Article Source: AIGC Open Community

Image Source: Generated by Unbounded AI
Currently, most text-to-image models use random sampling mode, resulting in different image effects each time, and performing poorly in generating coherent images.
For example, even with similar prompts, it is difficult to generate a set of coherent images through AI. Although DALL·E 3 and Midjourney can achieve coherent image generation control, both of these products are closed source.
Therefore, researchers from NVIDIA and Tel Aviv University have developed a zero-training consistent and coherent text-to-image model—ConsiStory. (To be open-sourced soon)
Paper link: https://arxiv.org/abs/2402.03286
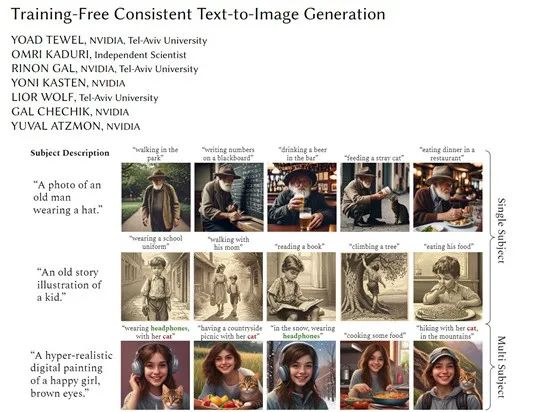
Currently, the main reasons why text-to-image models perform poorly in generating content consistency are: 1) They cannot recognize and locate common subjects in images. Text-to-image models do not have built-in object detection or segmentation modules, making it difficult to automatically identify the same subject in different images;
2) They cannot maintain visual consistency of the subject in different images. Even if the subject is located, it is difficult to ensure that independently generated subjects in different steps maintain a high degree of similarity in detail.
The mainstream methods to solve these two problems are based on personalized and encoder optimization. However, both of these methods require additional training processes, such as fine-tuning model parameters for specific subjects or using target images to train encoders as conditions.
Even with these optimization methods, the training period is long and difficult to extend to multiple subjects, and it is easy to deviate from the original model distribution.
ConsiStory proposes a completely new method, which can achieve subject consistency without any training or tuning by sharing and adjusting the model's internal representation.
It is worth mentioning that ConsiStory can serve as a plugin to help other diffusion models improve the consistency and coherence of text-to-image generation.
Subject-Driven Self-Attention (SDSA)
SDSA is one of the core modules of ConsiStory, which can share subject-related visual information in the generated image batch, ensuring the consistency of subjects in different images.
SDSA mainly expands the self-attention layer in diffusion models, allowing "prompts" in one image to focus not only on the output of their own image, but also on the output of the subject area in other images in the batch.
This way, the visual features of the subject can be shared across the entire batch, aligning the subjects in different images with each other.
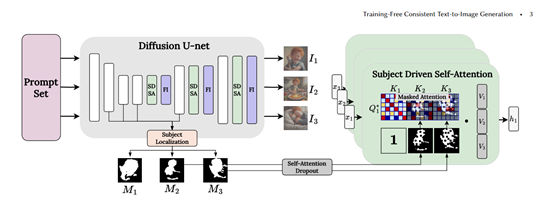
To prevent sensitive information leakage between background areas, this module uses subject segmentation masks for masking—each image can only focus on the output of the subject area in other images in the batch.
The subject mask is automatically extracted through the cross-attention features of the diffusion model itself.
Feature Injection
To further enhance the consistency of subject details between different images, "feature injection" establishes a dense correspondence map based on the diffusion feature space, allowing the sharing of self-attention output features between images.
Similar optimization areas in different images share self-attention features, effectively ensuring that subject-related textures, colors, and other detailed features are aligned across the entire batch.
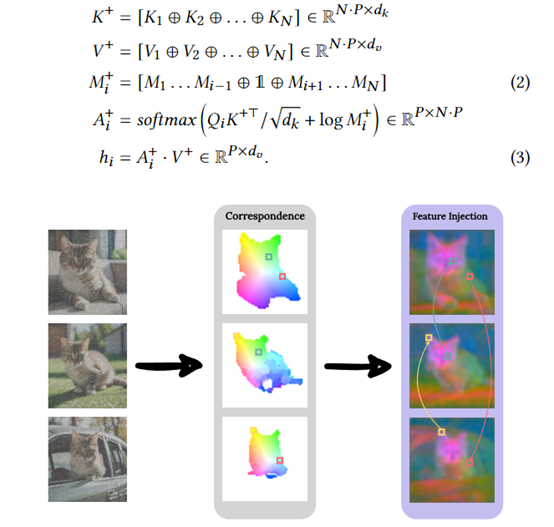
Feature injection also uses subject masks for masking, only executing feature sharing in the subject area. It also sets a similarity threshold, only executing it in sufficiently similar optimizations.
Anchor Images and Reusable Subjects
Anchor images in ConsiStory provide a reference function for subject information, mainly used to guide the image generation process and ensure consistency in the generated images.
Anchor images can be images provided by users or related images obtained from other sources. During the generation process, the model will refer to the features and structure of the anchor image and generate images as consistent as possible.

Reusable subjects are achieved by sharing the internal activations of pre-trained models to ensure subject consistency. During the image generation process, the model will use the internal feature representation of the pre-trained model to align the generated images without further alignment of external source images.

In other words, the generated images can focus on and share features with each other, allowing ConsiStory to achieve zero training cost and avoid the difficulties of training for each subject required by traditional methods.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







