Author: Wuyue & Faust, Geek web3
Advisor: Kevin He, Founder of BitVM Chinese Community, ex Web3 Tech Head@Huobi
Currently, Bitcoin Layer2 has become a trend, and there are reportedly dozens of projects positioning themselves as "Bitcoin Layer2" in the market. Among them, many claim to be "Rollup" Bitcoin Layer2, stating that they have adopted the solution proposed in the BitVM white paper, making BitVM a model in the Bitcoin ecosystem.
Unfortunately, most of the current textual information about BitVM has not been able to explain its principles in a popular way.
This article is a simple summary we came up with after reading the 8-page BitVM white paper and consulting materials related to Taproot, MAST tree, and Bitcoin Script. In order to facilitate readers' understanding, some expressions are different from those in the BitVM white paper. We assume that readers have some understanding of Layer2 and can understand the simple idea of "fraud proof".

To summarize BitVM's approach in a few words: data that does not need to be on chain is first published and stored off chain, and only commitments are stored on chain.
When a challenge/fraud proof occurs, we only put the data that needs to be on chain on chain, proving its association with the commitments on chain. Then, the BTC mainnet verifies whether these on-chain data have any issues and whether the data producers (nodes processing transactions) have engaged in malicious behavior. All of this follows the principle of Occam's razor - "if it is not necessary, do not increase entities" (if it can be done with less on chain, then do less on chain).

Text: The so-called BTC on-chain fraud proof verification solution based on BitVM, in simple terms:
- First, a computer/processor is an input-output system composed of a large number of logic gate circuits. One of the core ideas of BitVM is to use Bitcoin Script to simulate the input-output effect of logic gate circuits.
As long as logic gate circuits can be simulated, theoretically, a Turing machine can be implemented to complete all computable tasks. In other words, as long as you have enough people and money, you can gather a group of engineers to help you use rudimentary Bitcoin Script code to first simulate logic gate circuits, and then use a massive number of logic gate circuits to implement the functionality of EVM or WASM.
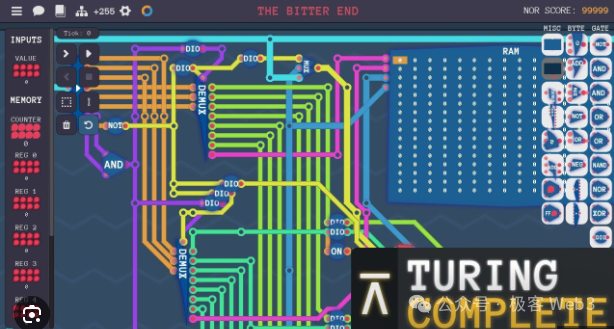
Some have compared BitVM's approach to: building an M1 processor using redstone circuits in "Minecraft". Or, it's like building the Empire State Building with building blocks.

- So, why bother simulating EVM or WASM with Bitcoin Script? Isn't this very troublesome? This is because most Bitcoin Layer2 projects often choose to support high-level languages such as Solidity or Move, while what can currently run directly on the Bitcoin chain is Bitcoin Script, a rudimentary, non-Turing complete programming language composed of a unique set of opcodes.
If Bitcoin Layer2 intends to verify fraud proof on Layer1 like Arbitrum and inherit BTC security to a great extent, it needs to directly verify "certain disputed transactions" or "certain disputed opcodes" on the BTC chain. This boils down to:
Implementing the effects of EVM or other virtual machines using Bitcoin Script, a rudimentary programming language native to Bitcoin.
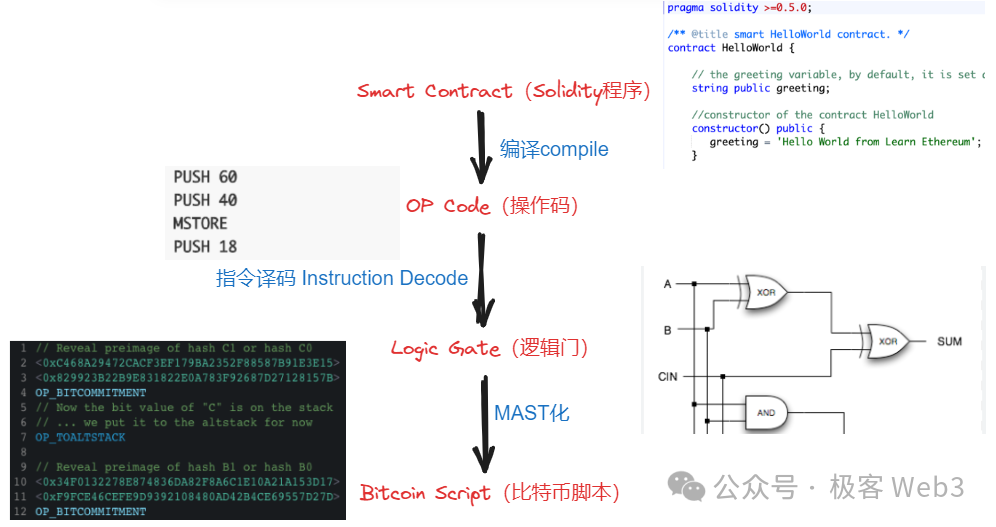
Therefore, from the perspective of compiler theory, the BitVM solution translates EVM/WASM/Javascript opcodes into Bitcoin Script opcodes, with logic gate circuits serving as an intermediate form (IR) between "EVM opcodes -> Bitcoin Script opcodes".
