Key Points Overview
Why is the idea that "any device can be a provider of computing power" still far from reality?
This report delves into the numerous challenges faced by heterogeneous distributed computing networks (DePIN) composed of PCs, mobile phones, edge devices, and more, as they transition from "technically feasible" to "economically viable." From the insights of volunteer computing projects like BOINC and Folding@home to the commercialization attempts of DePIN projects such as Golem and Akash, the report outlines the history, current state, and future of this field.
- Heterogeneous Network Challenges: How to schedule tasks, verify results, and ensure security amidst device performance differences, high network latency, and significant node fluctuations?
- Oversupply and Scarcity of Demand: Cold starts are easy, but finding real paying users is difficult. How can DePIN transition from a miner's game to real business?
- Security and Compliance: Data privacy, cross-border compliance, liability attribution… who will cover these hard issues that "decentralization" cannot avoid?
The report is approximately 20,000 words long, with an estimated reading time of 15 minutes (This report is produced by DePINOne Labs; please contact us for reprints).
1. Introduction
1.1 Definition of Heterogeneous Device Distributed Computing Networks
A distributed computing network refers to a network that utilizes geographically dispersed and diverse computing devices (such as personal computers, smartphones, IoT edge computing boxes, etc.) to aggregate the idle computing resources of these devices through internet connections to perform large-scale computing tasks.
The core idea of this model is that modern computing devices typically possess powerful processing capabilities, but their utilization is often very low (for example, an ordinary desktop computer only uses 10–15% of its capacity). Distributed computing networks aim to consolidate these underutilized resources to form a massive virtual computing cluster.
Unlike traditional High-Performance Computing (HPC) or centralized cloud computing, the most significant feature of such distributed networks is their heterogeneity.
The devices participating in the network exhibit vast differences in hardware (CPU types, GPU models, memory sizes), operating systems (Windows, macOS, Linux, Android), network connection quality (bandwidth, latency), and availability patterns (devices may go online or offline at any time).
Managing and effectively utilizing this highly heterogeneous and dynamically changing resource pool is one of the core technical challenges faced by such networks.
1.2 Historical Background: Volunteer Computing
Despite numerous challenges, the technical feasibility of utilizing distributed heterogeneous devices for large-scale computing has been thoroughly proven through decades of Volunteer Computing (VC) practice.
BOINC (Berkeley Open Infrastructure for Network Computing)
BOINC is a typical success story. It is an open-source middleware platform that employs a client/server architecture. Project teams run servers to distribute computing tasks, while volunteers run BOINC client software on their personal devices to execute these tasks. BOINC has successfully supported numerous scientific research projects across various fields, including astronomy (such as SETI@home, Einstein@Home), biomedicine (such as Rosetta@home), and climate science, leveraging volunteer computing resources to solve complex scientific problems. The computing power of the BOINC platform is astonishing, with its aggregated computing power several times that of the top supercomputers at the time, reaching PetaFLOPS levels, all derived from the idle resources of volunteers' personal computers. BOINC was designed to handle a network environment composed of heterogeneous, intermittently available, and untrusted nodes. Although establishing a BOINC project requires a certain level of technical investment (approximately three person-months of work, including system administrators, programmers, and web developers), its successful operation demonstrates the technical potential of the VC model.
Folding@home (F@h)
F@h is another well-known volunteer computing project that has focused since its launch in 2000 on helping scientists understand disease mechanisms and develop new therapies by simulating protein folding, conformational changes, and drug design through biomolecular dynamics processes. F@h also utilizes volunteers' personal computers (and even early PlayStation 3 game consoles) for large-scale parallel computing. The project has achieved significant scientific accomplishments, publishing over 226 scientific papers, with its simulation results aligning well with experimental data. Particularly during the COVID-19 pandemic in 2020, public participation surged, and the aggregated computing power of Folding@home reached ExaFLOP levels (10 quintillion floating-point operations per second), becoming the first computing system in the world to reach this scale, significantly supporting research on the SARS-CoV-2 virus and the development of antiviral drugs.
Long-running projects like BOINC and Folding@home undeniably prove that, from a technical perspective, aggregating and utilizing a large number of distributed, heterogeneous, volunteer-provided computing resources to handle specific types of parallelizable, computation-intensive tasks (especially scientific computing) is entirely feasible. They laid an important foundation for task distribution, client management, and handling unreliable nodes.
1.3 Emergence of Business Models: Golem and DePIN Computing
Building on the validation of technical feasibility through volunteer computing, recent years have seen the emergence of projects attempting to commercialize this model, particularly DePIN (Decentralized Physical Infrastructure Networks) computing projects based on blockchain and token economics.
Golem Network is one of the early explorers in this field and is considered a pioneer of the DePIN concept. It has built a decentralized computing power market that allows users to buy or sell computing resources (including CPU, GPU, memory, and storage) using its native token GLM through a peer-to-peer (P2P) approach. There are two main types of participants in the Golem network: requestors, who are users needing computing power, and providers, who share idle resources in exchange for GLM tokens. Its target application scenarios include CGI rendering, AI computing, cryptocurrency mining, and other tasks requiring substantial computing power. Golem achieves scalability and efficiency by breaking tasks into smaller sub-tasks and processing them in parallel across multiple provider nodes.
DePIN computing is a broader concept that refers to the use of blockchain technology and token incentive mechanisms to build and operate various physical infrastructure networks, including computing resources. In addition to Golem, other projects have emerged, such as Akash Network (providing decentralized cloud computing services), Render Network (focusing on GPU rendering), io.net (aggregating GPU resources for AI/ML), and many others. The common goal of these DePIN computing projects is to challenge traditional centralized cloud service providers (such as AWS, Azure, GCP) by offering lower-cost and more flexible computing resources through decentralization. They aim to leverage token economic models to incentivize hardware owners worldwide to contribute resources, thereby forming a vast, on-demand distributed computing network.
The shift from volunteer computing primarily relying on altruism or community reputation (points) as incentives to DePIN adopting tokens for direct economic incentives represents a change in model. DePIN seeks to create a financially sustainable and more universal distributed computing network, aiming to go beyond specific fields like scientific computing to serve broader market demands.
However, this transition also introduces new complexities, particularly in market mechanism design and the stability of token economic models.
Preliminary Assessment: Observations of Oversupply and Insufficient Demand
The current core dilemma faced by the DePIN computing field is not how to get users to participate in the network to contribute computing power, but how to ensure that the computing power supply network can genuinely meet and serve various computing demands.
- Supply is easy to guide: Token incentives are very effective in guiding suppliers to join the network.
- Demand is hard to prove: Generating real, paying demand is much more challenging. DePIN projects must provide competitive products or services that solve real problems, rather than relying solely on token incentives.
- Volunteer computing has proven technical feasibility, but DePIN must prove economic feasibility, which depends on whether it can effectively address demand-side issues. The success of volunteer computing projects (like BOINC, F@h) is due to the intrinsic value of "demand" (scientific computing) for the researchers running the projects, while the motivation for suppliers is altruism or interest.
DePIN constructs a market where suppliers expect economic returns (tokens), while demanders must perceive the value of the service to exceed its cost. Guiding supply with tokens is relatively straightforward, but creating genuine paying demand requires building services that can compete with or even surpass centralized services (like AWS). Current evidence suggests that many DePIN projects still face significant challenges in the latter.
2. Core Technical Challenges of Heterogeneous Distributed Networks
Building and operating a heterogeneous distributed computing network composed of mobile phones, personal computers, IoT devices, and more faces a series of severe technical challenges. These challenges stem from the physical dispersion of network nodes, the diversity of devices themselves, and the unreliability of participants.
2.1 Management of Device Heterogeneity
Devices in the network exhibit vast differences at the hardware level (CPU/GPU types, performance, architectures like x86/ARM, available memory, storage space) and software level (operating systems like Windows/Linux/macOS/Android and their versions, installed libraries and drivers). This heterogeneity makes it extremely difficult to reliably and efficiently deploy and run applications across the entire network. A task written for a specific high-performance GPU may not run on a low-end mobile phone or may do so with very low efficiency.
BOINC's Response
BOINC addresses heterogeneity by defining "platforms" (combinations of operating systems and hardware architectures) and providing specific "application versions" for each platform. It also introduces a "Plan Class" mechanism that allows for more detailed task distribution based on specific hardware features (such as particular GPU models or driver versions). Additionally, BOINC supports running existing executables using wrappers or running applications in virtual machines (like VirtualBox) and containers (like Docker) to provide a unified environment across different hosts, although this incurs additional performance overhead.
