来源丨腾讯科技
采访、编辑丨郭晓静
文字整理丨赵杨博

图片来源:由无界版图AI工具生成
这不是AI第一次引起热议,早在AlphaGo打败人类棋手的时候,行业就开启过一波“AI是否会取代人类”的恐慌性讨论,但在随后的几年,AI并没有跳出人类对它的一贯认知。直到2022年,这次,AI不但可以和人类流畅地聊天;可以迅速回答人类需要十几分钟才能回答的答案;能迅速检索人类可能几小时才能收集的资料;更能创作出让艺术家赞叹的有“创造力”的绘画。
人工智能公司OpenAI是这场热议中的焦点,它的CEO Sam Altman说:“十年前的传统观点认为,人工智能首先会影响体力劳动,然后是认知劳动,再然后,也许有一天可以做创造性工作。现在看起来,它会以相反的顺序进行。”ChatGPT的上线,颠覆了人类对AI“侵占”人类世界的认知。这场始于硅谷的AI宏大叙事,由于低门槛的参与性,迅速闯入普通人的生活。ChatGPT自2022年11月上线以来,人工智能公司Open AI的估值已经高达290亿美元。科技巨头如临大敌、AI创业公司摩拳擦掌、普通人在与AI的聊天中,玩的不亦乐乎。
同时,一系列问题也被带到了人们的面前:
● 生成式AI技术,是否会带来一场堪比移动互联网的新商业浪潮?
● 这是否会给目前的商业格局带来巨大的改变?
● 生成式AI赛道,到底有哪些商业模式可以挖掘?
● 中国的头部科技企业,抓住这场新的AI浪潮了吗?
● 高端芯片被限,中国还有可能发展自己的AI大模型吗?
腾讯科技对话全球科技创新产业专家、科技投资人,海银资本创始合伙人王煜全,根据他常年对全球科技产业的观察及亲身实践,尝试回答以上难解的问题。这些问题不会有标准答案,但是我们希望能从行业深度参与者的多角度观察中,给关注“生成式AI”的读者,带来一些启发。
01AI生成,必定引起科技巨头的重视
Q1:生成式AI为何引起科技巨头的关注?
王煜全:第一,AI绘画、ChatGPT等应用的出现,让越来越多的普通用户可以使用人工智能。美国经济学家Diego Comin表明一个经济体的强弱不取决于它引入先进科技的速度,而是取决于使用先进科技的深度。
比如互联网,不发达国家引入互联网的速度很快,但是引入互联网后使用比例低。科技之所以能推动社会发展,是因为科技能被广泛使用,广泛地提升效率或者带来新的能力,如果只是有少数人使用,它提升效率或者带来新的能力会很小。所以OpenAI在商业上讨论的热度是晚于用户所讨论的热度,这是比较少见的,所以后来人工智能话题火热,是顺理成章,水到渠成的。
第二、生成式AI类应用给未来带来巨大的想象空间。我认为生成式AI还有很多模式创新的空间,远没有达到最高点。虽然现在已经有人探索了AIGC的某些使用模式,但这远不是终点。特别像当年的互联网,从最早的门户网站到网游,再到电商,再到如今短视频的爆火,一直在迭代发展。

全球首例AIGC技术辅助商业化动画片《犬与少年》,动画场景由AI绘制
而OpenAI的技术依靠自己设计的模式就能够做出更多的应用,甚至说做出更大更成功的创业公司,这就是有想象空间。
之前的人工智能创业公司和创始人都是人工智能专家,现在有了AIGC、Chat GPT,我们可能逐渐会发现,很多人工智能创业公司的创始人可以不是技术专家。他可以先有一个idea,然后再去找某位CTO帮他实现,而且CTO也比较好找,因为有了这些基础技术,帮他实现并不难。这时候人工智能领域的创业就会变的活跃,也就是所谓的万众创新。这也是它被热议的原因之一,人们会认为这件事离“我”很近,除了能够日常使用以外,更主要是也许“我”就能创业,这其实降低了创新门槛,让更多人能够参与,会使得科技创新能够加快市场渗透,能够使创新的价值被凸显出来,这都是特别有意义的。
Q2:如何看待老牌科技巨头微软和OpenAI的合作?
