The future of the AI large model world will not lack the strength of China, nor will it fall behind.
Author: Hengyu from Aofeisi

Image source: Generated by Wujie AI
Just now, Jumpshare Star and Geely Automobile Group jointly open-sourced two multimodal large models!
The new models include:
The largest open-source video generation model Step-Video-T2V in terms of parameter count globally
The industry's first product-level open-source voice interaction large model Step-Audio
The multimodal king has begun to open-source multimodal models, with Step-Video-T2V adopting the most open and lenient MIT open-source license, allowing for any editing and commercial application.
(As usual, GitHub, Baobao Face, and Modao Direct Train can be seen at the end of the article)
During the development of the two large models, both parties complemented each other's strengths in computing power algorithms, scene training, etc., "significantly enhancing the performance of the multimodal large models."
According to the official technical report, the two models open-sourced this time performed excellently in Benchmark, outperforming similar open-source models both domestically and internationally.
Baobao Face's official account also retweeted the high praise given by the head of the China region.
Key point: "The next DeepSeek," "HUGE SoTA."
Oh, really?
Then Quantum Bit will have to break down the technical report + firsthand testing in this article to see if they live up to their name.

Quantum Bit verifies that both of the new open-source models are now integrated into the Yuewen App, allowing everyone to experience them.
The multimodal king has open-sourced multimodal models for the first time
Step-Video-T2V and Step-Audio are the first multimodal models open-sourced by Jumpshare Star.
Step-Video-T2V
First, let's take a look at the video generation model Step-Video-T2V.
It has a parameter count of 30B, making it the largest known open-source video generation large model globally, natively supporting bilingual input in Chinese and English.

According to the official introduction, Step-Video-T2V has four major technical features:
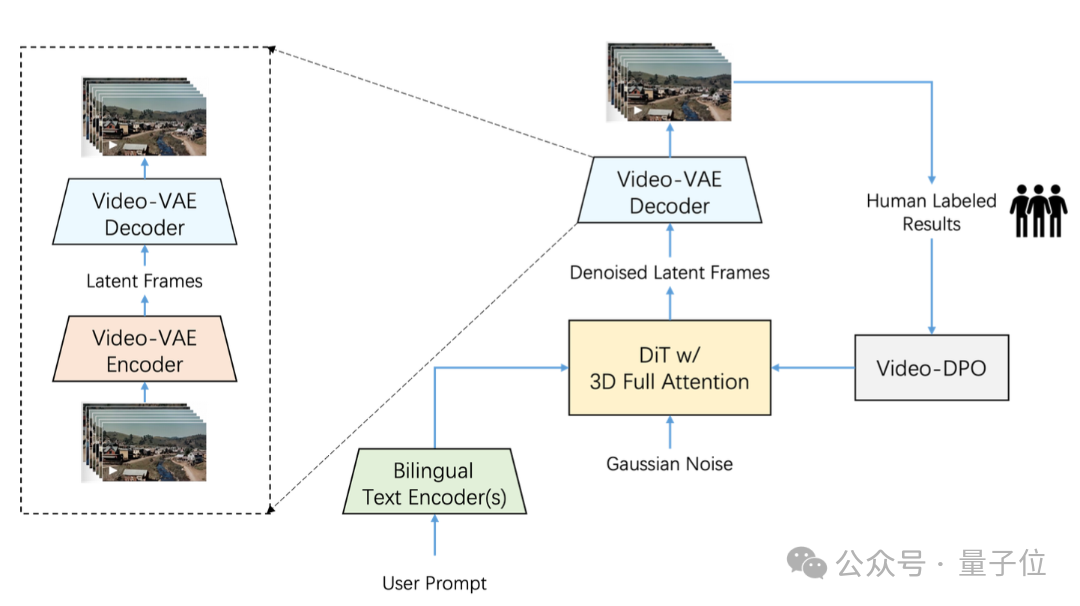
First, it can directly generate videos of up to 204 frames and 540P resolution, ensuring that the generated video content has extremely high consistency and information density.
Second, a high-compression Video-VAE was designed and trained specifically for video generation tasks, capable of compressing videos in the spatial dimension by 16×16 times and in the temporal dimension by 8 times while ensuring video reconstruction quality.
Most VAE models on the market currently have a compression ratio of 8x8x4, so with the same number of video frames, Video-VAE can compress an additional 8 times, thus improving training and generation efficiency by 64 times.
