
2026 年 2 月,小红书发布公告,要求 AI 生成合成内容必须主动标识,未标识内容将被限制分发。三个多月后,一份名为guizang-social-card-skill的开源项目出现在 GitHub 上,专门生成小红书 3:4 图文和公众号封面。它的技术路径有一个反常的选择:不用任何 AI 模型生成图像像素,整个画面靠 HTML+CSS 渲染,配图来自 Unsplash 等实拍图库检索。输出的不是“AI 生成图像”,而是一张浏览器引擎光栅化的网页截图。
这个选择对应着一个具体变化。2026 年以来,小红书已上线音画识别模型,通过分析图片像素分布规律和音频特征来判断 AIGC 内容。同期处置 AI 托管账号超 80 万个、AI 造假笔记近 15 万篇。对于需要高频产出图文的内容创作者,用 Midjourney 或 Canva AI 生成的图片,被检测并标记的概率在持续上升。藏师傅的 Skill 选了另一条路:让 AI 做版式决策,把最终像素交给渲染引擎和实拍图库。
这是一次有意识的技术绕行。但这套方案能走多远,取决于平台对“AI 生成合成内容”一词的定义弹性大小。
28 个版式骨架,AI 负责的是排版逻辑而非绘画
藏师傅本名归藏,此前发布过guizang-ppt-skill,同样是面向图文排版场景的 AI 工具。这次的 social-card-skill 定位更聚焦:面向小红书 3:4 图文、公众号 1:1 和 21:9 封面,输出分辨率分别为 1080×1440、1080×1080 和 2100×900。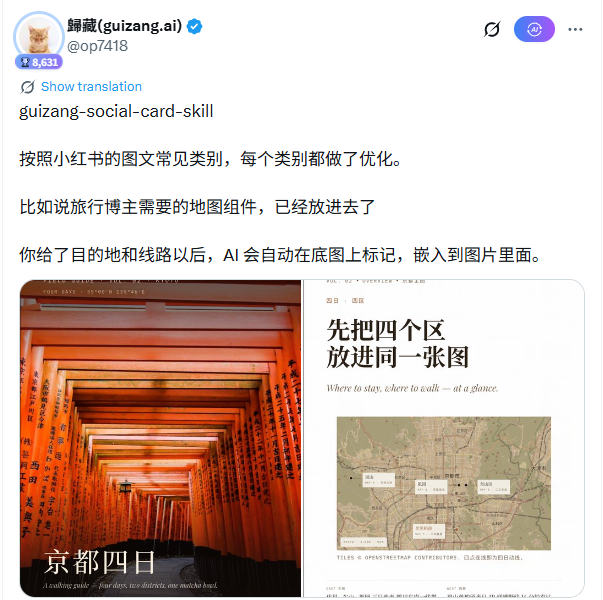
技术架构上,这个 Skill 内置 28 个版式骨架,分为两套视觉系统:Editorial(杂志风格,16 个版式)和 Swiss(瑞士国际主义风格,12 个版式),附带 10 套主题配色预设。用户输入目的地、行程或笔记主题后,AI 负责选择合适的版式骨架、决定文字位置、处理地图标注参数,然后把所有设计决策写成 HTML+CSS。Playwright 渲染引擎接管后续环节,逐页截图输出 PNG。
一个对旅行博主特别有用的组件是地图模块。它使用 MapLibre 加载 OpenStreetMap 的真实瓦片,支持多个地点标记和连线。用户只需提供城市或景点名称,AI 自动生成带标注的底图并嵌入排版。与之配套的图源工作流有明确的优先级:用户提供的实拍照片最优先;没有用户图时,按 Unsplash → Pexels → Flickr CC → Wallhaven 的顺序自动检索配图。
整个流程分七步执行:Intake(接收输入)→ Style & Theme(确定风格和主题)→ Layout Selection(版式选择)→ Asset Prep(素材准备)→ Compose & Render(排版与渲染)→ Deliver & Review(输出与复核)→ Iterate(迭代修改)。每一步都记录在 task 目录的 .poster 文件中。批量出图时运行node render.mjs,Playwright 逐个渲染。另有一个校验脚本validate-social-deck.mjs在真实浏览器环境中测量 DOM 元素,检测文字溢出、字号超出上限、footer 元件碰撞等排版事故。
这套机制的设计目标很清楚:像印刷排版软件一样精确可控,而不是像扩散模型一样自由但不可预测。代价是创意自由度被收束在 28 个格子里。对于依赖个人摄影风格、手绘元素或不规则拼贴的创作者,这些版式骨架提供的不是效率提升,而是设计约束。
使用门槛方面,CLI 版本需要安装 Playwright、Node 环境,同时获取 Claude Code 或 Codex 的 API 权限。另有一个网页版入口xiaohongshu.guizang.ai面向非开发用户,但功能完整度与 CLI 版是否一致,尚未有公开对比信息。开发者发布的几条 X 平台推文和反复更新的 README 说明这个项目仍在快速迭代中。
