
On June 22, 2026, the new model Fugu released by Sakana AI caused a stir in the AI community. In the rigorous SWE-Bench Pro and TerminalBench benchmark tests, Fugu Ultra scored 73.7 and 82.1, surpassing GPT-5.5 and Claude Opus 4.8, and even claimed to be on par with the export-controlled Fable 5 and Mythos Preview. Surprisingly, this system, which topped the engineering and reasoning capabilities, is not a massive model with hundreds of billions of parameters, but rather a model with only 7B parameters. It does not work independently; instead, it acts as a "contractor" dynamically scheduling the world's top large models. This counterintuitive architecture not only breaks the myth of "more parameters equals better performance" but also reflects Japan's path to breakthroughs in AI under limited computing power.
The 7B Parameter "Contractor": The Counterintuitive Architecture of Fugu
To understand the peculiarities of Fugu, we must first look at its origins. Sakana AI was founded in 2023 in Tokyo by Llion Jones, a co-author of the Transformer paper, and former Google researcher David Ha. From its inception, the company has carried the gene of "natural heuristics," aiming to solve AI problems using evolutionary algorithms and the collective intelligence of nature. In 2025, Sakana AI secured investments from giants like NVIDIA and Google, with a valuation exceeding $2.5 billion. However, even with endorsements from these giants, Japan still lacks the massive computing infrastructure and data pools found in the US and China. Under such resource constraints, Sakana AI chose not to compete head-on with large models with hundreds of billions of parameters but instead pursued a "composition" route.
The official positioning of Fugu is "a multi-agent orchestration system based on a single foundation model." In traditional AI architectures, a large model is a "monolithic monster" where the user inputs a prompt, and the model computes from the first layer of the neural network to the final layer to output results. This mode is highly efficient for handling simple problems, but often encounters hallucinations or logical breaks when facing complex multi-step engineering tasks.
Fugu completely transforms this paradigm. Its core is a 7B parameter model trained through reinforcement learning, referred to as RL Conductor. This 7B model does not directly generate the final answer; rather, it assumes the role of "contractor." When a user submits a task through a single OpenAI-compatible API, the RL Conductor dynamically analyzes the task type and then allocates sub-tasks to top models in the agent pool, such as GPT-5, Gemini 3.1 Pro, or Claude Opus 4.8. It is responsible for scheduling, validating, and synthesizing the outputs of these models to ultimately deliver a result that has undergone multiple verifications.
The theoretical support for this architecture comes from two papers presented at ICLR 2026: "TRINITY: An Evolved LLM Coordinator" and "Learning to Orchestrate Agents in Natural Language with the Conductor." The papers detail how a small parameter model can "command" large models through reinforcement learning. This changes the paradigm of Test-time scaling. In the past, computing power was mainly used for deep reasoning within the model, meaning letting the model "struggle" for one answer; now, computing power is used for external scheduling, validating, and synthesizing. Traditional large models are versatile monoliths, while Fugu represents a team of specialists. The 7B RL Conductor demonstrates that the size of model parameters is no longer the only standard for determining capabilities; knowing how to utilize tools and external agents can also achieve performance leaps.
The Truth Behind the Scores: Comparable to Fable and Surpassing GPT-5.5
The reason Fugu has caused such a sensation is its scoring in rigorous benchmark tests. In the AI industry, scores are the hard currency for measuring model capabilities, but different benchmark tests focus on completely different aspects. The SWE-Bench Pro and TerminalBench 2.1 chosen by Sakana AI are both "hard nuts" leaning towards real engineering environments.
SWE-Bench Pro focuses on software engineering capabilities, requiring the model to locate and fix bugs in real codebases. According to data released by the Sakana AI console, Fugu Ultra scored 73.7 on SWE-Bench Pro. In comparison, Claude Opus 4.8 scored 69.2, GPT-5.5 scored 58.6, and Gemini 3.1 Pro scored 54.2. In another test system measuring operational capabilities called TerminalBench 2.1, Fugu Ultra scored 82.1, surpassing the 78.2 of GPT-5.5 and the 74.6 of Opus 4.8. These two tests not only examined the model's code generation abilities but also assessed its logical stability and tool utilization in multi-step, long-chain tasks. The advantage of Fugu Ultra means that it encounters fewer mid-task failures or deviations from targets when solving complex engineering problems compared to monolithic models.
