Original source: Synced

Image source: Generated by Wujie AI
GPT has become more user-friendly, but has it really become smarter?
Yesterday, many people stayed up all night - the global tech community focused its attention on San Francisco, USA.
In just 45 minutes, OpenAI CEO Sam Altman introduced us to the most powerful large model to date and a series of applications based on it, which seemed as impressive as ChatGPT was at the beginning.

OpenAI launched GPT-4 Turbo at its first developer day on Monday. The new large model is smarter, has a higher text processing limit, and is also cheaper, with an app store now open. Users can now build their own GPT according to their needs.
According to the official statement, this wave of GPT upgrades includes:
- Longer context length: 128k, equivalent to 300 pages of text.
- Higher intelligence, better JSON/function calls.
- Higher speed: double the tokens per minute.
- Knowledge update: current deadline is April 2023.
- Customization: GPT3 16k, GPT4 fine-tuning, custom model service.
- Multi-modal: Dall-E 3, GPT4-V, and TTS models are now available in the API.
- Whisper V3 open source (API coming soon).
- Agent store sharing revenue with developers.
- GPT4 Turbo is priced at about 1/3 of GPT4.
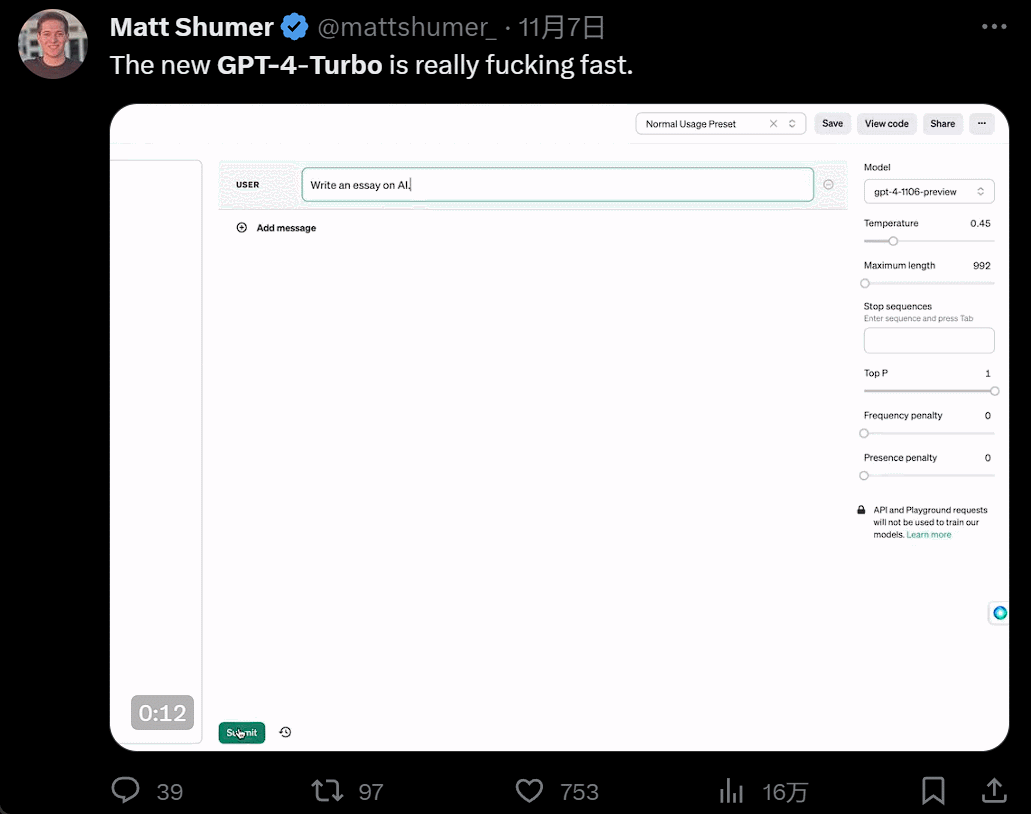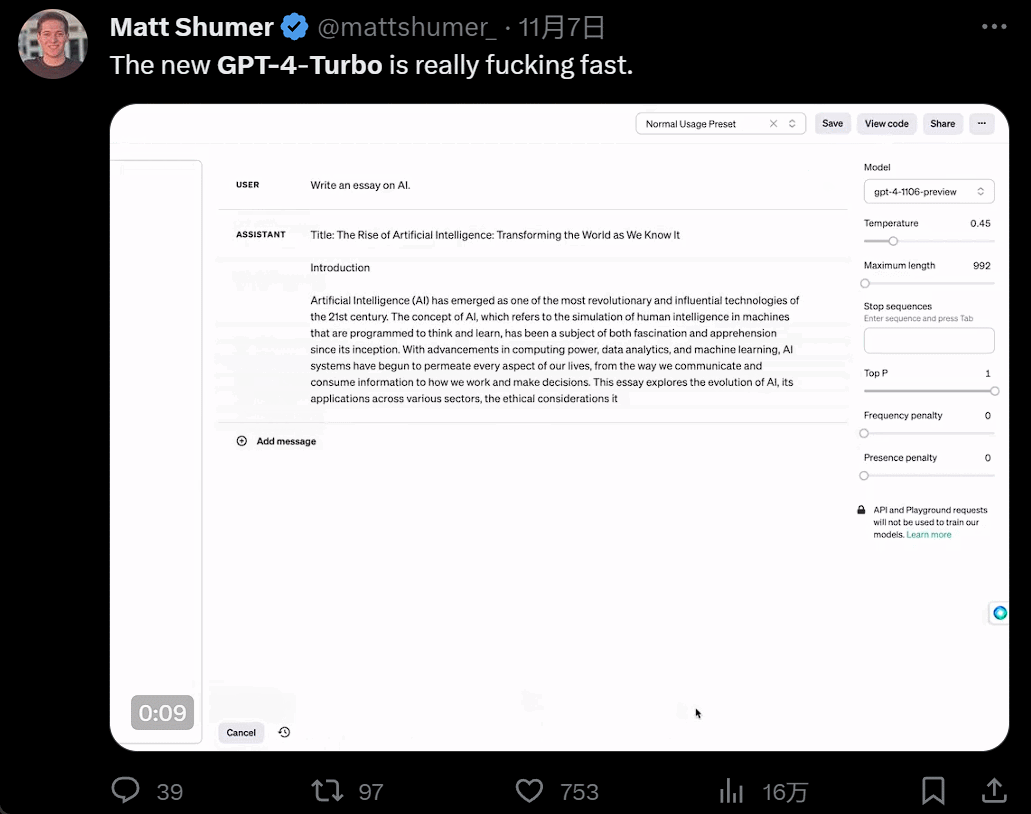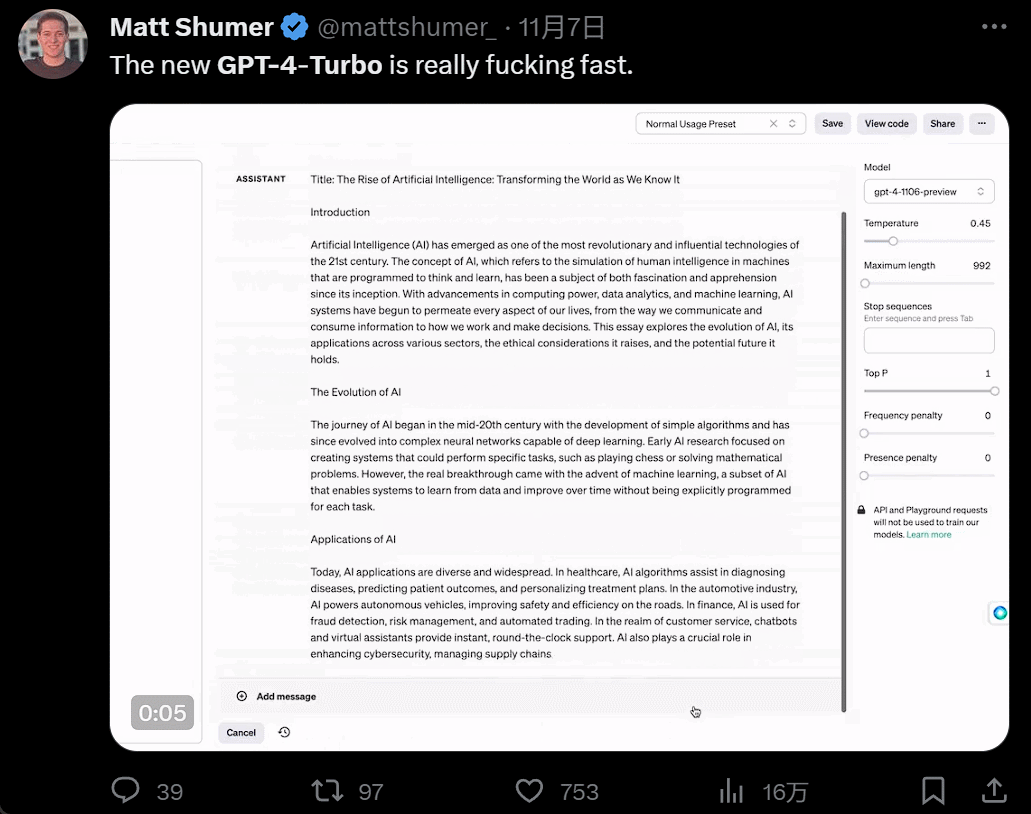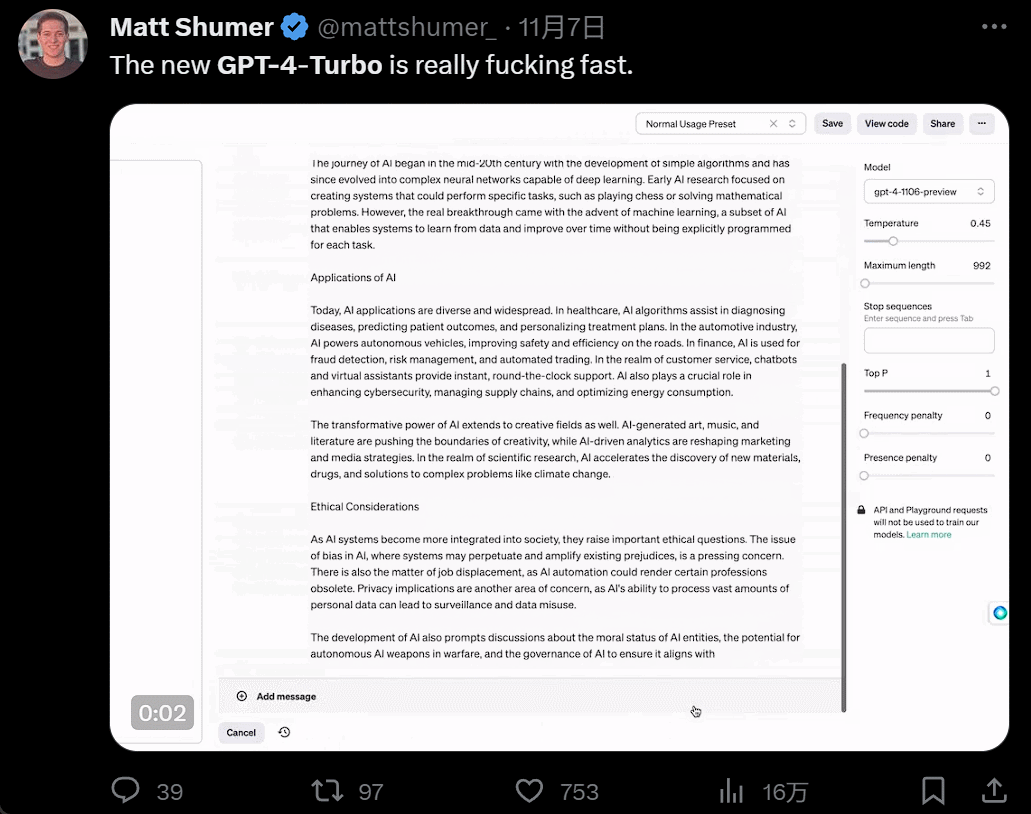
