As AI Agents are applied in various complex scenarios such as enterprise workflows, automated production, and autonomous execution, the global AI industry has officially transitioned from "passive response" to a new stage of "autonomous execution." The core of industry competition has long moved beyond simple comparisons of large model parameters to a competition over deployment execution capabilities, with powerful logical reasoning abilities constituting the fundamental support for this shift.
The paradigm shift in application scenarios has also led to a fundamental change in upstream computing infrastructure demands: the focus of computing consumption is continuously shifting from model training to business inference, and this trend is irreversible. However, the current mainstream centralized computing systems are facing massive, high-frequency, and highly fluctuating inference requests, exposing issues such as high operational costs, weak elastic scalability, and insufficient service stability. The entire AI industry is encountering developmental bottlenecks on the supply side of computing power.
On June 17, the well-established decentralized transmission ecosystem BitTorrent launched a strategic-level product—BTTInferGrid, anchoring in the AI inference track and building a decentralized computing network. This platform relies on a decentralized distributed architecture, efficiently aggregating scattered idle GPU computing resources from around the world, breaking down the connection barriers between the resource supply side and AI developers, and providing open, easily accessible, verifiable computational results, and flexible pay-per-use AI inference computing services.

Leveraging the advantages of decentralized technology, BTTInferGrid not only fills the gaps in traditional centralized computing for high concurrency and load fluctuation scenarios but also achieves a leap in computing supply, reconstructing the resource allocation and circulation logic of the entire computing ecosystem.
At the same time, BTTInferGrid is a strategic product upgraded from BitTorrent's existing BTFS service, which not only represents the extension of BitTorrent's long-standing capabilities in decentralized resource scheduling from the storage domain to the computing field but also a key move in its layout of the decentralized AI track.
Transition of Computing Demand Structure from “Training” to “Inference”: BTTInferGrid Reconstructs AI Inference Computing Supply in a Decentralized Manner
BTTInferGrid seeks to reconstruct the computing supply system through decentralized models to address issues such as high costs and shortages in AI inference computing power, enhancing the efficiency of large model inference while reducing costs and increasing efficiency, thus providing high-performance, resilient, and cost-effective computing infrastructure for the industry.
If 2024 to 2025 is seen as the "thousand-model battle" and parameter arms race led by massive clusters in the AI industry, then in 2026, with the large-scale rollout of AI Agents, AI will officially enter the "era of inference" where large-scale application explosive growth occurs. AI inference is the key link for realizing the value of models, transforming "trained models" into real applications, business value, and everyday services. In simple terms, training is about "teaching AI to learn," while inference is about "letting AI be put to use"—for example, a self-driving car identifying traffic signs on an unfamiliar road perfectly exemplifies inferencing behavior. The inference capability directly influences the user experience, operational costs, and commercial value of AI products.
There is a consensus in the industry that in the future, over 70% of computing resources will be used in inference scenarios. Oracle once predicted that the market size for inference computing will eventually surpass that of training computing. Similarly, Zheng Weimin, an academician of the Chinese Academy of Engineering, pointed out that currently, the vast majority of computing is consumed in daily interactions between users and large models. From a cost composition perspective, the expenses for large model inference are composed of only 3% for manpower, 2% for data, while a staggering 95% is attributed to computing power; top applications have significant computing costs, with ChatGPT's daily inference costs around 700,000 USD and DeepSeek V3 reaching 87,000 USD.
As AI computing demands transition from the centralized training of a few tech giants to the commercial inference scenarios of millions of developers across various industries, the evaluation criteria for underlying infrastructure will also change. In the training era, developers primarily focused on the centralized scale and efficiency of computing power; entering the inference era, AI services are directly aimed at mass end-users, with daily interactions in the hundreds of billions causing massive consumption of computing power. Developers' focus has shifted to the cost per invocation, response speed, and service stability. Currently, computing supply, invocation costs, and service availability have become the core criteria for evaluating AI infrastructure, and are also key factors determining whether AI applications can be smoothly deployed.
