1. Introduction: The Development of AI+Web3
In the past few years, the rapid development of artificial intelligence (AI) and Web3 technology has attracted widespread attention globally. AI, as a technology that simulates and imitates human intelligence, has made significant breakthroughs in areas such as facial recognition, natural language processing, and machine learning. The rapid development of AI technology has brought about significant changes and innovations to various industries.
The market size of the AI industry reached 200 billion US dollars in 2023, and industry giants and outstanding players such as OpenAI, Character.AI, and Midjourney have emerged one after another, leading the AI boom.
At the same time, Web3, as an emerging network model, is gradually changing our understanding and usage of the Internet. Based on decentralized blockchain technology, Web3 realizes data sharing and control, user autonomy, and the establishment of a trust mechanism through smart contracts, distributed storage, and decentralized identity verification. The core concept of Web3 is to liberate data from centralized authorities, empowering users with control over data and the sharing of data value.
Currently, the market value of the Web3 industry has reached 25 trillion, and players such as Bitcoin, Ethereum, Solana, as well as application layer players like Uniswap and Stepn, continue to emerge with new narratives and scenarios, attracting more and more people to join the Web3 industry.
It is easy to see that the combination of AI and Web3 is an area of great concern for builders and venture capitalists in both the East and the West. How to integrate the two effectively is a problem worthy of exploration.
This article will focus on the current development of AI+Web3, exploring the potential value and impact brought about by this integration. We will first introduce the basic concepts and characteristics of AI and Web3, and then explore their interrelationships. Subsequently, we will analyze the current status of AI+Web3 projects and delve into the limitations and challenges they face. Through this research, we hope to provide valuable references and insights for investors and practitioners in related industries.
2. Interaction between AI and Web3
The development of AI and Web3 is like the two sides of a balance, with AI bringing about an increase in productivity, and Web3 bringing about a transformation in production relations. So, what kind of spark can AI and Web3 collide to produce? Next, we will first analyze the dilemmas and potential for improvement faced by the AI and Web3 industries, and then discuss how they help each other solve these dilemmas.
Dilemmas and Potential for Improvement in the AI Industry
Dilemmas and Potential for Improvement in the Web3 Industry
2.1 Dilemmas in the AI Industry
To explore the dilemmas faced by the AI industry, let's first look at the essence of the AI industry. The core of the AI industry revolves around three elements: computing power, algorithms, and data.

First is computing power: Computing power refers to the ability to perform large-scale computation and processing. AI tasks typically require processing large amounts of data and conducting complex calculations, such as training deep neural network models. High-intensity computing power can accelerate the process of model training and inference, improving the performance and efficiency of AI systems. In recent years, with the development of hardware technologies such as graphics processing units (GPUs) and specialized AI chips (such as TPUs), the improvement in computing power has played a crucial role in the development of the AI industry. Nvidia, whose stock has soared in recent years, is a major GPU provider that has captured a large market share and earned high profits.
What are algorithms: Algorithms are the core components of AI systems, representing mathematical and statistical methods used to solve problems and accomplish tasks. AI algorithms can be divided into traditional machine learning algorithms and deep learning algorithms, with the latter making significant breakthroughs in recent years. The selection and design of algorithms are crucial for the performance and effectiveness of AI systems. Continuous improvement and innovation in algorithms can enhance the accuracy, robustness, and generalization ability of AI systems. Different algorithms yield different effects, making algorithm improvement crucial for task performance.
Why data is important: The core task of AI systems is to extract patterns and regularities from data through learning and training. Data forms the basis for training and optimizing models, allowing AI systems to learn more accurate and intelligent models from large-scale data samples. Rich datasets can provide more comprehensive and diverse information, enabling models to better generalize to unseen data and help AI systems better understand and solve real-world problems.
After understanding the core three elements of AI, let's look at the dilemmas and challenges AI faces in these three aspects. First, in terms of computing power, AI tasks typically require a large amount of computing resources for model training and inference, especially for deep learning models. However, acquiring and managing large-scale computing power is a costly and complex challenge. The cost, energy consumption, and maintenance of high-performance computing devices are issues. Particularly for startups and individual developers, obtaining sufficient computing power may be difficult.
In terms of algorithms, despite the significant success of deep learning algorithms in many fields, there are still dilemmas and challenges. For example, training deep neural networks requires a large amount of data and computing resources, and for certain tasks, the interpretability and explainability of models may be insufficient. In addition, the robustness and generalization ability of algorithms are also important issues, as the performance of models on unseen data may be unstable. Among the numerous algorithms, finding the best algorithm to provide the best service is an ongoing exploration process.
In terms of data, data is the driving force of AI, but obtaining high-quality and diverse data remains a challenge. Data in certain fields may be difficult to obtain, such as sensitive health data in the medical field. Additionally, the quality, accuracy, and labeling of data are also issues, as incomplete or biased data may lead to model errors or biases. Furthermore, protecting data privacy and security is an important consideration.
In addition, there are issues such as explainability and transparency. The black-box nature of AI models is a public concern. For certain applications such as finance, healthcare, and judiciary, the decision-making process of models requires interpretability and traceability, yet existing deep learning models often lack transparency. Providing trustworthy explanations for model decision-making processes remains a challenge.
Furthermore, many AI projects have unclear business models, which has left many AI entrepreneurs feeling lost.
2.2 Dilemmas in the Web3 Industry
In the Web3 industry, there are currently various dilemmas that need to be addressed, whether it is in terms of data analysis, poor user experience in Web3 products, or issues with smart contract code vulnerabilities and hacker attacks. AI, as a tool to improve productivity, also has a lot of potential to play a role in these areas.
First is the improvement in data analysis and predictive capabilities: The application of AI technology in data analysis and prediction has had a significant impact on the Web3 industry. Through intelligent analysis and mining by AI algorithms, Web3 platforms can extract valuable information from massive data and make more accurate predictions and decisions. This is of great significance for risk assessment, market forecasting, and asset management in the decentralized finance (DeFi) field.
Additionally, there can be improvements in user experience and personalized services: The application of AI technology enables Web3 platforms to provide better user experience and personalized services. By analyzing and modeling user data, Web3 platforms can offer personalized recommendations, customized services, and intelligent interaction experiences. This helps to increase user engagement and satisfaction, promoting the development of the Web3 ecosystem. For example, many Web3 protocols integrate AI tools such as ChatGPT to better serve users.