王煜全:第一,降低算力支出:对Open AI来说,算力是很大的成本,因此,它选择和微软合作可以大幅降低算力支出;第二,未来云计算、人工智能、大数据将会深度结合,而大量的人工智能应用是基于云进行部署,算力也由云来提供。OpenAI想要合作肯定会考虑选择三朵云(谷歌云、亚马逊云、微软云)的其中一朵,最后和谁合作?第一肯定是选择合作愿望最强烈的,之前微软就投资了Open AI,也表明了合作的意愿。
第三,从未来发展看,三朵云中亚马逊云的客户种类比较单一,主要针对电商客户,而谷歌在开拓商业客户上做的不够好,虽然谷歌的DeepMind在人工智能领域的研究非常深入,但商业化落地并不出色。微软是商业化做的最好的,且有大量的企业客户,如今微软能在“三朵云”中实现后来居上,就在于大量的企业客户上云。这对OpenAI来说也很重要,产品和服务能让客户最终使用和买单才是关键,能有大量用户使用,进而开拓市场,才是双赢。
我们也看到,OpenAI与微软的合作不排他。OpenAI的开放API,意味着创业者只要有Idea,就可以去做相关的创作工作,对微软来说这也是非常大的突破。回顾微软的发展历程,它并没有最早进入互联网行业,但是依靠全面网络化又追上了其他互联网企业的脚步。在这波人工智能浪潮中,微软也比谷歌云和亚马逊云都稍慢,但现在依旧又追上前者的步伐。现在在三朵云中,微软隐隐有胜出的趋势,原因也很直接,就是在应用的上的结合更好。亚马逊最早,谷歌的技术能力最强,但是它们在与应用结合上都没有微软做的那么出色。OpenAI整合进其他应用将是必然趋势,把更多的人工智能与其他应用结合,让更多的人享受到人工智能带来的便利,让更多有创意的人参与其中,整个市场才会更加活跃,所以从应用上讲这是极大的拓展。
另一方面微软也很聪明,它向OpenAI追加投入100亿美元投资,但是这些投资需要OpenAI在合作后,如果盈利首先给微软分红偿还投资并置换部分股权,如果OpenAI没赚钱,那微软仅仅是占有原有股份,不需要创业者赔付。这是一种双赢的设计。
02现在的生成式AI,有点像互联网的瀛海威时代
Q3:在生成式AI领域,有没有观察到逐渐清晰的商业模式?
王煜全:有些苗头。现在有点像当年互联网刚热起来的时候,当时有家公司叫做瀛海威,可以说是“启蒙”了中国老百姓的网络意识,许多人伴随着瀛海威走进互联网世界。但瀛海威和门户就差一步,门户的实际商业影响比瀛海威高很多。现在有点处于中间阶段,人们所看到的还是BBS,至少还没到门户阶段,这就意味着可能有非常大的新模式,在今明年两年出现。
我们对原理的总结,未来最大的模式应该不是叫“AIGC”而是叫“AIGS”,因为C(Content)是有局限性的,即使AIGC的能力再强大,从C的角度来讲,可能同一组关键词,出来的C是类似的,并不能满足人们的个性化需求。而真正最大的价值是能够将它变成一种服务(Service),想要什么定制什么,这样人人得到的东西都不一样,人人的需求都能被个性化地满足,这也符合我们所讲的服务规模化时代的到来,这里的规模化服务,指的是“人工智能的服务”(而不是人的服务)。因为人工智可以复制“服务规模化的个性化”。
高端服务的特点就是个性化,首先是“我”为“你”定制,所以叫高端,而且要有设计,内容要呈现一定的复杂度。就像ChatGPT与你的互动,像ChatGPT写出文章,它都有足够的复杂度,足够懂你。
比如,2022年11月28日,26岁的纽约华人艺术家米歇尔·黄(Michelle Huang)的推特小火了一把。她把自己10年的日记上传给了GPT-3,训练出来了一个小米歇尔的AI分身,并将她们之间的聊天截图放到了推特上,消息一发布就引发了不小的关注,一周内点赞已经超过5.1万次。聊天内容非常治愈,米歇尔·黄形容这段经历就像一面镜子,帮她找回了很多自己身上没有改变的东西,也让她发现了很多已经遗失的地方。这就像真正的知己,理论上讲知己可以自我疗愈,当“我”有什么问题、委屈、困难,知己比我还了解自己,那未来这种“数字分身”可能变成一种服务,而且它的特点是“你”用个人的数据去喂养它,就能形成对你个人的深度理解。

用户在这个时代需要的永远不是产品而是服务,需要的是规模化的服务,因为有人工智能、有机器人,企业的规模化服务能力能够做到个性化,用“我”的能力来解决“你”的需求:如何能够个性化地和顾客互动,如何能在这个性化互动过程中提供高端的服务,可能在未来生成式AI领域商业潜力巨大。
Q4:生成式AI的应用探索主要还是集中于“科技圈”及有专业技术的人员,是否意味着普及门槛依然比较高?