However, in the face of exponentially rising inference demands, the shortcomings of the mainstream centralized computing systems are becoming increasingly apparent: GPU rental prices continue to rise, platform services frequently crash, and many AI applications are forced to shut down due to high computing costs. These issues manifest in three main areas:
First, insufficient elasticity in computing scheduling leads to an inability to cope with peak traffic fluctuations, resulting in an imbalance between cost and stability: Although leading AI companies and cloud vendors have been continuously increasing investments in computing facilities, the demand for inference is growing rapidly with obvious peak and valley characteristics—request volumes can surge several times during daytime office or marketing peaks; then drop dramatically at night. Centralized data centers, lacking elastic scheduling capabilities, struggle to adapt to such dynamic changes: configuring for peak demand results in high depreciation costs during low demand periods; whereas configuring for average demand leads to service interruptions during peak periods, resulting in a dilemma of "high cost" and "low stability." Additionally, centralized computation incurs multilayered costs associated with data center construction, electricity, operations, and commercial profits, causing computing costs to soar, severely compressing the trial-and-error space for small and medium-sized innovative teams. The market urgently needs a new solution that offers both cost advantages and elastic scheduling capabilities.
Second, the continuous rise in GPU leasing prices obstructs innovation and deployment for small and medium enterprises and developers: While open-source large models (such as Qwen, DeepSeek, etc.) have lowered the entry barriers in the AI field, the deployment and operation of these models still depend on stable, inexpensive, and easily accessible inference computing power. However, the reality is that GPU leasing costs are climbing, with the rental price for mainstream H100 graphics cards rising from $1.70 in October 2025 to $2.35 in March 2026, a nearly 40% increase in half a year. The high costs deter many individual developers and small enterprises that possess high-quality solutions, leaving them in a predicament of "having models but no computing power," severely stifling innovation vitality and scalable development in the AI industry.
Third, a large volume of idle global GPU resources remains ineffectively utilized, leading to serious supply-demand mismatches: In sharp contrast to the market's "computing power shortage" is the substantial amount of idle high-performance GPU resources that exist globally, dispersed across personal devices, university laboratories, small data centers, and facilities left over from cryptocurrency transitions. Due to a lack of standardized access channels and efficient scheduling engines, these computing powers cannot enter the mainstream inference market, creating a contradictory scenario where demand is met with "hard-to-find cards" while supply remains "sleeping computing power." There is significant room for improvement in resource utilization, and the mismatch between supply and demand urgently needs to be addressed.
In summary, the current AI inference computing market is facing three structural dilemmas: on one side, centralized supply cannot balance cost and elasticity; on the other, rising computing rental fees stifle AI innovation; and finally, a large volume of idle GPU resources remains dormant and unactivated. Addressing these industry challenges, BTTInferGrid leverages decentralized technology to bring forth new solutions to rectify the mismatch between computing supply and demand.
BTTInferGrid aims to efficiently connect the globally scattered idle GPU resources with vast AI developers through decentralized methods, fundamentally breaking the monopoly and bottlenecks of centralized computing power. On one hand, the platform integrates scattered idle GPU computing power, constructing an open and shared computing infrastructure; on the other hand, it opens the connection channel between the supply side and the demand side, eliminating the access barriers and pricing black boxes of traditional centralized models. At the same time, benefiting from the incentive and collaboration mechanisms of DePIN, BTTInferGrid continuously delivers high-cost performance inference computing, fundamentally resolving the core pain points of high computing costs and supply shortages, and truly unleashing the inference capabilities and commercial value of large models.
BTTInferGrid: Building a Decentralized Computing Network for AI Inference Scenarios, with Three Major Advantages Redefining the Computing Allocation Mechanism
BTTInferGrid has a clear and precise positioning, focusing on building a decentralized computing network for AI inference scenarios, connecting global idle GPU computing supply with AI inference market demand, providing an open, verifiable, and pay-per-use global AI computing service system.
