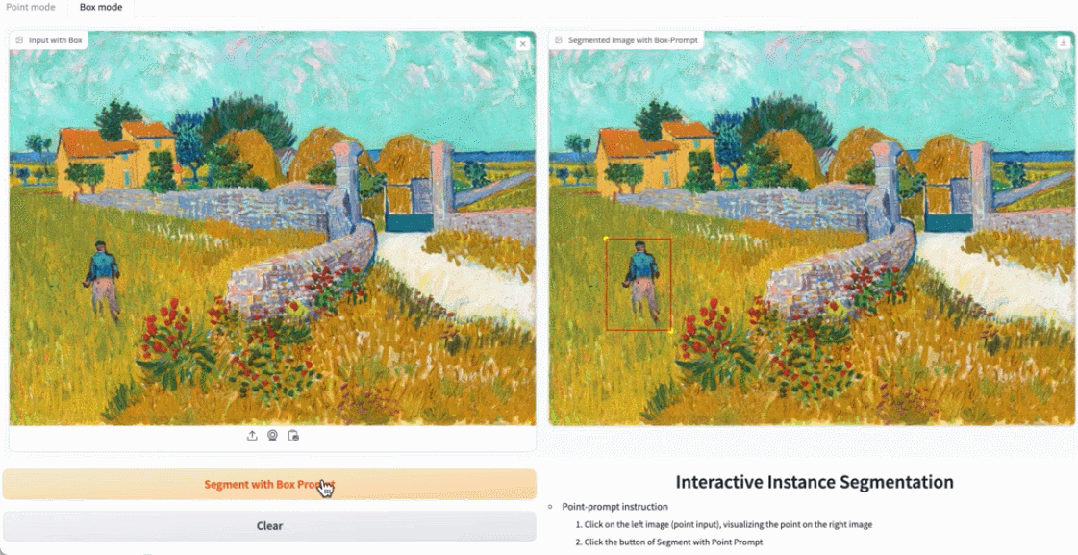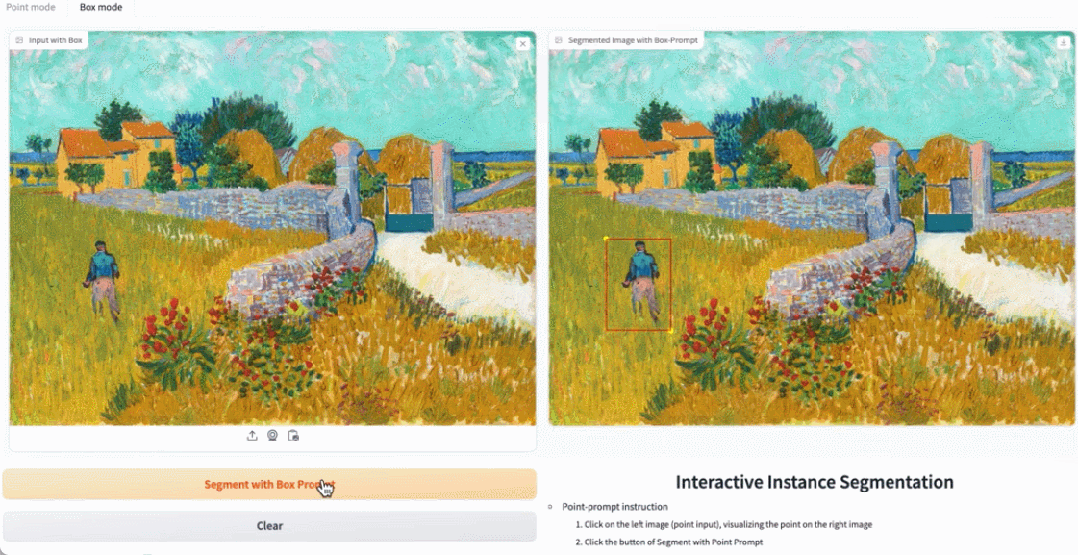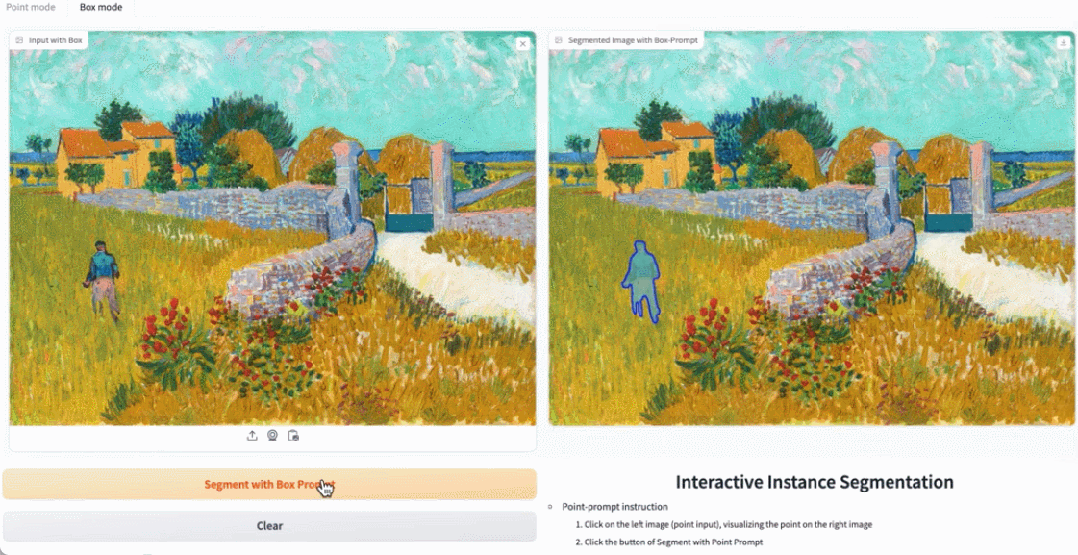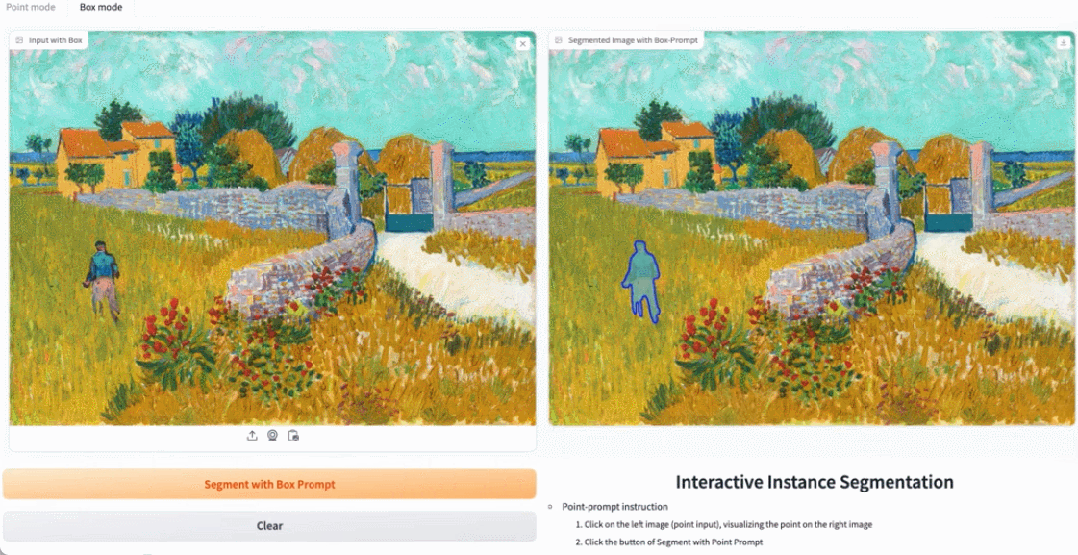
Try it out: https://ab348ea7942fe2af48.gradio.live/
Method
EfficientSAM consists of two stages: 1) Pretraining SAMI on ImageNet (above); 2) Fine-tuning SAM on SA-1B (below).