王煜全:我认为不是技术门槛的问题。凡事总有过程,技术人员本身离新技术较近。20年以前,硅谷的一个很著名的营销专家Jeffrey Moore,提出了“跨越裂谷理论(Crossing the Chasm)”,他把市场中的人分成五类,最领先的一类人叫创新者(Innovator);另外一类是早期采用者(Early Adapter),他们特别愿意应用新产品,使用新产品,这两类人就是高科技产品的第一批用户。
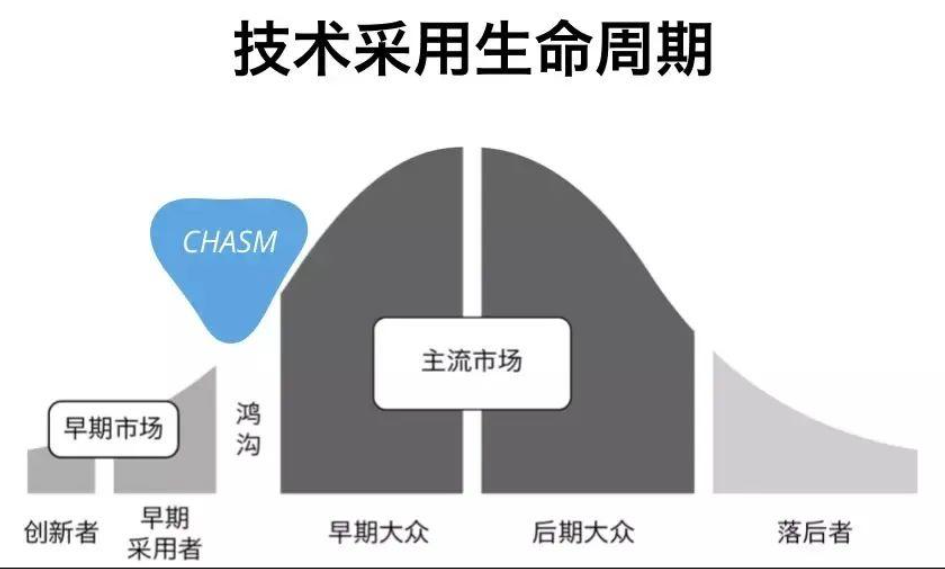
这两类人对于新事物会立即使用,可能这时候产品体验有很大瑕疵,但是他们不会害怕使用,看中的是新功能、新能力。所以很多高科技产品一上来就有一个高速的市场增长,是因为这批用户。
但是后面的主流用户分成早期主流、晚期主流和拖后腿的用户,后面三类用户和前面这两类用户的行为习惯很不一样,他不会因为你的新功能就去使用你,而是会看我的使用体验是不是得到满足,是不是很舒服。如何让主流人群用上“ 你”的应用,这是最主要的。有些高科技公司,在获得第一波高速增长的时候就扩产,实际上还没获得主流人群的认可,这时候扩产,实际上就加速了企业的财务问题,甚至企业可能破产。
所以说好的CEO,往往都是Early Adopter(早期采用者)。他不一定是创新者,例如马云不是创新者,互联网不是他发明的,但是他是早期采用者,他知道互联网的优势就是“你”能在网上做电商,但他也知道互联网的劣势是电商没信用证明,所以后来他创办了淘宝,通过淘宝先学习eBay模式,在实践过程中发现eBay没有解决的诚信问题。为了解决诚信问题引入支付宝,将平台作为第三方中间人,等到买方确认以后再付款,这一模式便解决了诚信问题。
所以阿里巴巴后来的成功不是因为它的技术多么领先,而是因为它在技术应用中解决了应用痛点,这是很正常的现象。大多数人为什么不是“马云”,因为最早接触技术的人往往是技术人员,而大多数技术人员只会使用技术,不知道如何解决问题,把有问题的技术变成普及的技术。
什么人能做这件事?是非技术的使用者。当他们不能通过技术去解决自己的问题时,只好想办法解决,那时候“你”能解决这个问题,它就有了普及性,所以当使用者说因为OpenAI的技术还不是特别的大众化,所以热议的第一批人一定是技术专家,但现在已经有了大众化的苗头,因为很多热议的人已经不是技术专家。
所以OpenAI的ChatGPT已经对公众将门槛降到非常低,这时候公众再不使用,就不是因为有门槛的问题,而是因为大多数公众不知道紧跟前沿科技,不知道做早期采用者,不知道要实时去体验使用,只觉得这离“我”很远,因为科技在普通人眼中,很容易下意识认为“搞不懂”,这其实不是真的搞不懂,而是理念问题、心态问题。
这个问题会逐渐得到扭转,当有成功案例产生,当大众看见应用可以这样使用的实际例子,当非技术人员也能玩转科技,便会有更广泛的群体参与进来,所以至少我现在认为已经不是技术门槛的原因。
03有些专家纠结ChatGPT“是否有技术突破”其实暴露了无知
Q5: AIGC、Chat GPT、AlphaFold,经常被放在一起谈论,他们是否可以被划为同大类的创业方向,能否被称作“AI+”?
王煜全:我认为可以。它们都是将AI的能力进行输出,当然AI也有N种能力,可以文字输出,可以图片输出,可以音乐输出,也可以做内容修改、内容优化,所以在生成式AI的技术浪潮下,会有各种各样的新功能出现,这些功能都会被当成一种能力提供出来。