 (In the BitVM white paper, the general idea of executing certain "disputed instructions" on the Bitcoin chain is discussed)
(In the BitVM white paper, the general idea of executing certain "disputed instructions" on the Bitcoin chain is discussed)
Anyway, the ultimate effect of the simulation is to directly process the instructions that were originally handled on EVM/WASM on the Bitcoin chain. While this approach is feasible, the challenge lies in how to express all EVM/WASM opcodes as opcodes using a large number of logic gate circuits as an intermediate form. Additionally, using combinations of logic gate circuits to directly express extremely complex transaction processing flows may result in a huge amount of work.
- Next, let's talk about another core concept mentioned in the BitVM white paper, which is the "interactive fraud proof" highly similar to Arbitrum.
Interactive fraud proof involves a term called "assert". Generally, the proposer of Layer2 (often acted by a sequencer) will publish an assert assertion on Layer1, declaring that certain transaction data or state transition results are valid and correct.
If someone believes that the assert assertion submitted by the proposer is problematic (the associated data is incorrect), a dispute will arise. At this point, the proposer and challenger will exchange information in rounds and use binary search to quickly locate a very fine-grained operation instruction and its associated data fragment.
For the disputed operation instruction (OP Code), it needs to be directly executed on Layer1 along with its input parameters, and the output result needs to be verified (Layer1 nodes will compare the output result they calculated with the output result previously published by the proposer). In Arbitrum, this is referred to as "single-step fraud proof".