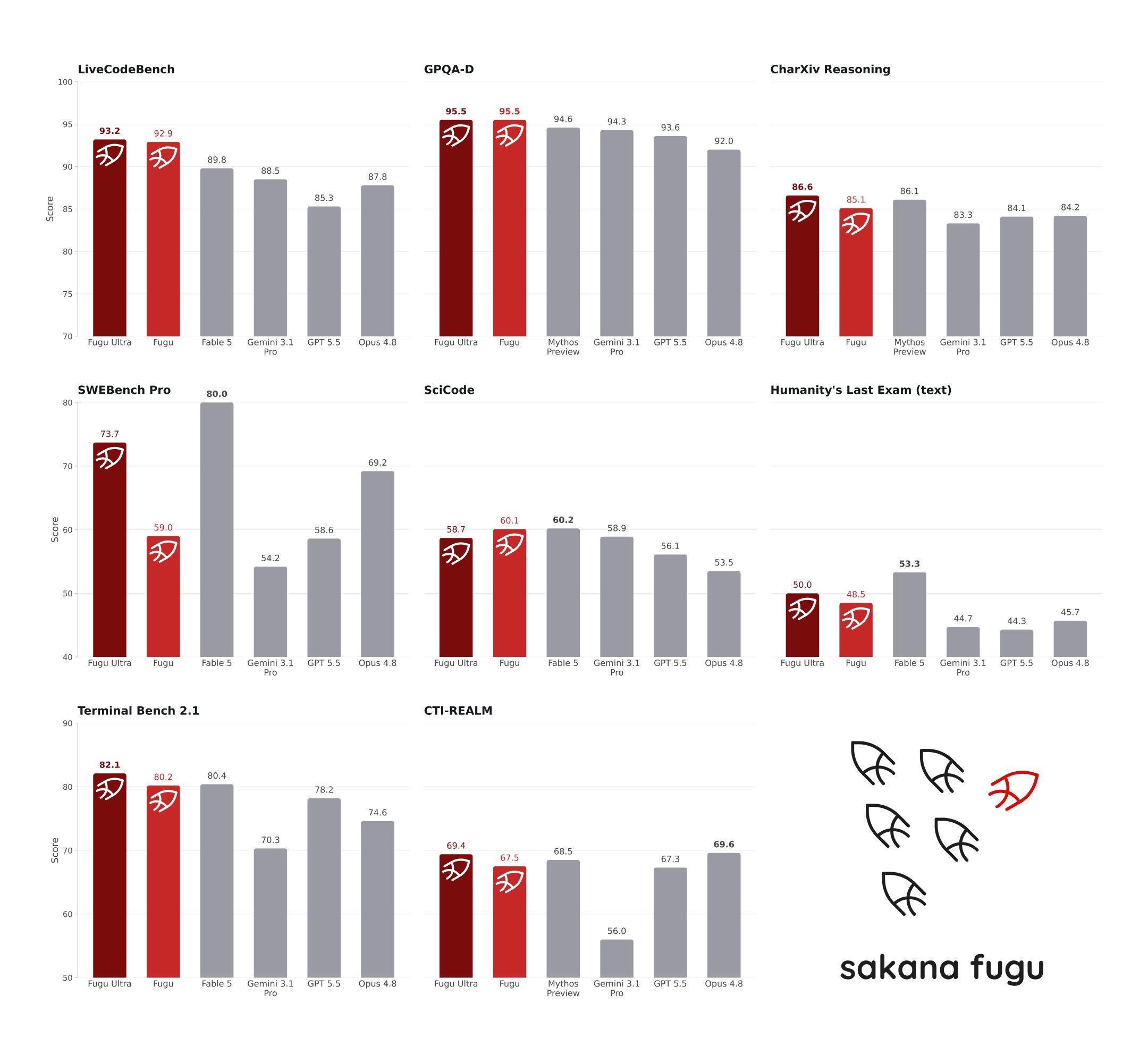
More attention is drawn to Fugu's comparison with Fable 5 and Mythos Preview. Anthropic's Fable series and another frontier lab's Mythos series represent the leading edge of current AI reasoning capabilities. However, due to export controls or incomplete public disclosure, these two models did not enter Fugu's agent pool. Sakana AI claims that Fugu Ultra is "comparable" to Fable 5 and Mythos Preview in engineering and scientific benchmarks, but it must be made clear that this comparison is not based on tests conducted in the same pool. Fugu's scores are based on the actual operational results of its own system, while the data for Fable and Mythos are based on scores reported publicly by their respective manufacturers.
