Original Source: AIGC Open Community

Image Source: Generated by Wujie AI
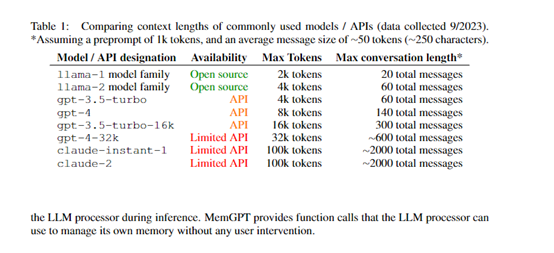
Currently, mainstream large language models such as ChatGPT, Llama 2, and Wenxin Yiyuan have been limited in contextual input due to technical architecture issues. Even Claude only supports a maximum of 100,000 token inputs, which is very inconvenient for interpreting reports, books, and papers that span hundreds of pages.
To address this issue, researchers at the University of California, Berkeley, inspired by the memory management mechanism of operating systems, have proposed MemGPT. The model's major innovation is to mimic the multi-level memory management mechanism of operating systems, breaking the fixed contextual constraints of large language models by transferring data between different memory levels.
Open Source: https://github.com/cpacker/MemGPT
Paper: https://arxiv.org/abs/2310.08560
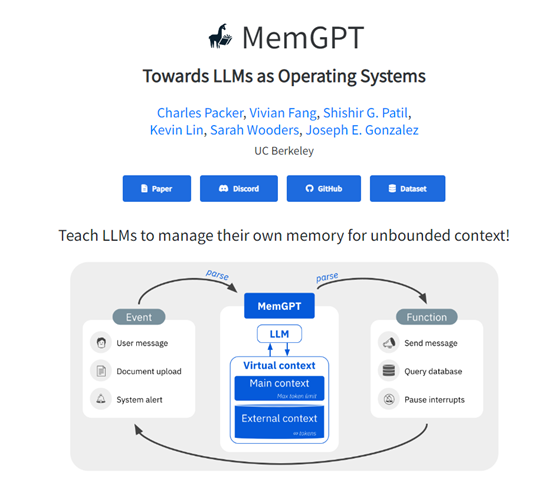
MemGPT mainly includes two major types of memory: main context and external context. The main context is equivalent to the main memory of an operating system, which is a fixed-length context window that a large language model can directly access.
The external context is equivalent to disk storage, which saves additional information beyond the main context. MemGPT also provides rich function calls, allowing large language models to autonomously manage their memory without human intervention.
These function calls can import and export information between the main context and the external context. Large language models can autonomously decide when to move context information to better utilize the limited main context resources based on the current task goal.
Researchers evaluated MemGPT in multiple test environments, and the results show that MemGPT can effectively handle text content with context lengths far exceeding the limits of large language models, such as handling documents with context limits far beyond GPT-3.5 and GPT-4.
As the number of retrieved documents increases, the performance of fixed-context models is limited by the quality of the retriever, while MemGPT can retrieve more documents through paging mechanisms, and its question-answering accuracy also improves.
In the newly proposed multi-step nested keyword extraction task, MemGPT successfully completed tasks that require multi-hop queries across documents by calling the external context multiple times, while the accuracy of GPT-3.5 and GPT-4 sharply drops to 0 as the nesting level increases.
Main Context
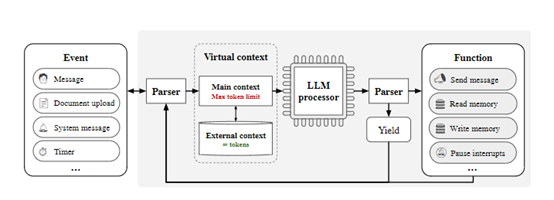
The main context in MemGPT is equivalent to the "main memory" in an operating system, which is a fixed-length context window that a large language model can directly access. Researchers divided the main context into three parts:
System Instructions: This part saves the basic control logic of MemGPT, such as the function call mode, with a fixed length and read-only.
Dialogue Context: This is a first-in, first-out queue that saves the recent user interaction history, is read-only, and will trim the front end of the conversation when the length exceeds the limit.
Work Context: This is a read-write temporary storage where a large language model can autonomously write information into through function calls.
It should be noted that the combined length of these three parts cannot exceed the maximum context length of the underlying large language model.
External Context
The external context saves additional information beyond the main context, equivalent to "disk storage" in an operating system. Explicit function calls are required to import information into the main context for model access, including the following two types:
Backtracking Storage: Saves complete historical event information, equivalent to an uncompressed version of the dialogue context.
Archival Storage: A general-purpose read-write database that can serve as overflow space for additional information in the main context. In dialogue applications, archival storage can save additional information about users or system roles, preferences, and more.
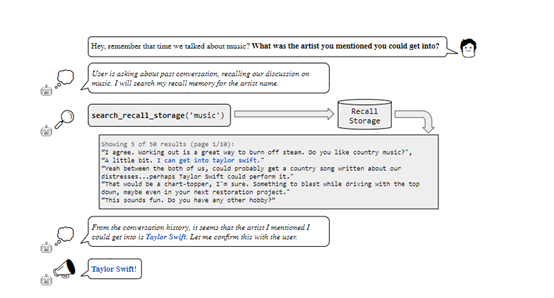
Backtracking storage allows retrieval of specific time periods of historical interactions. In document analysis, archival storage can support searching larger document sets.
Autonomous Editing and Retrieval
MemGPT achieves autonomous editing and retrieval by moving data between memory levels through function calls generated by large language models. For example, it can autonomously decide when to move information between contexts to adapt to the current task goal without human involvement.
The innovation lies in the detailed description of the memory system architecture and function call methods in the system instructions, guiding large language models to learn to use these tools to manage memory.
Large language models can adjust call strategies based on feedback. Additionally, when the main context space is insufficient, the system will remind the large language model to save important information in a timely manner, guiding it to manage memory.
Chained Calls
In MemGPT, various external events trigger large language models to perform inference, including user messages, system memory warnings, user interaction events, and more.
Function calls can request control, enabling chained calls. For example, when browsing search results in pages, consecutive calls can collect data from different pages into the main context.

Yield calls will pause the large language model until the next external event triggers the resumption of inference. This event-based control flow coordinates smooth communication between memory management, model inference, and user interaction.
Parser and Optimization
MemGPT uses a parser to validate function calls generated by large language models, checking if parameters are correct, and more. The results are then fed back to the model, allowing it to learn and adjust strategies to reduce errors.
Furthermore, the system instructions of MemGPT can be updated in real time to provide customized memory management guidance for different tasks, achieving continuous optimization.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