Specifically, BTTInferGrid relies on the underlying network mechanism of DePIN, precisely matching computing supply with the explosive growth of AI inference demand, achieving a two-way value empowerment between supply and demand:
- On the computing supply side, efficiently aggregating fragmented idle GPU resources from around the world to build an open and shared computing foundation. Additionally, leveraging DePIN's incentive and smart scheduling mechanisms, it opens up low-threshold and sustainable monetization channels for computing resource holders, allowing "sleeping GPUs" to become "liquid assets"; at the same time, it ensures stable and elastic expansion of computing power, creating high-cost performance, high scalability, and secure and reliable global inference service capability.
- On the computing demand side, providing global AI developers with easy access, verifiable results, and pay-per-use global inference services. Compared to the high-premium pricing of centralized cloud vendors, BTTInferGrid possesses extreme cost advantages and elastic expansion capabilities, allowing small and medium-sized tech innovation teams and independent developers to reduce business trial-and-error costs and efficiently complete product validation and business iterations while simultaneously empowering the upstream computing supply ecosystem.
Thus, BTTInferGrid effectively addresses the urgent demand for low-cost, high-elasticity computing from AI developers in the "application competition" stage and opens up sustainable value monetization channels for a vast number of idle hardware resources globally.
More importantly, the BTTInferGrid platform will successfully create a self-sustaining positive growth flywheel: as idle GPU nodes continuously expand, inference computing costs decrease, attracting more developers; market demand continues to rise, further incentivizing global computing suppliers to join the ecosystem. BTTInferGrid reconstructs computing supply in a decentralized manner, transforming scarce and high-priced dedicated AI computing resources into an accessible, demand-based public foundational infrastructure for AI.
In terms of product performance advantages, currently, most decentralized GPU platforms face general issues such as high access thresholds, insufficient service credibility, and unsustainable economic models. BTTInferGrid optimizes from the bottom layer architecture, achieving breakthroughs across three dimensions: computing aggregation, service verification, and sustainability of the economic system, forming a unique core competitiveness. The specific advantages are as follows:
1. An open-access computing supply network that rapidly aggregates global idle GPU resources: Traditional cloud computing access has high thresholds (such as requiring compliant data centers, static public IPs, expensive switches, etc.), whereas BTTInferGrid has built a truly open-access computing supply network, enabling any entity or individual with idle GPU or computing resources to seamlessly connect, as long as they meet basic performance parameters (such as memory capacity, computing benchmark) and network stability requirements. This design significantly lowers the participation threshold on the supply side of computing resources, enabling quick networked and matrixed aggregation of idle global GPU resources.
2. Verifiable service quality and node behavior, solving the trust issues in decentralization: The biggest pain point of decentralized computing is credibility—how to prevent miners from using low-end graphics cards to impersonate high-performance cards? How to ensure the results of inference are true and credible? BTTInferGrid constructs a cross-verifiable closed-loop through task scheduling (intelligent distribution), challenge verification (cryptographic sampling), consensus scoring (dynamic reputation scoring), and on-chain coordination (smart contract rewards and penalties), effectively enhancing the credibility of inference services.
3. A demand-driven economic model to create a sustainable ecosystem: Early DePIN projects often fall into a "high token inflation attracts nodes to mine blindly, but due to a lack of real demand, lead to token inflation, price plummeting, and nodes leaving" death spiral. BTTInferGrid established early on the goal to create a demand-driven economic ecosystem—using actual inference calls and node performance as the core incentive basis. Only when AI developers genuinely pay to invoke models can computing providers obtain core revenue sharing and reputation boosts. This design will vigorously promote healthy adaptative growth between supply scale and market demand, ensuring the long-term healthy and sustainable development of the network ecosystem.