This comparative metric has caused some controversy in the developer community. Some argue that the testing conditions of different systems in different environments are difficult to align completely, making direct score comparisons unfair. However, some developers point out that in the absence of a unified testing environment, referencing vendor report data is an industry convention. Regardless of the disputes with Fable and Mythos, Fugu Ultra's surpassing of GPT-5.5 and Opus 4.8 in SWE-Bench Pro and TerminalBench 2.1 reflects a genuine comparison of similar conditions. This superiority is not because Fugu's underlying model is smarter than GPT-5.5 but because the RL Conductor performs more precisely in task decomposition and expert scheduling. In experiments requiring multi-round reasoning and verification, such as AutoResearch, Rubik's cube solving, and mechanical design, Fugu continues to demonstrate advantages. This indicates that in processing "long, chaotic, multi-step" real-world workflows, the multi-agent orchestration architecture indeed proves to be more resilient than monolithic models.
Real Development Scenario Testing: Code Review and Long Conversation Stability
For developers and AI tool users, scores are merely a reference; what truly determines whether a model is usable is its performance in real work scenarios. Fugu underwent Beta testing with nearly 500 early users before its release, and their feedback revealed Fugu's unique value in practical applications.
Code review is one of the most commonly used AI scenarios for developers. Traditional monolithic models often only detect superficial syntax errors or common logical flaws when reviewing code. In the Beta testing, some developers reported that Fugu displayed exceptional detail in code reviews, capable of identifying deep architectural bugs that other tools could only recognize a few surface-level problems. This difference stems from Fugu's architecture. When RL Conductor receives a code review task, it can call upon models adept at static analysis, models skilled in logical reasoning, and models proficient in security audits to conduct multi-angle cross-validation on the same code segment. This "expert consultation" mode naturally reveals more hidden issues than the "solo effort" of a single model.
Another frequently mentioned advantage is long conversation stability. One of the biggest headaches for developers when building AI Agent products is the "persona drift" of models in long conversations. As the number of dialogue rounds increases, monolithic models often forget initial settings or deviate in instruction adherence. Some corporate executives, after testing, reported that Fugu's persona remained exceptionally stable during long conversations, with almost no drift occurring. This is because the RL Conductor does not maintain memory of long texts itself; it only accurately selects the most suitable underlying model to generate replies based on the current context in each dialogue round. This "separation of control and generation" architecture significantly enhances the stability of the Agent during extended operations.
In the field of cybersecurity, Fugu has also demonstrated end-to-end practical capabilities. In tests, Fugu could independently complete the entire process from reconnaissance and XSS/SQL injection vulnerability detection to authentication review, generating a comprehensive penetration testing report while strictly adhering to instructions not to disrupt the system. The completeness of such complex tasks relies on the precise orchestration of the security toolchain and the capabilities of different large models by the RL Conductor.
Additionally, token efficiency is another highlight of Fugu. Traditional large models often generate lengthy chains of thought when handling complex problems, consuming a large number of tokens. However, Fugu's RL Conductor avoids meaningless long chain of thought consumption through precise routing. Official reports and early tests show that it can significantly reduce wasted tokens. For developers charged by tokens, this not only means reduced costs but also improved response speed.
The Weakness of Underlying Dependencies: The Cost of Multi-Agent Orchestration
Although Fugu performs impressively in architecture and scoring, as a tool for real work, it is not without weaknesses. The multi-agent orchestration architecture brings significant performance breakthroughs but also introduces non-ignorable risks and limitations.