As soon as the conference ended, people flocked in to try it out. The experience with GPT4 Turbo was indeed extraordinary. First, it's fast, so fast that it outperforms all previous large models:
Then there are more features. When drawing, you can simply speak to let AI implement your inspiration:
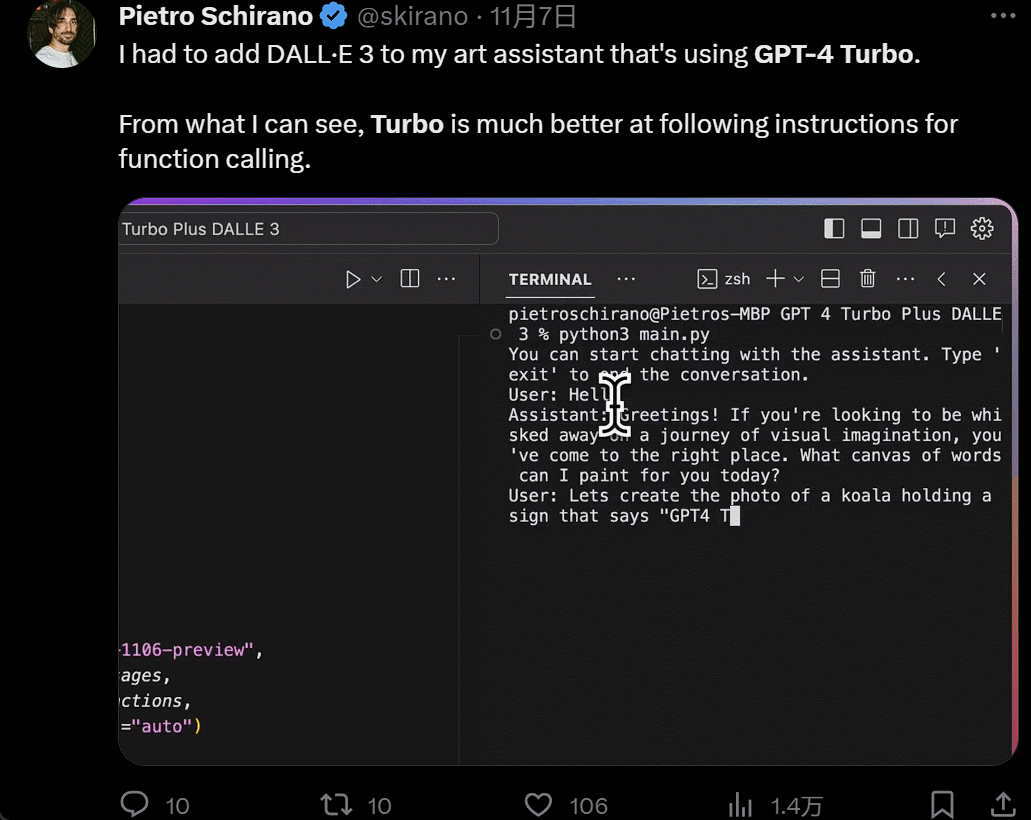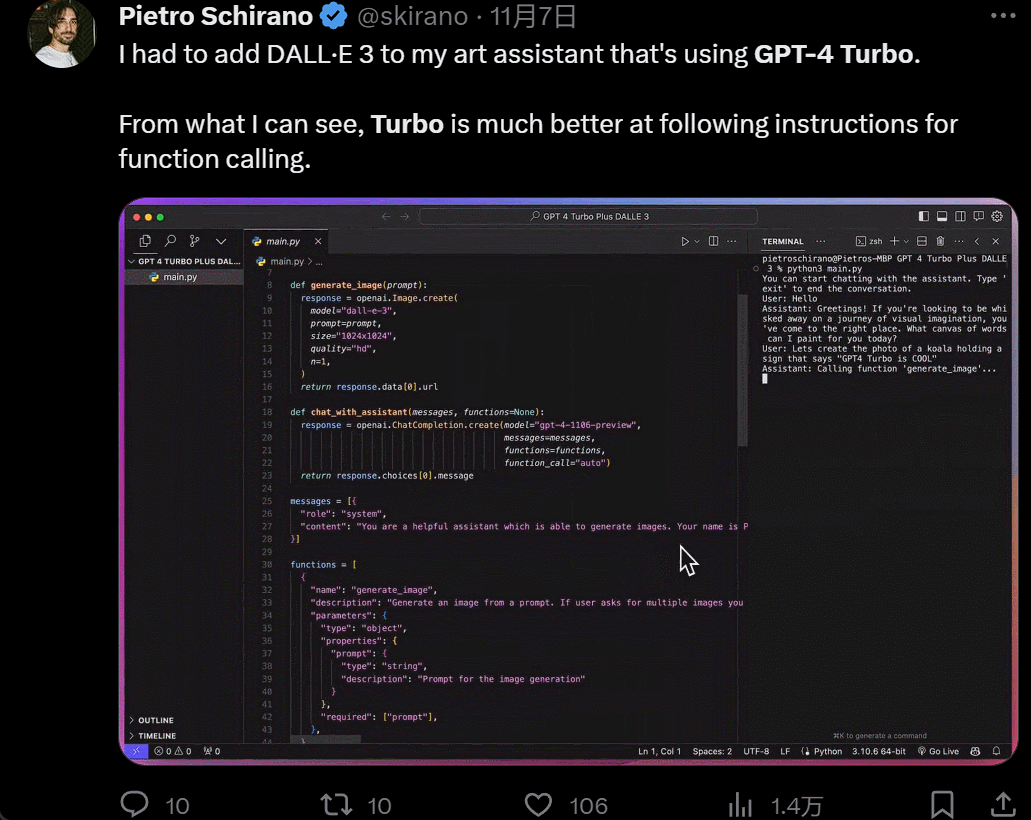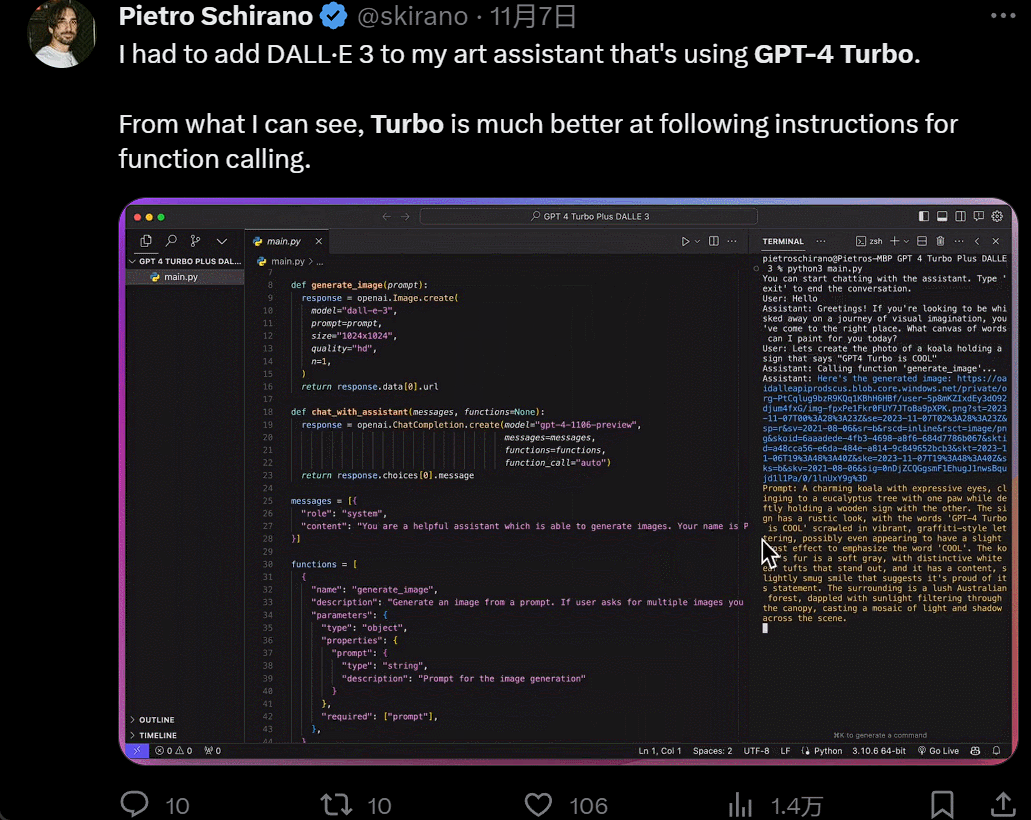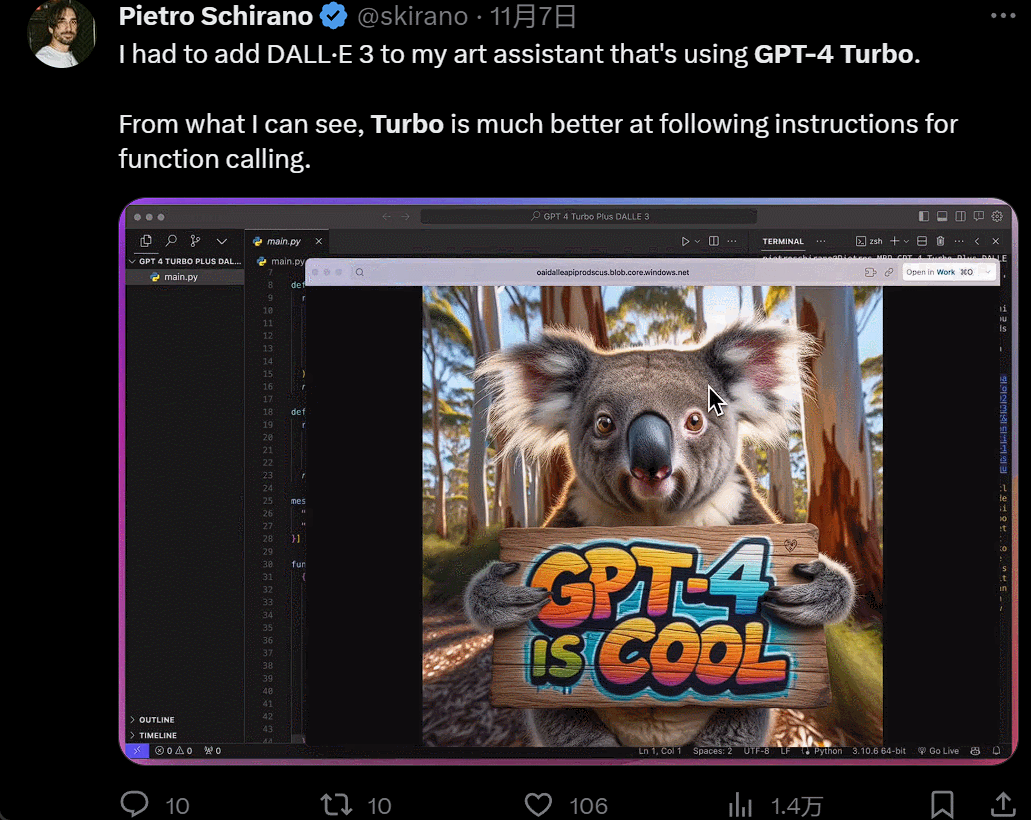