In summary, from breaking traditional access barriers to enable seamless access for any idle GPU that meets performance standards in the open supply grid, to constructing a fully verifiable trust defense line through task scheduling, challenge verification, consensus scoring, and on-chain rewards and penalties, and finally bidding farewell to speculative bubbles by anchoring incentives in real AI inference call demand-driven economic models—BTTInferGrid is redefining the allocation mechanism of computing resources from the perspectives of resource aggregation, service credibility, and value distribution.
BTTInferGrid Will Gradually Build a New Computing Ecosystem Driven by Real Demand
BTTInferGrid is not merely a "computing aggregation" but a sophisticated decentralized computing network that integrates AI inference task scheduling and execution, intelligent matching and connection of computing supply and demand, and on-chain resource coordination and settlement.
In the decentralized computing ecosystem of BTTInferGrid, all participants form three core roles around the "supply, utilization, and verification" of computing power:
- Computing suppliers (miners): Provide idle GPU resources, undertake and execute AI inference tasks, and the system automatically allocates corresponding rewards based on verified actual workload, task completion quality, and dynamic performance scoring.
- Computing demanders (AI developers): BTTInferGrid provides standardized API service interfaces, supporting developers to access globally distributed GPU resources.
- Network guardians (validators): Participate in decentralized verification and scoring systems, auditing miner nodes' computational performance and conducting random challenges to identify abnormal behavior and maintain network service quality. At the same time, validators earn rewards for maintaining the integrity of the network, collectively ensuring the network's fairness and credibility.
In summary, for AI developers, BTTInferGrid brings cost-effective, highly scalable, and trustworthy AI inference services, effectively alleviating problems of product interruptions and customer loss caused by insufficient computing power. For GPU providers, it revitalizes global edge and idle hardware resources, creating a sustainable revenue channel for GPU resource providers, enabling every piece of computing power to realize its expected value in the inference era.
In terms of specific product implementation, unlike the heavy asset model of traditional centralized cloud vendors which "first piles up hardware, then waits for demand," DePIN inherently faces the challenge of bidirectional coordination during its construction—over-supply can lead to idle nodes and token economic collapse, while under-supply can impair developer experience and system efficiency. Therefore, BTTInferGrid has set a clear, robust, demand-oriented phased launch strategy, discarding disorderly and extensive growth, prioritizing resource utilization, economic sustainability, and steady expansion of technical architecture.
- Short-term goal (2026): Network cold start, completing access of core underlying nodes and validating distributed inference services, gradually expanding the GPU node scale.
- Mid-term goal (2027): Ecological diversification, improving the stability and privacy security of network services, while accommodating more AI model formats and inference frameworks, gradually extending towards applications like model fine-tuning.
- Long-term goal (2028 and beyond): To become a native underlying infrastructure for AI, constructing a computing layer preferred for AI Agents and automated applications, providing elastic computing support for large-scale AI applications, ultimately achieving synergy among computing power, distributed storage, and on-chain smart contracts within a unified architecture.
In terms of practical execution, BTTInferGrid will also adopt a phased evolution strategy. In the initial launch phase, the network will primarily utilize professional graphics cards, requiring approved access for the computing supply side (miners), while demand side users can call inference services through the platform. In the future, it will evolve into a fully open super computing grid: supporting consumer-grade, professional-grade, and data center-grade GPU types, with performance-based access and pricing; enabling open access for miners, while introducing staking mechanisms to ensure service quality; the demand side will also have an open standardized API interface, compatible with various AI model formats and inference frameworks, providing flexible deployment options.