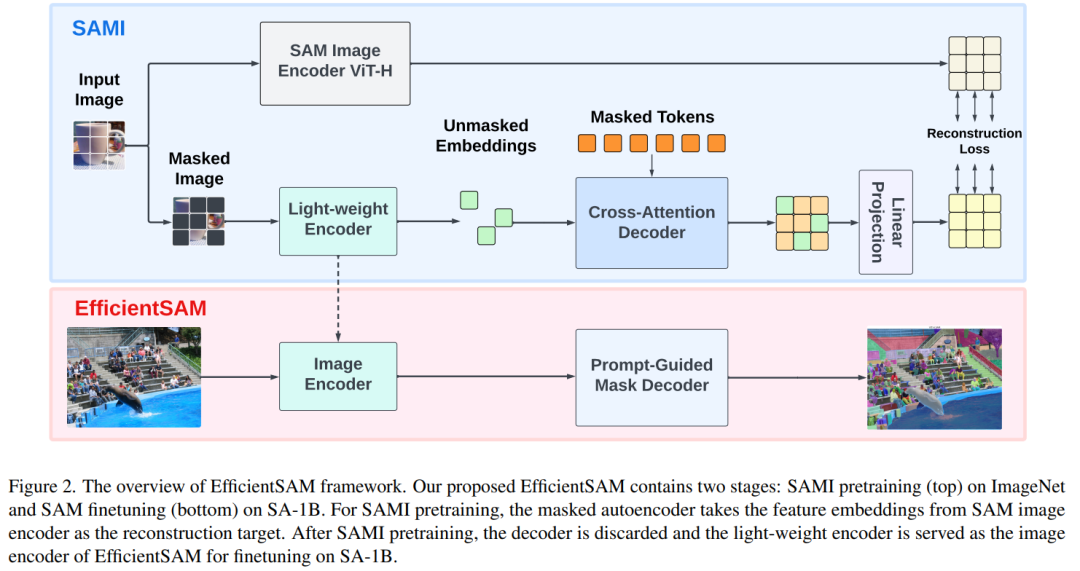
EfficientSAM mainly includes the following components:
Cross-Attention Decoder: Under the supervision of SAM features, the paper observed that only the mask token needs to be reconstructed through the decoder, while the output of the encoder can serve as anchors during the reconstruction process. In the cross-attention decoder, the query comes from the mask token, and the keys and values come from the unmasked features and masked features of the encoder. The output features from the cross-attention decoder's mask token and the output features from the unmasked token of the encoder are merged to produce MAE output embeddings. These combined features are then reordered to the original positions of the input image tokens for the final MAE output.
Linear Projection Head: The features obtained from the encoder and cross-attention decoder are then input into a small projection head to align the features in the SAM image encoder. For simplicity, the paper only uses a linear projection head to address the feature dimension mismatch between the SAM image encoder and MAE output.
Reconstruction Loss: In each training iteration, SAMI includes forward feature extraction from the SAM image encoder and forward and backward propagation processes from MAE. The outputs from the SAM image encoder and the MAE linear projection head are compared to calculate the reconstruction loss.
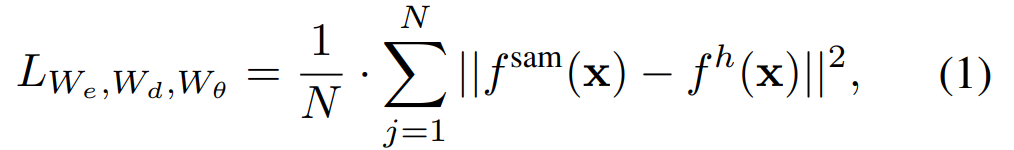
After pretraining, the encoder can extract feature representations for various visual tasks, and the decoder will also be discarded. In particular, in order to build an efficient SAM model for segmenting any task, this paper uses the lightweight encoder pre-trained with SAMI (e.g., ViT-Tiny and ViT-Small) as the image encoder for EfficientSAM and SAM's default mask decoder, as shown in Figure 2 (bottom). This paper fine-tunes the EfficientSAM model on the SA-1B dataset to achieve segmentation for any task.
Experiments
Image Classification. To evaluate the effectiveness of this method in image classification tasks, the researchers applied the SAMI concept to ViT models and compared their performance on ImageNet-1K.
Table 1 compares SAMI with pretraining methods such as MAE, iBOT, CAE, and BEiT, as well as distillation methods such as DeiT and SSTA.