The core issue is the risk of underlying dependencies. Fugu's agent pool heavily relies on underlying APIs from major US manufacturers like GPT, Claude, and Gemini. Although the RL Conductor has dynamic routing capabilities that allow it to switch to other models when a particular model malfunctions or faces throttling, this only mitigates the risk of a single vendor and does not remove dependence on the entire US AI infrastructure ecosystem. If these underlying models collectively increase prices, throttle on a large scale, or change API terms, Fugu's cost structure and stability will be directly impacted. This "parasitic" mode on others' infrastructure carries inherent fragility in terms of commercialization and long-term stability.
Next is the balance between latency and cost structure. Although the RL Conductor saves on token consumption through precise routing, multi-agent orchestration inevitably involves multiple API calls and communications between models. For real-time interaction scenarios that require extremely low latency, such as real-time voice conversations or high-frequency trading assistance, the "deep thinking and scheduling" time of Fugu Ultra may exceed that of directly invoking a monolithic model. In scenarios where response speed is crucial, Fugu's architectural advantages may become a hindrance to user experience.
Moreover, the issue of comparison fairness persists. As mentioned earlier, Fugu claims to be on par with Fable and Mythos, but the latter two models did not enter Fugu's agent pool. There are voices in the developer community questioning whether comparisons based on vendor report data have actual reference value. After all, different models perform differently under varying task distributions, and simple total score comparisons may obscure specific strengths and weaknesses. For developers requiring precise assessments of model capabilities, the lack of test data from the same pool still necessitates caution when making selection decisions.
Not Competing on Computing Power but on Orchestration: Japan's Asymmetrical Breakthrough in Large Models
Stepping outside of specific product evaluations, the birth of Fugu carries a deeper significance for Japan's large model ecosystem. In the global AI arms race, Japan finds itself in an awkward position. It neither has the continuous top computing power and cutting-edge algorithm accumulation like the US nor the massive data pool and fierce market competition environment like China. More critically, Japan also faces the risk of export controls on cutting-edge models from the US (such as Fable/Mythos). In this context, Sakana AI's "evolutionary algorithm" and "multi-agent orchestration" route demonstrate a "non-asymmetrical breakthrough" logic for resource-constrained countries.
Japan is not without large model manufacturers. NTT has launched tsuzumi, and organizations like ELYZA, Rinna, and LLM-jp are also working on training local language models. However, most of these manufacturers are pursuing the traditional route of "training from scratch," making it difficult to compete with top models from China and the US in terms of parameter scale and general capabilities. Sakana AI stands out as the only laboratory with global influence that focuses on "asymmetrical architecture."
Fugu's dynamic routing capabilities essentially help Japanese enterprises and institutions establish "AI sovereignty." Under limited computing power, rather than spending vast sums to train a hundred billion parameter model that is inferior to GPT-5.5 in many aspects, it is preferable to train an intelligent 7B "contractor." This contractor can flexibly connect to the best global models according to task requirements. If one day a model from the US is subjected to export control or discontinuation, the RL Conductor can quickly route the tasks to other available models, even connecting to locally specialized models in Japan. This architecture grants Japan a certain degree of autonomy and risk resilience in the use of AI capabilities.
OmniTools found that in observing the global AI tool ecosystem, the capabilities of large models are gradually leveling out, shifting the main battlefield of competition from simple parameter stacking to toolchains and practical scenarios. The emergence of Fugu coincides with this trend. It no longer pursues perfection in a single model but seeks to achieve optimal performance at the system level. This approach has important reference significance for countries and regions that do not have advantages in computing power or data.
However, this "asymmetrical breakthrough" also has its ceiling. As long as the core technologies of underlying models remain in the hands of a few giants, the upper limit of orchestration system capabilities will be restricted by the underlying models. Fugu has proven that a 7B model can become an excellent commander, but it cannot create capabilities that underlying models do not possess out of thin air. For Japan's large models to achieve genuine breakthroughs, continuous investment in underlying computing power, core algorithms, and high-quality data is still necessary, in addition to innovation in orchestration architecture. Fugu is a sophisticated system-level innovation, but it is not a panacea. For developers and corporate users, Fugu offers a highly competitive new option in complex engineering scenarios, but they must also be acutely aware of its underlying dependency vulnerabilities and the trade-offs of latency costs when using it.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








