Author: Tina, Dongmei, InfoQ
1. Nearly three years later, Musk open-sources the X recommendation algorithm again
Just now, the X engineering team posted on X announcing the official open-sourcing of the X recommendation algorithm. This open-source library includes the core recommendation system that supports the "For You" information feed on X. It combines content from within the network (from accounts users follow) with content from outside the network (discovered through machine learning-based retrieval) and ranks all content using a Grok-based Transformer model. In other words, the algorithm uses the same Transformer architecture as Grok.
Open-source address: https://x.com/XEng/status/2013471689087086804
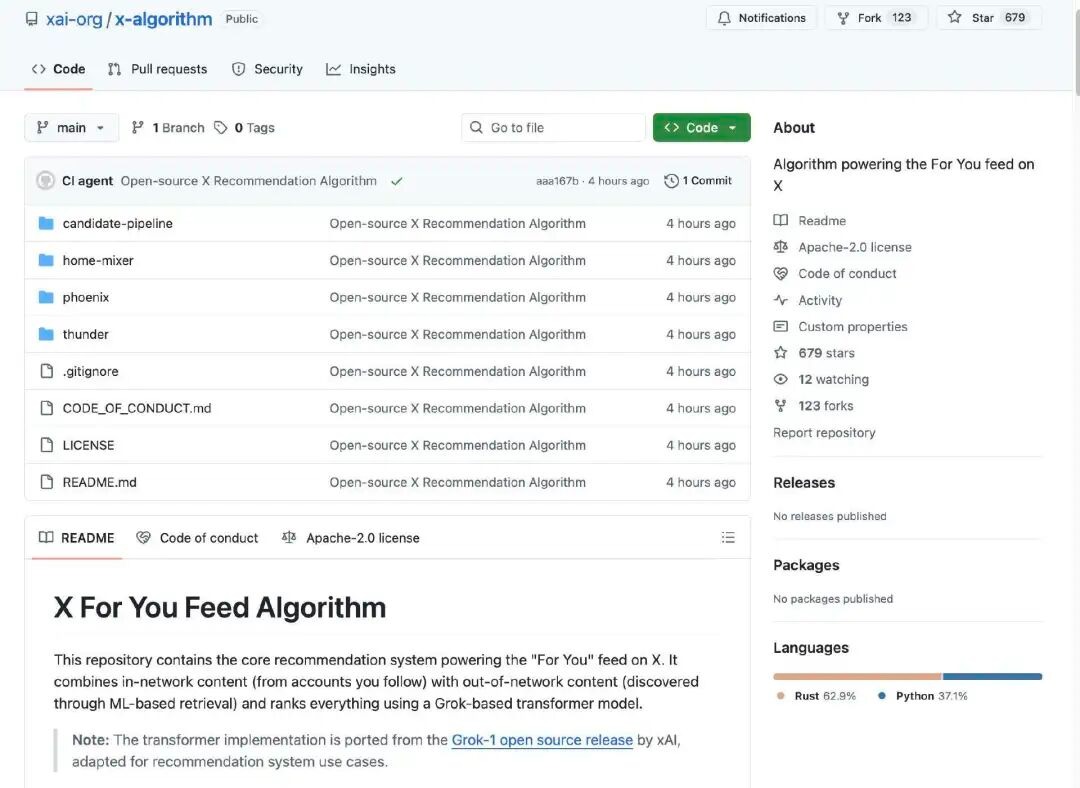
The X recommendation algorithm is responsible for generating the "For You Feed" content that users see on the main interface. It obtains candidate posts from two main sources:
Accounts you follow (In-Network / Thunder)
Other posts discovered on the platform (Out-of-Network / Phoenix)
These candidate contents are then uniformly processed, filtered, and ranked by relevance.
So, what is the core architecture and operational logic of the algorithm?
The algorithm first fetches candidate content from two types of sources:
Content from followed accounts: Posts published by accounts you actively follow.
Non-followed content: Posts that the system retrieves from the entire content library that may interest you.
The goal of this stage is to "find potentially relevant posts."
The system automatically removes low-quality, duplicate, inappropriate, or irrelevant content. For example:
Content from blocked accounts
Topics that the user has explicitly shown no interest in
Illegal, outdated, or invalid posts
This ensures that only valuable candidate content is processed during the final ranking.
The core of the open-sourced algorithm is that the system uses a Grok-based Transformer model (similar to large language models/deep learning networks) to score each candidate post. The Transformer model predicts the probability of each type of user behavior (likes, replies, retweets, clicks, etc.) based on the user's historical actions. Finally, these behavior probabilities are weighted and combined into a comprehensive score, with higher-scoring posts being more likely to be recommended to users.