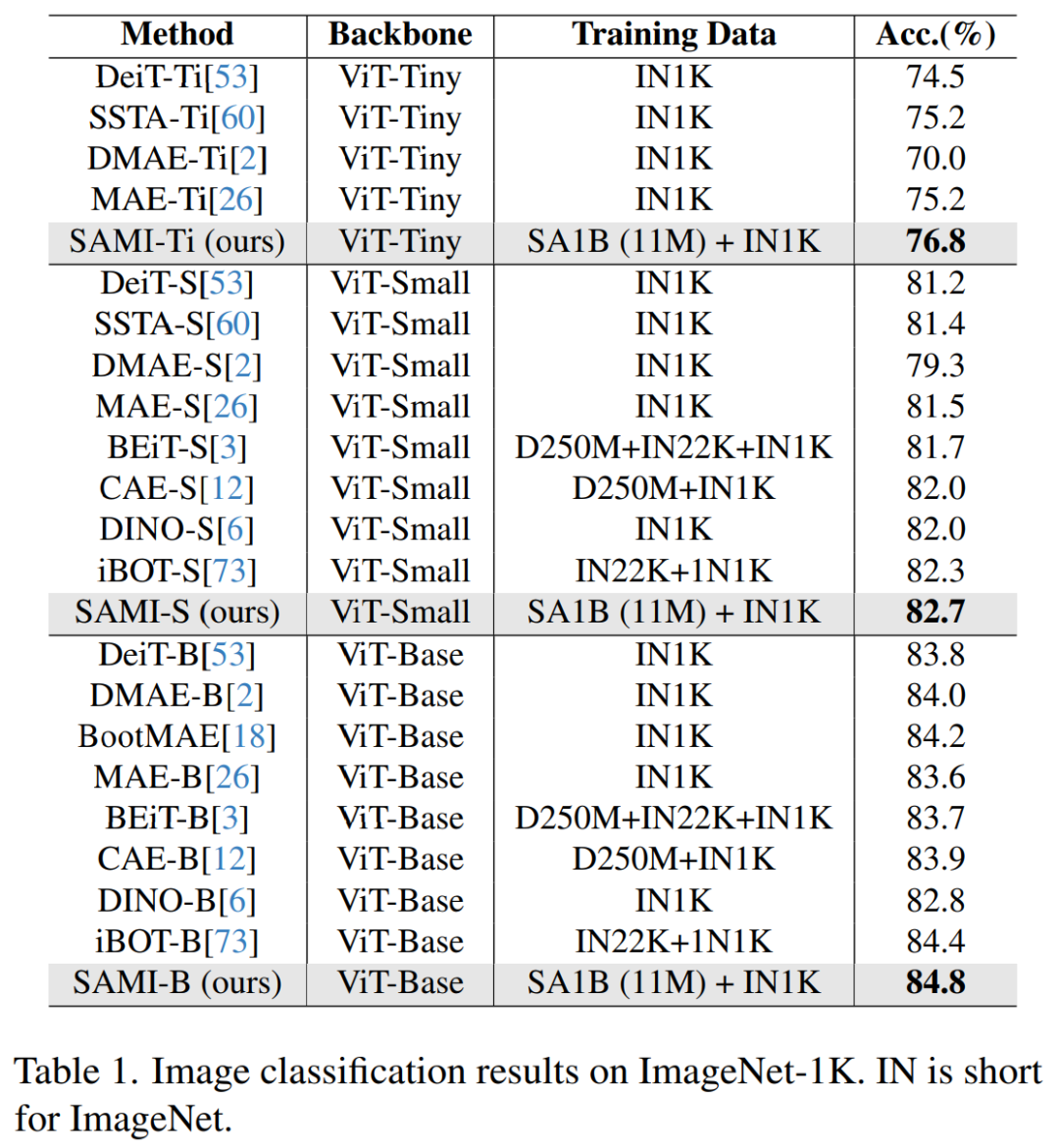
SAMI-B achieves a top-1 accuracy of 84.8%, higher than the pretraining baselines, MAE, DMAE, iBOT, CAE, and BEiT. SAMI also shows significant improvements compared to distillation methods such as DeiT and SSTA. For lightweight models like ViT-Tiny and ViT-Small, SAMI results in significant gains compared to DeiT, SSTA, DMAE, and MAE.
Object Detection and Instance Segmentation. This paper also extends the ViT backbone pre-trained with SAMI to downstream object detection and instance segmentation tasks, and compares it with baselines pre-trained on the COCO dataset. As shown in Table 2, SAMI consistently outperforms other baselines.