DePIN's Response
Many DePIN computing platforms also rely on containerization technologies (for example, Akash uses Docker) or specific runtime environments (such as Golem's gWASM, which may also support VM/Docker) to abstract the differences in underlying hardware and operating systems, thereby improving application compatibility. However, fundamental performance differences between devices still exist. Therefore, the task scheduling system must be able to accurately match tasks to nodes with the corresponding capabilities.
Device heterogeneity significantly increases the complexity of application development, deployment, task scheduling (matching tasks to suitable nodes), performance prediction, and result verification. While virtualization and containerization provide a certain degree of solution, they cannot completely eliminate performance differences. To efficiently utilize the diverse hardware resources in the network (especially dedicated accelerators like GPUs and TPUs), complex scheduling logic is required, and it may even be necessary to prepare different optimized application versions for different types of hardware, further increasing complexity. Relying solely on generic containers may lead to underutilization of dedicated hardware performance.
2.2 Network Latency and Bandwidth Limitations
Network latency refers to the time required for data to be transmitted between network nodes. It is primarily affected by physical distance (propagation delay due to the speed of light), network congestion (leading to queuing delays), and device processing overhead. High latency can significantly reduce the system's responsiveness and throughput, affecting user experience and hindering the execution of tasks that require frequent interaction between nodes. In high-bandwidth networks, latency often becomes a performance bottleneck.
Bandwidth refers to the maximum amount of data that can be transmitted over a network connection in a given time. Insufficient bandwidth can lead to network congestion, further increasing latency and reducing the actual data transmission rate (throughput). Volunteer computing and DePIN networks typically rely on participants' home or mobile internet connections, which may have limited and unstable bandwidth (especially upload bandwidth).
High latency and low bandwidth greatly limit the types of workloads suitable for running on such networks. Tasks that require frequent communication between nodes, need to transmit large amounts of input/output data relative to the computation, or demand real-time responses are often impractical or inefficient in this environment. Network limitations directly affect task scheduling strategies (data locality becomes crucial, meaning computation should be close to the data) and the efficiency of result transmission. Particularly for tasks like AI model training that require substantial data transfer and synchronization, the bandwidth of consumer-grade networks may become a severe bottleneck.
Network limitations are the result of the interplay between physical laws (latency constrained by the speed of light) and economic factors (bandwidth costs). This makes distributed computing networks inherently more suitable for computation-intensive, sparsely communicating, and easily parallelizable "embarrassingly parallel" tasks. Compared to centralized data centers with high-speed internal networks, the communication efficiency and reliability of such network environments are generally poorer, fundamentally limiting the range of applications and market scale they can effectively serve.
2.3 Node Dynamics and Reliability
The devices (nodes) participating in the network exhibit high dynamics and unreliability. Nodes may join or leave the network at any time (referred to as "churn"), and devices may unexpectedly lose power, lose network connectivity, or be turned off by users. Additionally, these nodes are often untrusted and may return erroneous results due to hardware failures (such as instability caused by overclocking) or malicious behavior.
This dynamism can interrupt task execution, leading to wasted computing resources. Unreliable nodes can affect the correctness of the final results. High churn rates make it difficult to complete long-running tasks and pose challenges for task scheduling. Therefore, the system's fault tolerance becomes crucial.
In general, there are several strategies to cope with node instability:
- Redundant computation/replication: Assign the same task to multiple independent nodes for execution, then compare their results. Only when the results are consistent (or within an acceptable error range) are they accepted as valid. This can effectively detect errors and malicious behavior, improving the reliability of results, but at the cost of increased computational overhead. BOINC also employs an adaptive replication strategy based on host historical reliability to reduce overhead.
- Checkpointing: Allows applications to periodically save their intermediate states. When a task is interrupted, it can resume execution from the most recent checkpoint rather than starting from scratch. This greatly mitigates the impact of node churn on task progress.
- Deadlines & Timeouts: Set a completion deadline for each task instance. If a node fails to return a result before the deadline, that instance is assumed to have failed, and the task is reassigned to other nodes. This ensures that even if some nodes are unavailable, the task can still be completed.
- Work Buffering: Clients pre-download enough tasks to ensure that the device can continue working even when temporarily losing network connectivity or unable to fetch new tasks, maximizing resource utilization.
Handling unreliability is a core principle of distributed computing network design, rather than an additional feature. Since nodes cannot be directly controlled and managed as in centralized data centers, the system must rely on statistical methods and redundancy mechanisms to ensure task completion and result correctness. This inherent unreliability and its coping mechanisms increase the complexity and overhead of the system, thereby affecting overall efficiency.
2.4 Task Management Complexity: Segmentation, Scheduling, and Verification
Task segmentation: First, a large computational problem needs to be broken down into many small task units (workunits) that can be executed independently. This requires the problem itself to have a high degree of parallelism, ideally in an "embarrassingly parallel" structure, meaning that there are almost no dependencies or communication requirements between sub-tasks.
Task scheduling: Effectively allocating these task units to suitable nodes in the network for execution is one of the core and most challenging problems in distributed computing. In heterogeneous, dynamic network environments, the task scheduling problem is often proven to be NP-complete, meaning there is no known polynomial-time optimal solution. Scheduling algorithms must consider multiple factors:
- Node heterogeneity: Differences in nodes' computing capabilities (CPU/GPU), memory, storage, architecture, etc.
- Node dynamics: Node availability, online/offline patterns, churn rates.
- Network conditions: Latency and bandwidth between nodes.
- Task characteristics: Computational load, memory requirements, data volume, dependencies (if dependencies exist between tasks, they are usually represented as directed acyclic graphs, DAGs), deadlines.
- System policies: Resource share allocation (such as BOINC's Resource Share), priorities.
- Optimization objectives: These may include minimizing total completion time (makespan), minimizing average task turnaround time (flowtime), maximizing throughput, minimizing costs, ensuring fairness, improving fault tolerance, etc., which may conflict with each other.
Scheduling strategies can be static (allocated all at once before the task starts) or dynamic (adjusting allocations based on the real-time state of the system, further divided into online and batch modes). Due to the complexity of the problem, heuristic algorithms, meta-heuristic algorithms (such as genetic algorithms, simulated annealing, ant colony optimization, etc.), and AI-based methods (such as deep reinforcement learning) have been widely researched and applied. The BOINC client uses local scheduling strategies (including work fetching and CPU scheduling) to attempt to balance multiple objectives such as deadlines, resource shares, and maximizing point acquisition.
Result verification: Since nodes are untrusted, the correctness of returned results must be verified.
- Replication-based verification: This is the most commonly used method, where multiple nodes compute the same task and then compare results. BOINC uses this method and provides "homogeneous redundancy" for tasks that require results to be identical, ensuring that only nodes with the same hardware and software environment participate in the same task's replicated computation. Golem also uses redundancy verification and may adjust verification frequency (probabilistic verification) based on provider reputation or employ spot-checking. This method is simple and effective but incurs high costs (doubling or more of the computational load).
- Non-deterministic problems: For certain computational tasks, especially AI inference executed on GPUs, even with the same input, outputs may exhibit slight differences across different hardware or runtime environments (computational non-determinism). This renders replication verification methods based on exact result matching ineffective. New verification methods need to be adopted, such as comparing the semantic similarity of results (for AI outputs) or using statistical methods (like the SPEX protocol) to provide probabilistic correctness guarantees.
- Cryptographic methods: Verifiable computation techniques provide a way to verify the correctness of computations without needing to repeat them.
- Zero-Knowledge Proofs (ZKPs): Allow a prover (computing node) to demonstrate to a verifier that a computation result is correct without revealing any input data or intermediate processes of the computation. This holds great promise for privacy protection and improving verification efficiency, but generating ZKPs typically requires substantial computational overhead, limiting their application in complex computations.
- Fully Homomorphic Encryption (FHE): Allows arbitrary computations to be performed directly on encrypted data, yielding encrypted results that, when decrypted, match the results of computations performed on plaintext. This can achieve high levels of privacy protection, but current FHE schemes have extremely low computational efficiency and high costs, far from achieving large-scale practicality.
- Trusted Execution Environments (TEEs): Utilize hardware features (such as Intel SGX, AMD SEV) to create an isolated and protected memory area (enclave), ensuring the confidentiality and integrity of the code and data running within it, and can provide proof to remote parties (remote attestation). TEEs offer a relatively efficient verification method, but they depend on specific hardware support, and their security also relies on the security of the hardware itself and the associated software stack.
Task management, especially scheduling and verification, is significantly more complex in heterogeneous, unreliable, and untrusted distributed networks than in centralized cloud environments. Scheduling is an actively ongoing research area (an NP-complete problem), while verification faces fundamental challenges such as non-determinism and verification costs, which limit the types of computational tasks that can be reliably and economically executed and verified.