任何的新的技术突破以后,都要有一轮模式创新,使得技术突破的优势能够被发挥,但模式创新的前提是要解决“技术容易被得到”的问题,所以现在我认为OpenAI做的特别好。但AlphaFold以及其他类似的,坦白讲我认为它们确实有欠缺。
OpenAI需要和微软谈合作才能用它的云,但Google本身有云,从这方面来讲,Deepmind的先天优势是更大的,而且它也有先进的科研成果。但是能让普通用户广泛调用的应用基本没有,即使出现了当年下围棋的AlphaGo,但许多人并没看到DeepMind在普及中做出贡献,所以这波生成式AI的热潮,我认为核心就是看到人工智能的某些功能有新的突破。剩下的工作就是如何让功能被广泛使用,带动应用的大范围普及。
Q6:有专家认为ChatGPT、GPT-3没有技术创新,底层的依旧是Transformer语言模型,如何看待这种观点?
王煜全:互联网刚开始火热时,也有人认为互联网不是技术创新,最早的技术创新是Tim Berners-Lee(蒂姆·伯纳斯·李,世界互联网发明者),将互联网贡献给大众使用。对公众来说纠结技术创新意义不大,关键是使用。当然对这件事的讨论是有意义的,为什么?我们要理解什么是技术创新,因为我们强调创新要端到端,从实验室研发出来最后要被公众广泛使用,真正好的创新不是你能够向大众示范多么酷炫而是能够被广泛使用。
很多好的技术都是在专利已经过期,没有什么新技术发明突破的情况之下,有人找出应用痛点、解决应用痛点后从而形成普及。比如说,特斯拉有什么技术突破?锂电池不是它发明的,电池组管理很多时候并不是技术,我们可以发现特斯拉赢在制造上,批量制造依然能够保持便宜的价格、很好的产品体验。但制造能够提升也是一种“技术”。所以不能片面理解“专利”才是技术,“应用创新”也是人类经验知识的积累,“不能专利化”的经验积累从一定意义上讲更重要。大多数创新的普及,发明人是一批,推向市场的是另一批人,这是产业界的常态。
如果非要纠结“是不是真的有技术突破”,那么科技创新的过程都应该归科研人员来完成,但实际上科研人员根本不擅长将科技创新推广到社会。他们擅长做新的东西,但是新的东西要被社会接受,要Early Adopter(早期采用者)去发现,在使用当中发现痛点问题,然后去解决。新技术出现,原理突破是Innovator(创新者)做的事,就如同当年锂电池出现,它装车续航才到达100公里,需要工程师、技术人员来做性能调优,最后才能被社会接受,这些都不是科学家能完成的。
真正为科技推广到社会,做出最大贡献的不是科学家,而是科技企业家。比如马斯克,他不是技术人员,但是他是Early Adopter,他知道电动车怎样做,才能让社会广泛接受。做出这种论断的所谓专家,恰恰是暴露了自己的无知,对科技创新如何推广到社会中是无知的。他以为只有科学家就管用了,其实是远远不够的,只有科学家的话,大量的科研成果,会困于高校,无法被社会采纳。
马斯克说话有时候大嘴巴,但是有段话说的很对,英文有个词叫“Rocket Science”,但是没有“Rocket Scientist”,因为火箭的原理早就被发明,Space X的成功不是基于科学的突破,而是基于技术的完善,性能调优的完善,完成这些的叫做“Rocket Engineer”,真正推动火箭被普及的不是火箭科学家而是火箭工程师。这就是科技企业的意义,从这种意义上讲,OpenAI是标准的科技企业,技术未必是它原创,但它能够做到极大的普及,恰恰应该感谢OpenAI,使得科学家的研究成果没有白费,能够被社会采纳。

Q7: 有论断说“类似于Transformer的这些基础模型是未来的通用技术,就好像蒸汽机、印刷机、电动机,这种说法对吗?