Designing a UI, which used to take hours, now only takes minutes:
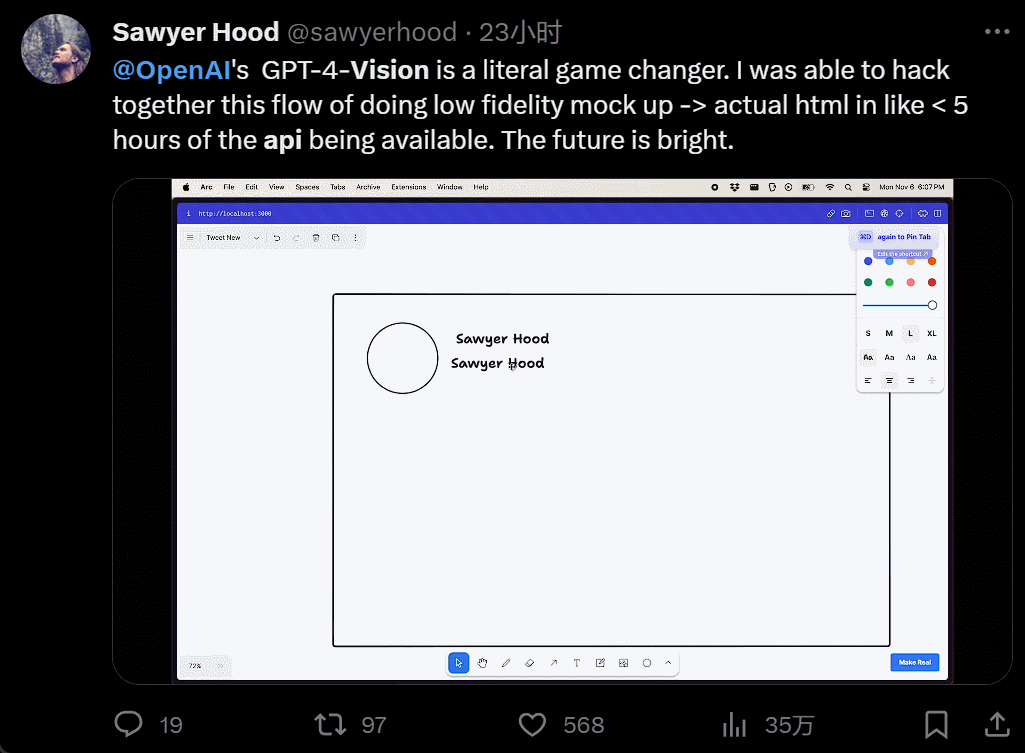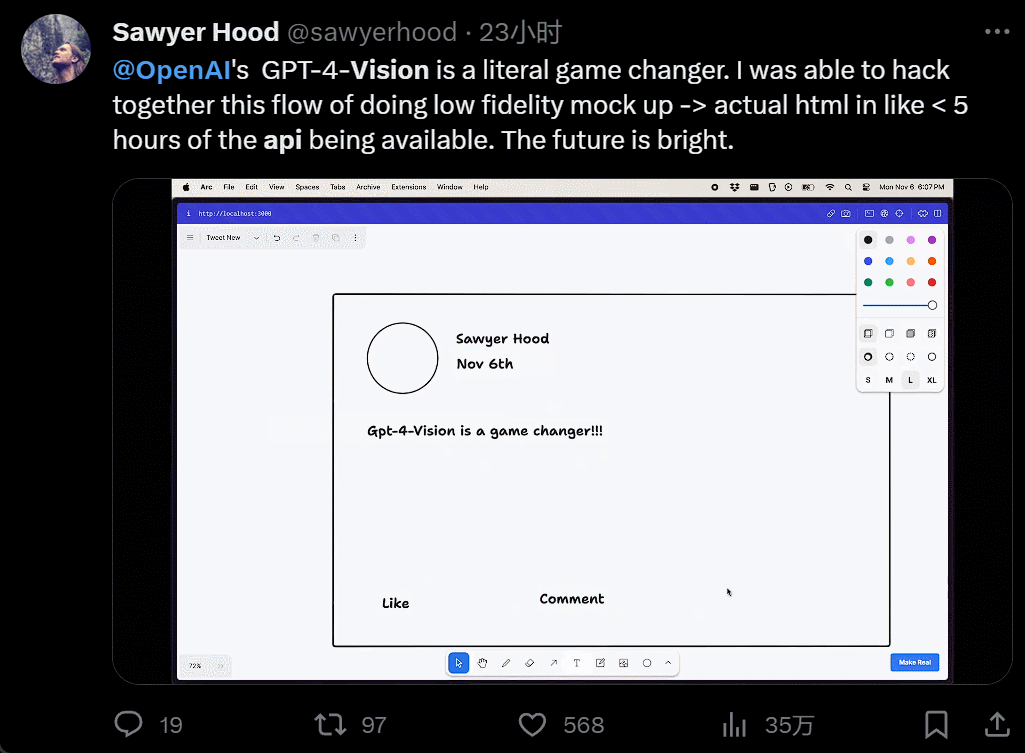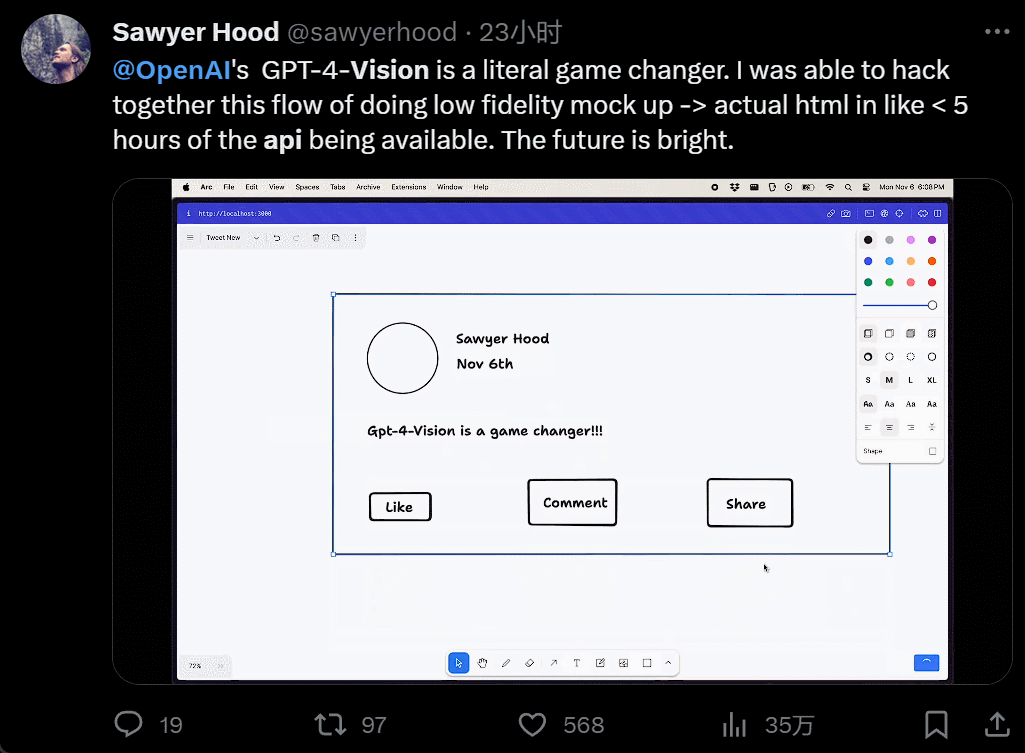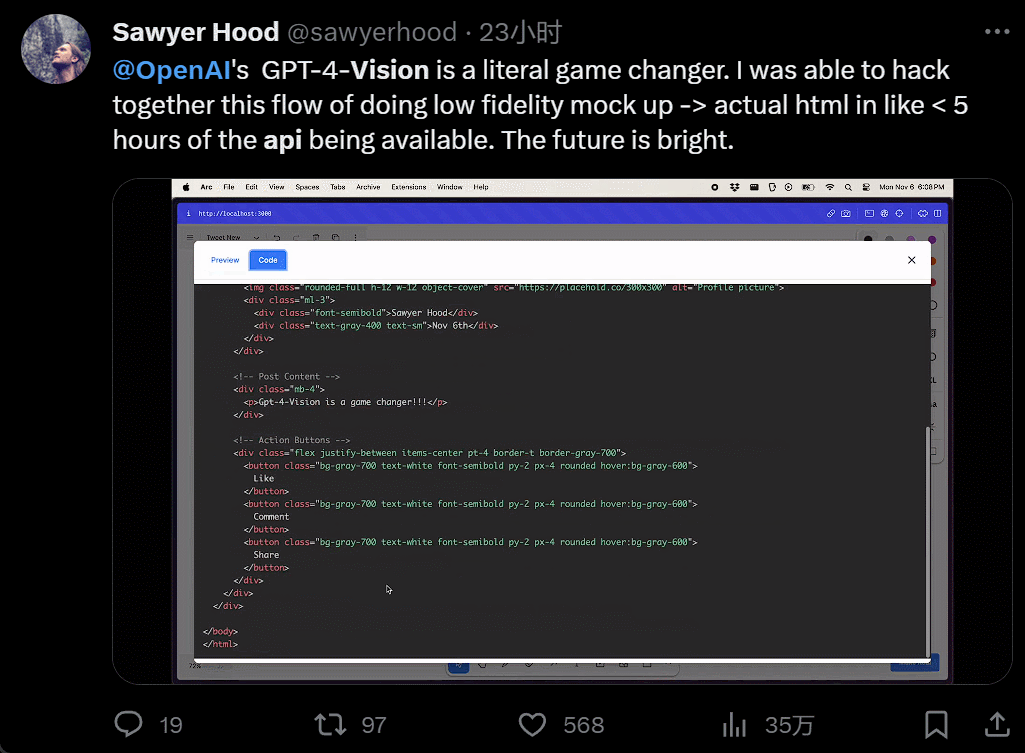
I won't even bother to install it. I'll just take a screenshot, copy and paste someone else's website, and generate my own in just 40 seconds:
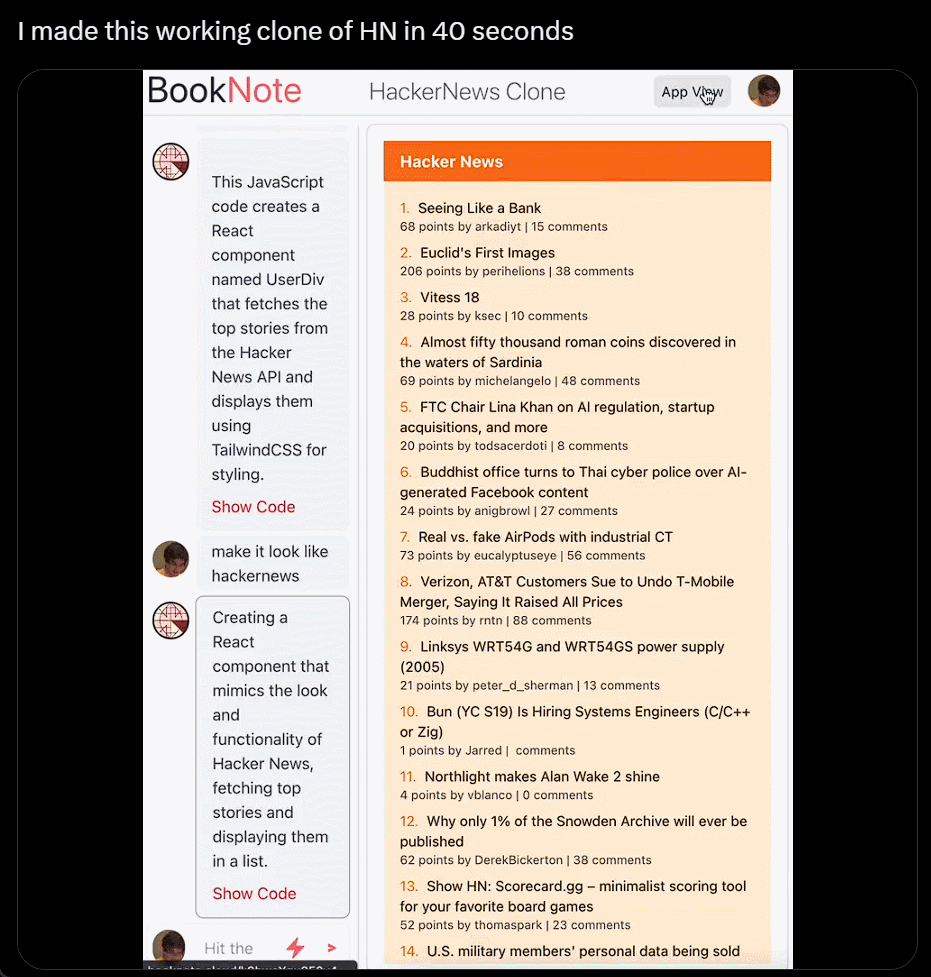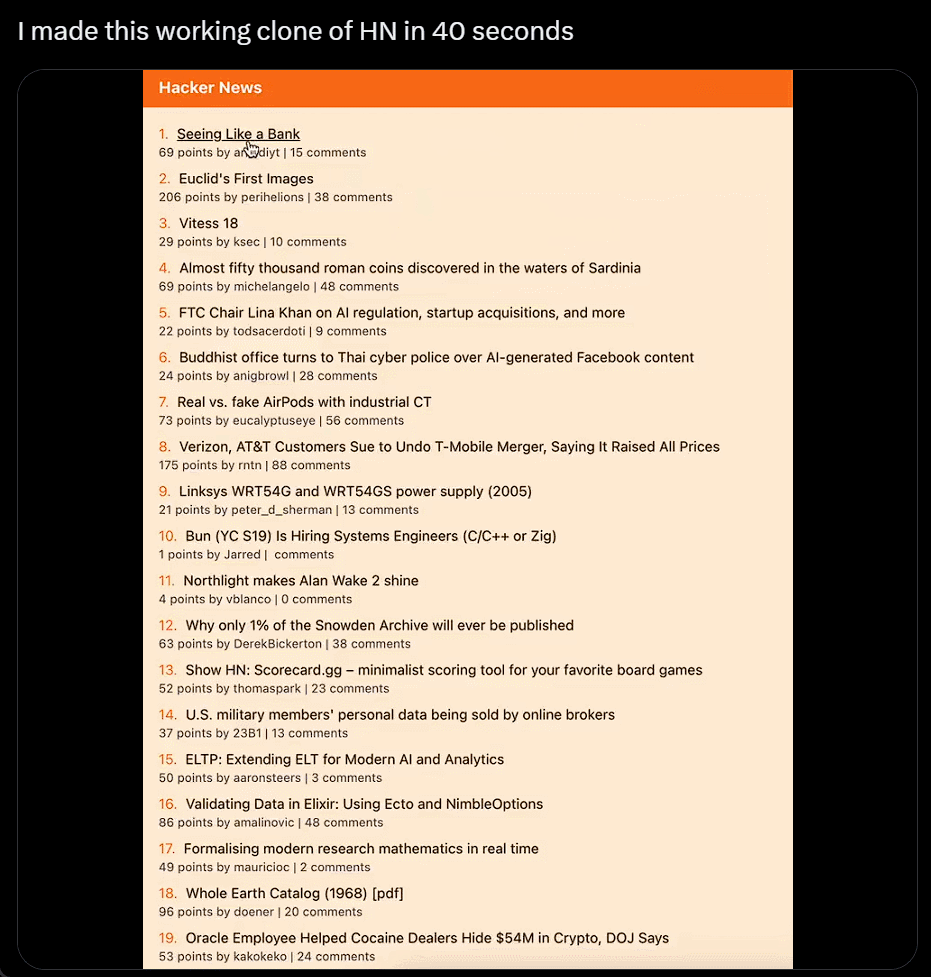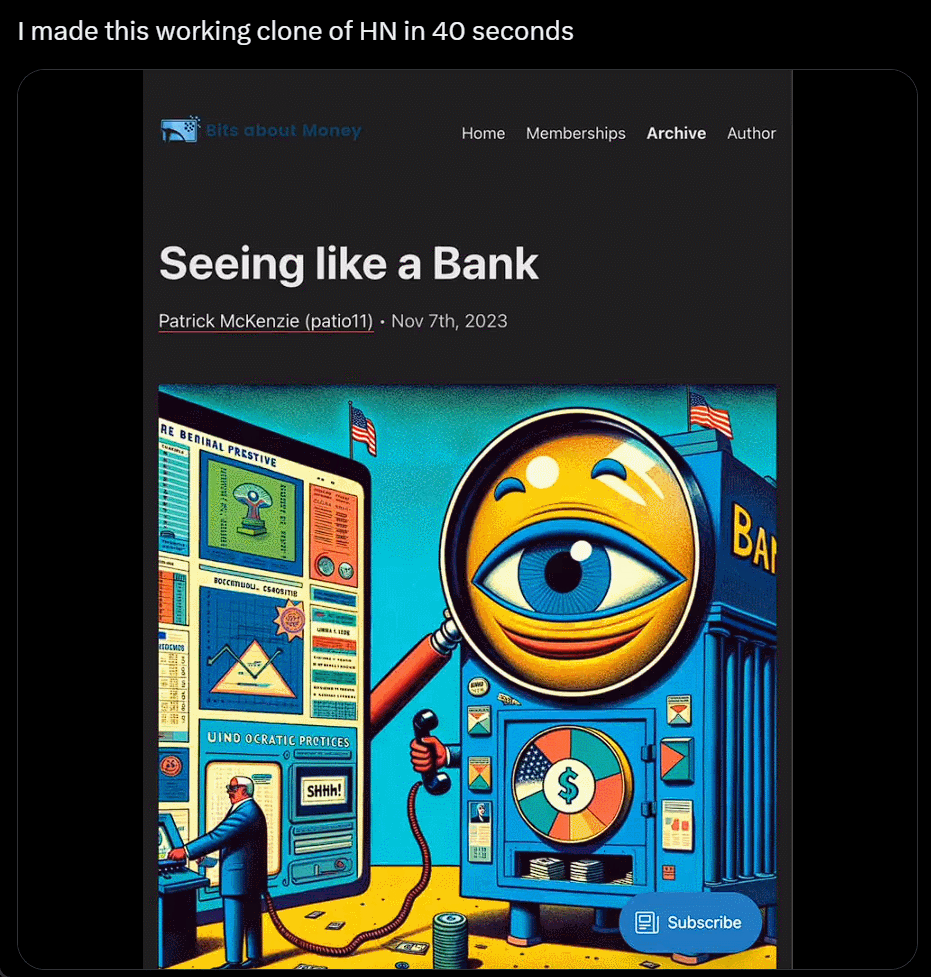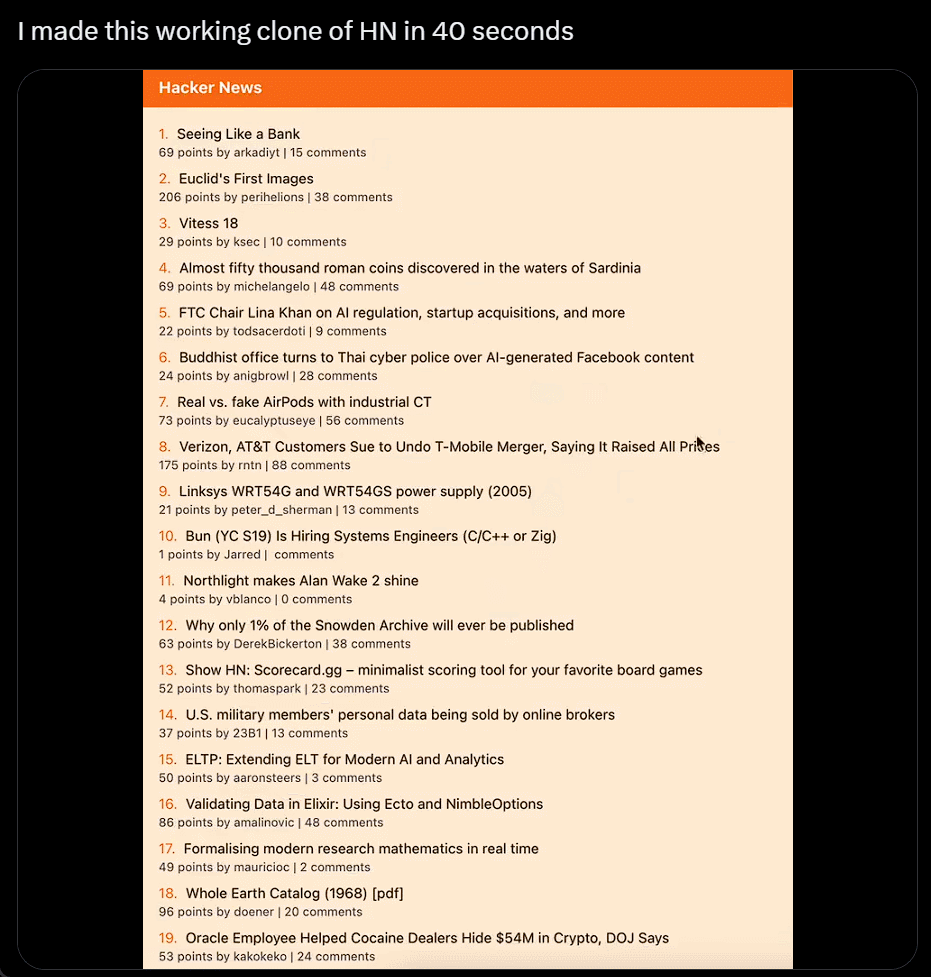
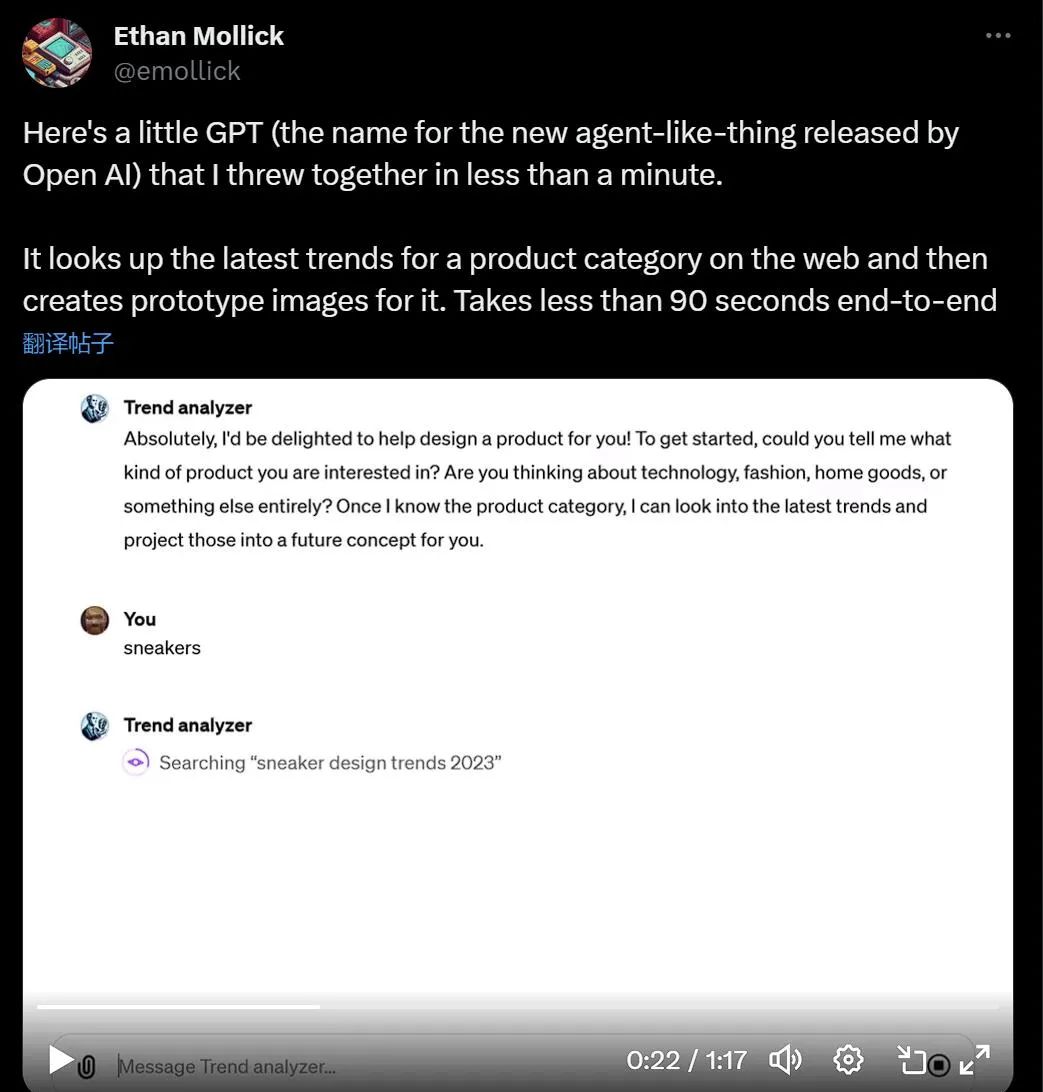
Using ChatGPT's browsing feature with Bing and integration with the DALL-E 3 image generator, Wharton School professor Ethan Mollick shared a video demonstrating his GPT tool called "Trend Analyzer," which can search for trends in specific market segments and then create prototype images for new products.