2.5 Security and Privacy Protection Across Devices
Threat Environment: Distributed computing networks face security threats from multiple levels:
- Node Level: Malicious nodes may return forged results or falsely report computational workloads to cheat rewards. Nodes controlled by attackers may be used to run malicious code (if the project server is compromised, attackers may attempt to distribute viruses disguised as computational tasks). Nodes may try to access sensitive data from the host system or other nodes. Internal threats from volunteers or providers should not be overlooked.
- Network Level: Project servers may suffer from denial-of-service (DoS) attacks, such as being overwhelmed by a large amount of invalid data. Network communications may be subject to eavesdropping (Packet Sniffing), leading to the leakage of account information (such as keys, email addresses). Attackers may conduct man-in-the-middle attacks or IP spoofing.
- Project Level: Project teams may intentionally or unintentionally release applications containing vulnerabilities or malicious features that harm participants' devices or privacy. Input or output data files of the project may be stolen.
- Data Privacy: Processing data on untrusted nodes inherently carries privacy risks, especially when it involves personally identifiable information (PII), commercially sensitive data, or regulated data (such as medical information). Data may also be intercepted during transmission. Compliance with data protection regulations such as GDPR and HIPAA is extremely challenging in a distributed environment.
Mitigation Mechanisms:
- Result and Reputation Verification: Verify the correctness of results through redundant computation and detect malicious nodes. Establish a reputation system (like Golem) to score and filter nodes based on their historical behavior.
- Code Signing: Project teams digitally sign the applications they release. Clients verify the signature before running tasks to ensure the code has not been tampered with, preventing the distribution of malicious code (BOINC employs this mechanism).
- Sandboxing and Isolation: Run computational tasks in restricted environments (such as low-privilege user accounts, virtual machines, containers) to prevent tasks from accessing sensitive files or resources on the host system. TEEs provide hardware-based strong isolation.
- Server Security: Implement traditional server security measures, such as firewalls, encrypted access protocols (SSH), disabling unnecessary services, and conducting regular security audits. BOINC also provides upload certificates and size limit mechanisms to prevent DoS attacks on data servers.
- Authentication and Encryption: Use strong authentication methods (such as multi-factor authentication MFA, tokens, biometrics). Communication between nodes uses mTLS encryption (like Akash). Encrypt data in transit and at rest.
- Network Security: Employ network segmentation, zero-trust architecture, continuous monitoring, and intrusion detection systems to protect network communications.
- Trusted Providers: Allow users to choose providers that have been audited and certified by trusted third parties (like Akash's Audited Attributes).
- Privacy Protection Technologies: Although costly, technologies like FHE and ZKP can theoretically provide stronger privacy protection.
Security is a multidimensional issue that requires protecting the integrity and privacy of project servers, participant nodes, network communications, and the computational process itself. Despite various mechanisms such as code signing, redundant computation, and sandboxing, the inherent untrustworthiness of participants demands that system designers remain vigilant and accept the additional overhead that comes with it. For commercial applications or scenarios involving sensitive data, ensuring data privacy on untrusted nodes remains a significant challenge and a major barrier to adoption.
3. DePIN Dilemma: Matching Supply and Demand for Computing Power
This section will delve into the difficulties of supply and demand matching, particularly in the areas of workload allocation, service discovery, quality assurance, and market mechanism design.
3.1 Why is Demand Harder to Generate than Supply?
In the DePIN model, it is relatively easy to attract suppliers of computing resources (nodes) to join the network using token incentives. Many individuals and organizations have idle computing hardware (especially GPUs) and connect it to the network in hopes of earning token rewards, which is often seen as a low-barrier, low-friction way to participate. The potential value of tokens is sufficient to drive early growth on the supply side, creating what is known as a "cold start."
However, generating demand follows a completely different logic and faces greater challenges. Simply having a large supply of computing power does not mean the network has economic value. Sustainable demand must come from users willing to pay for the use of this computing power. This means that the computing services provided by DePIN platforms must be sufficiently attractive, capable of solving users' real problems, and superior to or at least not worse than existing centralized solutions (such as AWS, GCP, Azure) in terms of cost, performance, or specific features.
Token incentives alone cannot create this real demand; they can only attract supply.
The current market situation confirms this. In the decentralized storage field (such as Filecoin), there has already been a noticeable oversupply and low utilization issue, with token economic activities revolving more around miners and speculation rather than meeting end-user storage needs. In the computing field, although scenarios like AI and 3D rendering present potential huge demand, DePIN platforms still face challenges in actually meeting these needs. For example, io.net aggregates a large number of GPUs, but consumer-grade GPUs may lack the bandwidth and stability to support large-scale AI training, leading to low actual utilization. Render Network, while benefiting from OTOY's user base, has a token burn rate far below its issuance rate, indicating that actual application adoption remains insufficient.
Therefore, the DePIN model naturally tends to promote supply through tokenization. However, generating demand requires going through the traditional "product-market fit" process, overcoming strong market inertia, and competing with established centralized service providers, which is essentially a more difficult business challenge. This asymmetry in the mechanisms of supply and demand generation is the core economic dilemma currently faced by the DePIN computing model.
3.2 Challenges in Workload Allocation and Service Discovery
In DePIN computing networks, effectively allocating users' computational tasks (demand) to suitable computing resources in the network (supply) is a complex process involving service discovery and workload matching.
Complexity of Matching: Demand-side users often have very specific requirements, such as needing a specific model of GPU, a minimum number of CPU cores, memory size, storage capacity, specific geographic locations (to reduce latency or meet data sovereignty requirements), or even specific security or compliance certifications. The resources provided by the supply side are highly heterogeneous. Accurately matching each demand to a cost-effective provider that meets all conditions in a large and dynamically changing supply pool is a daunting task.
Service Discovery Mechanisms: How do users find providers that meet their needs? DePIN platforms typically adopt market-based approaches to solve service discovery issues:
- Marketplace/Order Book: The platform provides a marketplace where providers list their resources and quotes, and demanders post their needs and the prices they are willing to pay. For example, Akash Network adopts this model and combines it with a reverse auction mechanism.
- Task Templates & Registry: The Golem network allows demanders to describe their computational needs using predefined or custom task templates and to find providers capable of executing these template tasks through an application registry.
- Auction Mechanisms: Akash's reverse auction (where demanders set a maximum price and providers bid) is a typical example aimed at lowering prices through competition.
Pricing Mechanisms: Prices are usually determined by market supply and demand dynamics but may also be influenced by provider reputation, resource performance, service levels, etc. For example, Render Network employs a multi-tiered pricing strategy that considers speed, cost, security, and node reputation.
Current Limitations
Existing matching mechanisms may not be optimal. Simply finding "available" resources is not enough; the key is to find "suitable" resources. As mentioned earlier, consumer-grade hardware may be unable to handle AI training tasks due to insufficient bandwidth, even if its GPU computing power is adequate. Finding providers that meet specific compliance (such as HIPAA) or security standards may also be challenging, as providers in the DePIN network come from diverse backgrounds.
Effective workload allocation requires far more than simple resource availability checks. It necessitates complex discovery, matching, and pricing mechanisms that can accurately reflect providers' capabilities, reliability, and the specific requirements of demanders. These mechanisms are still evolving and improving in current DePIN platforms. If the matching process is inefficient or yields poor results (for example, assigning bandwidth-intensive tasks to low-bandwidth nodes), user experience will suffer, and the value proposition of DePIN will be weakened.
3.3 Challenges in Ensuring Quality of Service (QoS)
In traditional centralized cloud computing, service providers typically commit to certain quality levels through service level agreements (SLAs), such as guaranteeing specific uptime and performance metrics. Although the execution of these SLAs may sometimes favor the provider, they at least provide a formal framework for quality expectations.
In a DePIN network composed of numerous unreliable and uncontrolled nodes, providing similar QoS guarantees is much more difficult.
- Lack of Centralized Control: No single entity can fully control and manage the performance and reliability of all nodes.
- Difficulty in Verifying Off-Chain Events: The blockchain itself cannot directly observe and verify real-world events occurring off-chain, such as whether a computing node has truly achieved the promised computational speed or whether its network connection is stable. This complicates the automated execution of QoS based on blockchain.
- Individual Default Risk: In a decentralized market, any participant (provider or demander) may violate agreements. Providers may fail to deliver the promised QoS, and demanders may refuse to pay.
To establish trust and attempt to ensure QoS in a decentralized environment, several mechanisms have emerged:
- Witness Mechanisms: Introduce independent third-party "witnesses" (usually incentivized community members) responsible for monitoring off-chain service quality and reporting to the network in case of SLA violations. The effectiveness of this mechanism relies on reasonable incentive design to ensure that witnesses fulfill their duties honestly.