像素不来自生成模型,但合规不等于长期安全
小红书的 AI 内容检测逻辑,根据公开信息和技术资料分析,核心依赖音画识别模型。这个模型通过分析图片的像素分布规律来判断内容是否来自 AI 生成模型。扩散模型和 GAN 在生成图像时会在像素层面留下特定的统计特征,这些特征与相机传感器捕捉的自然光影、镜头畸变、噪声模式存在差异。音画识别模型的训练目标,正是捕捉这种统计规律上的不一致。
藏师傅 Skill 的规避逻辑建立在一个关键区分上:它输出的图片像素不来自任何生成模型。HTML 渲染引擎对 CSS 样式进行光栅化,产生的像素分布特征更接近浏览器界面截图或桌面排版软件的输出。照片部分来自 Unsplash 等图库的真人实拍素材,这些图片由相机拍摄、经过人工后期处理,不携带扩散模型痕迹。
但这个区分成立的前提,是平台对“AI 生成合成内容”的定义范围恰好卡在“AI 模型生成像素”这条线上。小红书的官方公告用的是“AI 生成合成内容”这个表述,原文覆盖范围并不窄。一旦平台将定义扩展到“AI 辅助设计的程序渲染输出”,或者将 HTML 光栅化图片的浏览器渲染特征纳入识别模型训练集,这套方案当前的技术红利就会消失。
平台有扩展定义的技术基础和治理动机。音画识别模型本身在持续迭代。如果训练数据中纳入大量 HTML 渲染图片与 AI 生成图片的对比样本,模型可以学习区分“浏览器字体渲染的 subpixel 抗锯齿特征”与“GAN 在文字生成时的不规则像素块”。目前没有公开信息表明小红书已启动这个方向的训练,但从模型能力边界看,这种扩展在技术上成立。
更需要注意的事实是小程序托管相关的合规要素。目前没有看到任何官方文档说明该 Skill 接入了模型备案号或完成了相关合规登记。如果平台在内容审核流程中增加对出图工具链的追溯要求,缺乏备案信息可能成为新的拦截点。
API 模板引擎、平台定制工具与 HTML 渲染,正在拉出三条分岔路
观察市面上为社交媒体生成图片的工具,会发现它们正在分化为三条不同的技术路线。每一条面临不同的审核风险结构。
AI 模型直接出图。这条路代表是 Canva AI 于 2026 年 4 月发布的 Magic Design 功能,它从文字提示词直接生成包含 AI 视觉元素的设计稿。Midjourney、DALL·E 等模型生成的图片同样属于这个范畴。问题明确:这些图片是音画识别模型的主要检测目标。Canva 的应对方式是鼓励透明标注,而非规避检测。小红书上,AI 模型出图的帖子被标注后是否会降低推荐权重,没有公开数据可以证实,但平台对“未标识 AI 内容限制分发”的表述已是既定政策。每次扩散模型版本更新,像素统计特征可能发生变化,对应的检测模型也会同步迭代,创作者面对的是一个持续移动的靶子。
API 模板引擎渲染。Bannerbear 是这个路线的典型。用户在设计器中制作模板,通过 REST API 传入 JSON 数据修改图层变量,服务端渲染输出 PNG 或 JPG。它的内核同样是“程序渲染”而非“模型生成像素”,输出不含扩散模型痕迹。与藏师傅 Skill 的差异在于:Bannerbear 的模板依赖人工设计,AI 不参与版式决策;藏师傅 Skill 让 Claude 直接读写 HTML,版式选择权交给 AI。Bannerbear 方案的风险在另一个维度:大量账号使用相同模板、相同配色、相同字体产出图文时,即使每张图都不是 AI 生成,也会在平台侧触发“程序化批量生产”模式识别。反垃圾规则的触发条件不完全等同于 AI 检测,但对批量运营账号的创作者而言,结果同样是分发受限。
平台定制化生成。Pin Generator 专为 Pinterest 设计,自动生成符合平台算法偏好的 Pin 图。这个路线的核心不是规避,而是完全适配——尺寸、视觉风格、发布节奏都对齐平台规范。优点是审核风险最低,缺点也很明显:工具能力绑死在平台规则上,Pinterest 调整算法或限制第三方 API 调用时,工具直接失效。对照藏师傅 Skill,前者属于平台专属工具,后者是跨平台通用方案。平台专属更安全但更脆弱,跨平台通用更灵活但更复杂,这是一组在 AI 工具领域反复出现的取舍。