In terms of security and privacy protection, the application of AI has profound implications for the Web3 industry. AI technology can be used for detecting and defending against network attacks, identifying abnormal behavior, and providing stronger security guarantees. Additionally, AI can be applied to data privacy protection, safeguarding users' personal information on Web3 platforms through techniques such as data encryption and privacy computation. In terms of smart contract auditing, as there may be vulnerabilities and security risks in the process of writing and auditing smart contracts, AI technology can be used for automated contract auditing and vulnerability detection, enhancing the security and reliability of contracts.
It can be seen that AI can participate and provide assistance in many aspects of the dilemmas and potential for improvement faced by the Web3 industry.
3. Analysis of the Current Status of AI+Web3 Projects
The integration of AI and Web3 projects mainly focuses on two major aspects: using blockchain technology to enhance the performance of AI projects and utilizing AI technology to serve the improvement of Web3 projects.
Focusing on these two aspects, a large number of projects have emerged to explore this path, including Io.net, Gensyn, Ritual, and various other projects. This article will analyze the current status and development of different sub-tracks of AI assisting Web3 and Web3 assisting AI.
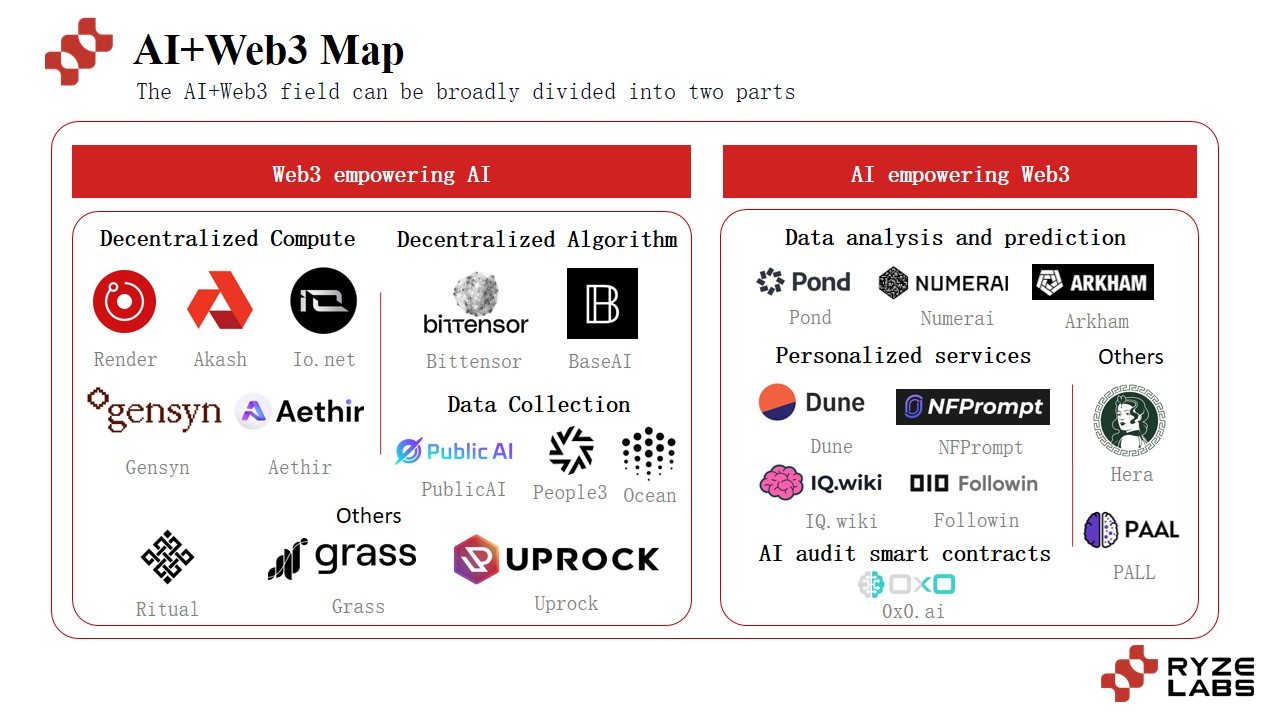
3.1 Web3 Assisting AI
3.1.1 Decentralized Computing Power
Since the launch of ChatGPT by OpenAI at the end of 2022, it has ignited a wave of enthusiasm for AI. Within 5 days of its launch, the user base reached 1 million, while it took Instagram about two and a half months to reach 1 million downloads. Subsequently, ChatGPT's growth was also very rapid, with a monthly active user base of 100 million within 2 months, and reaching 1 billion weekly active users by November 2023. With the emergence of ChatGPT, the AI field rapidly transformed from a niche track to a highly anticipated industry.
According to Trendforce's report, ChatGPT requires 30,000 NVIDIA A100 GPUs to run, and future iterations like GPT-5 will require even more computational power. This has led to an arms race among AI companies, as only those with sufficient computational power can ensure they have the necessary strength and advantage in the AI battle, resulting in a shortage of GPUs.
Before the rise of AI, the largest GPU provider, NVIDIA, had its customers concentrated in the three major cloud services: AWS, Azure, and GCP. With the rise of artificial intelligence, a large number of new buyers emerged, including major tech companies like Meta, Oracle, and other data platforms and AI startups, all joining the war to hoard GPUs for training AI models. Large tech companies like Meta and Tesla significantly increased their purchases of custom AI models and internal research. Basic model companies like Anthropic, and data platforms like Snowflake and Databricks, also purchased more GPUs to help provide AI services to their customers.
As mentioned by Semi Analysis last year, there are "GPU rich" and "GPU poor" companies. A few companies have over 20,000 A100/H100 GPUs, and team members can use 100 to 1000 GPUs for projects. These companies are either cloud providers or have their own large machine learning models, including OpenAI, Google, Meta, Anthropic, Inflection, Tesla, Oracle, and Mistral.