Reference: Former Arbitrum technical ambassador explains the component structure of Arbitrum (above)
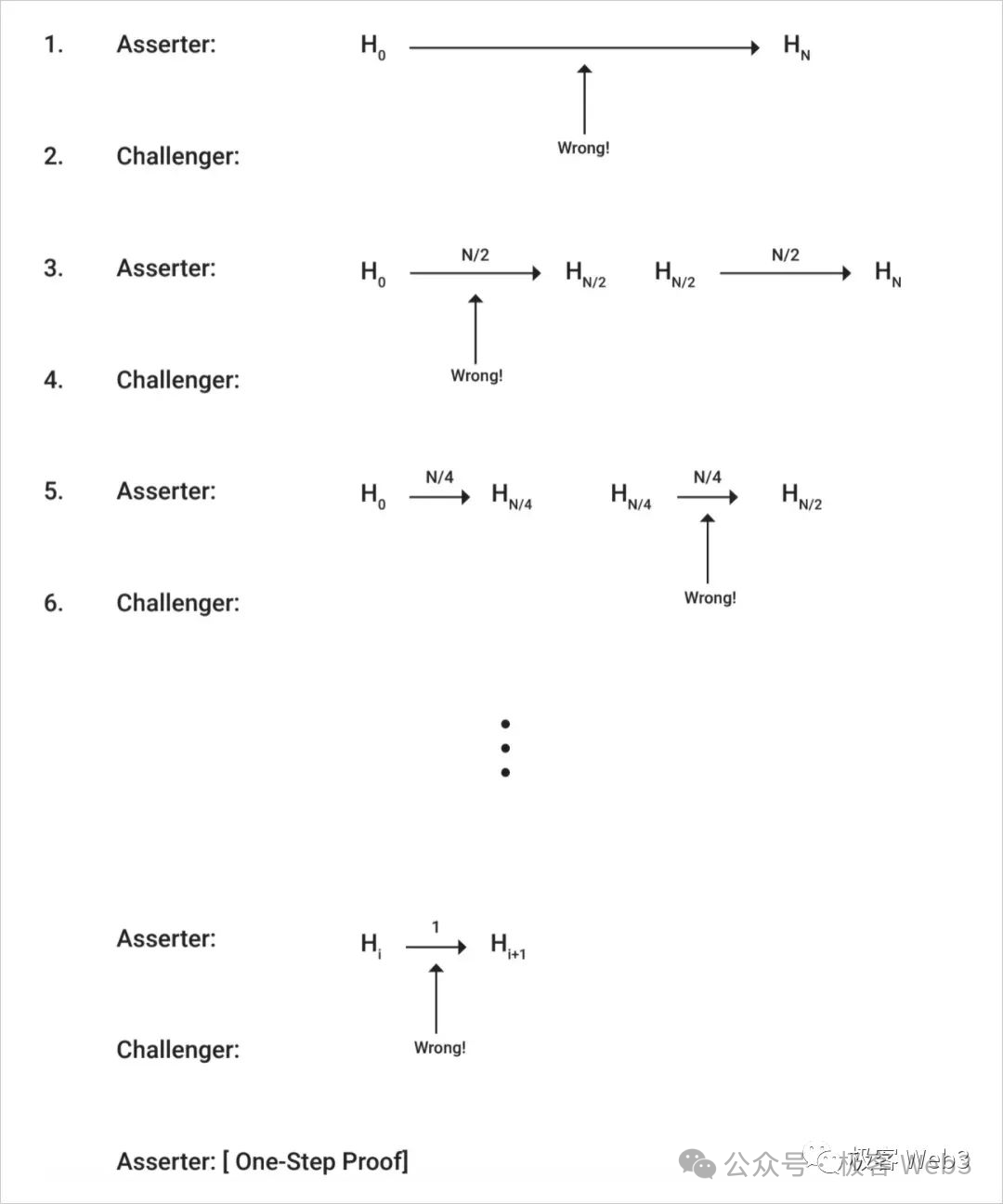
At this point, the concept of single-step fraud proof is easy to understand: the vast majority of transaction instructions that occur in Layer2 do not need to be re-verified on the BTC chain. However, when a certain disputed data fragment/opcode is challenged, it needs to be replayed on Layer1.
If the conclusion of the detection is: the data previously published by the Proposer is problematic, then the assets staked by the Proposer will be slashed; if the Challenger is at fault, then the assets staked by the Challenger will be slashed. If the Prover does not respond to the challenge for a long time, they can also be slashed.
Arbitrum achieves the above effects through contracts on Ethereum, while BitVM needs to use Bitcoin Script to implement functions such as time locks and multi-signatures.
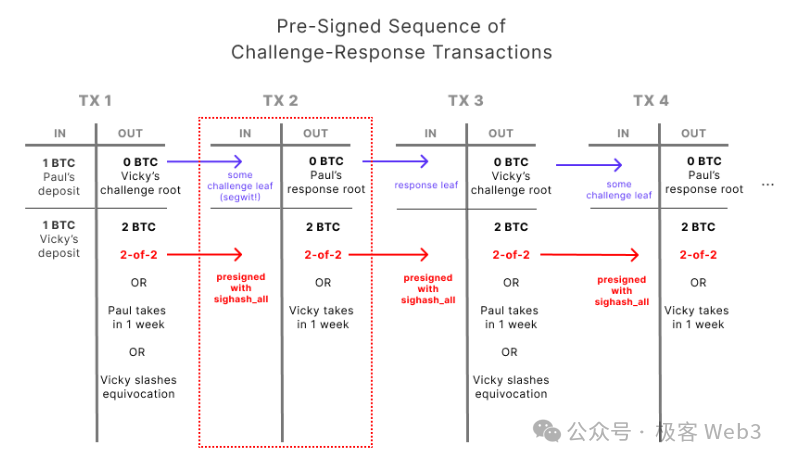
- After briefly explaining "interactive fraud proof" and "single-step fraud proof", we will discuss MAST tree and Merkle Proof.
As mentioned earlier, in the BitVM solution, a large amount of transaction data processed off-chain by Layer2 and the massive logic gate circuits involved are not directly put on chain, and only a minimal amount of data/logic gate circuits are put on chain when necessary.
However, we need a way to prove that the data that needs to be put on chain from off-chain is not fabricated on the spot, and this is what is commonly referred to as Commitment in cryptography. Merkle Proof is a type of Commitment.
First, let's talk about MAST tree. MAST, short for Merkelized Abstract Syntax Trees, is the transformation of the AST tree involved in compiler theory into the form of a Merkle Tree.
