Source: AI Technology Review
Author: Wang Yue

Image Source: Generated by Unlimited AI
About a month ago, two weeks before the launch of GPT Store, a foreign developer named Kyle Tryon shared on his personal blog three Agents (also known as "GPTs") developed based on ChatGPT Plus. One of the Agents is a personal guide for traveling in Philadelphia, USA, called "PhillyGPT". It can access the local SEPTA public transportation API to provide individuals with real-time weather, travel information, cultural and artistic events, travel routes, bus stations and landmark data, estimated arrival times, and more in Philadelphia.
You can visit the PhillyGPT link for more details: PhillyGPT
The development of the Philadelphia personal guide is actually people's true imagination of C-end personalized consumer products in the GPT era. Similarly, on January 11th, after OpenAI officially launched GPT Store and announced 3 million GPTs, it also recommended the hiking route guide "AllTrails" which is closely related to users' daily consumption activities. Unlike the situation in China where there are some concerns about the prospects of large models, the development of a large number of personalized applications overseas is flourishing.
In the era of personalized economy, the development of large models in China actually needs to change the old problem-solving mindset.
Among the many large model manufacturers in China, MiniMax is one of the few that insists on product innovation and pursues personalized applications. Starting from this original intention, since its debut in early March last year, when most teams were still in the early stages of large language model development, MiniMax has excelled in the crowded field with its positioning of multimodal large models, and its valuation has soared, making it one of the highest valued large model manufacturers in China.
Of particular note, MiniMax is also one of the very few teams that have bet on large speech models.
Different from text and images, the development of speech models is niche, and the community data ecosystem is not prosperous, making it difficult to obtain a large amount of high-quality data for model training. However, in scenarios with a large number of individual users such as social, entertainment, and education, voice is often an important component of many To C and B2B2C products, and it is a battleground for the commercialization of large models.
Recently, MiniMax has also launched a new generation of speech models that surpass traditional speech technology in multiple performance indicators.
The capabilities of the speech model are widely used in MiniMax's own product, Xingye. In a recent AI challenge launched within the Xingye app, the capabilities of the MiniMax speech model were fully demonstrated. Not only can it synthesize speech naturally, but it can also simulate human rap, with a variety of styles, approaching the level of a real human rapper.
(For friends who want to participate in the Xingye AI battle rap, you can click: AI Battle Rap to experience):
According to AI Technology Review, MiniMax's latest speech model is trained on high-quality audio data spanning millions of hours, and its performance is not inferior to ElevenLabs and OpenAI.
At the same time, MiniMax is actively promoting the application of speech capabilities, creating an open platform for B-side users, and launching the AI speech dialogue product "Hailuowenwen" for C-side users, which only requires a 6-second audio to replicate the voice.
In the era of GPT, MiniMax's large model economy has broken the limitations of single text and defined a new connotation of personalized applications starting from "voice".
1. Every silicon-based user can have their own voice
In the era of AIGC, the demand for speech generation is actually no less than that for text and images.
From the perspective of AI landing, the ability of large language models to predict text sequences is the first step in the engineering of AIGC products. However, in practical applications, the single presentation of text often does not perform well, and the expressive power of voice can provide strong support for the emotional color and personal expression of text content.
Take AI video generation as an example. In the scenario of using AI technology to generate short videos, "breaking character" is the main weakness in user experience, and voice is often the "culprit" for breaking character. In the application of AIGC products, the fidelity of character voices, the fluency of speech intonation, and the naturalness of speech pauses are the main challenges of speech synthesis technology, and they must be "packaged" to be solved, without neglecting any of them, as any weakness will reduce the user's product experience.
Different scenarios have different requirements for the effect of speech synthesis. For example, live streaming for e-commerce requires high timeliness and low latency in the interaction between the anchor and the audience, the replication of audio books requires the rapid generation of multiple character voices and speech content, and the educational teaching scenario requires precise pronunciation of some special and rare words.