王煜全:关键在于怎么理解Transformer,本身它不是通用智能,因为它不是万能的,它是一个通用训练模型。
首先,以前对每一个领域的人工智能要先建立训练模型,然后再做训练,建立训练模型是最难的,必须是人工智能的技术专家才能做到。而现在训练模型是只要用不同的数据训练就会成为不同的“专家”,但是它依然不通用,意思就是用围棋训练它,它是围棋专家,用象棋训练它,它就是象棋专家。训练它下象棋,它就不会下围棋。但最起码门槛降低了,训练工具是同一个,所以Transformer的价值在这儿,在一定程度上降低了门槛.
其次,用通用训练工具做通用数据的训练后,提供给大众的能力,就是今天的GPT-3,它每年一次对互联网的全体数据做训练,训练完成后,任何问题就已经有了答案,等于它将互联网当成一个大数据集,这是特别了不起的地方。
人类的核心价值就在于我们对知识的汇集、共享和传承。我们所提的“积木式创新”,人类每个创新就像一块新的积木,新老积木如何叠加在一起形成新的技术,那就是靠知识的汇集、共享和传承。我们原来有个研究是竞争情报,Competitive Intelligence,里面有一个说法是,人类知识的大多数是隐性知识,存在于某个人的头脑中没有显性出来。但是当有了PC之后,人类知识的显性化加快了。过去人类用“写书”的方式,进行知识显性化的速度是比较慢的,而且还经常有图书馆被烧这种事情发生。但是互联网时代之后,人类用网络做记录,隐性知识显性化的速度大大加快。
OpenAI可以自动去生成一段文字,这不是新的生成,而是对整个互联网知识的提炼,迄今为止人工智能是没有创造力的,人工智能没有创造新知识,人工智能只是更好的把旧知识综合和呈现出来。也就是如果没有人类知识,那GPT-3就是“傻子”。它为什么比每个人都聪明?它下围棋为什么能赢李世石?因为人类所有的围棋经验全部汇集给它。
Q8: 未来AI获得大爆发和普及的核心是模型还是大数据?
王煜全:当然都需要具备。但最主要的是,全民的认知。我们看到互联网后来的繁荣依赖于大众对互联网的认知越来越丰富,应用越来越普及、参与者越来越多。现在最起码OpenAI树立了先例,告诉大众人工智能可以有“新玩法”,人人都可以体验使用人工智能,但体验时现在还是规定动作——自然语言问答,未来可能会出现更多的自选动作。
所以我的理解是,模型很重要、大数据很重要,但是更重要的是全民的使用、尝试和创新。门槛降低后,人人都获得了创新的资格。它就会从量变到质变,人类当中永远有聪明人,很多科技发明、应用的出现并不是有目的的发明,而是某个人某一天的“灵光一现”。当大众一起参与到这个异想天开的盛筵,就会有更多有意思的结果出现。
04高端芯片被限制,我国如何发展自己的“AI大模型”?
Q9:如何看到国外的“大模型”的开源,为什么我们还没有自主大模型?我国有没有必要去发展自己的“大模型”?