However, most companies fall into the "GPU poor" category, struggling with a much smaller number of GPUs and spending a lot of time and effort on tasks that are difficult to push the ecosystem forward. This situation is not limited to startups. Some of the most well-known AI companies, such as Hugging Face, Databricks (MosaicML), Together, and even Snowflake, have fewer than 20,000 A100/H100 GPUs. These companies have world-class technical talent but are limited by the supply of GPUs, putting them at a disadvantage in the AI competition compared to larger companies.
This shortage is not limited to "GPU poor" companies. Even at the end of 2023, the leading AI player OpenAI had to close paid registrations for several weeks due to the inability to obtain sufficient GPUs and had to procure more GPU supplies.
It can be seen that the rapid development of AI has led to a severe mismatch between the demand and supply of GPUs, creating an urgent supply shortage issue.
To address this issue, some Web3 projects have begun to explore the use of Web3's technological characteristics to provide decentralized computing power services, including Akash, Render, Gensyn, and others. These projects share a common approach of using tokens to incentivize users to provide idle GPU computing power, becoming the supply side of computing power to support AI clients.
The supply side profile mainly consists of three aspects: cloud service providers, cryptocurrency miners, and enterprises.
Cloud service providers include major cloud service providers (such as AWS, Azure, GCP) and GPU cloud service providers (such as Coreweave, Lambda, Crusoe), where users can resell idle computing power from cloud service providers to generate income. With Ethereum transitioning from PoW to PoS, idle GPU computing power has become an important potential supply side for cryptocurrency miners. In addition, large enterprises like Tesla and Meta, which have purchased a large number of GPUs due to strategic deployments, can also utilize their idle GPU computing power as part of the supply side.
Currently, players in this track can be roughly divided into two categories: those using decentralized computing power for AI inference and those using it for AI training. The former includes Render (although focused on rendering, it can also be used for AI computing power), Akash, Aethir, and others; the latter includes io.net (supports both inference and training) and Gensyn, with the main difference being the different requirements for computing power.
Let's first discuss the projects for AI inference. These projects attract users to provide computing power through token incentives and then provide the computing power network service to the demand side, effectively matching the supply and demand of idle computing power. Information and analysis about these projects were previously mentioned in a research report by Ryze Labs, feel free to check it out.
The key point is that through token incentive mechanisms, the projects first attract suppliers and then attract users to use the service, thereby achieving the cold start and core operation of the project, leading to further expansion and development. In this cycle, the supply side receives more valuable token rewards, while the demand side gains access to more cost-effective services. The value of the project's tokens and the growth of participants on both the supply and demand sides remain consistent. As the token price rises, more participants and speculators are attracted to participate, creating value capture.
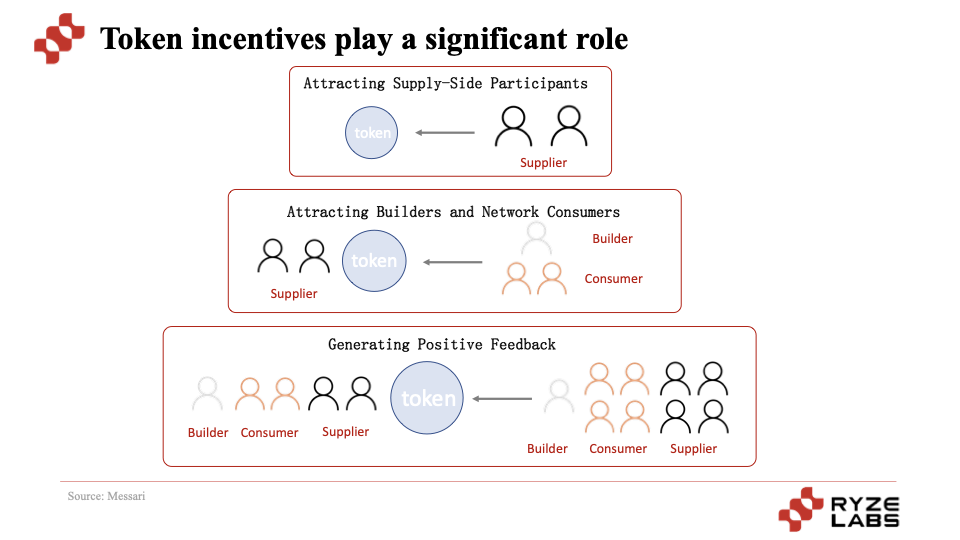
Another category is the use of decentralized computing power for AI training, such as Gensyn and io.net (supports both AI training and inference). The operational logic of these projects is essentially the same as those for AI inference, using token incentives to attract the supply side to provide computing power for the demand side to use.
io.net, as a decentralized computing power network, currently has over 500,000 GPUs, performing prominently in the decentralized computing power project. Additionally, it has integrated computing power from Render and Filecoin, and is continuously developing its ecosystem.

Furthermore, Gensyn uses smart contracts to facilitate task allocation and rewards for machine learning training. As shown in the figure below, the hourly cost of machine learning training work in Gensyn is approximately $0.4, much lower than the cost of over $2 on AWS and GCP.
The ecosystem of Gensyn includes four participating entities: submitters, executors, validators, and reporters.
- Submitter: The demand user is the consumer of the task, providing tasks to be computed and paying for AI training tasks.
- Executor: The executor performs the task of model training and generates proof of task completion for verification.
- Validator: Connects the non-deterministic training process with deterministic linear computation, compares the executor's proof with the expected threshold.
- Reporter: Checks the work of the validator, raises questions when problems are found, and earns rewards.
It can be seen that Gensyn aims to become a large-scale, economically efficient computing protocol for global deep learning models.
However, looking at this track, why do most projects choose decentralized computing power for AI inference rather than training?
Here, let's also help friends who are not familiar with AI training and inference understand the differences between the two:
- AI Training: If we compare artificial intelligence to a student, then training is similar to providing the student with a large amount of knowledge and examples, which can be understood as the data we often talk about. Artificial intelligence learns from these knowledge examples. Since learning requires understanding and memorizing a large amount of information, this process requires a lot of computational power and time.
- AI Inference: What is inference? It can be understood as using the acquired knowledge to solve problems or take exams. During the inference stage, artificial intelligence uses the acquired knowledge to answer questions, rather than acquiring new knowledge, so the computational power required during inference is relatively small.