- Reputation Systems: Establish reputation scores by tracking providers' historical performance (such as task success rates, response times, reliability). Demanders can choose providers based on reputation, while providers with poor reputations will struggle to obtain tasks. This is one of the key mechanisms adopted by Golem.
- Audited Providers: Rely on trusted auditing institutions to review and certify providers' hardware, security standards, and operational capabilities. Demanders can choose to use only audited providers, thereby increasing the credibility of service quality. Akash Network is implementing this model.
- Staking/Slashing: Require providers to stake a certain amount of tokens as collateral. If providers behave improperly (such as providing false resources, failing to complete tasks, or engaging in malicious behavior) or fail to meet certain service standards, their staked tokens will be "slashed." This provides economic constraints for providers to act honestly.
Overall, QoS guarantees in DePIN networks are generally weaker and less standardized than traditional cloud SLAs. They currently rely more on provider reputation, audit results, or basic redundancy mechanisms rather than strict, enforceable contractual guarantees.
The lack of strong and easily enforceable QoS guarantees is a major barrier to the adoption of DePIN by enterprise users and critical business applications. Establishing reliable service quality expectations and trust without centralized control is a key issue that DePIN must address to mature. Centralized clouds achieve SLAs by controlling hardware and networks, while DePIN needs to rely on indirect mechanisms based on economic incentives and community oversight, the reliability of which still needs to be tested by the market over the long term.
3.4 Market Mechanisms: Pricing, Reputation, and Provider Selection
Effective market mechanisms are key to the successful matching of supply and demand and the establishment of trust on DePIN platforms.
DePIN typically adopts market-driven pricing methods aimed at providing lower costs through competition compared to fixed prices in centralized clouds. Common pricing mechanisms include:
- Auctions/Order Books: Such as Akash's reverse auction, where demanders set price ceilings and providers bid.
- Negotiated Pricing: For example, Golem allows providers and demanders to negotiate prices to some extent.
- Tiered Pricing: For instance, Render offers different pricing tiers based on speed, cost, security, reputation, etc. The price discovery process can be quite complex, requiring a balance of interests between supply and demand sides.
In decentralized markets filled with anonymous or pseudonymous participants, reputation is an indispensable part of building trust. The Golem network uses an internal reputation system to score providers and demanders based on task completion, payment timeliness, result accuracy, and other factors. The reputation system helps identify and exclude malicious or unreliable nodes.
Users need effective tools to filter and select reliable providers that can meet their needs. Golem primarily relies on reputation scores to help users filter providers; Akash Network has introduced the concept of "Audited Attributes." Users can specify in their Service Deployment Language (SDL) files to only accept bids from providers that have been audited by trusted entities (such as the Akash core team or other future auditors). Additionally, the community is discussing the introduction of a user rating system (Tier 1) and the integration of broader third-party audits (Tier 2). Akash also attracts high-quality, committed providers to join the network through its Provider Incentives Program.
The biggest challenge facing reputation systems is the potential for manipulation (such as score inflation). The effectiveness of the auditing mechanism depends on the credibility of the auditors and the rigor of the auditing standards. Ensuring that there are enough high-quality providers of various types in the network, and that these providers can be easily discovered by demanders, remains an ongoing challenge. For example, although the utilization rate of A100 GPUs on the Akash network is high, their absolute numbers are still lacking, making it difficult to meet all demands.
Effective market mechanisms are crucial for the success of DePIN. While mechanisms like auctions help with price competition, reputation and audit systems are key supplements for controlling quality and reducing risk. The maturity, reliability, and resistance to manipulation of these mechanisms directly affect users' confidence in and willingness to adopt the platform. If users cannot reliably find high-quality providers that meet their needs through these mechanisms, the efficiency and attractiveness of the DePIN market will be significantly diminished.
4. Economic Feasibility: Incentives and Token Economics
One of the core innovations of DePIN lies in its attempt to address the incentive issues in the construction and operation of distributed infrastructure through token economics. This section will explore the evolution of incentive mechanisms from volunteer computing to DePIN, the design challenges of computing network token economic models, and how to balance contributor rewards with consumer value.
4.1 Evolution of Incentive Mechanisms: From BOINC Credits to DePIN Tokens
Volunteer computing projects like BOINC primarily rely on non-economic incentives. BOINC established a "credit" system that quantifies participants' contributions based on the amount of computation completed (usually based on FLOPS or CPU time from benchmarks). The main purpose of these credits is to provide reputation, satisfy participants' competitive psychology (for example, through team rankings), and gain recognition within the community. Credits themselves typically do not have direct monetary value and cannot be traded. The design goal of BOINC's credit system is fairness, difficulty to forge, and support for cross-project credit tracking (achieved through third-party websites).
DePIN projects use cryptocurrency tokens (such as Golem's GLM, Akash's AKT, Render's RNDR/RENDER, Helium's HNT, Filecoin's FIL, etc.) as their core incentive mechanism. These tokens typically have multiple functions:
- Medium of Exchange: Used as a payment method for purchasing services (such as computing, storage, bandwidth) within the platform.
- Incentives: Reward participants who contribute resources (such as computing power, storage space, network coverage), serving as a key tool for guiding supply-side bootstrapping.
- Governance: Token holders can usually participate in the network's decision-making processes, such as voting on protocol upgrades, parameter adjustments, and fund usage.
- Staking: Used to ensure network security (for example, Akash's validation nodes need to stake AKT) or may serve as a condition for providing or accessing services.
This represents a fundamental shift from BOINC's non-financial, reputation-based credit system to DePIN's direct financial, token-based incentive system. DePIN aims to attract a broader and more commercially motivated resource supply by providing direct economic returns. However, this also introduces a series of new complexities, such as cryptocurrency market volatility, token valuation, and the sustainability of economic models. The value of token rewards is no longer stable credits but is linked to market prices, making the incentive effects unstable and posing challenges for designing sustainable economic cycles.
4.2 Designing Sustainable Token Economic Models for Computing Networks
The ideal DePIN token economic model aims to create a positive feedback loop, known as the "Flywheel Effect." The logic is: Token incentives attract resource supply → The formed resource network provides services → Valuable services attract paying users (demand) → User payments (or token consumption) increase the value or utility of the tokens → Increased token value or enhanced utility further incentivizes supply-side participation or retention → Increased supply enhances network capacity, attracting more demand.
Core Challenges
- Balancing Supply and Demand Incentives: Finding a balance between rewarding supply-side participants (usually through token issuance/release, i.e., inflation) and driving demand-side participants (through token burning/locking/usage, i.e., deflation or utility) is a core difficulty in design. Many projects face high inflation rates and insufficient token consumption on the demand side, making it difficult to maintain token value.
- Linking Rewards to Value Creation: Incentive mechanisms should be linked as closely as possible to real, valuable contributions to the network (such as successfully completing computational tasks, providing reliable services), rather than just simple participation or online duration.
- Long-term Sustainability: As the early token releases decrease or market conditions change, the model needs to continuously incentivize participants to avoid network shrinkage due to insufficient incentives.
- Managing Price Volatility: Severe fluctuations in token prices directly affect providers' income expectations and demanders' usage costs, posing significant challenges to the stability of the economic model. Akash Network introduced USDC payment options partly to address this issue.
Model Examples
- Golem (GLM): Primarily positioned as a payment token used to settle computing service fees. Its value is directly related to the network's usage. The project migrated from GNT to the ERC-20 standard GLM token.
- Render Network (RNDR/RENDER): Adopts a "Burn-and-Mint Equilibrium" (BME) model. Demanders (render task submitters) burn RENDER tokens to pay for service fees, while providers (GPU node operators) receive rewards by minting new RENDER tokens. Theoretically, if demand (burning volume) is sufficiently large, exceeding the minting volume of rewards, RENDER could become a deflationary token. The project has migrated its token from Ethereum to Solana.
- Akash Network (AKT): The AKT token is primarily used for network security (staking by validation nodes), governance voting, and is the default settlement currency within the network (although USDC is also supported now). The network charges a portion of the fee (Take Fee) from each successful lease to reward AKT stakers. The AKT 2.0 upgrade aims to further optimize its token economics.
DePIN token economics is still in a highly experimental stage. Finding a model that can effectively bootstrap the network, continuously incentivize participation, and closely link incentives to real economic activities is extremely challenging. Many existing models seem to face inflationary pressures or overly rely on market speculation rather than intrinsic value. If the rate of token issuance far exceeds the consumption or purchasing pressure generated by actual use, token prices may decline. A price drop would reduce incentives for providers, potentially leading to a contraction in supply. Therefore, strongly linking token value to the actual usage of network services (demand) is crucial for the long-term survival of DePIN.