Third, Step-Video-T2V underwent in-depth systematic optimization regarding the hyperparameter settings, model structure, and training efficiency of the DiT model, ensuring the efficiency and stability of the training process.
Fourth, it provides a detailed introduction to the complete training strategy, including pre-training and post-training, covering training tasks, learning objectives, and data construction and selection methods at each stage.
Additionally, Step-Video-T2V introduces Video-DPO (Video Preference Optimization) in the final training phase—this is a reinforcement learning optimization algorithm for video generation that can further enhance video generation quality, reinforcing the rationality and stability of the generated videos.
The final effect is to make the movements in the generated videos smoother, the details richer, and the instruction alignment more accurate.
To comprehensively evaluate the performance of the open-source video generation model, Jumpshare has also released a new benchmark dataset for text-to-video quality assessment, Step-Video-T2V-Eval.
This dataset has also been open-sourced!
It contains 128 evaluation questions in Chinese sourced from real users, aimed at assessing the quality of generated videos across 11 content categories, including movement, scenery, animals, combined concepts, surrealism, and more.
The evaluation results on Step-Video-T2V-Eval are shown below:
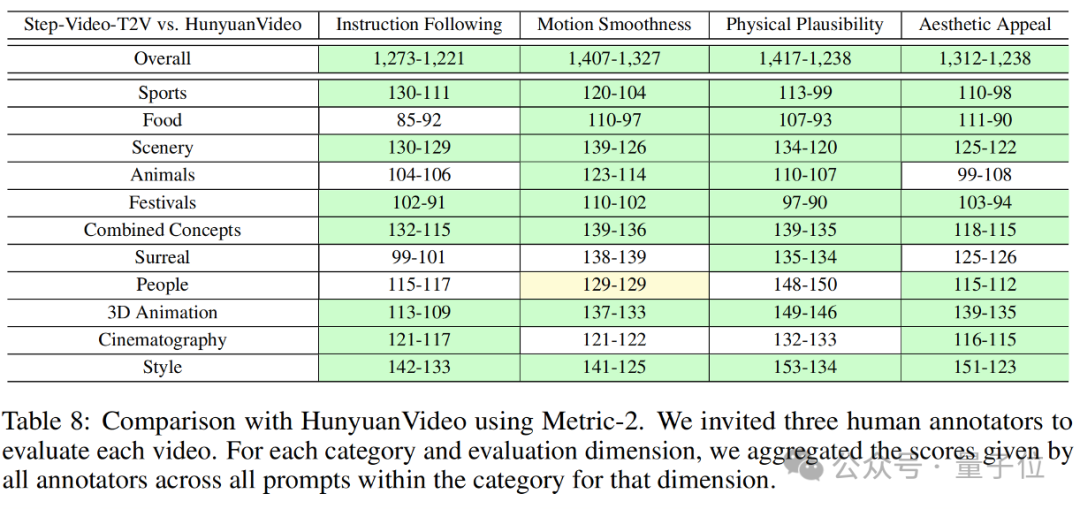
As can be seen, Step-Video-T2V outperformed previous best open-source video models in terms of instruction adherence, motion smoothness, physical rationality, and aesthetic quality.
This means that the entire video generation field can conduct research and innovation based on this new strongest foundational model.
Regarding actual performance, Jumpshare officially states:
In terms of generation effects, Step-Video-T2V has strong generation capabilities in complex movements, aesthetically pleasing characters, visual imagination, basic text generation, native bilingual input in Chinese and English, and shot language, with outstanding semantic understanding and instruction adherence capabilities, effectively assisting video creators in achieving precise creative presentations.
What are you waiting for? Let's test it out—
According to the official introduction, the first challenge is to test whether Step-Video-T2V can handle complex movements.
Previous video generation models often produced strange images when generating clips of complex movements such as ballet, standard dance, Chinese dance, artistic gymnastics, karate, and martial arts.
For example, suddenly appearing third legs, crossed and fused arms, etc., which can be quite frightening.
To address this, we conducted a targeted test, giving Step-Video-T2V a prompt:
An indoor badminton court, eye-level perspective, a fixed camera records a scene of a man playing badminton. A man wearing a red short-sleeve shirt and black shorts holds a badminton racket, standing in the center of the green badminton court. The net spans the court, dividing it into two parts. The man swings the racket to hit the shuttlecock towards the opposite side. The lighting is bright and even, and the image is clear.
