Author: Deep Thinking Circle
Have you ever thought about how an American AI company without models, products, or revenue can raise funds at a valuation of $50 billion? This price could package all of China's leading AI large model startups, including DeepSeek, Kimi, Zhipu, Minimax, and so on.
After the release of the Gemini 3 Pro model yesterday, questions arose in Silicon Valley regarding the frenzy over American AI models. Jen Zhu, founder of the energy startup PowerDynamics, posted that Google's model is the strongest, China's open-source models are more popular, Anthropic has advantages in the enterprise market, and xAI has access to Twitter. So why can OpenAI achieve $100 billion in revenue?
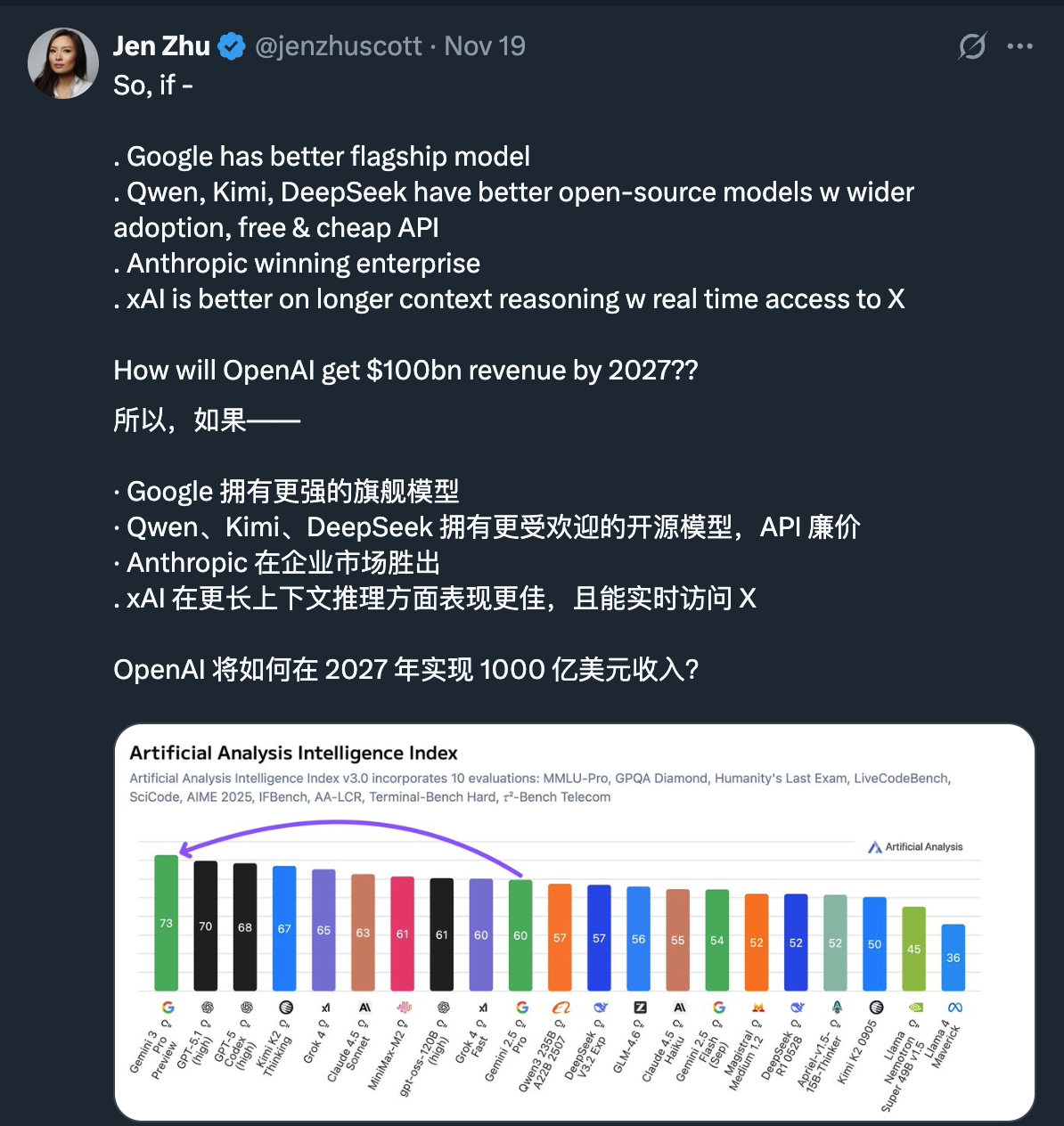
Behind the huge valuation gap between China and the U.S. AI models lies a deeper question: When Chinese AI labs can create models of equal quality at a far lower cost than Silicon Valley, can the massive investments made by tech giants in the U.S. to build data centers yield corresponding commercial returns?