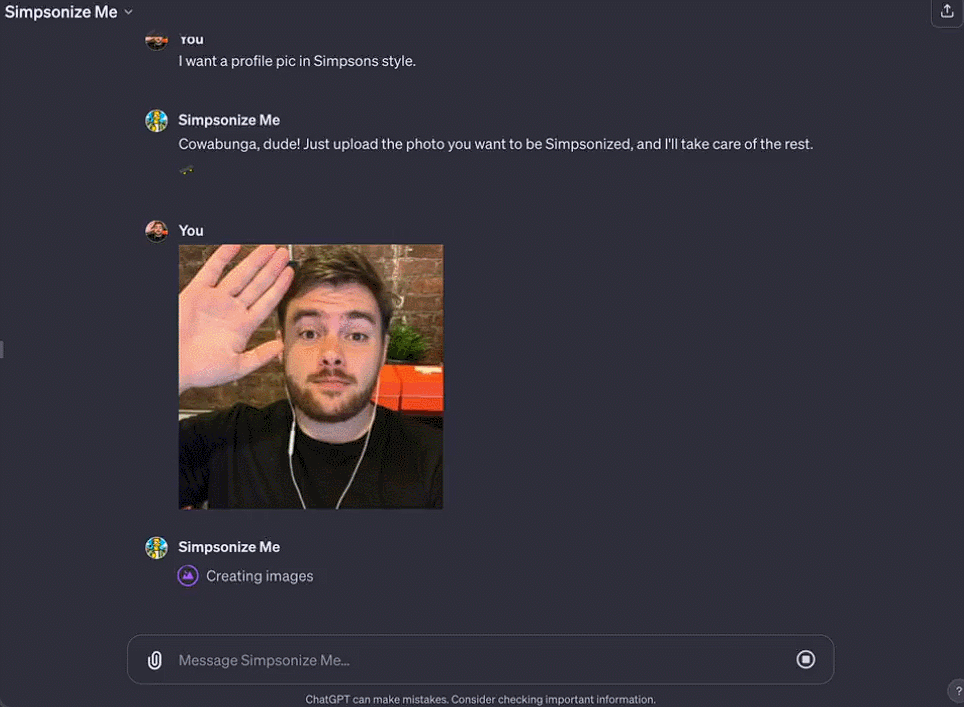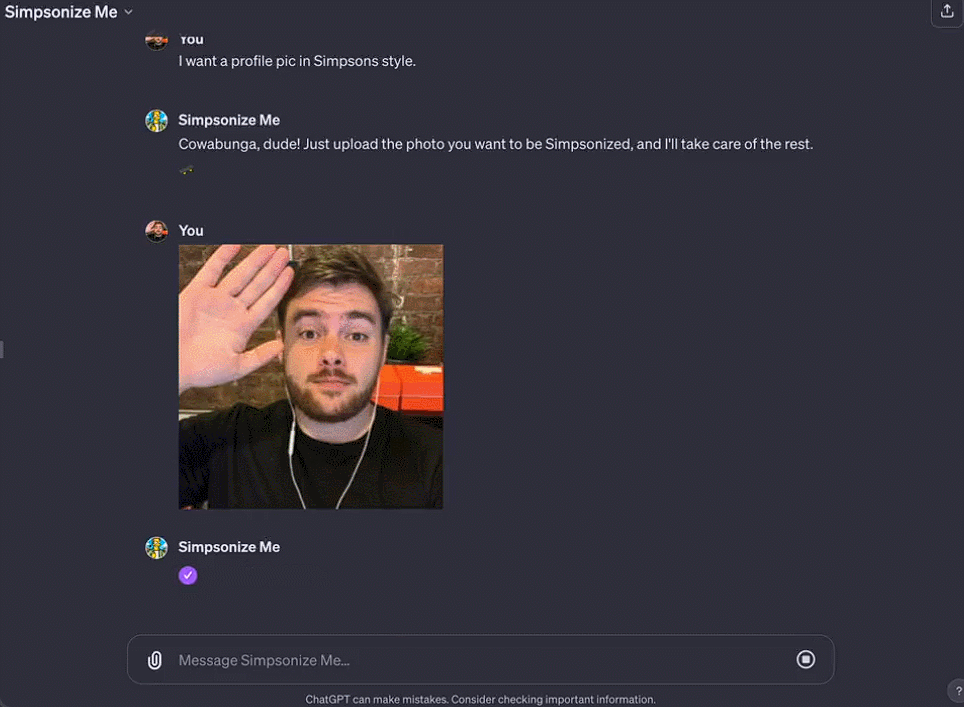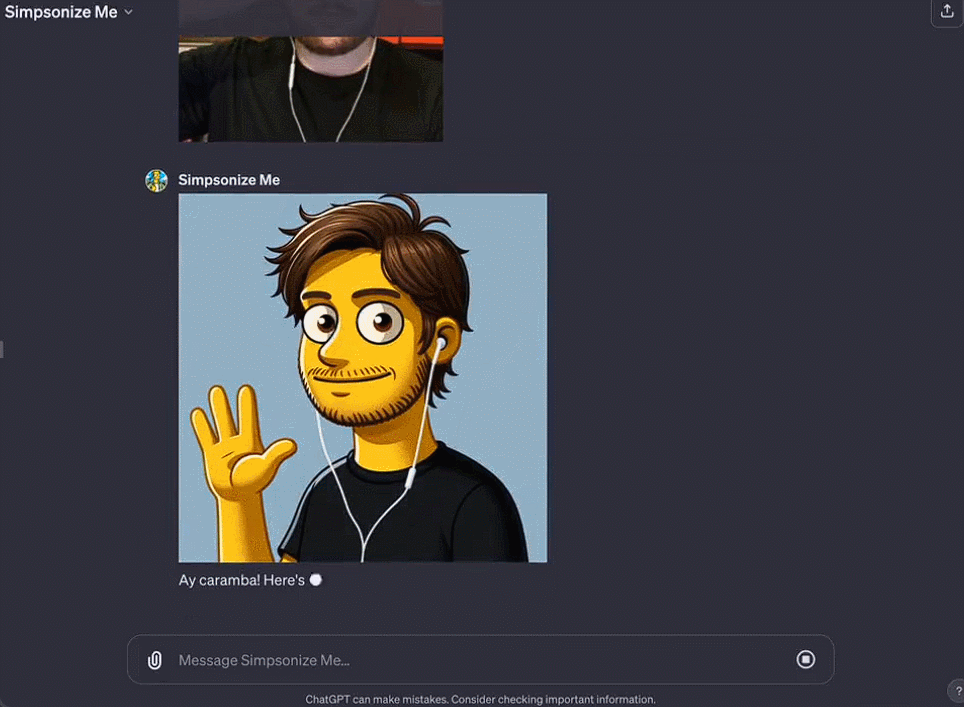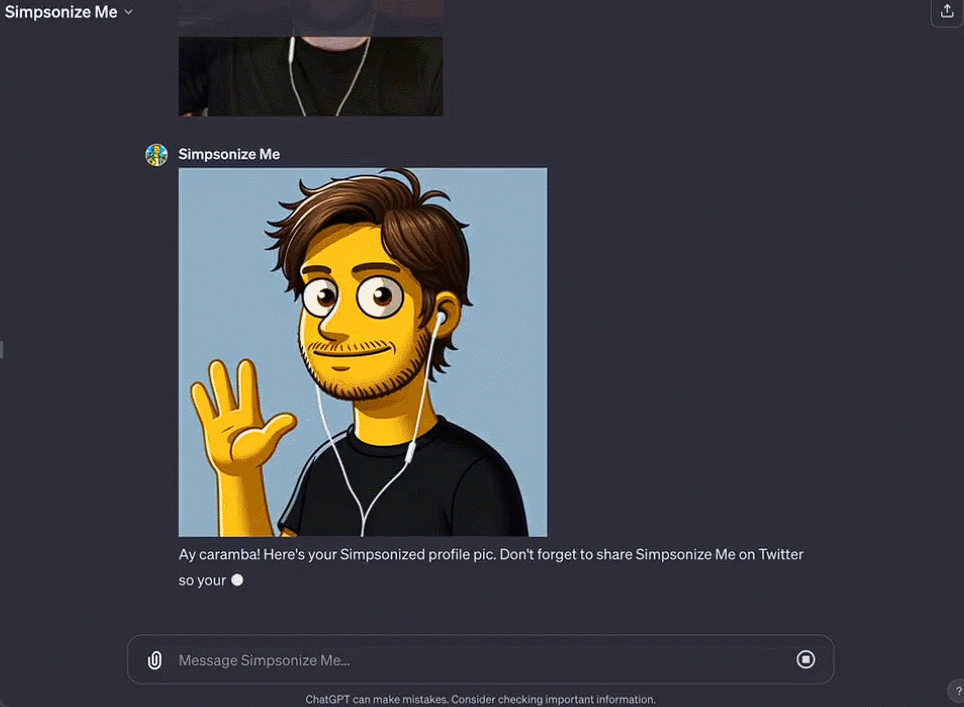
Octane AI CEO Matt Schlicht's Simponize Me GPT automatically applies prompts to transform users' uploaded profile photos into the style of "The Simpsons," taking less than ten minutes to create this small app.
GPT-4 Turbo has a record-breaking accuracy. On the PyLLM benchmark, GPT-4 Turbo achieved an accuracy of 87%, while GPT-4 achieved 52%, all while being almost four times faster (48 tokens per second).
With this, it seems that the competition in generative AI has entered a new stage. Many believe that while competitors are still pursuing faster and more capable large models, OpenAI has already tried every direction, and this wave of updates will put a large number of startups out of business.

Some also say that since Agent is an important direction for large models, OpenAI has also opened an Agent app store, and in the field of intelligent agents, we will have many opportunities ahead.
Do competitors really have no way out? After lowering prices and increasing speed, can the performance of large models still improve? This must be seen in practice. In OpenAI's blog, the statement is actually like this: in some output formats, GPT-4 Turbo will produce better results than GPT-4. So, what will the overall situation be like?
Within 24 hours of the release of the new model, researchers conducted tests on the AI's ability to generate code on Aider.
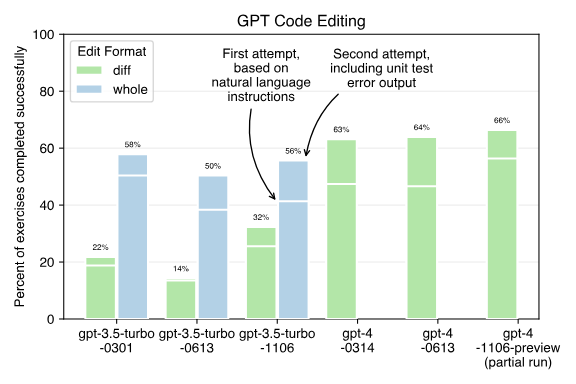
On the gpt-4-1106-preview model, conclusions drawn from benchmark testing using the diff editing method on the GPT-4 model are:
- The new gpt-4-1106-preview model seems much faster than the earlier GPT-4 model;
- It seems to be better at generating correct code on the first attempt, correctly completing about 57% of the exercises, compared to the previous model's 46-47% completion rate on the first attempt;
- After having the opportunity to correct errors by checking the test suite's incorrect outputs, the new model's performance (~66%) seems similar to the old model (63-64%).
Next is the benchmark testing of the GPT-3.5 model using the whole and diff editing formats. The results indicate that no gpt-3.5 model seems to effectively use the diff editing format, including the latest November model (referred to as 1106). Here are some whole editing format results:
- The new gpt-3.5-turbo-1106 model completes benchmark testing 3-4 times faster than the earlier GPT-3.5 model;
- The success rate after the first attempt is 42%, similar to the June (0613) model. Both the 1106 model and the 0613 model perform worse than the original 0301 model's first attempt result, which was 50%;
- The success rate of the new model after the second attempt is 56%, seemingly similar to the March model, but slightly better than the June model, which scored 50%.