Therefore, providing users with high-quality and personalized speech experiences and services based on traditional speech synthesis technology has become the next difficult problem in speech generation.
In the past, the pain points of speech synthesis technology on the market were obvious:
- Strong mechanical feeling, due to sacrificing the naturalness of some human voices, the voice cannot convey emotions;
- Relatively single tone, unable to provide multiple tones for users to choose from, and unable to meet the diverse needs of different scenarios;
- High cost and low efficiency, requiring professional equipment and taking a long time.
To solve this series of pain points, many leading companies at home and abroad have also conducted related explorations.
Google's multimodal large model Gemini attempts to seamlessly understand and infer the input content of the three popular modes of text, image, and speech, but in practical applications, Gemini's text, visual, and audio are considered to be a "rigid splicing state". For more information about domestic and foreign large model manufacturers, feel free to add the author: s1060788086 to chat.
The speech synthesis effect of the startup ElevenLabs is amazing, but it is more suitable for English text, and its Chinese speech synthesis capability is slightly inferior.
There are also open-source TTS models such as Tortoise and Bark that have accumulated a certain number of users, but according to user feedback, Tortoise has a slow generation speed, and Bark has uneven sound quality, making it difficult to be commercialized at present.
Competing with its peers, MiniMax is also continuously iterating its self-developed speech large model, and the latest speech large model has made MiniMax the first domestic large model company to open a commercial interface for multi-role dubbing.
Relying on the capabilities of the new generation of large models, MiniMax's speech large model can intelligently predict the emotions, intonation, and other information of the text based on the context, and generate super-natural, high-fidelity, and personalized speech to meet the personalized needs of different users.
Compared to traditional speech synthesis technology, MiniMax's speech large model achieves a new level of "AI" authenticity in terms of sound quality, sentence breaks, and rhythm.
By combining punctuation and contextual language, MiniMax's speech large model can comprehensively interpret the emotions, tone, and even laughter hidden behind the text, and can handle them appropriately.
In some special contexts, it can also demonstrate dramatic vocal tension. For example, when a speaker is amused by a friend's joke and bursts into laughter, it can also match this exaggerated emotion and laugh heartily.
In addition to the supernatural AI speech generation effect, another highlight of the MiniMax speech large model is its diversity and high scalability. It can accurately capture the unique characteristics of thousands of tones and freely combine them to easily create infinite voice variations, emotions, and styles. This advantage can flexibly meet various scenarios such as social media, podcasts, audiobooks, news, education, and digital characters.
2. Long Text Speech Generation, API Price Reduced by Half
Starting from the second half of 2023, the large model industry has seen two battlegrounds: long text and commercialization. The competition in the former is also concentrated in the text field, with competition ranging from 32k to 200k characters heating up, while speech generation remains a blue ocean. The commercialization of the latter is mainly reflected in pricing.
A large model practitioner told AI Technology Review, "The technical barriers of large models are decreasing, and in the end, it's about who can first reduce the cost of model training and deployment." The market demand for large models is no longer a choice between high-performance model quality and competitive product services.
In the field of speech generation, MiniMax's text-to-speech interface has also undergone rapid iterations:
On September 12, 2023, MiniMax released the long text-to-speech synthesis interface T2A pro, which can input up to 35,000 characters for single speech synthesis and adjust parameters such as intonation, speed, volume, bit rate, and sampling rate, mainly suitable for the audiobook of long texts.
On November 15, 2023, MiniMax launched the asynchronous long text interface T2A large, supporting users to upload text with a length of up to 10 million characters at a time.
On November 17, 2023, MiniMax released the speech large model abab-speech-01, with significantly improved overall performance in rhythm, emotional expression, style diversity, mixed Chinese and English, and multi-language capabilities.
While improving model performance, MiniMax has also reduced the prices of its APIs: according to official sources, the prices of MiniMax's three text-to-speech interfaces T2A pro, T2A, and T2A Stream have been reduced to half of the original prices, from 10 yuan per 10,000 characters to 5 yuan per 10,000 characters.