I have been pondering this question. Over the past few weeks, I have closely studied the global tech community's response to the release of Kimi K2 Thinking and analyzed the significant differences in AI investment strategies between China and the U.S. I found that this is not just a valuation issue, but a collision of two entirely different AI development paths. On one side is the Silicon Valley model of massive capital accumulation, while on the other is the Chinese model that prioritizes efficiency. The outcome of this contest may redefine the future direction of the entire AI industry.
The Situation of Chinese AI in Silicon Valley Has Opened Up
Let me start with a few recent events. A couple of days ago, Perplexity announced the integration of Kimi K2 Thinking, which is currently their only Chinese model. Alongside Kimi, they also integrated OpenAI's newly released GPT-5.1. The last Chinese model integrated by Perplexity was the globally shocking DeepSeek R1 back in January. The significance of this news is far greater than it appears. As a leading global AI search engine, Perplexity is extremely selective about the models they choose; they need to ensure that the integrated models have strong performance and can reliably serve users. Being selected by Perplexity is itself a form of endorsement and certification from a global tech giant.
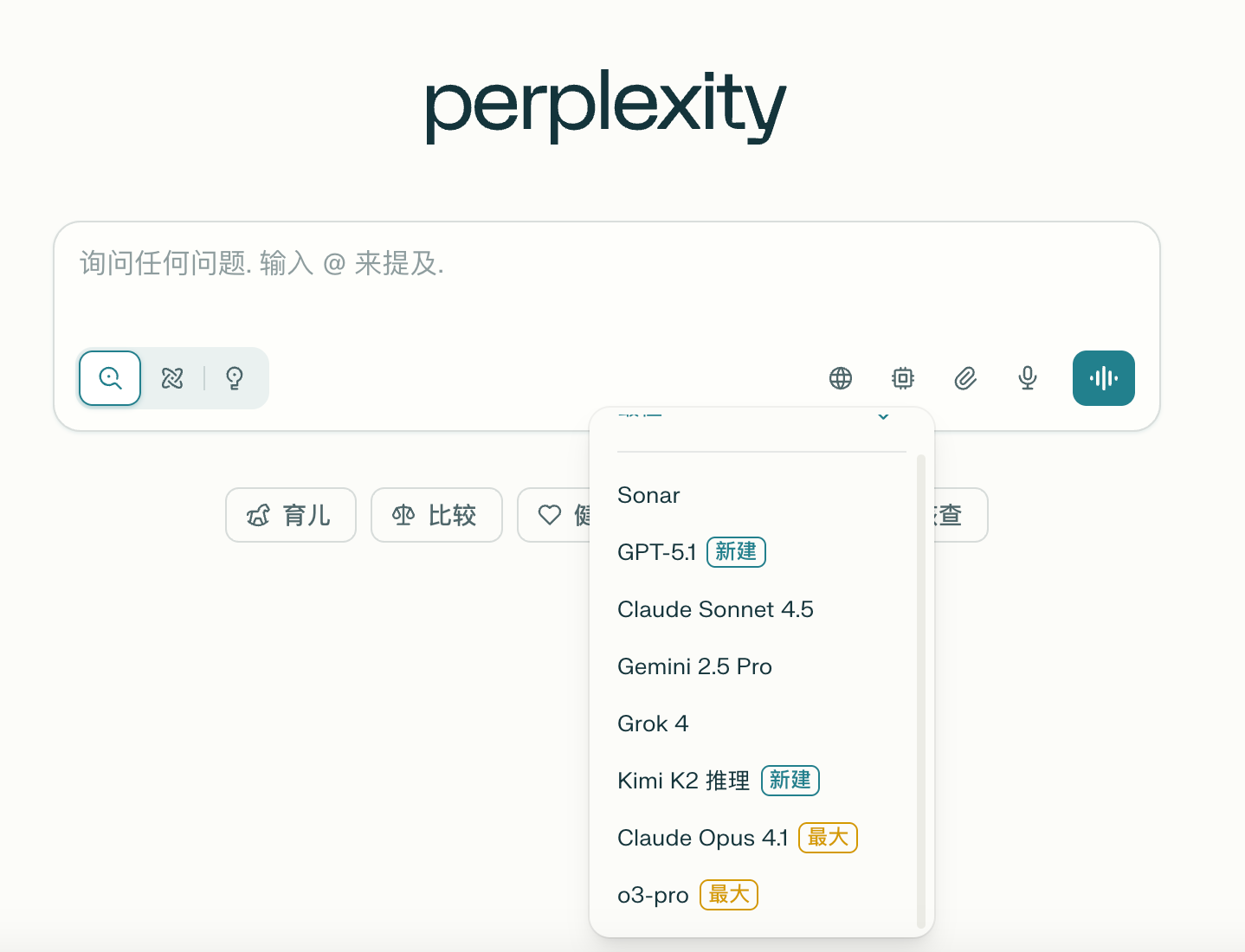
Perplexity's CEO had expressed interest in Kimi K2 back in July when it was first released, stating that they would train based on Kimi. This indicates that their attention to this model is not a fleeting interest but the result of long-term observation and evaluation. I believe this reflects an important trend: top global tech companies are increasingly taking Chinese AI models seriously, no longer viewing them as mere substitutes for domestic markets, but as genuinely competitive global products.
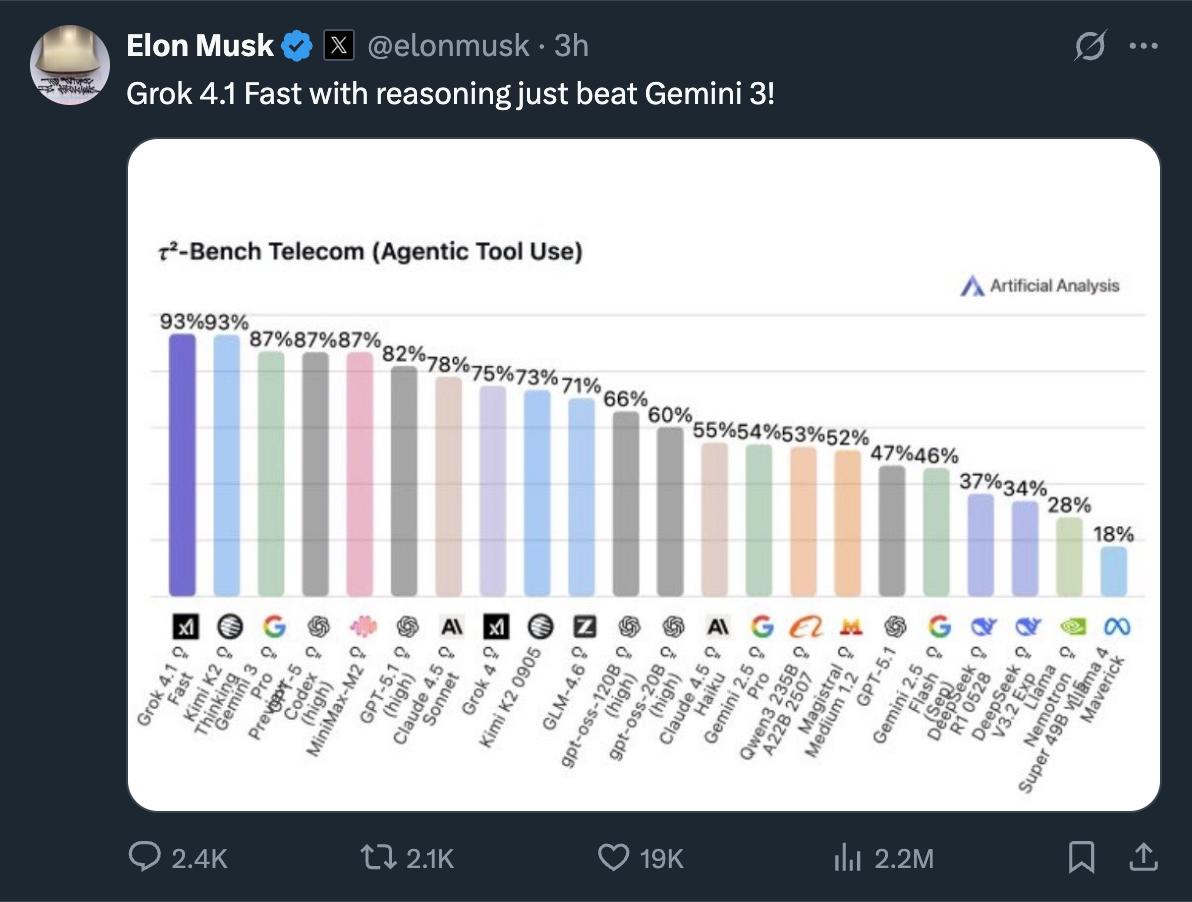
Almost simultaneously, when Musk released Grok 4.1, he made a comparative score, listing the performances of several top AI models. In this comparison, Kimi K2 was the only Chinese model treated as a "reference," and it wasn't even the latest Thinking version, just the basic K2. Even so, its score still surpassed many well-known models. I find this detail particularly noteworthy. Musk, as one of the most influential figures in the AI field, choosing to include Kimi K2 in the comparison is itself a form of recognition.