It can be seen that the computational power requirements for the two are quite different. The availability of decentralized computing power for AI inference and AI training will be further analyzed in the subsequent challenge section.
In addition, Ritual aims to combine distributed networks with model creators, maintaining decentralization and security. Its first product, Infernet, allows smart contracts on the blockchain to access AI models off-chain, allowing such contracts to access AI in a way that maintains verification, decentralization, and privacy protection.
The coordinator of Infernet is responsible for managing the behavior of nodes in the network and responding to consumer computing requests. When using Infernet, inference, proofs, and other work are performed off-chain, and the output results are returned to the coordinator and ultimately transmitted to consumers on-chain.
In addition to decentralized computing power networks, there are also decentralized bandwidth networks like Grass, to improve the speed and efficiency of data transmission. In general, the emergence of decentralized computing power networks provides a new possibility for the supply side of AI computing power, driving AI towards new directions.
3.1.2 Decentralized Algorithm Models
As mentioned in Chapter 2, the three core elements of AI are computing power, algorithms, and data. Since computing power can form a supply network in a decentralized manner, can algorithms also have a similar approach to form a supply network for algorithm models?
Before analyzing the projects in this track, let's first understand the significance of decentralized algorithm models. Many people may wonder, since we already have OpenAI, why do we need a decentralized algorithm network?
Essentially, a decentralized algorithm network is a decentralized AI algorithm service market that connects many different AI models, each with its own expertise and skills. When users pose questions, the market selects the most suitable AI model to provide answers. Chat-GPT, developed by OpenAI, is an AI model that can understand and produce text similar to humans.
In simple terms, ChatGPT is like a highly capable student helping to solve different types of problems, while a decentralized algorithm network is like a school with many students helping to solve problems. Although the current student's capabilities are strong, in the long run, there is great potential for recruiting students from around the world.
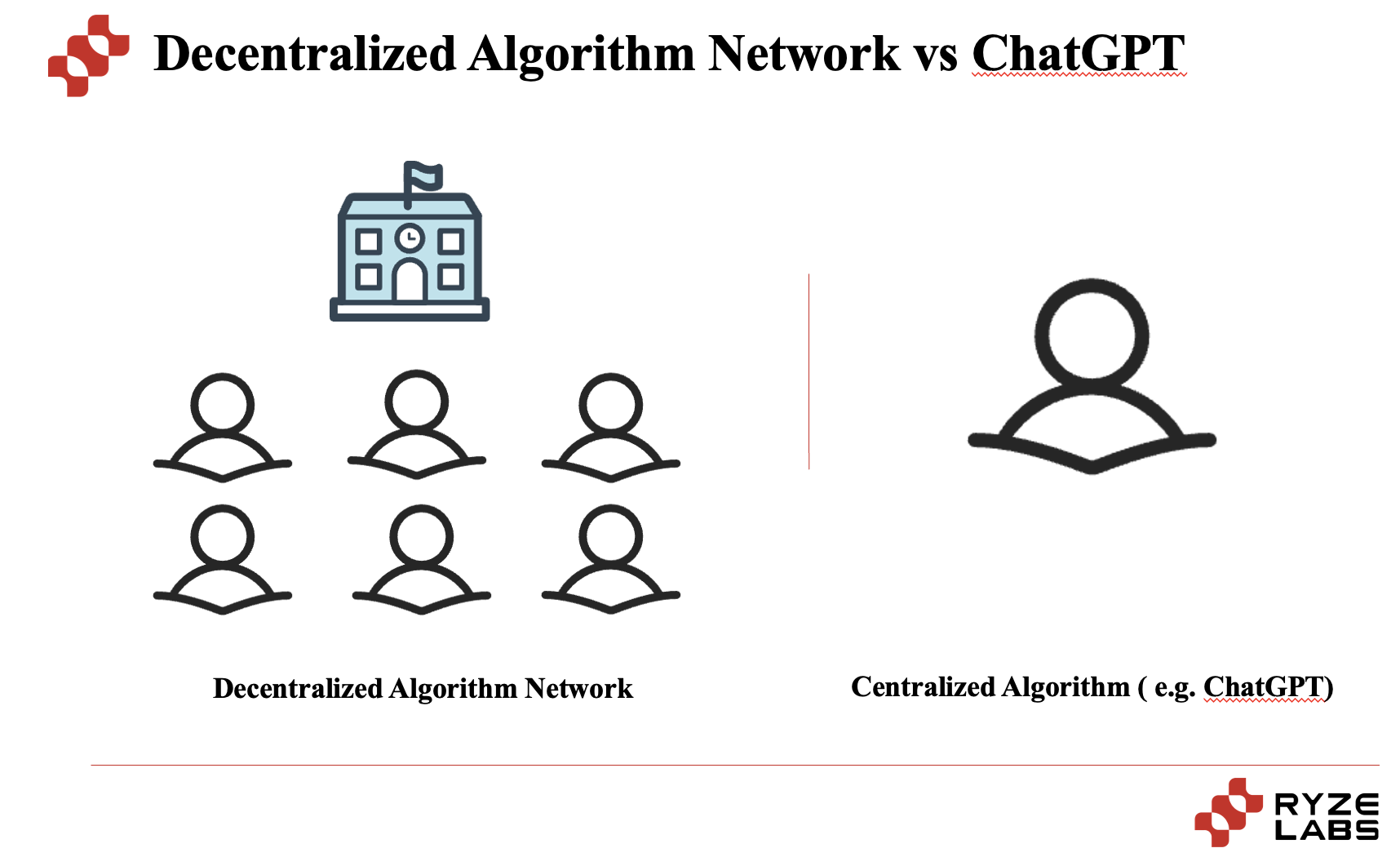
Currently, in the field of decentralized algorithm models, there are also some projects that are exploring and experimenting. Next, let's use the representative project Bittensor as a case study to help understand the development of this niche field.
In Bittensor, the supply side of algorithm models (or miners) contributes their machine learning models to the network. These models can analyze data and provide insights. Model providers receive the cryptocurrency token TAO as a reward for their contributions.
To ensure the quality of answers, Bittensor uses a unique consensus mechanism to ensure the network reaches a consensus on the best answer. When a question is posed, multiple model miners provide answers. Then, validators in the network begin working to determine the best answer, which is then sent back to the user through contracts.
