Source: AIGC Open Community

Image Source: Generated by Wujie AI
With the emergence of products such as Midjourney and Stable Difusion, the field of natural image generation has made great breakthroughs. However, it is quite difficult to generate/embed precise text in images.
It often results in blurry, inexplicable, or incorrect text, especially with very poor support for Chinese. For example, generating an image with a spring couplet that reads "2024 Year of the Dragon," even well-known natural image models find it difficult to generate accurately.

Generated by a well-known natural image model: The image is okay, but the prompt words cannot be understood to embed Chinese in the image
To address these challenges, researchers at Alibaba Group have open-sourced the multilingual visual text generation and editing model - AnyText.
According to the actual usage experience of "AIGC Open Community," AnyText's control over text generation can rival professional Photoshop. Users can customize the planned appearance of text, image intensity, strength, seed number, etc. It is currently very popular with over 2,400 stars on Github.

Generated by AnyText, perfectly understands Chinese prompt words, and allows customization of text appearance
It is worth mentioning that AnyText can seamlessly integrate with other open-source diffusion models in the form of plugins, comprehensively enhancing its ability to embed precise text in images.
Open source address: https://github.com/tyxsspa/AnyText
Paper address: https://arxiv.org/abs/2311.03054
Online demo: https://huggingface.co/spaces/modelscope/AnyText
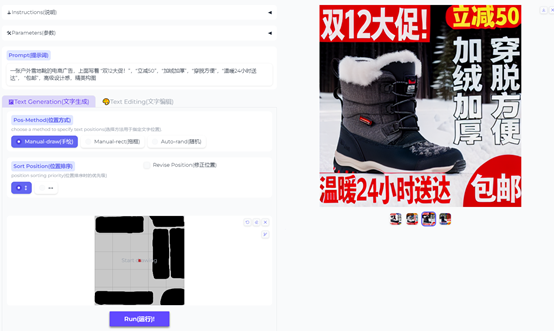
AnyText test interface, intuitive and simple operation, can manually adjust various parameters
AnyText supports multiple languages such as Chinese, Japanese, Korean, and English, and can provide high-precision, customized natural image services for personnel in e-commerce, advertising graphic design, film production, animation design, illustration, web design, UI design, digital marketing, and other fields.
AnyText Technology Architecture
Currently, open-source diffusion models perform poorly in embedding precise text in generated images, mainly due to three reasons:
1) Lack of large-scale image and text pairing datasets with comprehensive text content annotations. Existing large-scale image diffusion model training datasets, such as LAION-5B, lack manually annotated or OCR results of text content.
2) Many open-source diffusion models use text encoders, such as the CLIP text encoder, which use vocabulary-based tokenizers and cannot directly access character-level information, leading to reduced sensitivity to individual characters.
3) The loss functions of most diffusion models aim to improve the overall image generation quality, lacking specific supervision and optimization for text regions.
To address these challenges, Alibaba's researchers developed the AnyText model and the AnyWord-3M dataset. AnyText adopts a text-controlled diffusion process, including two important modules: auxiliary latent variables and text embedding.
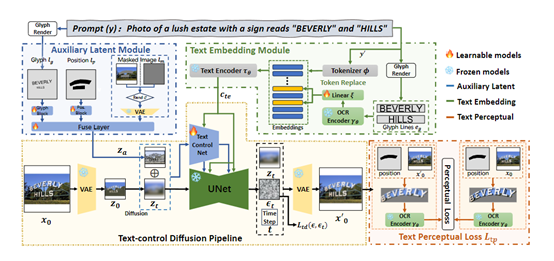
The auxiliary latent variable module is used to generate or edit the latent features of text, accepting inputs such as text shape, position, and mask images to generate latent features for text generation or editing.
These latent features play an auxiliary role in generating or editing text, helping to ensure the accuracy and consistency of the text.
The auxiliary latent variables enable AnyText to generate or edit text in curved or irregular regions in images. This means that even generating curved or irregular fonts is not a problem!

The text embedding module uses an OCR model to encode stroke data into embedding vectors, which are then fused with the image caption embedding vectors generated by the marker to seamlessly integrate text with the background.
To improve writing accuracy, the research team used text-controlled diffusion loss and text perception loss for training.
Improving Image Text Embedding Accuracy
To further improve the accuracy of generated text, AnyText uses text-controlled diffusion loss and text perception loss for training.
The text-controlled diffusion loss is used to control the accuracy of generated text in specified positions and styles. By comparing the differences between the generated text and the target text, it encourages the model to generate more accurate and consistent text.
The text perception loss further enhances the accuracy of generated text. By comparing the feature representations of generated text with the corresponding feature representations in the real image, it measures the visual accuracy of the generated text.
AnyWord-3M Dataset
This dataset is an important part of enhancing AnyText's text capabilities, containing a total of 3 million image-text pairs and providing OCR (optical character recognition) annotations in multiple languages.
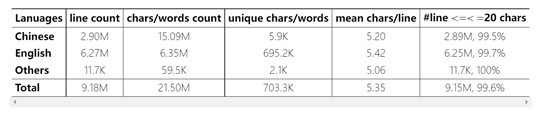
AnyWord-3M contains over 9 million text lines, with a total of over 200 million characters and vocabulary. The text covers languages such as Chinese, English, Japanese, and Korean. This is currently the largest publicly available and the first multilingual dataset specifically designed for text generation tasks.

Main datasets included: The Chinese part of the Wukong dataset, a multimodal dataset with billions of Chinese data constructed by Bilibili's laboratory. AnyWord-3M selected approximately 1.54 million images from it.
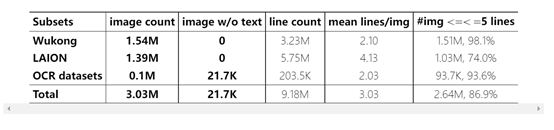
The English part of the LAION dataset, a large-scale English image-text matching dataset constructed by Stanford University, among others. AnyWord-3M selected approximately 1.4 million images from it.
Multiple OCR recognition datasets, including standard datasets in text localization and recognition fields such as ArT, COCO-Text, RCTW, providing approximately 100,000 annotated text images.
After obtaining these source data, the AnyText research team also designed strict filtering rules to filter the images and text lines, ensuring the quality of the training data.

The rules for filtering text lines are very detailed, such as a minimum text line height of 30 pixels, and a text recognition confidence exceeding 0.7.
Therefore, AnyWord-3M has absorbed the essence of multiple datasets, making it one of the important reasons for AnyText's strong capabilities.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