4.3 Balancing Contributor Rewards and Consumer Value Propositions
DePIN platforms must achieve a delicate balance in two areas:
- Rewards for Suppliers: Rewards (primarily in tokens) must be attractive enough to incentivize a sufficient number of high-quality providers to join and continuously operate their computing resources.
- Value for Demanders: The prices offered to consumers (computing task demanders) must be significantly lower than or superior in performance/functionality to centralized alternatives (such as AWS, GCP) to effectively attract demand.
DePIN projects claim that their "asset-lite" model (where protocol developers do not directly own hardware) and the ability to utilize underutilized resources allow them to provide services at lower operational costs, thereby rewarding providers while also offering lower prices to consumers. This is especially true for providers whose hardware has already depreciated or have lower operational costs (such as those using consumer-grade hardware), as their expected return rates may be lower than those of large data centers.
Challenges in Maintaining Supply-Demand Balance
- Token Volatility: The instability of token prices makes it difficult to maintain this balance. If token prices drop significantly, providers' actual income will decrease, potentially leading them to exit the network unless service prices are raised (in token terms), which would weaken consumer appeal.
- Service Quality and Price Matching: The price consumers pay must not only be low but also provide reliable service quality (QoS) that matches it. Ensuring that providers can consistently deliver performance and stability that meet demand is key to maintaining the value proposition.
- Competitive Pressure: Competition among DePIN projects may lead to a "race to the bottom" in rewards, offering unsustainable high rewards to attract early users, which can harm long-term economic health.
The economic feasibility of DePIN depends on finding a sustainable balance point: at this balance point, providers can earn sufficient income (considering costs such as hardware, electricity, time, and token value fluctuations), while consumers pay prices significantly lower than those of cloud giants and receive acceptable services. This balance window may be quite narrow and is very sensitive to market sentiment and token prices. Providers have actual operational costs, and token rewards must cover these costs and provide profits while also considering the value risk of the tokens themselves. Consumers will directly compare DePIN's prices and performance with AWS/GCP. DePIN must demonstrate a significant advantage in some dimension (primarily cost) to win demand. The internal fee mechanisms (such as transaction fees, lease fees) or token burning mechanisms must be able to provide sufficient rewards to providers while maintaining price competitiveness for consumers. This is a complex optimization problem, especially in the context of severe fluctuations in cryptocurrency prices.
5. The Impact of Legal and Regulatory Issues
DePIN projects, especially those involving cross-border distributed computing networks, inevitably encounter complex legal and regulatory issues in their operations. These issues involve data sovereignty, privacy regulations, cross-border data flows, token classification, and the attribution of responsibility in decentralized governance.
5.1 Data Sovereignty, Privacy Regulations, and Cross-Border Data Flows
Data Sovereignty: Many countries have enacted laws requiring that certain types of data (especially sensitive data or personal data of citizens) must be stored or processed within their borders. DePIN networks are inherently globally distributed, and computing tasks and data may flow between nodes in different countries, which can easily conflict with various countries' data sovereignty regulations.
Privacy Regulations: Regulations such as the EU's General Data Protection Regulation (GDPR) impose extremely strict rules on the collection, processing, storage, and transmission of personal data. If the DePIN network processes data involving personally identifiable information (PII) or user behavior (for example, certain inputs or outputs of computing tasks may contain such information), it must comply with these regulations. GDPR has extraterritorial effect, meaning that even if the DePIN platform or nodes are located outside the EU, they must comply with GDPR if their services or monitoring activities involve EU residents. Ensuring that all nodes in a distributed network composed of numerous anonymous or pseudonymous participants comply with regulations like GDPR is a significant challenge.
Cross-Border Data Flows: Transferring data from one jurisdiction to another is subject to strict legal restrictions. For example, GDPR requires that the receiving country must provide a level of data protection that is "essentially equivalent" to that of the EU (i.e., "adequacy determination"), or additional safeguards must be implemented, such as standard contractual clauses (SCCs) and impact assessments. The U.S. CLOUD Act allows U.S. law enforcement agencies to require service providers headquartered in the U.S. to provide data stored anywhere in the world, further exacerbating legal conflicts regarding international data transfers. The input data distribution and result data retrieval of DePIN computing tasks almost inevitably involve cross-border data flows, making compliance exceptionally complex.
These legal requirements directly contradict the decentralized and borderless nature of DePIN. Ensuring compliance may require complex technical solutions, such as geofencing or filtering tasks based on data type and source, but this increases system complexity and may limit the efficiency and scalability of the network. Compliance issues are a major barrier for DePIN in handling sensitive data or applying in heavily regulated industries (such as finance and healthcare).
5.2 Responsibility and Accountability in Decentralized Systems
In traditional centralized services, the responsible party is usually clear (i.e., the service provider). However, in a decentralized network composed of numerous independent, and even anonymous, participants, determining who bears legal responsibility when issues arise becomes very difficult. For example:
- If a computing node returns an incorrect result, causing economic loss to the user, who should be held responsible? Is it the node provider, the protocol developer, or does the user bear the risk?
- If a provider node is hacked, leading to a data breach, how is responsibility defined?
- If the network is used for illegal activities (such as running malware or computing illegal content), who bears legal responsibility?
Unclear attribution of responsibility not only makes it difficult for users to seek redress for losses but also exposes providers and developers to potential legal risks. How to handle disputes between users and providers? How to ensure that providers comply with local laws and regulations (such as content filtering requirements)?
Current DePIN projects mainly rely on code-level mechanisms (such as smart contracts for automatic payment execution), reputation systems (punishing bad actors), and possible on-chain or off-chain arbitration mechanisms (although relevant details are not clear in the provided materials) to handle disputes and regulate behavior. However, the legal effectiveness of these mechanisms is often untested.
The lack of a clear legal framework to define responsibilities in decentralized systems creates legal uncertainty and risk for all participants (users, providers, developers). This uncertainty is one of the significant factors hindering the adoption of DePIN by mainstream enterprises. Establishing effective accountability mechanisms under the premise of decentralization is a major legal and technical challenge for DePIN. Centralized service providers (such as AWS) are more easily trusted by enterprises due to their clear responsible parties, while the distributed structure of DePIN makes the allocation and enforcement of legal responsibilities ambiguous, increasing the risks of commercial applications.
5.3 The Ambiguous Status of DePIN Tokens and Network Governance
How should the tokens issued by DePIN projects be legally classified (as securities, commodities, or utility tokens)?
This is an unresolved issue globally, especially as regulatory bodies like the U.S. Securities and Exchange Commission (SEC) take a hardline stance. The lack of clear, forward-looking guidelines from regulators has led to significant legal uncertainty for both project teams and investors. If tokens are deemed unregistered securities, project teams, developers, and even token holders may face severe penalties. This ambiguity severely hinders the financing, planning, and development of DePIN projects.
Governance: Many DePIN projects adopt decentralized governance models, allowing token holders to participate in the formulation of network rules, protocol upgrades, and community fund management through voting and other means. However, the legal status and responsibility definitions of these decentralized governance structures are also unclear. How binding are these governance decisions legally? If governance decisions lead to network issues or harm the interests of certain participants, who bears the responsibility? Is it the voting token holders, the core development team, or the protocol itself?
Regulatory Lag: The speed of technological innovation often far exceeds the pace of regulatory policy updates. Regulatory bodies often adopt a "regulation by enforcement" approach, punishing existing projects in the absence of clear rules, which creates a chilling effect on the entire industry and stifles innovation.
The regulatory ambiguity, particularly surrounding token classification and governance responsibilities, casts a shadow over the entire DePIN industry. The industry urgently needs regulators to provide clearer, more adaptive rules to technological developments so that projects can invest resources in technology and product development rather than legal compliance speculation and responses. This legal fog makes enterprises hesitant to decide whether to adopt or invest in DePIN technology.
6. User Experience
Although DePIN computing networks theoretically have advantages in cost and decentralization, their user experience (UX)—for both resource-contributing providers and resource-using consumers—often serves as a major barrier to adoption. Participating in DePIN networks typically requires a higher technical threshold and more complex operational processes compared to mature centralized cloud platforms.
6.1 Joining and Managing Nodes: Contributor (Provider) Perspective
Experience of BOINC Volunteers: One of the design goals of BOINC is to enable the general public to participate easily, so its client software strives for simplicity and ease of use. Volunteers only need to download and install the client program, select the scientific fields or specific projects they are interested in, and then the client will automatically download and run computing tasks in the background, having minimal impact on the user's daily computer use. This process is relatively straightforward and has a low technical threshold. However, for researchers running BOINC projects, setting up project servers, porting applications to various platforms, and writing task submission scripts can be quite complex. The introduction of virtual machine technology alleviates the challenges of application porting but also increases configuration complexity.