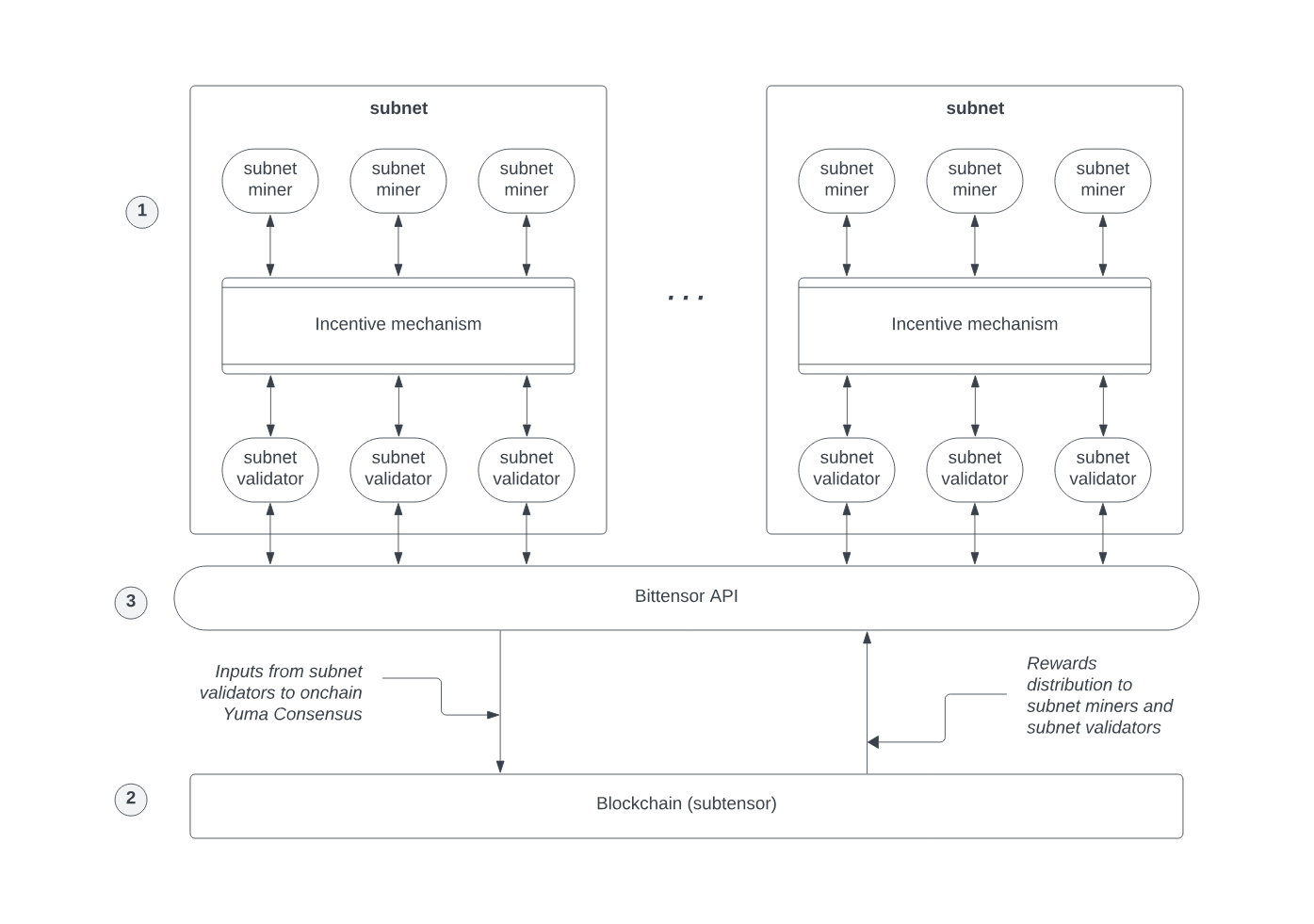
The token TAO in Bittensor primarily serves two purposes throughout the process: as an incentive for miners to contribute algorithm models to the network, and as a requirement for users to ask questions and have the network complete tasks.
As Bittensor is decentralized, anyone with internet access can join the network, either as a user posing questions or as a miner providing answers. This allows more people to use powerful artificial intelligence.
In summary, networks like Bittensor have the potential to create a more open and transparent ecosystem for decentralized algorithm models. In this ecosystem, AI models can be trained, shared, and utilized in a secure and decentralized manner. Additionally, there are also decentralized algorithm model networks like BasedAI attempting similar things, with the more interesting part being the use of ZK to protect user-model interactive data privacy, which will be further discussed in the fourth section.
With the development of decentralized algorithm model platforms, they will enable small companies to compete with large organizations in using top AI tools, potentially having a significant impact on various industries.
3.1.3 Decentralized Data Collection
For AI model training, a large supply of data is essential. However, currently, most web2 companies still claim ownership of user data, and platforms such as X, Reddit, TikTok, Snapchat, Instagram, and YouTube prohibit data collection for AI training. This has become a major obstacle to the development of the AI industry.
On the other hand, some web2 platforms sell user data to AI companies without sharing any profits with the users. For example, Reddit reached a $60 million agreement with Google, allowing Google to train AI models on its posts. This has led to the domination of data collection rights by big capital and big data, resulting in an overly capital-intensive direction for the industry.
Faced with this situation, some projects combine Web3 to achieve decentralized data collection through token incentives.
Taking PublicAI as an example, users can participate in two roles in PublicAI:
- One is as a provider of AI data, where users can find valuable content on X, @PublicAI with insights, use #AI or #Web3 as classification tags, and send the content to the PublicAI data center for data collection.
- The other is as a data validator, where users can log in to the PublicAI data center to vote for the most valuable data for AI training.
In return, users can earn token incentives for both contributions, promoting a mutually beneficial relationship between data contributors and the AI industry.
In addition to projects like PublicAI specifically collecting data for AI training, many other projects also use token incentives for decentralized data collection. For example, Ocean collects user data through data tokenization to serve AI, Hivemapper collects map data through users' in-car cameras, Dimo collects users' car data, and WiHi collects weather data, and so on. These projects that collect data in a decentralized manner are also potential supply sides for AI training, so in a broad sense, they can also be included in the paradigm of Web3 assisting AI.