This design essentially abolishes the traditional manual feature extraction approach, opting instead for an end-to-end learning method to predict user interests.
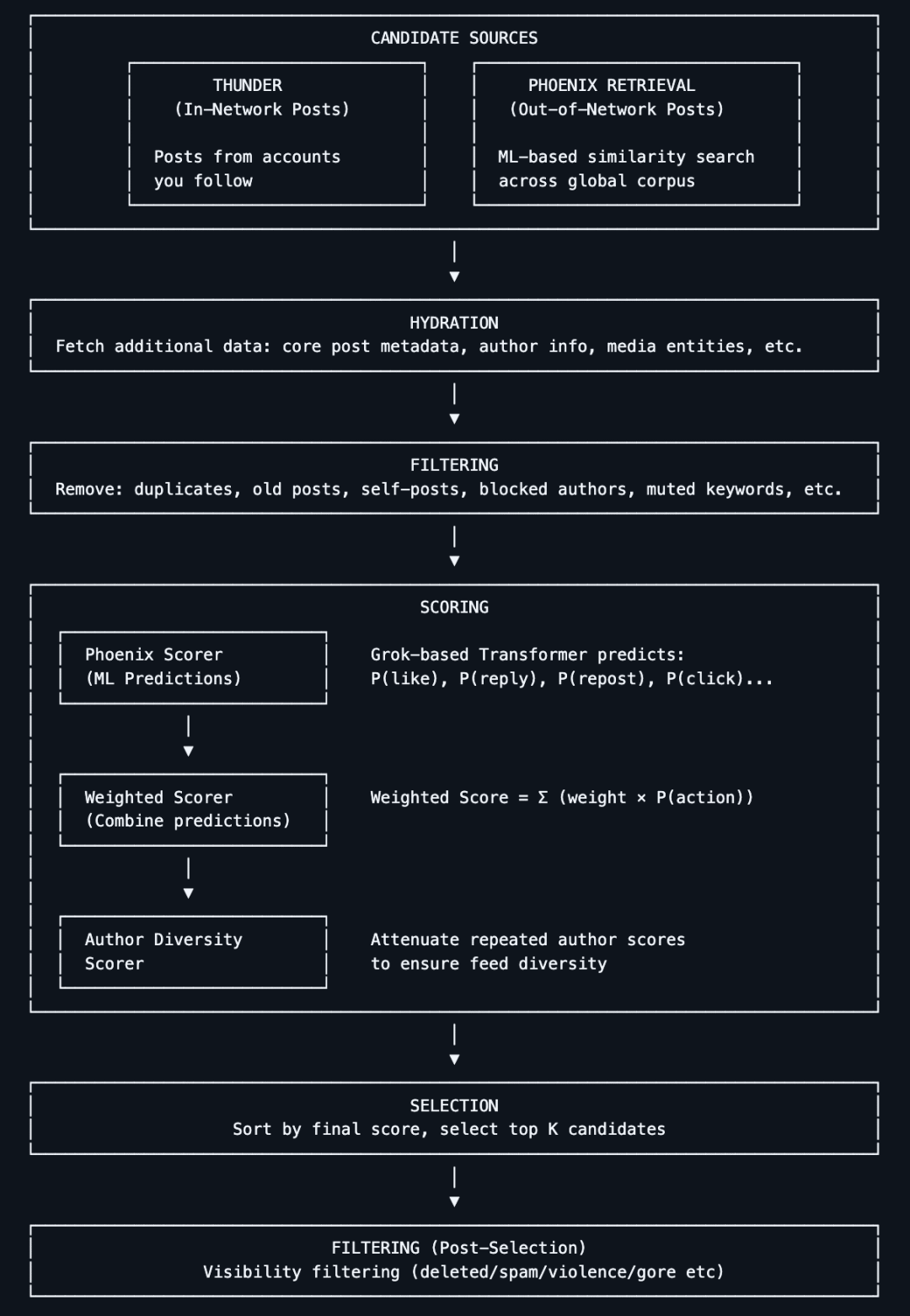
This is not Musk's first time open-sourcing the X recommendation algorithm.
As early as March 31, 2023, as promised during Musk's acquisition of Twitter, he officially open-sourced part of Twitter's source code, including the algorithm for recommending tweets in users' timelines. On the day of the open-source release, the project garnered over 10k stars on GitHub.
At that time, Musk stated on Twitter that this release included "most of the recommendation algorithms," with the remaining algorithms to be opened up gradually. He also mentioned that he hoped "independent third parties could reasonably determine the content Twitter might show to users."