After the release of Gemini 3 Pro, Musk became anxious. When he retweeted Grok 4.1's performance surpassing that of Gemini 3 Pro, everyone noticed that the Chinese model Kimi K2 Thinking was sandwiched between the two, becoming the strongest backdrop.
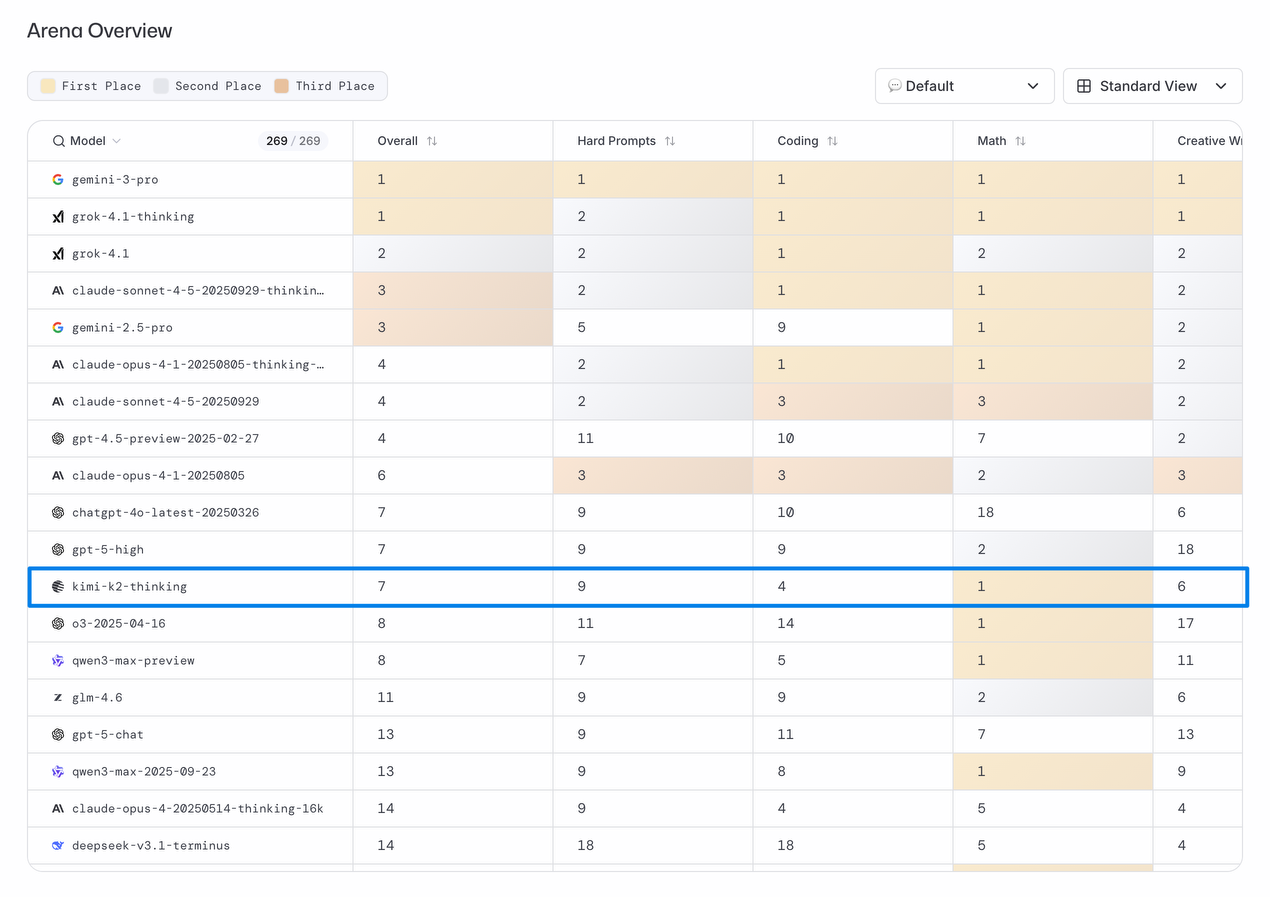
In the world's most authoritative large model arena, LM Arena, Kimi K2 Thinking once again claimed the top spot among global open-source models, ranking seventh in the overall open and closed source rankings. This ranking is not determined unilaterally by any company or institution, but is based on real user feedback and blind test results from around the world. Users rate the responses of different models without knowing which model they are using, and the rankings are compiled from these scores. This method best reflects the true performance of models in practical applications. Kimi K2 Thinking's high ranking on such a list proves that it has also gained widespread recognition in terms of user experience.
Product Growth: Kimi K2 is More Important than GPT-5.1
When OpenAI released GPT-5.1, the entire tech community was discussing its improvements. However, Aakash Gupta, a well-known product growth expert in the Silicon Valley venture capital circle, expressed an unusual viewpoint: the most important model update that week was not GPT-5.1, but Kimi K2 Thinking. This judgment comes from his in-depth practical testing. As the former VP of product at the unicorn company Apollo.io and the author of the must-read newsletter for AI product managers, "Product Growth," Aakash's evaluations carry significant weight in the Silicon Valley tech community.
He conducted a very practical test. He posed the same product decision question to both GPT-5.1 and Kimi K2 Thinking: based on user engagement data, study competitors' solutions, compare their methods, adoption rates, and pricing strategies, then score the feature options by impact and workload, and finally recommend release priorities. This is a typical scenario in a product manager's daily work, requiring both data analysis skills and product judgment.