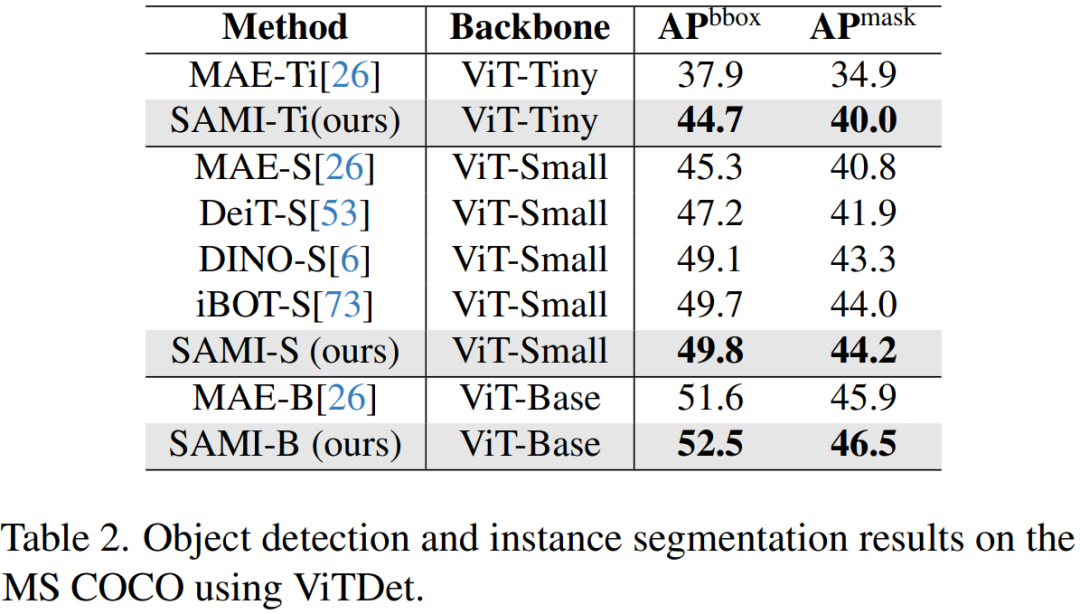
These experimental results indicate that the pretraining detector backbone provided by SAMI is very effective in object detection and instance segmentation tasks.
Semantic Segmentation. This paper further extends the pretraining backbone to semantic segmentation tasks to evaluate its effectiveness. The results in Table 3 show that using the SAMI pretraining backbone, Mask2former achieves better mIoU on ImageNet-1K compared to using the MAE pretraining backbone. These experimental results validate that the proposed technique can generalize well to various downstream tasks.
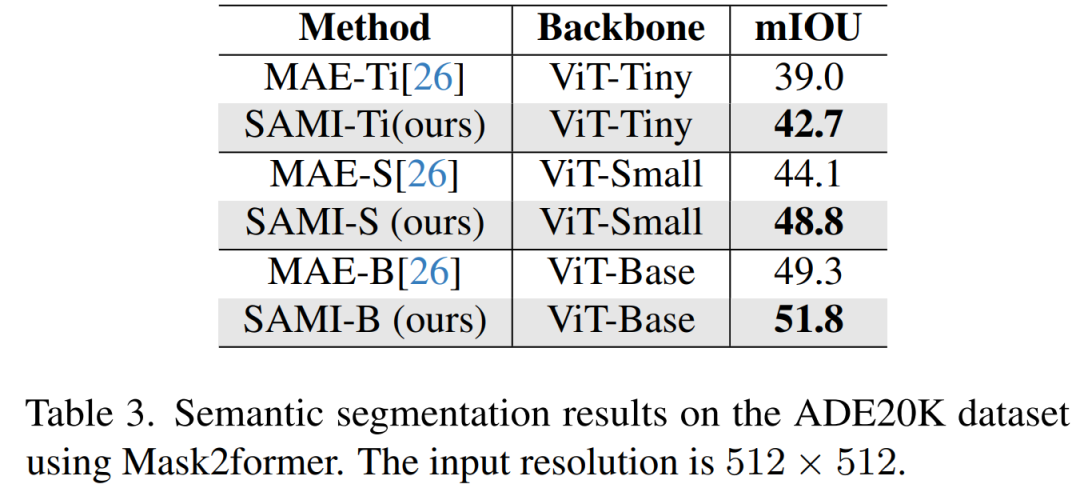
Table 4 compares EfficientSAMs with SAM, MobileSAM, and SAM-MAE-Ti. On COCO, the performance of EfficientSAM-Ti is better than MobileSAM. EfficientSAM-Ti has SAMI pretraining weights and also performs better than MAE pretraining weights.
Furthermore, EfficientSAM-S is only 1.5 mIoU lower than SAM on COCO box, and 3.5 mIoU lower on LVIS box, with a 20x reduction in parameters. The paper also found that compared to MobileSAM and SAM-MAE-Ti, EfficientSAM also performs well in multiple click scenarios.