王煜全:中国有必要建立一个自己的大模型。一方面中文环境和英文不同,基于中文环境,中国自己建立会有更好的表现。其次建立大模型本身难度也不大,实际上相关学术论文发表后,基本知道怎么落实,所以无外乎是如何去实践的问题。
至于大模型的落地效果,有一部分是因为早期投入的原因,云计算的成本是巨大的,考验的是投资者和企业家的魄力。中国自己的大模型能做,也需要做。我认为至今中国没有做出来的原因不是因为能力问题,也不是因为模型本身的问题,是因为我们的开放性问题,很多时候不愿意开放,而不开放恰恰是不能进步的核心原因。
早期OpenAI里有各种笑话,有各种愚蠢的问题,但是把愚蠢暴露出来,把错误暴露出来,慢慢纠正就会越来越好。但如果怕说错话就不张嘴,那人工智能就不能学会语言。就好像孩子学习语言,会说错很多东西,但是你去纠正,他慢慢就说对了。人工智能最大的特点就是它是在学习中完善,特别看重反馈。OpenAI其实很了不起,他把工具免费提供给大家,让大家做各种尝试,即使早期顶了很多骂名,但是在这个过程中,它不断地成熟起来。中国行业的头部企业开放性都不够,舍不得把实验室成果开放出来给大家用。一方面免费开放,算力成本会提高,你要为公众的免费使用买单;但是其实反过来,公众也是在帮你打磨产品的完善性,用一种众包的方式帮你完善产品。
另外,就是所谓的IT传统。OpenAI本身,是基于整个IT的开放传统。一直以来,都会有人(企业)站出来登高一呼“你们来使用吧”。中国这种开放的传统,相对来说就弱很多,行业中没有企业站出来登高一呼,而是闷声自己研究,和别人的合作性比较弱,所以造成我们的普及性差很多。
OpenAI的火热,其实也给中国的头部科技企业敲响了警钟,其实我们的头部企业也都在搞,但是大家都喜欢放在后台搞,搞出来之后炫耀一下。但是老百姓无法参与,“藏在深闺”的高科技到最后反而很可能落伍,只有大家都广泛参与你的黑科技打磨,才能建立更多的业务模式。基于OpenAI的创业慢慢都已经成规模了,这是很多企业特别希望看到的状态,基于我的平台创业,我的平台就丰富、活跃。可以说,我们的头部科技企业已经错过了第一波,或者说是晚了半拍,能不能尽快赶上来,我觉得这是非常重要的。
Q10:如何理解开源?OpenAI的开源可以和安卓的开源类比吗?我们常说苹果的生态它是封闭的,但是基于苹果的平台,也生长出各种各样的应用。
王煜全:“开源”和“应用功能的自由调用”是两回事,我们其实更在乎的不是开源,而是功能的自由调用。就是包括现在大量的OpenAI的使用,其实不是基于开源,你可以认为搭建ChatGPT平台是基于开源的程序,但搭建的整个过程中会有很多knowhow,所以很多公司并不会把整个GPT如何搭建、如何运营的knowhow公布。
那严格来说 ChatGPT平台就不是开源的,但这不妨碍我去大量使用,就相当于我们都知道苹果平台不开源,但不妨碍有大量使用,只要符合两个前提即可。第一个前提是用户数量大,第二个前提是能够允许开放调用功能,在用户数量足够大的平台上去调用功能,去实现一个应用,就有足够多的用户能够受益。
那它的开放性就足够,所以我们真正强调的是开放性,而不一定非得强调开源。开放性现在意义更大的叫开放调用,更多的开发者能够去调用,把平台的功能变成他的应用的一部分,平台的功能实现实际价值,那就有更多大量的开发者会主动的将你的功能植入到自己的应用中,这个就成立了。
Q11:中国的高端芯片被限,而发展AI大模型需要巨大的算力支持,这是否也封死了中国AI行业的未来发展?