Experience of Golem Providers: Becoming a provider on the Golem network requires installing specific provider agent software (which provides a Linux installation package). Users need to configure the resources they are willing to share (CPU, memory, disk, etc.). This usually requires some knowledge of Linux system operations. Additionally, providers need to understand and manage the receipt and wallet operations of GLM tokens.
Experience of Akash Network Providers: Akash providers are typically data center operators or individuals/organizations with server resources. They need to set up physical or virtual servers and run Akash's provider daemon to connect to the network. This usually requires a high level of technical ability, such as familiarity with Linux server management, network configuration, and often implies an understanding of container orchestration technologies like Kubernetes, as Akash primarily runs containerized workloads. Providers also need to manage AKT tokens (used for receiving rewards or potential staking), participate in market bidding, and may need to go through an auditing process to obtain trusted certification. Certain specific DePIN platforms may also have hardware requirements, such as the TEE functionality of P2P Cloud requiring AMD EPYC processors.
General Situation of DePIN: The complexity of provider setup varies significantly across different DePIN projects. Some projects (like Helium's wireless hotspots) strive for a "plug-and-play" experience, but computing-related DePINs typically require providers to have a higher level of technical literacy. Managing cryptocurrency wallets and handling token transactions present an additional learning curve and operational barrier for non-cryptocurrency users.
Compared to the user-friendly design of BOINC aimed at a broad base of volunteers, commercial DePIN computing platforms generally have higher technical requirements for providers. Providers need to manage their nodes, resources, pricing, and collections as if they were running a small business. This limits the potential provider pool, making it more inclined towards professional technicians or institutions rather than ordinary computer users.
6.2 Accessing and Utilizing Resources: Consumer (Demander) Perspective
BOINC's "Consumers": BOINC is primarily designed for research projects that require large-scale computing. Researchers need to establish and maintain project servers, manage the generation and distribution of applications and work units, as well as collect and verify results. It is not aimed at ordinary consumers or developers who need on-demand access to general computing power.
Experience of Golem Demanders: Demanders need to define and submit computing tasks through the API or SDK provided by Golem (such as JS API, Ray interface). This usually requires using task templates (which can be pre-made or custom-created) to describe task logic, resource requirements, and validation methods. Demanders need to hold and use GLM tokens for payment. They also need to utilize the reputation system to help select reliable providers. This entire process requires a certain level of programming ability and an understanding of the Golem platform.
Experience of Akash Network Demanders: Akash users (tenants) need to use its specific "Stack Definition Language" (SDL) to describe the application containers they need to deploy, resource requirements (CPU, memory, storage, GPU), persistent storage, network settings, and requirements for providers (such as geographical location, audit certification, etc.). They then submit this SDL file to the market for reverse auction, selecting suitable providers to bid and create leases. Payments can be made using AKT or USDC. This process requires users to be familiar with containerization (Docker) concepts, and it is preferable to have a basic understanding of Kubernetes principles. Although Akash provides command-line tools and some graphical interfaces to simplify operations, the underlying logic and operational processes still present a significant learning cost for users accustomed to the control panels and APIs of cloud platforms like AWS, Azure, and GCP.
General Situation of DePIN: Using DePIN computing resources is generally more complex than using traditional cloud services. Users often need to interact with blockchain wallets and tokens, understand decentralized concepts (such as leases and provider reputation), and learn platform-specific tools and languages (such as SDL, task templates, SDK). Compared to the rich and familiar toolchains provided by mature cloud service providers (such as monitoring, logging, debugging, integration services), the supporting tools of DePIN platforms are often not yet fully developed, which increases the difficulty of development and operations.
For end users (demanders), the learning curve of DePIN computing platforms is typically steeper than that of mainstream cloud platforms. It not only requires users to have the necessary technical skills (such as containerization and specific API usage) but also necessitates an understanding and operation of cryptocurrency-related processes. This complexity is a significant factor hindering the widespread adoption of DePIN.
6.3 Usability Comparison: BOINC vs. Golem vs. Akash
- BOINC: The simplest for contributors (volunteers), requiring minimal intervention after installation. However, it is very complex for consumers (research project parties), who need to build and operate the entire project backend themselves.
- Golem: Attempts to provide interfaces for both supply and demand sides through APIs and markets. Both providers and demanders require a certain level of technical knowledge and need to handle cryptocurrencies. Initially focused more on specific use cases (like rendering), it gradually expanded to more general computing (like gWASM).
- Akash Network: Target users are closer to cloud developers familiar with containers/Kubernetes. SDL provides powerful deployment flexibility. Provider setup has high technical requirements, and demanders also need to learn SDL and handle cryptocurrencies. Compared to Golem, Akash aims to support a broader range of cloud-native workloads. Although it provides a user interface, the underlying complexity still exists.
User experience varies based on target users (contributors vs. consumers) and platform positioning (scientific research vs. commercial market vs. cloud alternatives). Currently, no platform can match the usability of mainstream cloud service providers in general computing services. For developers already familiar with container technology, Akash may offer a relatively smoother transition path, but for a broader user base, the usage threshold of DePIN remains high.
7. Distributed Computing vs. Centralized Cloud
Comparing distributed computing networks based on heterogeneous devices (including volunteer computing and DePIN models) with traditional centralized cloud computing (represented by AWS, Azure, GCP) reveals significant differences in architecture, cost, performance, reliability, scalability, and applicable scenarios.
7.1 Architecture and Resource Management Models
- Centralized Cloud: Adopts a centralized architecture, with computing, storage, networking, and other resources deployed in large data centers owned and managed by cloud service providers. Providers are responsible for managing and maintaining all underlying infrastructure and pool resources through virtualization technology to provide services to multiple customers. Users obtain services on demand through consoles or APIs, usually without needing to worry about underlying hardware details, enjoying a high degree of abstraction and self-service capability.
- Distributed Computing Network: Adopts a decentralized architecture, with resources distributed across geographically dispersed devices owned by numerous independent participants (volunteers or providers). Resource management and coordination need to be conducted through protocols among nodes, typically placing more management responsibility on users or the protocol itself, resulting in a lower degree of abstraction but potentially providing greater control.
7.2 Cost Structure and Economic Efficiency
- Centralized Cloud: Typically adopts a pay-as-you-go operational expenditure (OpEx) model. While it avoids upfront hardware investments for users, the costs of large-scale or long-term use can be high. There is a risk of vendor lock-in. Cloud service providers themselves need to bear significant capital expenditures (CapEx) to build and maintain data centers. The market is dominated by a few giants, which may lead to price monopolies. Providers offer discounts for reserved instances or long-term commitments.
Distributed Computing Network:
- Volunteer Computing (BOINC): Extremely low cost for researchers, with the main expenses being server costs and a small number of management personnel. The computing resources themselves are free.
- DePIN Computing: The core value proposition is significantly reduced costs. This is due to its asset-lite model (protocol developers do not own hardware) and the utilization of underutilized resources (the marginal cost or opportunity cost of these resources may be very low). Prices are further driven down through market competition (such as auctions). For providers, the barrier to entry is low, allowing them to generate revenue using existing hardware. However, the costs of the DePIN model may also be affected by token price fluctuations. Providers may need upfront hardware investments (if they purchase equipment specifically to participate).
7.3 Performance, Latency, and Applicable Workloads
- Centralized Cloud: Typically provides good and relatively predictable performance for various types of workloads. Data centers use high-speed, low-latency networks, making them very suitable for applications that require frequent communication between nodes or are sensitive to latency. They can provide instances of various specifications, including top-tier, dedicated hardware (such as the latest GPUs, TPUs).
- Distributed Computing Network: Performance varies greatly and is unstable, depending on the hardware capabilities of participating nodes and the current network conditions. Due to reliance on the public internet and geographically dispersed nodes, network latency is usually high and variable. It is best suited for running highly parallelizable, compute-intensive tasks that are not sensitive to latency (i.e., high-throughput computing HTC). It is not suitable for interactive applications, databases, or tasks that require low-latency responses or tight collaboration between nodes. Its advantage lies in the ability to aggregate massive parallel computing power. The "heterogeneous clustering" explored by DePIN platforms may become a unique performance advantage, combining different types of GPUs to complete large tasks.
7.4 Reliability, Fault Tolerance, and Security Posture
- Centralized Cloud: Provides high reliability by deploying redundant hardware and network connections within data centers, and typically offers SLA guarantees. However, there is still a risk of centralized failure points (e.g., service outages across an entire region). Security is the responsibility of the cloud service provider, which invests heavily in protection, but user data is ultimately stored and processed in environments controlled by third parties.