3.1.4 ZK Protection of User Privacy in AI
In addition to the advantages of decentralization brought by blockchain technology, there is also a very important aspect, which is zero-knowledge proof. Through zero-knowledge technology, privacy can be protected while achieving information verification.
In traditional machine learning, data is usually centralized for storage and processing, which may lead to the risk of data privacy leakage. On the other hand, methods to protect data privacy, such as data encryption or de-identification, may limit the accuracy and performance of machine learning models.
The technology of zero-knowledge proof can help address this dilemma by resolving the conflict between privacy protection and data sharing.
ZKML (Zero-Knowledge Machine Learning) allows training and inference of machine learning models without revealing the original data, using zero-knowledge proof technology. Zero-knowledge proof enables the features of the data and the results of the model to be proven correct without revealing the actual data content.
The core goal of ZKML is to achieve a balance between privacy protection and data sharing. It can be applied to various scenarios such as medical health data analysis, financial data analysis, and cross-organizational collaboration. By using ZKML, individuals can protect the privacy of their sensitive data while sharing data with others to gain broader insights and collaboration opportunities, without worrying about the risk of data privacy leakage.
Currently, this field is still in its early stages, and most projects are still exploring. For example, BasedAI has proposed a decentralized approach, seamlessly integrating FHE and LLM to maintain data confidentiality. Using Zero-Knowledge Large Language Models (ZK-LLM) to embed privacy into the core of its distributed network infrastructure, ensuring the privacy of user data throughout the network operation.
Here's a brief explanation of Fully Homomorphic Encryption (FHE). Fully Homomorphic Encryption is an encryption technology that allows data to be computed while in an encrypted state, without the need for decryption. This means that various mathematical operations (such as addition, multiplication, etc.) performed on data encrypted using FHE can be carried out while maintaining the encrypted state of the data, and obtaining the same results as performing the same operations on the original unencrypted data, thus protecting the privacy of user data.
In addition to the above four categories, in terms of Web3 assisting AI, there are also blockchain projects like Cortex that support the execution of AI programs on-chain. Currently, running machine learning programs on traditional blockchains faces a challenge, as virtual machines are highly inefficient when running any non-trivial machine learning model. Therefore, most people believe that running artificial intelligence on the blockchain is impossible. However, Cortex's virtual machine (CVM) uses GPUs to execute AI programs on-chain and is compatible with EVM. In other words, the Cortex chain can execute all Ethereum Dapps and integrate AI machine learning into these Dapps. This achieves the decentralized, immutable, and transparent operation of machine learning models, as network consensus verifies every step of artificial intelligence inference.
3.2 AI Empowering Web3
In the collision of AI and Web3, in addition to the assistance of Web3 to AI, the assistance of AI to the Web3 industry is also worth paying attention to. The core contribution of artificial intelligence lies in enhancing productivity, so there are many attempts in AI-audited smart contracts, data analysis and prediction, personalized services, security, and privacy protection.
3.2.1 Data Analysis and Prediction
Currently, many Web3 projects are beginning to integrate existing AI services (such as ChatGPT) or self-developed AI to provide data analysis and prediction services for Web3 users. The coverage is very broad, including providing investment strategies, on-chain analysis AI tools, price and market predictions, and more using AI algorithms.
For example, Pond uses AI graph algorithms to predict future valuable alpha tokens, providing investment assistance to users and institutions. BullBear AI trains based on user historical data, price history, and market trends to provide the most accurate information to support price trend predictions, helping users gain profits.
There are also investment competition platforms like Numerai, where participants use AI and large language models to predict the stock market. The platform provides free high-quality data for model training and participants submit predictions daily. Numerai calculates the performance of these predictions over the next month, and participants can stake NMR on their models to earn profits based on their model's performance.
In addition, blockchain data analysis platforms like Arkham also integrate AI for services. Arkham links blockchain addresses with entities such as exchanges, funds, and whales, and displays key data and analysis of these entities to provide decision-making advantages to users. The integration with AI is seen in Arkham Ultra, which matches addresses with real-world entities using algorithms, developed over three years with the support of core contributors from Palantir and OpenAI.
3.2.2 Personalized Services
In Web2 projects, AI has many applications in the fields of search and recommendations, serving the personalized needs of users. This is also the case in Web3 projects, where many projects optimize user experience through AI integration.
For example, the well-known data analysis platform Dune recently launched the Wand tool, which uses large language models to write SQL queries. With the Wand Create feature, users can generate SQL queries based on natural language questions, making it very convenient for users who do not understand SQL to search.
In addition, some Web3 content platforms have started integrating ChatGPT for content summarization. For example, the Web3 media platform Followin integrates ChatGPT to summarize viewpoints and recent developments in a certain track. The Web3 encyclopedia platform IQ.wiki aims to be the primary source of objective, high-quality knowledge about blockchain technology and cryptocurrencies on the internet, making blockchain more easily discoverable and accessible globally, and integrates GPT-4 to summarize wiki articles. Kaito, a search engine based on LLM, aims to be a Web3 search platform, changing the way information is obtained in Web3.
In terms of content creation, there are projects like NFPrompt that reduce the cost of user creation. NFPrompt allows users to easily generate NFTs using AI, reducing the cost of user creation and providing many personalized services in content creation.
3.2.3 AI Auditing Smart Contracts
In the Web3 field, auditing smart contracts is also a very important task. Using AI to audit smart contract code can more efficiently and accurately identify and find vulnerabilities in the code.
As Vitalik has mentioned, one of the biggest challenges in the cryptocurrency space is errors in our code. An exciting possibility is that artificial intelligence (AI) can significantly simplify the use of formal verification tools to prove the codebase satisfies specific properties. If this can be achieved, we may have an error-free SEK EVM (such as the Ethereum Virtual Machine). The more errors are reduced, the greater the security of the space, and AI is very helpful in achieving this.
For example, the 0x0.ai project provides an AI smart contract auditor, which is a tool that uses advanced algorithms to analyze smart contracts and identify potential vulnerabilities or issues that may lead to fraud or other security risks. Auditors use machine learning techniques to identify patterns and anomalies in the code, flagging potential issues for further review.