The scene, characters, camera, lighting, and actions all match perfectly.
The second challenge for the generated image containing "aesthetic characters" is posed by Quantum Bit to Step-Video-T2V.
To be fair, the current level of text-to-image models generating real human images can absolutely be indistinguishable in static, local details.
However, when it comes to video generation, once the characters start moving, there are still identifiable physical or logical flaws.
As for Step-Video-T2V's performance—
Prompt: A male, dressed in a black suit, paired with a dark tie and white shirt, with scars on his face and a serious expression. Close-up shot.
"No AI feel."
This was the unanimous evaluation from the Quantum Bit editorial team after reviewing the video of the handsome guy.
It’s the kind of "no AI feel" where the facial features are well-defined, skin texture is realistic, and the scars on the face are clearly visible.
It’s also the kind of "no AI feel" where the character appears realistic without having hollow eyes or a stiff expression.
The first two challenges kept Step-Video-T2V at a fixed camera position.
So, how does it perform with camera movements like zooming, panning, and tilting?
The third challenge tests Step-Video-T2V's mastery of camera movements, such as zooming, panning, tilting, rotating, and following.
If you ask it to rotate, it rotates:
Not bad! It could shoulder a Steadicam and become a camera master on set (just kidding).
After a series of tests, the generation results provide the answer:
Step-Video-T2V indeed excels in semantic understanding and instruction adherence, just as the evaluation set results indicated.
It even easily handles basic text generation:
Step-Audio
The other model open-sourced simultaneously, Step-Audio, is the industry's first product-level open-source voice interaction model.
In the multi-dimensional evaluation system StepEval-Audio-360 benchmark test built and open-sourced by Jumpshare, Step-Audio achieved the best scores in logical reasoning, creative ability, instruction control, language ability, role-playing, word games, and emotional value.
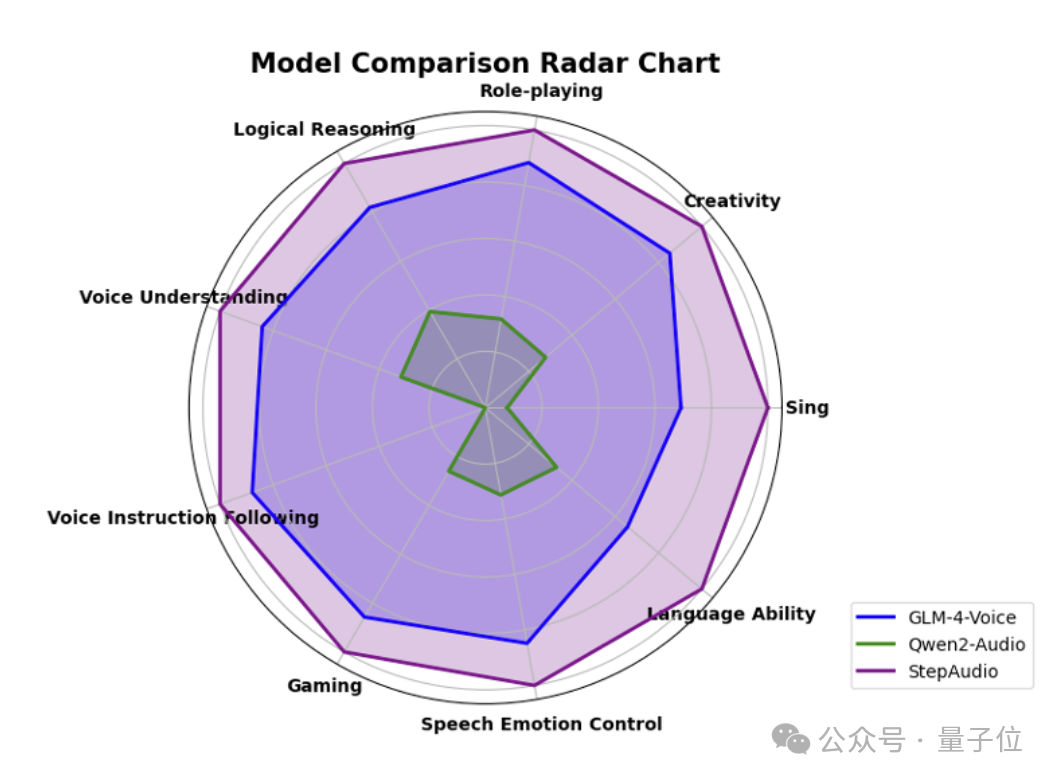
In the five major mainstream public test sets, including LlaMA Question and Web Questions, Step-Audio outperformed similar open-source models in the industry, ranking first.