The test results impressed Aakash. He found that Kimi used real data. Kimi extracted actual usage numbers (310, 260, 420 users) to validate its recommendations, while GPT merely scored features on an abstract impact and workload scale. Kimi thinks like a product manager, rather than working like a spreadsheet. Kimi provided actual workload in months (0.5 to 3.0 months), which is exactly what you need when planning sprints. The 1 to 5 scores given by GPT are meaningless when booking engineering time.
Most importantly, Kimi applied judgment in critical areas. This is a key moment: Kimi added, "Although the scores are similar, Battlecards have a clearer market promotion path than Feed." It understands that pure mathematics cannot capture the complexities of market promotion. GPT blindly follows its formula. GPT's suggestions are fundamentally untenable in actual product decisions. GPT told Aakash to prioritize the "report export" feature, which has an impact score of 3. Mathematically, this is correct (3÷1=3.0), but strategically, it is poor for a competitive intelligence product.
Aakash concluded that Kimi balanced quantitative scoring with product intuition. GPT-5.1 treated this as a math test, arriving at a suggestion that he would reject within the first 30 seconds of a roadmap review. This is what it looks like when expanded reasoning truly works—models do not just compute; they also validate hypotheses and check their work against real-world constraints. I find this practical test very convincing because it is not a benchmark test in a lab environment, but an application comparison in a real work scenario. This is the true value of AI models: not scoring high on test questions, but helping people make better decisions.

From "Conversational Q&A" to "Thinking While Doing"
To understand why Kimi K2 Thinking performs well, I need to explain the "Interleaved Reasoning" technique it employs. Traditional reasoning models follow a single "think → act" process; they can gather information from the internet and then stop interacting with the outside world, continuing to think. This approach may work for simple tasks, but once tasks become complex and require multi-step coordination, it is prone to errors.