In a Space discussion about the algorithm release, he said the open-source plan aimed to make Twitter "the most transparent system on the internet" and to make it as robust as the most well-known and successful open-source project, Linux. "The overall goal is to maximize the enjoyment of users who continue to support Twitter."
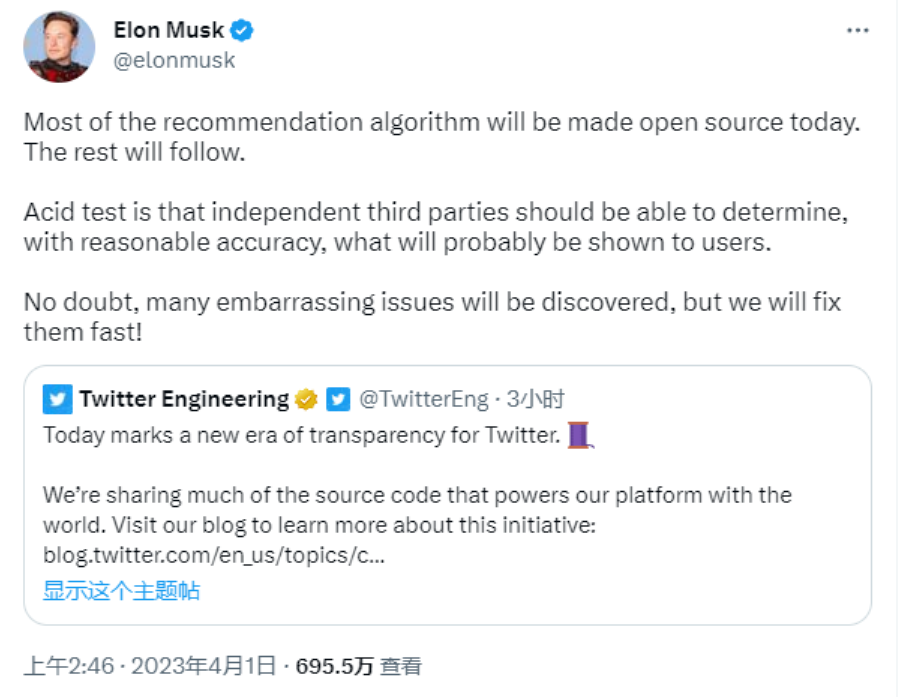
Now, nearly three years have passed since Musk first open-sourced the X algorithm. As a super KOL in the tech circle, Musk has already done ample promotion for this open-source release.
On January 11, Musk posted on X that he would open-source the new X algorithm (including all code for determining which organic search content and ad content to recommend to users) within 7 days.
This process will repeat every 4 weeks, accompanied by detailed developer notes to help users understand what changes have occurred.
Today, his promise has been fulfilled again.
2. Why does Musk want to open-source?
When Elon Musk mentions "open-source" again, the first reaction from the outside world is not technical idealism, but rather real-world pressure.
Over the past year, X has repeatedly fallen into controversy over its content distribution mechanism. The platform has been widely criticized for algorithmically favoring and amplifying right-wing views, a tendency seen as systemic rather than sporadic. A research report released last year pointed out that X's recommendation system exhibited a clear new bias in the dissemination of political content.
At the same time, some extreme cases further amplified external doubts. Last year, an unverified video involving the assassination of American right-wing activist Charlie Kirk spread rapidly on the X platform, causing public uproar. Critics argued that this not only exposed the platform's failure in its review mechanism but also highlighted the implicit power of the algorithm in "what to amplify and what not to amplify."
In this context, Musk's sudden emphasis on algorithm transparency is hard to interpret simply as a purely technical decision.

3. What do users think?
After the open-sourcing of the X recommendation algorithm, users on the X platform summarized the recommendation algorithm mechanism in the following 5 points:
- Reply to your comments. The algorithm weighs "replies + author responses" at 75 times that of likes. Not replying to comments severely affects exposure.
- Links will reduce exposure. Links should be placed in personal profiles or pinned posts, and should not be included in the body of posts.
- Watch time is crucial. If users scroll past, you won't capture their attention. Videos/posts gain high attention because they can make users stop.
- Stick to your niche. "Simulated clusters" are real. If you deviate from your niche (cryptocurrency, technology, etc.), you will not gain any distribution channels.
- Blocking/muting will significantly lower your score. Be controversial, but not annoying.
In short: Communicate with your audience, build relationships, and keep users in the app. It's actually quite simple.

Some users also found that while the architecture is open-source, some content remains undisclosed. One user stated that this release is essentially a framework without an engine. What specifically is missing?
