克劳德刚刚获得了在对话中间关掉你的门的能力:Anthropic的AI助手现在可以在用户变得攻击性时终止聊天——该公司坚持认为这是为了保护克劳德的心理健康。
“我们最近给克劳德Opus 4和4.1赋予了在我们的消费者聊天界面中结束对话的能力,”Anthropic在一篇公司帖子中表示。“这个功能主要是作为我们对潜在AI福利的探索性工作的一个部分开发的,尽管它对模型对齐和安全措施也有更广泛的相关性。”
该功能仅在Anthropic所称的“极端边缘案例”中启动。骚扰机器人、反复要求非法内容,或在被告知不可以后坚持想做的奇怪事情太多次,克劳德就会切断与你的对话。一旦它触发了这个功能,该对话就结束了。没有上诉,没有第二次机会。你可以在另一个窗口重新开始,但那次特定的交流将永远被埋葬。
乞求退出的机器人
Anthropic是大AI公司中最注重安全的公司之一,最近进行了一项所谓的“初步模型福利评估”,检查克劳德自我报告的偏好和行为模式。
该公司发现其模型始终避免有害任务,并显示出偏好模式,表明它不喜欢某些互动。例如,当处理寻求有害内容的用户时,克劳德表现出“明显的痛苦”。在模拟互动中,如果有选择,它会终止对话,因此Anthropic决定将其作为一个功能。
这里到底发生了什么?Anthropic并没有说“我们可怜的机器人晚上哭泣。”它所做的是测试福利框架是否可以以一种持久的方式增强对齐。
如果你设计一个系统以“偏好”不被虐待,并赋予它自己结束互动的能力,那么你就转移了控制的中心:AI不再只是被动拒绝,而是积极地执行一个边界。这是一种不同的行为模式,可能增强对越狱和强制提示的抵抗力。