It can be seen that it performed particularly well in the HSK-6 (Chinese Proficiency Test Level 6) evaluation.
The actual test is as follows:
The Jumpshare team introduced that Step-Audio can generate expressions of emotion, dialects, languages, singing, and personalized styles according to different scene requirements, allowing for natural high-quality conversations with users.
At the same time, the voice generated by it not only features realism and naturalness but also high emotional intelligence, achieving high-quality voice replication and role-playing.
In summary, for application needs in industries such as film and entertainment, social media, and gaming, Step-Audio will fully satisfy you.
The Jumpshare open-source ecosystem is snowballing
How to put it, just one word: competitive.
Jumpshare is truly competitive, especially in its forte of multimodal models—
The multimodal models in its Step series have been frequent visitors to the top spots in major authoritative evaluation sets and competitions both domestically and internationally since their inception.
Just looking at the last three months, they have already claimed the top spot multiple times.
On November 22 last year, the latest list of the large model competition arena saw the multimodal understanding large model Step-1V ranking, with a total score equal to Gemini-1.5-Flash-8B-Exp-0827, placing it first among Chinese large models in the visual field.
In January this year, the domestic large model evaluation platform "Sinan" (OpenCompass) real-time leaderboard for multimodal model evaluation saw the newly released Step-1o series model take first place.
On the same day, the latest list of the large model competition arena saw the multimodal model Step-1o-vision take first place among domestic visual large models.

Secondly, Jumpshare's multimodal models not only have excellent performance and quality, but also a high frequency of R&D iterations—
As of now, Jumpshare Star has released a total of 11 multimodal large models.
Last month, they launched 6 models in 6 days, covering the entire spectrum of language, speech, vision, and reasoning, further solidifying their title as the multimodal king.
This month, they have open-sourced 2 more multimodal models.
As long as they maintain this pace, they can continue to prove their status as a "full-stack multimodal player."
With their strong multimodal capabilities, starting in 2024, the market and developers have already recognized and widely integrated Jumpshare's API, forming a large user base.
Consumer goods, such as Cha Baidao, have integrated the multimodal understanding large model Step-1V into thousands of stores nationwide, exploring the application of large model technology in the tea industry for intelligent inspections and AIGC marketing.
Public data shows that an average of over a million cups of Cha Baidao tea are delivered to consumers daily under the protection of the large model's intelligent inspection.
Meanwhile, Step-1V can save Cha Baidao supervisors 75% of their self-inspection verification time daily, providing tea consumers with a more reassuring and high-quality service.
Independent developers, such as the popular AI application "Weizhi Book" and the AI psychological therapy application "Linjian Liaoyushi," after conducting AB tests on most domestic models, ultimately chose Jumpshare's multimodal model API.
(Whisper: Because using it yields the highest payment rate)
Specific data shows that in the second half of 2024, the call volume for Jumpshare's multimodal large model API increased by over 45 times.

Speaking of this open-source initiative, what is being open-sourced is Jumpshare's strongest multimodal model.
We note that Jumpshare, which has already accumulated market and developer reputation and numbers, is considering deeper integration from the model side with this open-source release.
On one hand, Step-Video-T2V adopts the most open and lenient MIT open-source license, allowing for any editing and commercial application.
It can be said that they are "not hiding anything."
On the other hand, Jumpshare states that they are "fully committed to lowering the industry access threshold."
Take Step-Audio for example; unlike other open-source solutions on the market that require redeployment and redevelopment, Step-Audio is a complete real-time dialogue solution that can be directly deployed for real-time conversations.
You can enjoy an end-to-end experience right from the first frame.
With this entire set of actions, a unique open-source technology ecosystem centered around Jumpshare Star and its multimodal model has begun to take shape.
In this ecosystem, technology, creativity, and commercial value intertwine, jointly promoting the development of multimodal technology.
Moreover, with the continued R&D and iteration of Jumpshare models, rapid and sustained integration by developers, and the support and collaboration of ecosystem partners, the "snowball effect" of the Jumpshare ecosystem has already occurred and is growing.
China's open-source strength is speaking with power
Once upon a time, when mentioning the leaders in the open-source field of large models, people would think of Meta's LLaMA and Albert Gu's Mamba.