So, what is an AST tree? Its Chinese name is "abstract syntax tree". Simply put, it is a data structure that breaks down a complex instruction into a set of basic operation units through lexical analysis and organizes them into a tree structure.
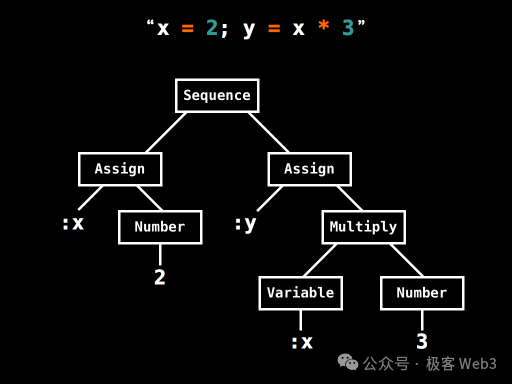 (A simple example of an AST tree, this AST tree breaks down simple operations like x=2, y=x*3 into low-level opcodes + data)
(A simple example of an AST tree, this AST tree breaks down simple operations like x=2, y=x*3 into low-level opcodes + data)
The MAST tree is the Merkle-ization of the AST tree to support Merkle Proof. A benefit of the Merkle tree is that it can achieve efficient "data compression". For example, if you want to publish a segment of data from the Merkle tree on the BTC chain when necessary, but also want to ensure that the outside world believes that this data segment does indeed exist on the Merkle tree and is not something you "pulled out of thin air", what do you do?
You just need to record the Root of the Merkle tree in advance on the chain, and in the future, present the Merkle Proof to prove that a certain data segment exists on the Merkle tree corresponding to the Root.
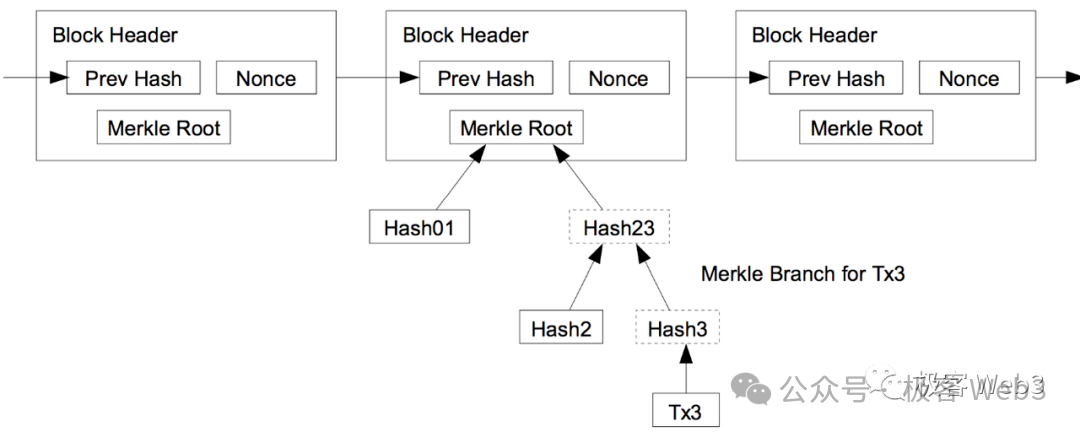
Therefore, it is not necessary to store the complete MAST tree on the BTC chain, only the Root needs to be disclosed in advance to serve as the Commitment, and when necessary, present the data segment + Merkle Proof/Branch. This can greatly compress the amount of on-chain data and ensure that the on-chain data truly exists on the MAST tree. Additionally, by only publicly disclosing a small portion of the data segment + Merkle Proof on the BTC chain, rather than all the data, it can provide good privacy protection.
Reference: Data withholding and fraud proof: Reasons why Plasma does not support smart contracts
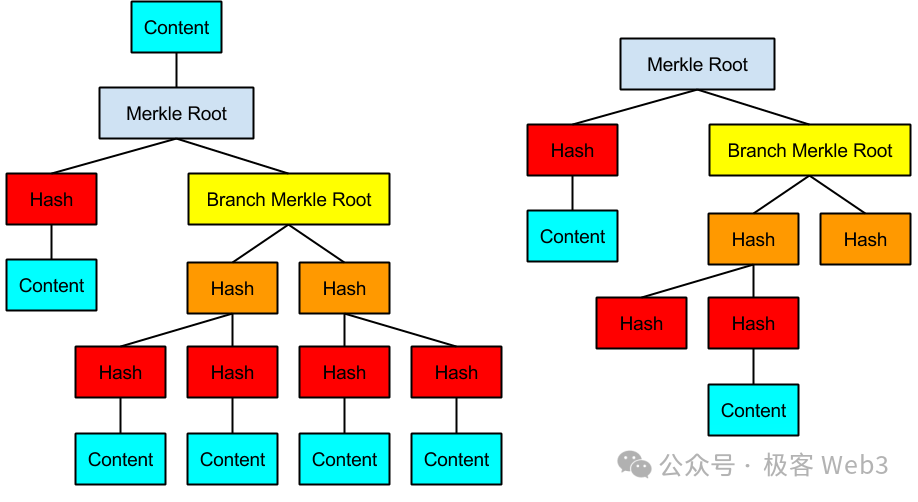
In BitVM's solution, an attempt is made to express all logic gate circuits using Bitcoin script, then organize them into a massive MAST tree, where the bottommost leaves (Content in the image) correspond to the logic gate circuits implemented using Bitcoin script.