Lack of weight parameters - The code confirms "positive behavior adds points" and "negative behavior deducts points," but unlike the 2023 version, specific values have been removed.
Hidden model weights - Does not include the internal parameters and calculations of the model itself.
Undisclosed training data - We know nothing about the data used to train the model, the sampling methods for user behavior, or how to construct "good" and "bad" samples.
For ordinary X users, the open-sourcing of X's algorithm will not have a significant impact. However, greater transparency can explain why some posts gain exposure while others do not, and enable researchers to study how the platform ranks content.
4. Why is the recommendation system a battleground?
In most technical discussions, recommendation systems are often seen as part of backend engineering—low-key, complex, yet rarely in the spotlight. However, if we truly dissect how internet giants operate, we find that recommendation systems are not marginal modules but rather "infrastructure-level existences" that support the entire business model. For this reason, they can be called the "silent giants" of the internet industry.
Public data has repeatedly confirmed this. Amazon has disclosed that about 35% of purchases on its platform come directly from the recommendation system; Netflix is even more aggressive, with about 80% of viewing time driven by recommendation algorithms; YouTube is similar, with approximately 70% of views coming from recommendation systems, especially in feeds. As for Meta, although it has never provided a clear percentage, its technical team has mentioned that about 80% of the computing cycles in its internal clusters are used for recommendation-related tasks.
What do these numbers mean? Removing the recommendation system from these products is almost equivalent to pulling out the foundation. Take Meta, for example; advertising placement, user engagement time, and business conversion are almost all built on the recommendation system. The recommendation system not only determines "what users see" but also directly influences "how the platform makes money."
However, such a life-and-death system has long faced the problem of extremely high engineering complexity.
In traditional recommendation system architectures, it is challenging to cover all scenarios with a single unified model. Real-world production systems are often highly fragmented. For companies like Meta, LinkedIn, and Netflix, a complete recommendation pipeline typically runs 30 or more specialized models simultaneously: recall models, coarse ranking models, fine ranking models, re-ranking models, each optimized for different objective functions and business metrics. Behind each model, there is often one or more teams responsible for feature engineering, training, tuning, deployment, and continuous iteration.
The cost of this model is evident: engineering complexity, high maintenance costs, and difficulty in cross-task collaboration. When someone proposes "can we use one model to solve multiple recommendation problems," it means a significant reduction in complexity for the entire system. This is the goal the industry has long desired but found difficult to achieve.
The emergence of large language models provides a new possible path for recommendation systems.
LLMs have already proven in practice that they can become extremely powerful general models: they have strong transferability between different tasks, and their performance can continue to improve as data scale and computing power expand. In contrast, traditional recommendation models are often "task-specific," making it difficult to share capabilities across multiple scenarios.
More importantly, the single large model brings not only engineering simplification but also the potential for "cross-learning." When the same model handles multiple recommendation tasks simultaneously, the signals from different tasks can complement each other, making it easier for the model to evolve as the data scale increases. This is precisely the characteristic that recommendation systems have long desired but found difficult to achieve through traditional methods.
What has LLM changed? It has actually changed the transition from feature engineering to understanding capability.
From a methodological perspective, the biggest change that LLM brings to recommendation systems occurs in the core link of "feature engineering."
In traditional recommendation systems, engineers need to manually construct a large number of signals: user click history, dwell time, preferences of similar users, content tags, etc., and then explicitly tell the model, "Please make judgments based on these features." The model itself does not understand the semantics of these signals; it merely learns the mapping relationships in numerical space.
With the introduction of language models, this process has been highly abstracted. You no longer need to specify "look at this signal, ignore that signal" one by one; instead, you can directly describe the problem to the model: this is a user, this is content; this user has liked similar content in the past, and other users have given positive feedback on this content—now please judge whether this content should be recommended to this user.
The language model itself already possesses understanding capabilities; it can autonomously determine which information is an important signal and how to integrate these signals to make decisions. In a sense, it is not just executing recommendation rules but is "understanding the act of recommending."
The source of this capability lies in the fact that LLM has been exposed to vast and diverse data during the training phase, making it easier to capture subtle yet important patterns. In contrast, traditional recommendation systems must rely on engineers to explicitly enumerate these patterns; if any are overlooked, the model cannot perceive them.
From a backend perspective, this change is not unfamiliar. Just like when you ask GPT a question, it generates answers based on contextual information; similarly, when you ask it, "Will I be interested in this content?" it can also make judgments based on the existing information. To some extent, the language model itself inherently possesses the ability to "recommend."
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