In addition to the above three categories, there are also native cases of AI assisting the Web3 field, such as PAAL, which helps users create personalized AI bots that can be deployed on Telegram and Discord to serve Web3 users. The AI-driven multi-chain DEX aggregator Hera uses AI to provide the widest range of tokens and the best trading paths between any token pairs. Overall, AI's assistance to Web3 is more at the tool level.
Four, Current Limitations and Challenges of AI+Web3 Projects
4.1 Real Obstacles in Decentralized Computing Power
In the current projects that assist AI with Web3, a large part is focused on decentralized computing power, using token incentives to promote global users to become the supply side of computing power, which is a very interesting innovation. However, on the other hand, there are some practical issues that need to be addressed:
Compared to centralized computing power service providers, decentralized computing power products typically rely on nodes and participants distributed globally to provide computing resources. Due to potential latency and instability in the network connections between these nodes, the performance and stability of decentralized computing power products may be inferior to centralized computing power products.
In addition, the availability of decentralized computing power products is influenced by the degree of matching between supply and demand. If there are not enough suppliers or if demand is too high, it may lead to resource shortages or an inability to meet user needs.
Furthermore, compared to centralized computing power products, decentralized computing power products typically involve more technical details and complexity. Users may need to understand and deal with knowledge related to distributed networks, smart contracts, and cryptocurrency payments, which can increase the cost of user understanding and usage.
After in-depth discussions with numerous decentralized computing power projects, it has been found that current decentralized computing power is primarily limited to AI inference rather than AI training.
Next, I will address four specific questions to help everyone understand the underlying reasons:
- Why do most decentralized computing power projects choose to focus on AI inference rather than AI training?
- What makes NVIDIA so powerful? What are the challenges in decentralized computing power training?
- What will be the endgame for decentralized computing power projects like Render, Akash, and io.net?
- What will be the endgame for decentralized algorithm projects like Bittensor?
Let's peel back the layers:
1) Looking at this field, most decentralized computing power projects choose to focus on AI inference rather than training, primarily due to the different requirements for computing power and bandwidth.
To help everyone better understand, let's compare AI to a student:
AI Training: If we compare artificial intelligence to a student, training is similar to providing the student with a large amount of knowledge and examples, which can be understood as data. The artificial intelligence learns from these knowledge examples. Since learning requires understanding and memorizing a large amount of information, this process requires a significant amount of computing power and time.
AI Inference: What is inference? It can be understood as using the acquired knowledge to solve problems or take exams. During the inference stage, artificial intelligence uses the learned knowledge to answer questions, rather than acquiring new knowledge. Therefore, the computing power required for inference is much lower.
It is easy to see that the fundamental difference in difficulty between the two lies in the fact that training large AI models requires a huge amount of data and high bandwidth for rapid communication. Therefore, the current difficulty in implementing decentralized computing power for training large AI models is extremely high. In contrast, inference requires much less data and bandwidth, making it more feasible to implement.
For large models, stability is crucial. If training is interrupted, it would require retraining, resulting in high sunk costs. On the other hand, demands with relatively lower computing power requirements can be met. For example, as mentioned earlier, AI inference or training of small to medium-sized models in specific scenarios is possible. There are relatively large node service providers in decentralized computing power networks that can cater to these relatively large computing power demands.
2) So where are the bottlenecks in data and bandwidth? Why is decentralized training difficult to achieve?
This involves two key elements of training large models: single-card computing power and multi-card parallelism.
Single-card computing power: Currently, all supercomputing centers that require training large models, which we can call "supercomputing centers," use GPUs as the basic units. If the computing power of a single unit (GPU) is strong, then the overall computing power (single unit × quantity) may also be strong.
Multi-card parallelism: Training a large model often involves hundreds of billions of gigabytes. For supercomputing centers that train large models, they would need at least tens of thousands of A100s as a foundation. Therefore, these tens of thousands of cards need to be mobilized for training. However, training a large model is not simply a serial process. It does not involve training on the first A100 card and then training on the second card. Different parts of the model are trained on different cards, and the training of part A may require the results of part B, thus involving multi-card parallelism.
Why is NVIDIA so powerful, with soaring market value, while AMD and domestic companies like Huawei and Horizon are currently struggling to catch up? The key lies not in the single-card computing power itself, but in two aspects: the CUDA software environment and NVLink multi-card communication.
On one hand, the existence of a software ecosystem that can adapt to hardware is crucial, such as NVIDIA's CUDA system. Building a new system is very difficult, similar to creating a new language, and the replacement cost is very high.
On the other hand, multi-card communication is essential. Essentially, the transmission between multiple cards is the input and output of information, and how to parallelize and transmit. Due to the existence of NVLink, it is not possible to connect NVIDIA and AMD cards. Furthermore, NVLink restricts the physical distance between cards, requiring the cards to be in the same supercomputing center. This makes it difficult to achieve decentralized computing power if the computing power is distributed worldwide.
The first point explains why AMD and domestic companies like Huawei and Horizon are currently struggling to catch up, and the second point explains why decentralized training is difficult to achieve.
3) What will be the endgame for decentralized computing power?
Decentralized computing power is currently difficult to use for training large models, primarily due to the emphasis on stability in training large models. If training is interrupted, it would require retraining, resulting in high sunk costs. The requirements for multi-card parallelism are also high, and bandwidth is limited by physical distance. NVIDIA uses NVLink to achieve multi-card communication. However, NVLink restricts the physical distance between cards, making it difficult to form a computing power cluster for training large models with decentralized computing power distributed worldwide.
However, on the other hand, demands with relatively lower computing power requirements can be met. For example, AI inference or training of small to medium-sized models in specific scenarios is possible. There are relatively large node service providers in decentralized computing power networks that have the potential to cater to these relatively large computing power demands. Additionally, scenarios like edge computing for rendering are relatively easy to implement.
4) What will be the endgame for decentralized algorithm models?
The endgame for decentralized algorithm models depends on the future of AI. I believe the future AI landscape may consist of 1-2 closed-source model giants (such as ChatGPT), along with a variety of models. In this context, it is not necessary for application-layer products to be tied to a single large model, but rather to collaborate with multiple large models. In this context, the potential for models like Bittensor is still significant.