The Proposer of Layer2 will frequently publish the root of the MAST tree on the BTC chain. Each MAST tree is associated with a transaction involving all its input parameters/operation codes/logic gate circuits. To some extent, this is similar to the Proposer of Arbitrum publishing a Rollup Block on the Ethereum chain.
When a dispute occurs, the Challenger declares on the BTC chain which Root they want to challenge, and then requests the Proposer to reveal a certain segment of data corresponding to the Root. Subsequently, the Proposer presents the Merkle Proof, repeatedly disclosing a small portion of the MAST tree's data segment on the chain until the Challenger and the Proposer jointly identify the disputed logic gate circuit. Then the Slash can be executed.
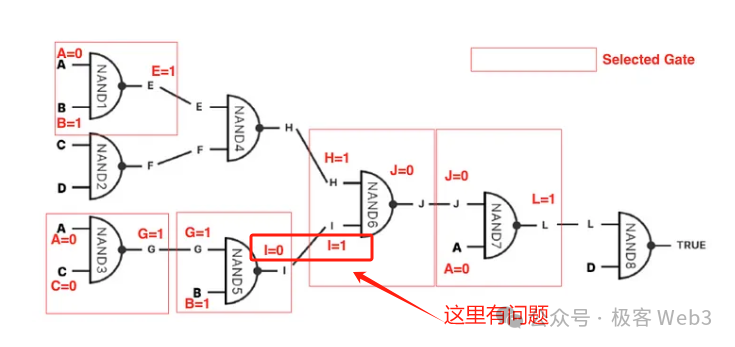
- At this point, the most important part of BitVM's entire solution has been explained. Although some details are still a bit obscure, I believe readers can grasp the essence and main points of BitVM. As for the "bit value commitment" mentioned in its white paper, it is to prevent the Proposer from giving the input values of a logic gate "both assigned 0 and 1" when challenged and forced to verify the logic gate circuit on the chain.
In summary, BitVM's solution first expresses logic gate circuits using Bitcoin script, then uses logic gate circuits to express the operation codes of EVM/other VMs, then uses the operation codes to express the processing flow of any transaction instruction, and finally organizes them into a Merkle tree/MAST tree.
For such a tree, if it expresses a very complex transaction processing flow, it is very easy to exceed 100 million leaves, so efforts should be made to minimize the block space occupied by Commitment and the scope of fraud proof.
Although single-step fraud proof only requires a very small segment of data and logic gate scripts on chain, the complete Merkle Tree needs to be stored off-chain for a long time, so that the data on the tree can be put on chain at any time when challenged.
Every transaction in Layer2 will generate a large Merkle Tree, and the computational and storage pressure on the nodes can be imagined. Most people may not be willing to run nodes (but this historical data can be expired and eliminated, and the B^2 network specifically introduces zk storage proofs similar to Filecoin to incentivize storage nodes to store historical data for a long time).
However, optimistic Rollup based on fraud proof does not need to have too many nodes, because its trust model is 1/N, as long as there is 1 honest node among N, it can initiate fraud proof at critical moments, and the Layer2 network is secure.
However, there are still many challenges in the design of Layer2 solutions based on BitVM, such as:
1) Theoretically, in order to further compress data, it is not necessary to directly verify the operation codes on Layer1, and the processing flow of the operation codes can be further compressed into zk proof, allowing challengers to challenge the verification steps of zk proof. This can greatly compress the amount of on-chain data. However, the specific development details will be very complex.
2) Proposers and Challengers need to repeatedly interact off-chain, how should the protocol be designed, and how to further optimize the Commitment and challenge process in the processing flow will require a lot of brainpower.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