三条路的风险结构各不相同。AI 出图最自由但每次更新都在应答新的检测模型。模板引擎最稳定但可能被反垃圾规则误伤。HTML 渲染走在这两者之间:版式由 AI 灵活控制,像素交给浏览器和实拍素材,规避的是“AI 生成像素”这一层的检测,但无法应对平台语义层面的规则扩展。
版式系统的上限,不在代码里而在内容类型里
28 个版式骨架覆盖了杂志风和瑞士风两种主流视觉系统。对需要展示地图路线、时间线、多日行程的旅行博主来说,这套系统匹配度很高。地图标注和行程连线是这些笔记的核心信息,版式骨架把信息结构化了,同时保持了排版的专业感。
但小红书的内容生态远比旅行攻略更丰富。穿搭笔记依赖个人摄影风格和色彩调性,美妆测评需要高清微距照片和产品对比图,生活方式类内容大量使用多图拼贴和手写标注。这些内容类型的“排版”不是信息的结构化呈现,而是个人审美和情绪的表达。28 个版式骨架在这种场景里不是工具,是约束。
技术层面的限制同样真实。目前支持 1080×1440(小红书 3:4)、2100×900(公众号 21:9)和 1080×1080(公众号 1:1)三种尺寸。抖音 9:16 竖屏封面、B 站 16:9 横屏封面不支持。图库依赖 Unsplash 和 Pexels,这两个平台的素材偏向高质量摄影,适合旅行、风景、城市建筑的配图需求。但美食特写、化妆品摆拍、穿搭单品这类垂直内容的高频素材,在这些图库中的覆盖度有限。用户图优先的策略可以部分缓解这个问题,前提是创作者本身有足够的实拍素材积累。
校验机制是一把双刃剑。validate-social-deck.mjs 能在出图前拦截排版事故,保证 100 次批量渲染不出错。这在需要日更几十张图的运营场景中是效率保障。但它也意味着任何不符合预设版式规则的设计都会被脚本拒绝。想要在标准版式中加一个倾斜的文字装饰或自定义边距的创作者,不能像在 Canva 里那样随手拖动调整,需要直接编辑 HTML 和 CSS 源码。
本地部署门槛是另一个分层点。能跑 Playwright 和 Node 脚本的创作者,可以深入到版式骨架和渲染脚本中做定制。但对于大部分小红书博主,能接触到的是网页版界面的功能子集。这两类用户从这个 Skill 中获得的实际价值差距很大。开源项目的核心用户群是愿意折腾、有技术背景的创作者和开发者,而非普通内容生产者的“一键出图”需求。
没有万能答案,但技术路线的分化本身已经说明问题
一个小红书旅行博主面对三种选择:用 Midjourney 生成插画风格的行程图,承担被标注和降权的风险;用 Bannerbear 设置好模板每天批量灌入数据,承担模板同质化带来的反垃圾风险;或者用藏师傅的 Skill,让 AI 选择版式后用 HTML 渲染出图,承担平台扩展“合成内容”定义的风险。没有安全牌,只有不同风险结构的组合。
这个格局本身在传递一个信息:平台与 AI 工具之间的对抗迭代已经开始。每一次平台更新检测模型,都会有一批工具的技术红利期结束。每一次有新工具找到绕过路线,平台又会调整策略。这不是一个会收敛到稳定状态的过程。HTML 渲染方案的有效期,取决于小红书音画识别模型的训练方向是继续聚焦“扩散模型像素特征”,还是扩展到“所有非原生摄影像素”。
对内容创作者来说,区分“AI 辅助”和“AI 替代”变得有实际意义。平台态度已经明确:鼓励 AI 作为创意放大器,反对用 AI 替代人进行低质批量生产。藏师傅 Skill 中,AI 做的是排版决策而非内容生成,照片是实拍的,版式是人类设计师预设的骨架。这恰好落在“AI 辅助”的区间。那些从文案到图片全部用生成模型产出的图文,才是平台明确要打击的对象。
这种区隔是否会成为平台审核的操作性标准,目前还不确定。但工具开发者已经在用技术选择回应这个定义了。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