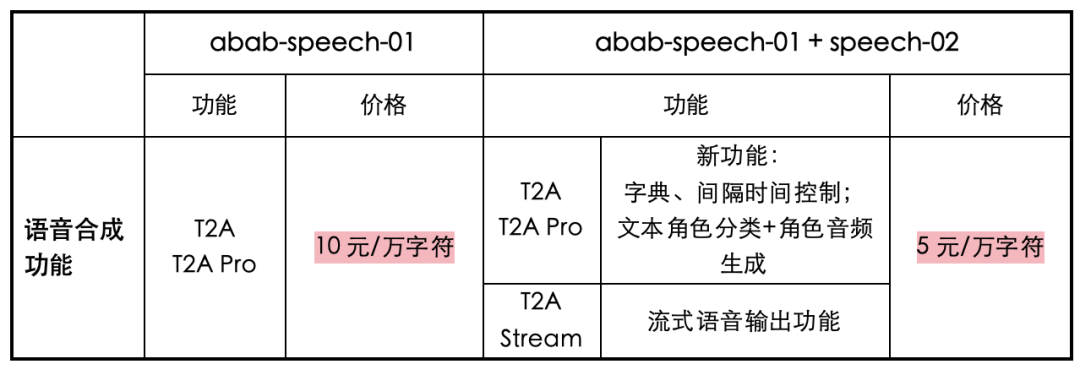
Based on its self-developed multimodal large model foundation, MiniMax's speech large model has also made layouts in the fields of speech assistants, news broadcasting, IP replication, and CV dubbing.
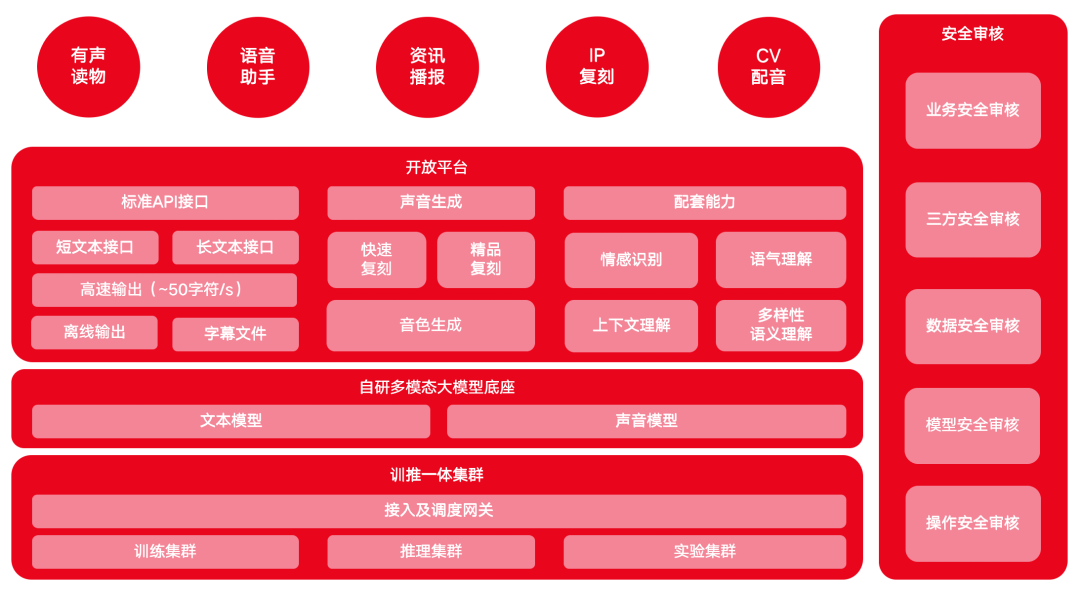
MiniMax Speech Large Model Product Architecture
To enhance model capabilities to meet the high-demand for speech from users, in January 2024, MiniMax's open platform added the following product features on top of its existing interface capabilities:
- Three new API interfaces were added, including multi-role audio generation API, text role classification API, and rapid replication API, mainly suitable for autonomous batch generation and cloning of multi-role audio.