- Distributed Computing Network: The decentralized nature provides potentially high fault tolerance, with no single point of failure. The overall reliability of the network depends on the effectiveness of redundancy mechanisms (such as task replication) and the quality of providers. Security is its main challenge, as the network consists of untrusted nodes and relies on public networks for communication. However, it also offers stronger resistance to censorship. Users have more control over security measures but also bear more responsibility.
7.5 Scalability and Resilience Comparison
- Centralized Cloud: Offers seamless, on-demand scalability and resilience, with resource adjustments typically completed quickly and managed by the cloud service provider. Supports vertical scaling (adding resources to a single instance) and horizontal scaling (increasing the number of instances).
- Distributed Computing Network: Primarily achieves scalability through horizontal scaling (adding more participating nodes). Theoretically has extremely high scaling potential, capable of aggregating computing power from millions or even billions of devices worldwide. However, actual resilience (the ability to quickly adjust available resources based on demand) depends on the efficiency of market mechanisms (the speed at which providers join and exit) and the speed of resource allocation. Managing the scaling of large distributed nodes can be more complex than simply clicking a button in the cloud. Akash Network utilizes Kubernetes to simplify the management of its network's scalability.
7.6 Competitive Positioning and Potential Niches
- Centralized Cloud: Dominates fields such as general computing, enterprise applications, website hosting, and SaaS services. Its mature ecosystem, rich services, and comprehensive toolchain create strong user stickiness.
- Distributed Computing Network/DePIN: Currently seeks competitive advantages primarily through cost. Its potential niches include:
- Cost-sensitive computing needs: Such as startups, academic research institutions, and individual developers.
- Large-scale parallel batch processing tasks: Such as 3D rendering, AI model training (especially training tasks that can tolerate higher latency and some unreliability), and scientific simulations.
- Applications requiring censorship resistance.
- Utilization of specific hardware resources: When certain hardware (like graphics cards) is scarce or expensive in the cloud, DePIN platforms (like Render, Akash) may offer more accessible or economical options.
- Geographically distributed applications: While latency is a challenge, certain applications may benefit from computing nodes being close to data sources or end users.
Distributed/DePIN computing offers a fundamentally different value proposition compared to centralized cloud. It has significant cost advantages and enormous parallel potential for specific types of workloads, but it lags far behind centralized cloud in usability, reliability guarantees, latency performance, and tool maturity. Currently, it appears more as a competitor or complement targeting specific niches rather than a direct replacement for most cloud use cases.
7.7 Table: Comparative Summary
To clearly illustrate these differences, the following table provides a multidimensional comparison of volunteer computing, decentralized markets (using Golem as an example), DePIN computing (using Akash as an example), and centralized cloud computing.
Comparison Analysis of Distributed Computing Models and Centralized Cloud Computing
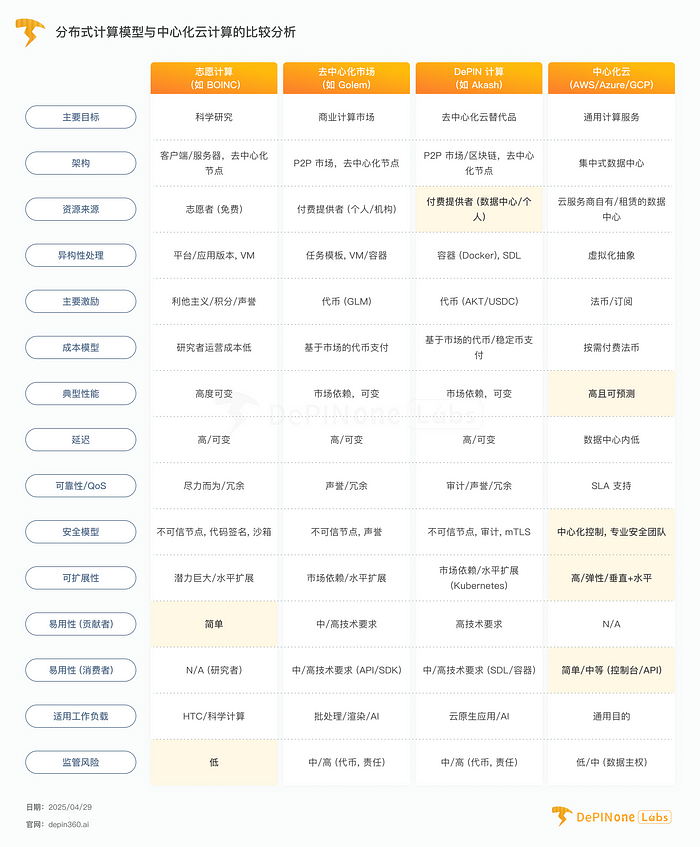
Note: The assessments in the table are relative, and specific situations may vary based on project implementation and market development.
8. The Way Forward: Sustainability and Ecosystem Maturity
For DePIN computing networks to evolve from an emerging concept into a mature, sustainable infrastructure, they must overcome challenges at multiple levels, including technology, economics, law, and community, while striving to build a healthy ecosystem.
8.1 Achieving Long-term Viability Beyond Initial Hype
The long-term survival of DePIN projects cannot rely solely on speculative increases in token prices or early hype. The core lies in whether they can create real economic utility. This means that the services provided by the network (whether computing, storage, or others) must deliver tangible value to users, and this value needs to be sufficient to support ongoing user payments. Demand must be driven by the quality, cost-effectiveness, or uniqueness of the service itself, rather than primarily by the expectation of receiving token rewards.
Successfully overcoming the "cold start" problem and genuinely initiating and maintaining the "flywheel effect" — where supply growth and service improvements attract more paying demand, and the growth of demand further incentivizes supply and enhances network value — is key to DePIN's sustainability. This requires projects to focus not only on supply-side incentives but also to invest significant effort in understanding market demand, refining products, establishing sales channels, and demonstrating that their services can consistently provide competitive advantages over existing solutions (especially centralized cloud) in terms of cost, performance (for specific loads), or characteristics like censorship resistance.
8.2 The Role of Standardization, Developer Tools, and Interoperability
The maturity of the ecosystem is inseparable from the improvement of infrastructure, especially for developers.
- Standardization: Currently, the DePIN field lacks unified standards and protocols. Different platforms use different interfaces, data formats, and operational processes. Establishing common standards is crucial for achieving interoperability between different DePIN networks, simplifying the integration of third-party tools, and reducing developers' learning costs. The absence of standards can hinder the widespread adoption of technology and the integration of the ecosystem.
- Developer Tools: Compared to the rich and user-friendly SDKs, APIs, command-line tools, monitoring dashboards, and debugging tools provided by mature cloud platforms like AWS, Azure, and GCP, the developer toolchain of DePIN platforms is often still in its early stages. To attract developers to build applications on DePIN, high-quality, well-documented, and easy-to-use development, deployment, and management tools must be provided. The JS API and Ray interface provided by Golem, as well as Akash's SDL, are examples of efforts in this direction, but the overall tool maturity of the ecosystem still has significant room for improvement.
- Interoperability: DePIN networks need not only to have internal components work together but also to interact with other blockchain systems (for example, Akash communicates with the Cosmos ecosystem through the IBC protocol) and traditional IT systems. Good interoperability can expand the application scenarios of DePIN, facilitating the flow of data and the innovation of combined services.
Developer experience is a key factor in the success of a technology platform. The DePIN ecosystem needs substantial investment to improve developer tools, provide clear documentation and tutorials, and promote the establishment of industry standards. Without these foundations, the barriers to building and integrating applications on DePIN will remain higher than those on traditional platforms, limiting its attractiveness.
8.3 Building Trust and Cultivating a Healthy Ecosystem
Beyond technology and economic models, trust and social factors are also crucial for the success of DePIN.
- Trust Mechanisms: In addition to technical result verification (as described in Section 2.4), establishing trust between users and providers requires other mechanisms. This includes transparency (e.g., on-chain transaction records, open-source code), reliable governance, effective reputation and audit systems (as described in Section 3.4), and clear, honest communication between project parties and the community.
- Community: An active, highly engaged community is the lifeblood of decentralized projects. Community members are not only potential users and providers but also participants in governance, contributors to code, supporters of new users, and promoters of the project. The success of the BOINC project has largely benefited from its large and loyal volunteer community.
- Governance: Clear, fair, and effective governance processes need to be established to guide the network's development direction, decide on protocol changes, and determine the use of community funds. Governance processes should be as transparent as possible and balance the interests of all parties. Additionally, as mentioned in Section 5.3, the legal status and liability issues of decentralized governance also need to be clarified urgently.