王煜全:现在公众有两个声音,一个声音是中国芯片落后,另一个声音是我们需要在芯片领域独立自主。自主创新芯片产业口号已经有20年之久,期间有各种尝试,最后效果并不理想,再加上随着中美贸易摩擦的加剧,对方采取封锁的手段。过去20年的各种创新努力都没有突破美国对中国芯片卡脖子的限制,这是事实。
造成这一情况的原因是什么?为什么美日荷联盟?因为美日荷早早就联盟,不是今天才联盟。在整个芯片产业诞生之初,美国主导,有少数的日本企业,荷兰的ASML(阿斯麦)以及少数的欧洲企业参与。这就涉及到科技创新的木桶理论。我们都知道传统的木桶理论认为企业不能有短板,后来又讲新木桶理论,企业要有一个长板,然后与其他长板合作,而整个芯片产业生态六七十年代才开始建立起来。
任何新的生态在建设初始阶段没有长板,都是短板,但问题在创新生态之初需要积极参与合作发展,尽管是短板但在与别人合作的产业发展过程中各个短板逐渐的演变成长板,最后的木桶的长板是生长出来的而不是拼凑起来的。
从这个角度就可以知道为什么现在中国做芯片的突破特别困难,因为其它国家的企业在合作中成长。为什么荷兰要听美国的?是在长期合作后互有认知,愿意彼此配合且利益一致。现在的问题在于我们如何去用短板与其他人合作发展?一方面,理论上讲自主创新,慢慢解决问题,但可能会比较慢,因为创新也是需要整个产业生态的协作才能完成,如果只是其中一环而其他协作方不配合,那创新突破就会异常艰难。
机会在哪?芯片产业并没有多少年历史,但是芯片产业到如今又出现新的革命,上一轮科技革命没有赶上,但下一轮科技革命是我们需要关注的,所以讲弯道才能超车。现在我们虽然慢,但是也不用沮丧,因为弯道很多,其中一个弯道就是人工智能。人工智能弯道的特点是什么?它的生态更复杂而不是更简单。过去是单芯片计算的时代,要遵循摩尔定律,如今我们经常谈到“摩尔定律失效了”。比如各企业推出的SOC(系统级芯片),一个芯片组里面有N个CPU,N个GPU,甚至GPU,所以叫异构计算,有通用计算单元和专有计算单元,而且专有计算单元还正在差异化。
比如手机里专门为图像处理,有一个计算单元,专门为视频处理是另一个计算单元,所以就形成一通用带多个专用的组合,这个结构极大提升了效率,降低了能耗,所以它不需要最高的计算速度,就能实现更好的效果,这也意味着在追求单芯片能力上的要求可以降低,不是单芯片最优就是综合最优,这样我国在单芯片上的劣势是不是就可以弥补?
另一方面,中国的优势在哪?能够让更多的大数据应用积极地去和人工智能结合,尤其如今系统芯片有算法固化的特点。理论上讲为某个行业专门训练行业数据,得到经过优化的算法,再把算法固化到硬件、芯片中,用固化的芯片去处理现实当中人工智能问题会更优,最典型的例子就是自动驾驶芯片。特斯拉为什么自主研发驾驶芯片?原因在于自动驾驶所碰到的问题是特异的,如果用大量自动驾驶的数据去训练,然后得到针对自动驾驶优化过的数据,这是最高效的。
中国如何弯道超车?系统芯片异构计算时代,能够号召拥有数据的机构参与预训练,然后与拥有芯片计算架构的公司深度合作,这样芯片的制造水平未必是最好,但芯片训练的模型是最好的,最后整体SOC芯片的系统输出能力是最强的,依然有机会胜出。
一方是芯片企业,一方是人工智能企业,一方是应用能够产生大量数据的应用企业,能够有更多的数据训练模型最后固化到硬件中,那中国就会转劣势为优势。从自动驾驶行业可以看的最清楚。自动驾驶行业有三类企业,一类是自动驾驶整车企业,产生车并且上路产生数据。另一类是芯片公司,第三类主要是人工智能公司。自动驾驶研发公司依靠硬件,通过数据训练硬件软件系统,使得自动驾驶能力提升,最后真正能够实现自动驾驶能力足够优秀。自动驾驶是人工智能的示范性范例,这种模式应该出现在各个行业领域中,任何有足够数据的行业领域都应该以此为范式,那中国就有可能转劣势为优势。
我认为这等于中国借助大量行业数据应用企业的参与来帮助我们在系统芯片层面胜出,不纠结于7纳米,可能48纳米同样够用,绕开单芯片的死局,同时能够使得应用普及,在系统芯片上做和应用的深度结合,形成基于数据优化的算法,固化到芯片行业的解决方案中,将是这一轮芯片竞争的核心。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