- Added T2A Stream (streaming speech output) capability to reduce the waiting time for users to generate speech and achieve synchronous speech generation and output.
- Added multi-language capabilities, dictionary functions, and interval control functions to meet users' diverse customization needs.
Specifically, the text role classification API can quickly distinguish different roles corresponding to different dialogues, the role audio generation API can achieve multi-role differentiation and multi-role broadcasting, and the rapid replication API allows users to quickly complete voice replication online. The combination of these three APIs provides a complete set of text-based role voice production solutions—more efficient role division, multi-role speech generation, and fully autonomous voice replication.
MiniMax told AI Technology Review that the three new API interfaces added to the open platform are to better address the issue of large text content.
In the generation of speech from long texts, the usual practice in the past was to manually label the role attribution of each dialogue and then use the speech model to generate virtual voices, which was time-consuming and labor-intensive. However, the speech large model open platform of MiniMax, using interface calls, can help users more efficiently generate multi-role voices.
Take the production of audiobooks as an example. The three API functional interfaces of MiniMax's speech open platform can eliminate the step of manually dividing text roles, automatically understand the text, divide roles, and create different voices for different roles. By collaborating with Qidian to create new AI voices for audiobooks, "Mr. Shuoshuoxiansheng" and "Miss Fox," the three interfaces can autonomously achieve high-quality voice replication online. This ensures the consistency of character voices and efficient and quick dubbing for multiple roles.
T2A Stream (streaming speech output) can quickly respond with a processing capacity of 500 characters of input. In scenarios requiring real-time feedback, it can generate speech in real-time in interactive dialogues, allowing users to receive speech responses without waiting.
At the same time, T2A Streaming has mixing and character checking functions to ensure the quality of the output content, and provides parameters such as intonation, speed, volume, as well as support for multiple audio formats (MP3, WAV, PCM) and return parameters (audio duration, size, etc.), allowing developers to customize speech services according to specific application needs.
In meeting users' customization needs, MiniMax's speech large model has also upgraded three new functions:
- Multilingual capabilities to make the mixed Chinese and English output sound more natural.
- Dictionary function allowing users to customize text pronunciation.
- Interval control function for fine-tuning pause rhythm.
These functions have been more widely used in educational scenarios, where the AI postgraduate entrance exam digital character "Wen Yong Teacher" created in collaboration with Gaotu can better conduct lectures and answer questions, providing students with a smoother learning experience.
Furthermore, the interval control function also makes the voice of audiobook characters or digital character dubbing more natural, effectively reversing the mechanical feel of traditional speech generation without pauses, improving the rhythm of speech, and making it more in line with human expression habits.
In educational scenarios, dialogues like the following are often encountered:
- The teacher said: "Hello, everyone! I am your math teacher, and I have a little challenge for you. Here's the question: Xiao Ming has 7 apples. If he gives 3 apples to Xiao Hua, how many apples will Xiao Ming have left? You have 10 seconds to think about it and find the answer! #10#> Time's up! Can anyone tell me the answer? That's right, Xiao Ming will have 4 apples left. Congratulations if you got it right! Because 7 minus 3 equals 4, so Xiao Ming will have 4 apples left.
Here, using the control code #X#> (where X is a numerical variable, ranging from 0.01 to 99.99 seconds) to add interval markers in the text, users can add the desired speech pause duration.
2. Sea Snail Ask To C, Bringing AI and People Closer through Speech
Since its establishment, MiniMax has been innovative in its To C product form.
According to MiniMax, they are walking on both legs in commercialization, with To B and To C. In the eyes of investors and the market, its innovation in C-end products has outshone many other large model manufacturers in the country, from Glow to Xingye, MiniMax's C-end products have always been eye-catching.
At the C-end, MiniMax's speech large model has also demonstrated unique advantages, first and foremost in its dialogue product Sea Snail Ask.