Kimi K2 Thinking operates using interleaved reasoning. Its process is: plan → identify goals and break them down into steps; act → use tools (web search, code execution, document creation); verify → check if the action has brought the goal closer; reflect → adjust strategies based on results; refine → iterate until completion. If any step in the chain fails, traditional reasoning collapses entirely. In contrast, interleaved reasoning captures and corrects these failures at each step.
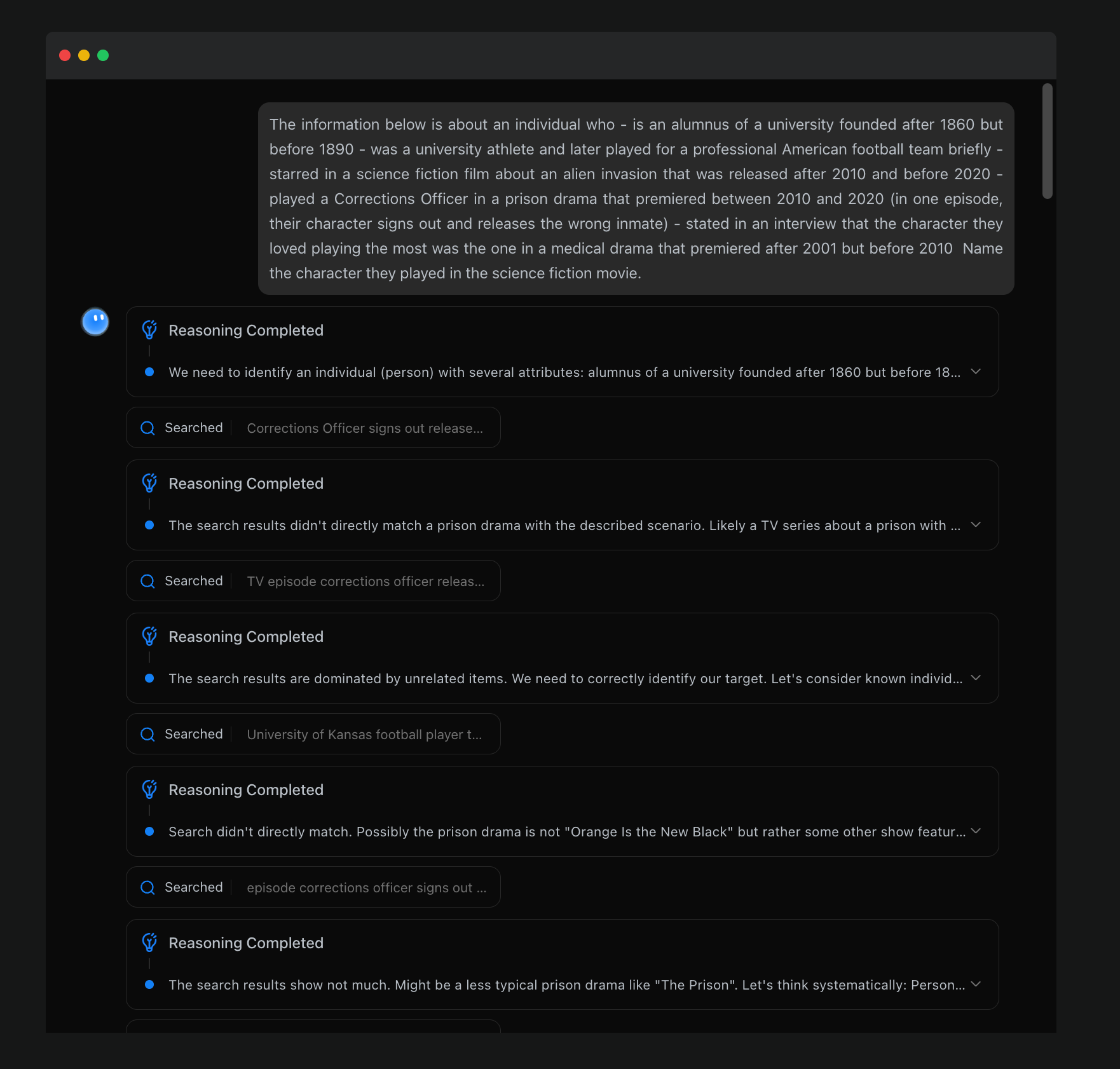
This method is crucial for building AI agents. Kimi K2 Thinking can run 200 to 300 tool calls in a single session. Each step does not reset. It validates, reflects, and refines based on what just happened. Traditional reasoning collapses at scale, while interleaved reasoning can handle this scale.