4.2 The Combination of AI and Web3 is Rough and Has Not Achieved 1+1>2
Currently, in projects combining Web3 and AI, especially in AI-assisted Web3 projects, most projects still only superficially use AI without truly demonstrating a deep integration between AI and cryptocurrencies. This superficial application is mainly evident in the following two aspects:
Firstly, whether using AI for data analysis and prediction, in recommendation and search scenarios, or for code auditing, the integration of Web2 projects with AI does not differ significantly from the integration of AI with Web3 projects. These projects simply use AI to improve efficiency and conduct analysis, without demonstrating a native integration and innovative solutions between AI and cryptocurrencies.
Secondly, the integration of many Web3 teams with AI is more of a marketing tactic, purely using the concept of AI. They have only applied AI technology in very limited areas and then started promoting the trend of AI, creating an illusion of a close connection between the project and AI. However, in terms of true innovation, these projects still have a long way to go.
Although current Web3 and AI projects have these limitations, we should recognize that this is only the early stage of development. In the future, we can expect more in-depth research and innovation to achieve a closer integration between AI and cryptocurrencies, creating more native and meaningful solutions in finance, decentralized autonomous organizations, prediction markets, NFTs, and other fields.
4.3 Tokenomics as a Buffer for the Narrative of AI Projects
As mentioned at the beginning, the challenge of the business model for AI projects is becoming increasingly prominent. As more and more large models are gradually open-sourced, many AI+Web3 projects often find it difficult to develop and finance as pure AI projects in Web2. Therefore, they choose to overlay the narrative of Web3 and tokenomics to promote user participation.
However, the key question is whether the integration of tokenomics truly helps AI projects meet actual needs, or if it is purely narrative or short-term value. This is a question that needs to be addressed.
Currently, most AI+Web3 projects are far from practical. It is hoped that more pragmatic and innovative teams will not only use tokens as a publicity tool for AI projects, but truly meet practical needs in various scenarios.
Five, Conclusion
Currently, many cases and applications have emerged in AI+Web3 projects. Firstly, AI technology can provide more efficient and intelligent application scenarios for Web3. Through AI's data analysis and predictive capabilities, it can help Web3 users have better tools for investment decisions and other scenarios. Additionally, AI can audit smart contract code, optimize the execution process of smart contracts, and improve the performance and efficiency of blockchain. At the same time, AI technology can provide more precise and intelligent recommendations and personalized services for decentralized applications, enhancing user experience.
At the same time, the decentralization and programmability of Web3 also provide new opportunities for the development of AI technology. Through token incentives, decentralized computing power projects provide new solutions for the supply-demand dilemma of AI computing power. Web3's smart contracts and distributed storage mechanisms also provide a broader space and resources for the sharing and training of AI algorithms. Web3's user autonomy and trust mechanisms also bring new possibilities for the development of AI. Users can choose to participate in data sharing and training, thereby improving the diversity and quality of data, further enhancing the performance and accuracy of AI models.
Although current cross-projects of AI+Web3 are still in the early stages and face many challenges, they also bring many advantages. For example, decentralized computing power products have some drawbacks, but they reduce reliance on centralized institutions, provide greater transparency and auditability, and enable broader participation and innovation. For specific use cases and user needs, decentralized computing power products may be a valuable choice. The same applies to data collection, where decentralized data collection projects also bring some advantages, such as reducing reliance on a single data source, providing broader data coverage, and promoting data diversity and inclusivity. In practice, it is necessary to balance these advantages and disadvantages and take appropriate management and technical measures to overcome challenges, ensuring that decentralized data collection projects have a positive impact on the development of AI.
Overall, the integration of AI+Web3 provides unlimited possibilities for future technological innovation and economic development. By combining the intelligent analysis and decision-making capabilities of AI with the decentralization and user autonomy of Web3, it is believed that a more intelligent, open, and fair economic and even social system can be built in the future.
VI. References
https://docs.bewater.xyz/zh/aixcrypto/
https://medium.com/@ModulusLabs
https://docs.bewater.xyz/zh/aixcrypto/chapter2.html#_3-4-4-%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E6%8A%80%E6%9C%AF%E5%BC%80%E6%BA%90%E7%9A%84%E9%97%AE%E9%A2%98
https://docs.bewater.xyz/zh/aixcrypto/chapter4.html#_1-2-1-%E6%95%B0%E6%8D%AE
https://mirror.xyz/lukewasm.eth/LxhWgl-vaAoM3s_i9nCP8AxlfcLvTKuhXayBoEr00mA
https://www.galaxy.com/insights/research/understanding-intersection-crypto-ai/
https://www.theblockbeats.info/news/48410?search=1
https://www.theblockbeats.info/news/48758?search=1
https://www.theblockbeats.info/news/49284?search=1
https://www.theblockbeats.info/news/50419?search=1
https://www.theblockbeats.info/news/50464?search=1
https://www.theblockbeats.info/news/50814?search=1
https://www.theblockbeats.info/news/51165?search=1
https://www.theblockbeats.info/news/51099?search=1
https://www.techflowpost.com/article/detail_16418.html
https://blog.invgate.com/chatgpt-statistics
https://www.windowscentral.com/hardware/computers-desktops/chatgpt-may-need-30000-nvidia-gpus-should-pc-gamers-be-worried
https://www.trendforce.com/presscenter/news/20230301-11584.html
https://www.linkedin.com/pulse/great-gpu-shortage-richpoor-chris-zeoli-5cs5c/
https://www.semianalysis.com/p/google-gemini-eats-the-world-gemini
https://news.marsbit.co/20230613141801035350.html
https://medium.com/@taofinney/bittensor-tao-a-beginners-guide-eb9ee8e0d1a4
https://www.hk01.com/%E7%B6%B2%E7%A7%913.0/1006289/iosg-%E5%BE%9E-ai-x-web3-%E6%8A%80%E8%A1%93%E5%A0%86%E6%A3%A7%E5%B1%95%E9%96%8B-infra-%E6%96%B0%E6%95%98%E4%BA%8B
https://arxiv.org/html/2403.01008v1
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