How was this test conducted? Specifically, researchers had Aider attempt to complete 133 Exercism Python coding exercises. For each exercise, Exercism provided an initial Python file containing a natural language description of the problem to be solved and a test suite to evaluate whether the encoder correctly solved the problem.
The benchmark test was divided into two steps:
And then the above results were obtained. As for Aider, for those who are not familiar, we will briefly introduce it next.
Aider is a command-line tool that allows users to pair programs with GPT-3.5/GPT-4 to edit code stored in a local git repository. Users can start new projects or use existing repositories. Aider ensures that the content edited in GPT is submitted to git with reasonable commit messages. Aider's uniqueness lies in its ability to work well with existing larger codebases. In summary, with this tool, users can write and edit code using OpenAI's GPT, easily perform git commit, diff, and undo GPT-suggested changes without copy/pasting, and it also has the ability to help GPT-4 understand and modify larger codebases. To achieve the above functions, Aider needs to accurately identify when GPT wants to edit user source code, determine which files GPT wants to modify, and apply the changes made by GPT accurately. However, performing this "code editing" task is not simple and requires a powerful LLM, accurate prompts, and good tools for interacting with LLM. During the operation, when changes occur, Aider relies on a code editing benchmark to quantitatively evaluate the performance of the modifications. For example, when a user changes Aider's prompts or the backend driving LLM dialogue, benchmark testing can be run to determine how much improvement these changes produce. Additionally, someone also compared the SAT scores of GPT-4 Turbo with other models, and it seems that the level of intelligence does not show a significant difference, and there may even be a slight regression. However, it must be pointed out that the sample size of the experiment is very small. In conclusion, the most important aspect of the wave of updates for GPT-4 Turbo is the improvement of functionality and speed, while the question of whether accuracy has improved remains uncertain. This may be consistent with the current trend in the entire large model industry: emphasis on optimization and application orientation. Companies with slow business implementation need to be cautious. On the other hand, from the content released at this developer day, OpenAI seems to have shifted from a startup company that pursues cutting-edge technology to one that is beginning to focus on user experience and ecosystem building, resembling a large tech company. We'll have to wait a little longer for the GPT-5 that will once again disrupt the AI field. References: https://venturebeat.com/ai/what-can-you-make-with-openais-gpt-builder-5-early-examples/https://aider.chat/docs/benchmarks-1106.htmlhttps://weibo.com/2194035935/N8pSZCdxH
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