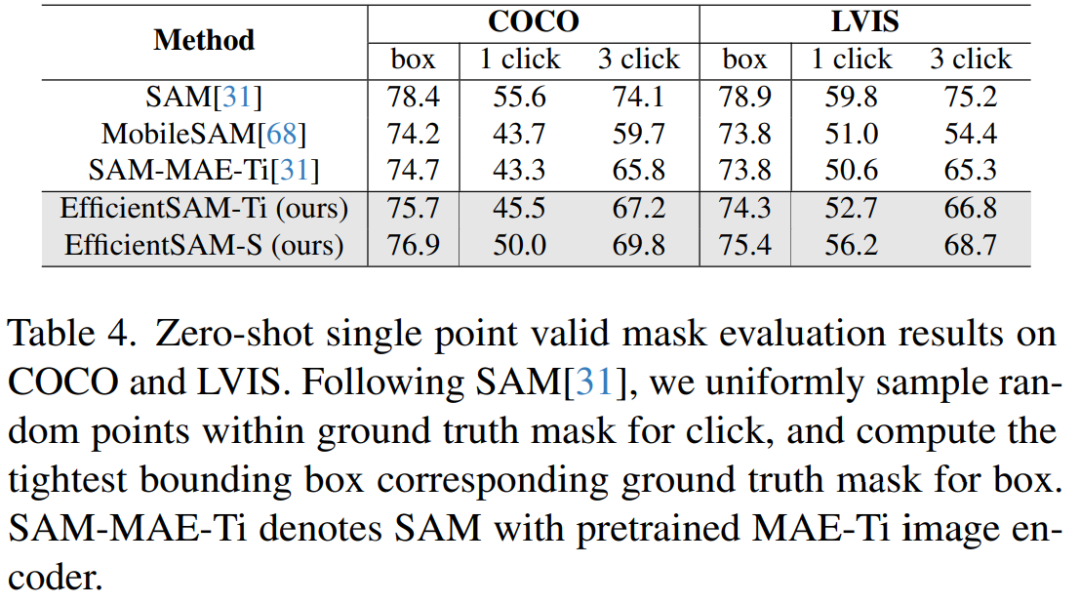
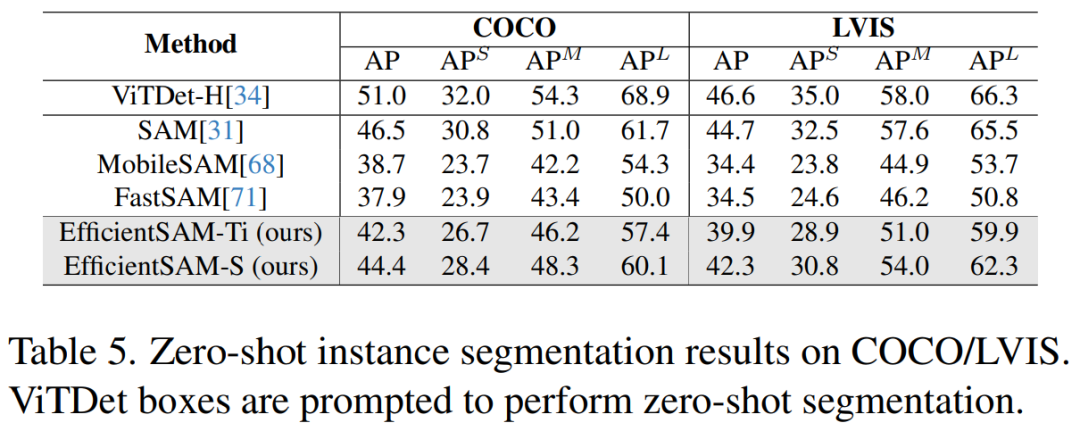
Table 5 shows the AP, APS, APM, and APL for zero-shot instance segmentation. The researchers compared EfficientSAM with MobileSAM and FastSAM, and it can be seen that EfficientSAM-S achieves over 6.5 AP on COCO, and 7.8 AP on LVIS compared to FastSAM. As for EffidientSAM-Ti, it still outperforms FastSAM by a large margin, with 4.1 AP on COCO and 5.3 AP on LVIS, while MobileSAM achieves 3.6 AP on COCO and 5.5 AP on LVIS.
Moreover, EfficientSAM is much lighter than FastSAM, with 9.8M parameters for efficientSAM-Ti, while FastSAM has 68M parameters.
Figures 3, 4, 5 provide some qualitative results to supplement the reader's understanding of the instance segmentation capabilities of EfficientSAMs.



免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