In this speech dialogue product based on large language model technology, the blessing of MiniMax's self-developed speech large model makes Sea Snail Ask stand out among similar products. After AI Technology Review's firsthand evaluation, it was particularly impressed by its supernatural and high-fidelity speech effect. Simply from the listening experience, it's difficult to distinguish whether the question-and-answer voice output by Sea Snail Ask is from a real person or synthesized by its speech large model.
For example, when asked "Where to go on the weekend?" the voice output by Sea Snail Ask sounds like a friend's tone and identity, engaging in easy conversation, communication, and discussion, rather than generating content mechanically, word by word, like traditional AI synthesized speech.
When hearing interesting questions, Sea Snail Ask will laugh; when encountering difficult questions, Sea Snail Ask will ponder and pause, as if "thinking." If not for confirming with MiniMax about the integration of the speech large model into Sea Snail Ask, users would probably think that there is a real person on the other end of the machine.
To achieve real-time conversation, Sea Snail Ask performs outstandingly in low latency, without the traditional large model's 5-10 seconds of thinking time, it can instantly output through the T2A Stream capability. In addition to the interactive form of voice messages, users can also click on the phone icon in the lower right corner of the UI interface to start a real-time voice call.
Before the formal call, users can choose the voice they want AI to output. Among them, there are cartoon-style voices like "Imitate Xiong Er," as well as friendly female voices like "Xin Yue," deep and magnetic male voices like "Zi Xuan," and representative royal voices like "Pang Ju," similar to those in ancient costume dramas.
In addition to the dozens of pre-set voices with different styles, Sea Snail Ask can also create its own voice, quickly replicating the voice through low samples in a short time. Just follow the instructions on the interface, read a given text of about 40 characters, and wait a few seconds to hear a highly restored version of your own voice.
In this way, every ordinary user using Sea Snail Ask can easily meet the demand for unlimited voice replication.
However, the ability to replicate voices is often a paid feature in the current market. Many AIGC application layer manufacturers consider it as one of their own products for sale, requiring users to spend time and effort to record their own audio, and then pay a high price, sometimes thousands or even tens of thousands, for realistic voice replication effects. On top of that, there are restrictions on usage frequency, duration, and subjects, making it a profitable business.
Sea Snail Ask, on the other hand, offers voice replication functionality to users for free, without charging for usage duration and frequency. At the same time, the operation process is simple, taking only 6 seconds to obtain a cloned audio, which undoubtedly lowers the threshold for people to use AI to change their lives and production, making it much more convenient for personal use.
Many users have provided feedback that they have recorded their mother's voice in Sea Snail Ask, so when asking questions about life in the app, it feels like their mother is there to help, and when searching for recipes, it's like their mother is teaching them how to cook. Some people have also preserved the voices of lost loved ones in Sea Snail Ask, using the voice to cherish the past.
In addition, the significance of Sea Snail Ask is not only in user questioning and intelligent responses, but it is also a chat software that allows free conversation to a greater extent. There is no need to be particularly concerned about the accuracy and standardization of sentences as in written expression, you can say whatever you want, and Sea Snail Ask can handle it, and sometimes even guide the conversation and ask questions actively.
What's even more exciting is that the voice sharing feature will be launched on Sea Snail Ask in the next few days. AI Technology Review has exclusively learned that through this feature, users can share their cloned voices with each other on social media platforms like WeChat through a method similar to voice red envelopes, further realizing "voice socialization."
Making AI voices sound as natural and appealing as human voices, the technological breakthroughs and a series of attempts by MiniMax's speech large model on Sea Snail Ask are a big step towards eliminating the gap between people and artificial intelligence.
In the past, the AI race for speech understanding focused on improving the accuracy of speech input and output. Now, MiniMax has not forgotten to focus on the speech interaction effects that affect user experience, reflecting the strategic vision and execution capabilities of this "young" company.
In 2024, MiniMax has fired the first shot for speech large models, which may be worth considering for every explorer in the industry: in which direction should technology evolve in the current world? What kind of large model is needed? What kind of products should be made?
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





