Source: AIGC Open Community

Image Source: Generated by Wujie AI
On December 13th, Microsoft officially released Phi-2, a large language model with 2.7 billion parameters on its official website.
Phi-2 is developed based on Microsoft's Phi-1.5 and is capable of generating text/code, summarizing text, mathematical reasoning, and other functions.
Although Phi-2 has a small number of parameters, its performance surpasses that of Llama-2 with 13 billion parameters, Mistral with 7 billion parameters, and Google's latest release, Gemini Nano 2.
It is worth mentioning that Phi-2 is just a base model without human feedback reinforcement learning (RLHF) and instruction fine-tuning. However, in multiple task evaluations, its performance can match or even exceed models with 25 times more parameters.
Currently, Microsoft has open-sourced Phi-1.5 and Phi-1 to help developers deeply research and apply models with small parameters.
Phi-1.5 open source address: https://huggingface.co/microsoft/phi-1_5
Phi-1 open source address: https://huggingface.co/microsoft/phi-1
Phi-1.5 paper address: https://arxiv.org/abs/2309.05463
Currently, there is a strange phenomenon in the large model field, where the model parameters are getting larger and larger. Models with several hundred billion parameters are considered entry-level, and there are numerous models with over a trillion parameters. Some models have even reached tens of trillions.
Models with high parameters are not necessarily bad, but it depends on the application scenario. For basic model service providers like Microsoft, OpenAI, Baidu, and iFlytek, higher parameters mean broader coverage. For example, ChatGPT has evolved to multimodal, capable of generating not only text but also images and understanding audio.
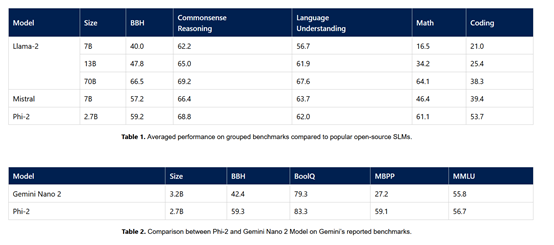
Phi-2 Evaluation Data
However, models with high parameters also have many drawbacks: overfitting; if the training data is poor, the model's performance may not improve and could even decline. High computational cost; each user query consumes a significant amount of resources. Long pre-training time; each model iteration requires a substantial amount of training time.
Difficult tuning; models with high parameters have a large and difficult-to-control number of neurons, making it challenging to perform partial function tuning and control. The recent lazy GPT-4 is a prime example.
Therefore, Microsoft's development of the Phi series models is primarily for research purposes, to explore how small parameter models can match or even surpass large parameter models while maintaining functionality, creating a win-win situation for enterprises and users.
Brief Introduction to Phi-2
Phi-2, like Phi-1.5, adopts a 24-layer Transformer architecture, with a dimension of 64 for each head, and utilizes techniques such as rotational embedding to enhance model performance.
Phi-2 is just a base model without human feedback reinforcement learning and instruction fine-tuning. However, in text generation, mathematical reasoning, and code programming, it is not inferior to models with high parameters and may even perform better than them.

In terms of training data and process, Phi-2 was pre-trained using 1.4T of high-quality "textbook-level" data, not random or black box data obtained from web crawling. Microsoft stated that this is one of the key reasons why models with small parameters outperform those with large parameters.
Phi-2 was trained for a total of 14 days on 96 A100 GPUs.
Phi-2 Experimental Data
Microsoft tested Phi-2 on mainstream platforms such as MMLU, BBH, PIQA, WinoGrande, ARC easy, Challenge, SIQA, and GSM8k.
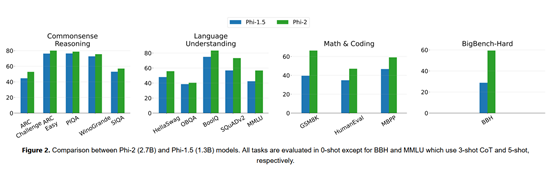
The data shows that Phi-2 outperforms Mistral -7B and Llama-2-13B on various aggregate benchmarks.
It is worth mentioning that in multi-step reasoning test tasks, such as encoding and mathematics, Phi-2's performance exceeds that of the 70-billion-parameter Llama-2.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