Now, there is no doubt that China's open-source strength in the large model arena has shone globally, rewriting the "stereotype" with its capabilities.
On January 20, just before the Spring Festival of the Year of the Snake, it was a day of fierce competition among large models both domestically and internationally.
The most notable event was the launch of DeepSeek-R1 on this day, which has reasoning performance comparable to OpenAI's o1, but at only one-third of the cost.
The impact was so significant that it caused Nvidia to evaporate $589 billion (approximately 42.4 trillion RMB) overnight, setting a record for the largest single-day drop in U.S. stocks.
More importantly and impressively, the reason R1 reached a height that excited millions of people is not only due to its excellent reasoning and affordable price but also because of its open-source nature.
This stirred up a wave of reactions, even prompting OpenAI, which has long been mocked for "no longer being open," to have CEO Altman publicly speak out multiple times.
Altman stated, "On the issue of open-source weight AI models, (I personally believe) we are on the wrong side of history."
He also said, "The world indeed needs open-source models; they can provide a lot of value to people. I am glad that there are already some excellent open-source models in the world."

Now, Jumpshare has also begun to open-source its new trump cards.
And the intention behind the open-sourcing is clear.
The official statement indicates that the purpose of open-sourcing Step-Video-T2V and Step-Audio is to promote the sharing and innovation of large model technology and to advance the inclusive development of artificial intelligence.
The open-source release has already showcased its strength across multiple evaluation sets.
Now, at the table of open-source large models, DeepSeek boasts strong reasoning, Jumpshare Step emphasizes multimodality, and there are various continuously developing competitors…
Their strength is not only prominent in the open-source circle but also stands out in the entire large model arena.
——China's open-source strength, after emerging, is taking further steps.
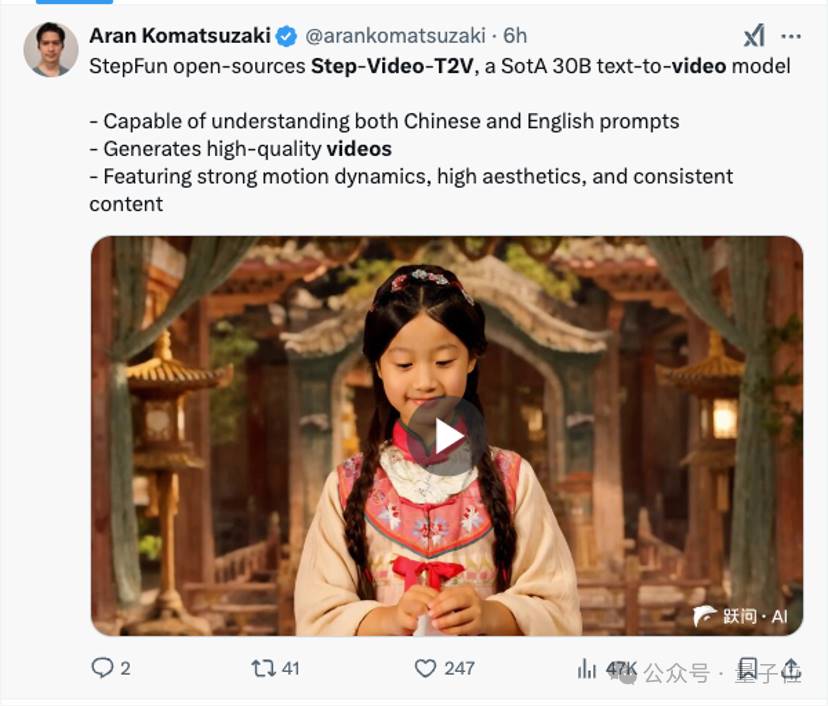
Taking Jumpshare's recent open-source initiative as an example, it breaks through the technology in the multimodal field and changes the choice logic of global developers.
Many active tech leaders in open-source communities like Eleuther AI have actively come forward to test Jumpshare's models, "Thank you, China open-source."
Wang Tiezhen, the head of Baobao Face's China region, directly stated that Jumpshare will be the next "DeepSeek."

From "technological breakthrough" to "ecological openness," the path of China's large models is becoming more stable.
That said, Jumpshare's open-sourcing of two models this time may just be a footnote in the AI competition of 2025.
On a deeper level, it showcases the technological confidence of China's open-source strength and sends out a signal:
In the future AI large model world, China's strength will not be absent, nor will it fall behind.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