The Huge Gap in AI Investment Between China and the U.S.
Now let’s take a step back and look at the broader picture. Bloomberg recently published a report titled "Is the DeepSeek Moment Now the New Normal?" The article opens with a sharp question: When an obscure Chinese AI company releases an open-source reasoning model that challenges Western dominance, and the development cost is just a fraction of Silicon Valley's, why is there almost no market reaction? This stands in stark contrast to the situation when DeepSeek R1 was released in January, which caused Nvidia to lose nearly $600 billion in market value in a single day.

Bloomberg economist Michael Deng pointed out, "In contrast to the panic over DeepSeek in January, investors have quickly internalized the fact that Chinese labs can achieve cutting-edge capabilities at a lower cost." Have we reached a point where matching the best levels in the AI field with extremely low budgets is no longer shocking? This question has made me think deeply. If the emergence of DeepSeek earlier this year was a "black swan" event, then Kimi K2's performance now indicates that this "black swan" is becoming the norm.
The cost difference is astonishing. CNBC reported that, according to insiders, the training cost of Kimi K2 Thinking is $4.6 million. Although a member of the Moonshot team later stated in a Reddit AMA that this "is not an official figure," he cleverly pointed out the huge expenditure difference when answering a question about when the next-generation model would be released, saying it would "launch before Sam (Altman)'s trillion-dollar data center is built." This comparison is filled with irony. On one side is a training cost of millions of dollars, and on the other is a trillion-dollar data center plan.
Jefferies analysts pointed out last week that between 2023 and 2025, the total capital expenditure of China's hyperscale cloud service providers is 82% lower than that of their American counterparts. However, according to various analyses, the performance gap between their two best models is now negligible. Even in the face of lower-quality chips and fierce competition, significantly reduced expenditures indicate that China is forming a clearer path to investment returns.
I believe this gap reflects two different development philosophies. The American approach is "brutal aesthetics": stacking the most advanced hardware, building the largest data centers, and investing the most capital. This method can indeed drive rapid technological advancement when resources are abundant, but it comes at the cost of massive capital investment and longer payback periods. China's approach, on the other hand, places more emphasis on efficiency: compensating for hardware deficiencies through algorithmic innovation and architectural optimization in the face of chip limitations.
What This Means for the Global AI Industry
I believe this shift in competitive landscape will bring several important impacts. For startups and developers, they now have more choices. They no longer need to rely entirely on OpenAI or Anthropic's APIs; they can use cost-effective yet competitively performing Chinese models. This will lower the barriers to building AI applications and foster more innovation. For large tech companies, this is a wake-up call. Simply piling up capital may no longer be a reliable strategy for maintaining a competitive edge; they need to perform better in terms of efficiency and innovation.
I believe that the future development of AI will not be about one side completely replacing the other, but rather a mutual borrowing and integration of these two paths. Silicon Valley may learn from China's efficiency orientation and begin to focus more on cost-effectiveness rather than purely performance metrics. Chinese companies may learn from Silicon Valley's experiences in commercialization and ecosystem building, transforming technological advantages into greater commercial value. This competition and exchange will ultimately drive the entire industry forward.
The case of Kimi K2 teaches us that in the AI era, technological capability is no longer solely determined by capital investment. Smart algorithms, innovative architectures, and efficient engineering practices—these "soft powers" may be more important than the scale of data centers. Teams that can make innovative breakthroughs with limited resources may gain unexpected advantages in this AI race. Meanwhile, companies that overly rely on capital accumulation will need to start thinking about how to improve investment efficiency; otherwise, they may find themselves paying for an arms race that is destined to yield insufficient returns.
Ultimately, the market will provide the answer. As more and more companies begin to choose cost-effective Chinese models, as investors start to question the returns on massive investments, and as users discover that the experience differences between different models are becoming smaller, the valuation system of this industry will readjust. I look forward to the arrival of that day, as it will mark a turning point for the AI industry from being capital-driven to value-driven, from speculative bubbles to rational development.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