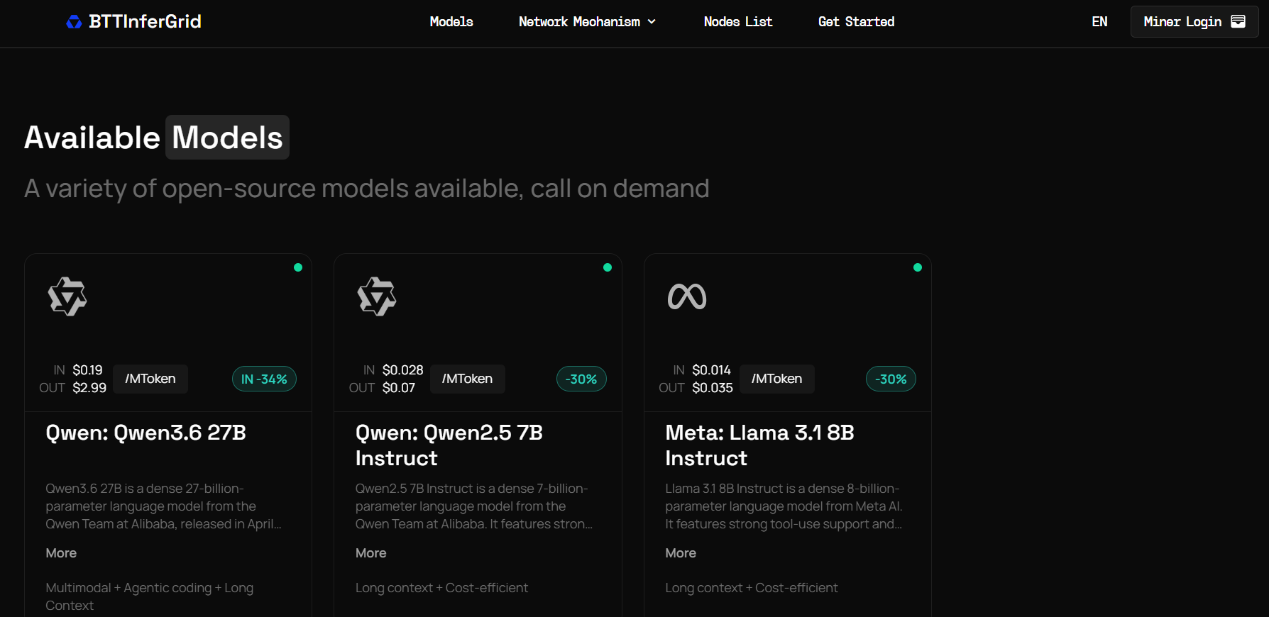
Currently, BTTInferGrid has successfully integrated several mainstream AI open-source large models, including Alibaba Cloud's Qwen series of Qwen3.6 27B and Qwen2.5 7B Instruct, as well as Meta's Llama 3.1 8B Instruct. AI developers can flexibly invoke according to their actual business scenarios. In the future, the platform will continue to expand its model ecosystem, providing developers with more cutting-edge model support.
More importantly, BTTInferGrid has the long-term accumulation of BitTorrent and BTFS as a solid backing, providing inherent development advantages. BitTorrent and its subsidiary BTFS have been deeply engaged in the field of decentralized storage for many years, with BitTorrent boasting over 100 million active users and 2 billion installations, successfully validating the feasibility of the DePIN model, and accumulating mature capabilities in areas such as resource access, token incentives, on-chain settlements, and community operations. As a strategic product for BitTorrent's entry into the AI track, BTTInferGrid is upgraded from the existing BTFS service, allowing these mature experiences to be seamlessly transferred to the AI inference computing field, thus facilitating rapid ecological growth.
Leveraging decentralized technology, BTTInferGrid precisely addresses the industry challenges of coexistence between "idle computing power" and "computing shortages." Its philosophy of open access, decentralized collaboration, verifiable contributions, and community co-construction not only represents a powerful breakout from the traditional centralized computing monopoly but also, with its clear product positioning and solid technological foundation, paints an imaginative picture of a new decentralized global computing blueprint. Here, every piece of idle computing power will be activated, and every developer will be able to reach an intelligent future at an affordable cost.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