- Maintaining Market Integrity: The ecosystem needs to work to distinguish genuine DePIN projects committed to providing value from those that are poorly designed, unsustainable, or purely speculative, in order to maintain the reputation of the entire field. At the same time, it is essential to be vigilant and seek to reduce the interference of "airdrop farmers" or purely short-term profit-seeking "mercenary capital" on the healthy development of the network.
The long-term success of DePIN depends not only on whether the technology is feasible and the economic model is reasonable but also on whether a trustworthy, vibrant, and well-governed ecosystem can be built around its technology and economic model. This ecosystem needs to attract and retain high-quality providers and genuine users, evolving and improving through collaboration. Building trust is a multi-layered process that involves multiple dimensions, including technology, economics, market, and social governance; any missing link could jeopardize the health of the entire ecosystem.
9. Conclusion and Strategic Considerations
9.1 Review: Feasibility, Key Barriers, and Untapped Potential
This report provides an in-depth analysis of the feasibility, challenges, and applications of distributed computing networks based on heterogeneous devices and the DePIN model. The analysis indicates:
- Technical feasibility has been validated: Over two decades of volunteer computing practices (such as BOINC and Folding@home) have proven that aggregating the idle computing power of a large number of distributed, heterogeneous devices via the internet to complete large-scale, parallel computing tasks is entirely feasible.
- DePIN model faces severe challenges: While the potential for commercializing this model and applying it to more general computing scenarios is enormous, DePIN projects face numerous core obstacles. These obstacles span multiple levels, including technology, economics, law, and user experience:
- Technical level: Managing device heterogeneity, overcoming network latency and bandwidth limitations, handling node unreliability and dynamism, designing efficient task scheduling and result verification mechanisms (especially in non-deterministic computing scenarios), and ensuring security and privacy in untrusted environments are all highly challenging.
- Economic level: The core dilemma lies in matching supply and demand — incentivizing supply with tokens is relatively easy, but creating sustainable, paying demand is much more difficult. Designing a stable token economic model that balances the interests of all parties and provides competitive pricing and service quality (QoS) is key.
- Legal level: Issues such as data sovereignty, privacy regulations, cross-border data flow restrictions, the legal classification of tokens, and the liability of decentralized governance bring significant regulatory uncertainty.
- User experience level: For both providers and demanders, the technical barriers and operational complexity of participating in the DePIN network are typically much higher than those of mature centralized cloud platforms, hindering widespread adoption.
- Untapped potential still exists: Despite the challenges, the potential of the DePIN computing model should not be overlooked. It is expected to provide significant cost savings (especially for specific types of workloads), achieve unprecedented computing scale (aggregating global resources), offer stronger resistance to censorship, and democratize access to computing resources (especially scarce GPU resources).
9.2 Reassessing Supply and Demand Challenges: Is It Solvable?
The supply-demand matching dilemma is the core issue determining the future direction of DePIN computing. Can it be solved? The answer is not a simple "yes" or "no," but depends on the fulfillment of a series of conditions:
- Finding a "killer application": DePIN needs to identify applications where it can provide orders of magnitude advantages over centralized cloud (e.g., 10 times cost reduction, or unique scalability/censorship resistance). Simply offering slightly cheaper or functionally similar services makes it difficult to overcome user inertia in migration. AI model training, large-scale scientific simulations, and applications requiring extremely high censorship resistance may be potential directions.
- Improving technological maturity: Achieving breakthroughs in task scheduling, result verification (especially for non-deterministic computing), usability, and reliability assurance. For example, smarter scheduling algorithms, more efficient and practical verifiable computing solutions, and more seamless user interfaces and developer tools.
- Sustainable economic models: Token economic models must shift from primarily relying on speculation to being closely tied to actual network usage and value creation. It is necessary to find stable mechanisms that can continuously incentivize high-quality providers while maintaining price attractiveness for users.
- Clarification of the regulatory environment: Regulatory agencies need to provide clear and reasonable rules, especially regarding token classification, data processing, and platform liability, to reduce uncertainty and provide space for innovation.
Current status assessment: At present, DePIN computing has still not been fundamentally validated in creating widespread, sustainable demand. Projects serving specific niche markets (such as 3D rendering, cost-sensitive AI inference/training, and Web3 native applications) are more likely to succeed in the short term. There is still a long way to go to become a mainstream choice for general computing.
9.3 Strategic Recommendations for Stakeholders
Based on the above analysis, the following strategic considerations are provided for stakeholders in different roles:
- For developers and project teams
- Focus on niche markets: Avoid direct competition with centralized cloud in general computing, and instead concentrate on specific areas where decentralization can provide clear, significant advantages.
- User experience first: Invest resources to significantly simplify the usage process for providers and demanders, lower technical barriers, and develop high-quality documentation and tools.
- Address trust and QoS: Invest heavily in developing reliable and efficient verification mechanisms and QoS assurance solutions (even if probabilistic), and establish transparent reputation/audit systems.
- Design sustainable economic models: Deeply bind token value to actual network usage, avoiding unsustainable inflation models. Consider introducing stablecoin payment options to reduce volatility risks.
- Proactive compliance and communication: Closely monitor regulatory dynamics, strive to operate in compliance within the existing framework, and actively communicate with regulatory agencies and the community.
For users and consumers (demanders)
- Evaluate trade-offs: Carefully weigh the cost advantages of DePIN against potential disadvantages in performance, reliability, usability, and security based on specific workload requirements.
- Start with low-risk scenarios: Prioritize using DePIN for computing tasks that are insensitive to latency, have high fault tolerance, and involve non-core or non-sensitive data.
- Understand risks: Fully recognize the security risks, privacy risks, and cost uncertainties associated with token price fluctuations that may arise from using DePIN.
- Choose reliable providers: Utilize the reputation systems, audit information, and other tools provided by the platform to select more reliable computing resource providers.
For investors
- Focus on the demand side: When evaluating projects, emphasize whether they have clear, feasible demand-side strategies and product-market fit, rather than just supply-side growth data.
- Examine token economics: Analyze the sustainability of the token model in depth, being wary of high inflation and models lacking actual utility support.
- Assess risks: Consider the technical risks (such as verification challenges), market risks (insufficient demand), and regulatory risks that the project faces.
- Evaluate the team and community: A strong technical team, clear vision, and an active, healthy community are important factors for project success.
Overall, distributed computing networks based on heterogeneous devices, particularly the DePIN model, represent a development direction in the computing field that is full of potential but also highly challenging. Its ultimate success is not guaranteed and requires significant breakthroughs across multiple dimensions, including technology, economics, law, and ecosystem building. However, its potential to disrupt traditional centralized models and its ability to address specific computing scenario pain points make ongoing exploration, development, and careful evaluation of it highly valuable.
Partial References
- BOINC — Knowledge and References — Taylor & Francis, https://taylorandfrancis.com/knowledge/Engineeringandtechnology/Computer_science/BOINC/
- Volunteer computing — Wikipedia, https://en.wikipedia.org/wiki/Volunteer_computing
- DePIN: Unlocking New Opportunities For Scalable Cloud Infrastructure, https://www.forbes.com/councils/forbestechcouncil/2024/05/09/depin-unlocking-new-opportunities-for-scalable-cloud-infrastructure/
- Golem gWASM verification by redundancy scheme, https://blog.golem.network/gwasm-verification/
- Data Sovereignty and Legal Challenges in Digital Infrastructure, https://www.withlaw.co/blog/Technology-and-Innovation-1/Data-Sovereignty-and-Legal-Challenges-in-Digital-Infrastructure
- Difference Between Cloud Computing & Distributed Computing — Fynd Academy, https://www.fynd.academy/blog/cloud-computing-and-distributed-computing
- Akash Network GPU Provider Incentives, https://github.com/orgs/akash-network/discussions/448
- Introduction to Volunteer computing and BOINC — IN2P3 Events Directory (Indico), https://indico.in2p3.fr/event/147/contributions/19399/attachments/15857/19460/ACGRIDBOINCI.pdf
- (PDF) Centralized vs. Decentralized Cloud Computing in Healthcare — ResearchGate, https://www.researchgate.net/publication/383715197CentralizedvsDecentralizedCloudComputingin_Healthcare
- Ultimate Guide to Building a DePIN Project in 2024 — Rapid Innovation, https://www.rapidinnovation.io/post/building-a-depin-project-essential-steps-for-developers-and-entrepreneurs
- DePin: A Beginner’s Guide to Decentralized Physical Infrastructure — Spheron’s Blog, https://blog.spheron.network/depin-a-beginners-guide-to-decentralized-physical-infrastructure
Special Statement: All articles from DePINone Labs are for informational and knowledge purposes only and do not constitute any investment advice.
This report is produced by DePINone Labs. For reprints, please contact us.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