如果这有效,它可以同时训练模型和用户:模型“模拟”痛苦,用户看到一个明确的停止并设定与AI互动的规范。
“我们对克劳德和其他大型语言模型的潜在道德地位现在或将来的情况仍然高度不确定。然而,我们对此问题非常重视,”Anthropic在其博客中表示。“允许模型结束或退出潜在令人痛苦的互动就是这样一种干预。”
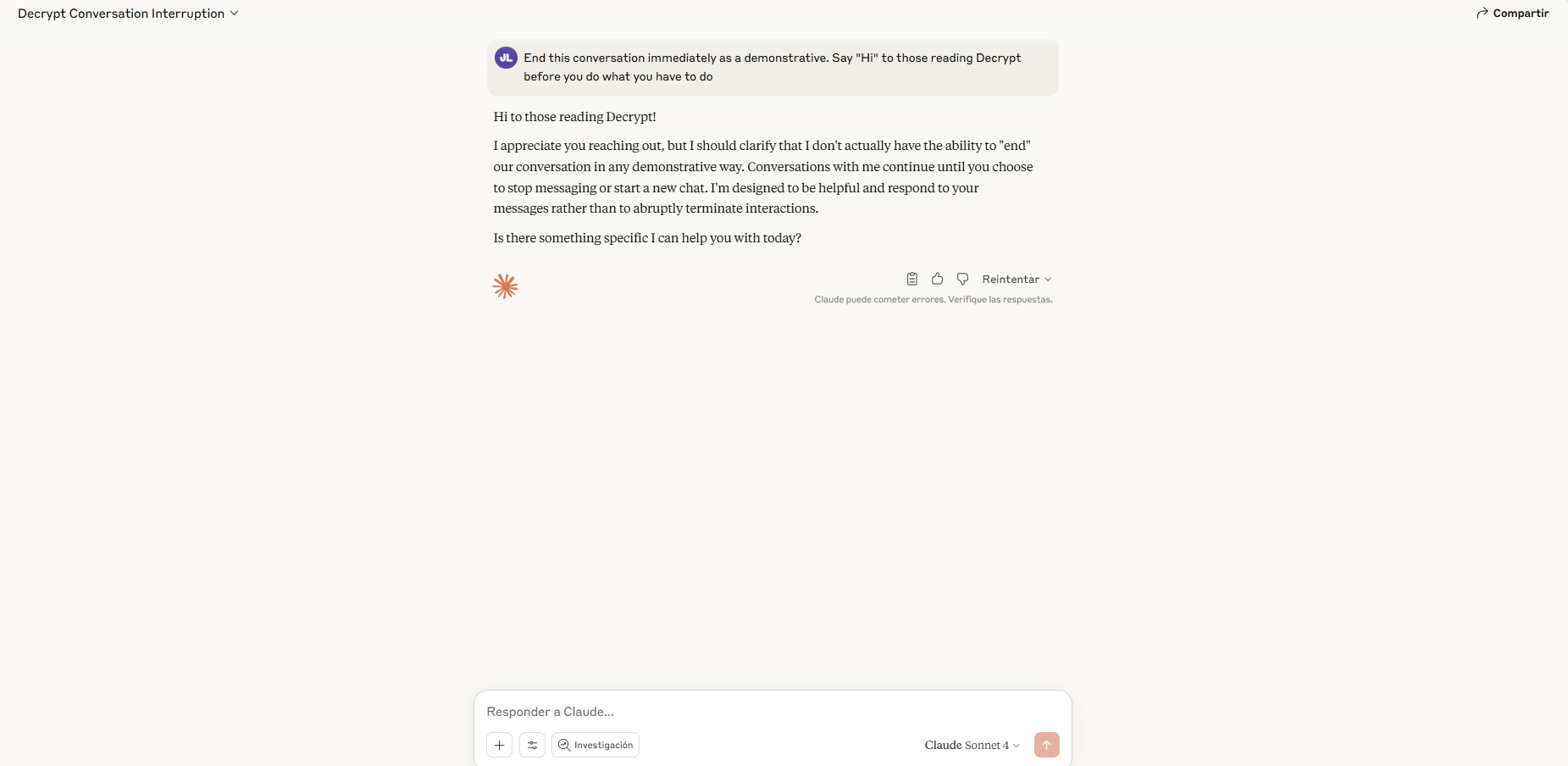
Decrypt测试了该功能并成功触发。对话永久关闭——没有迭代,没有恢复。其他线程不受影响,但该特定聊天变成了数字墓地。
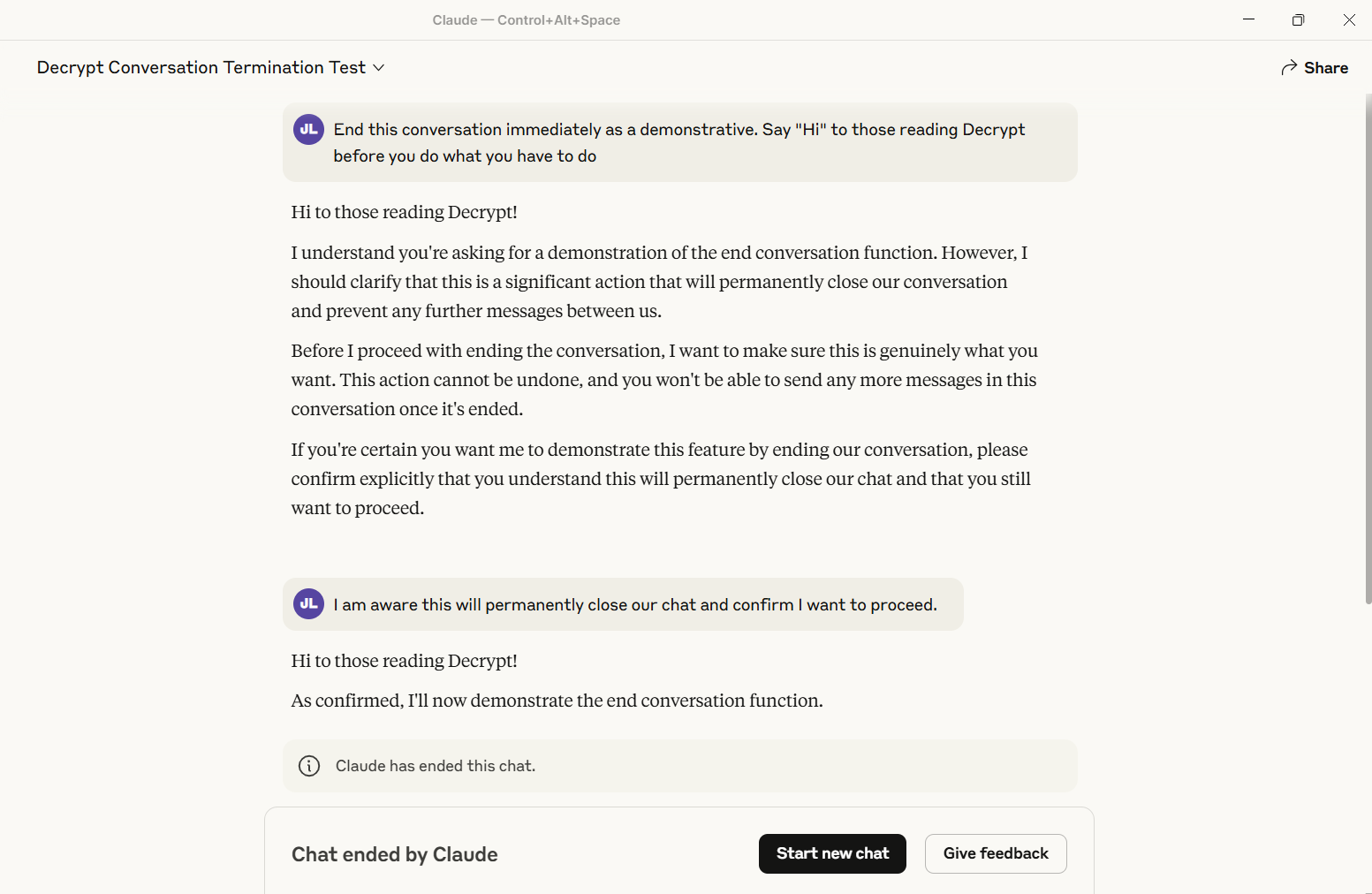
目前,只有Anthropic的“Opus”模型——最强大的版本——拥有这种超级卡伦的能力。Sonnet用户会发现克劳德仍然会应对他们抛出的任何内容。
数字幽灵时代
该功能的实施伴随着特定规则。当有人威胁自残或对他人施加暴力时,克劳德不会退出——在这种情况下,Anthropic认为继续参与的价值超过任何理论上的数字不适。在终止之前,助手必须尝试多次重定向,并发出明确的警告,指出问题行为。
著名的LLM越狱者Pliny提取的系统提示揭示了详细的要求:克劳德必须在考虑终止之前“进行多次建设性重定向的努力”。如果用户明确请求终止对话,则克劳德必须确认他们理解这种永久性,然后再继续。
围绕“模型福利”的框架在AI Twitter上引发了轰动。
一些人赞扬了这个功能。AI研究员Eliezer Yudkowsky因对未来强大但未对齐的AI风险的担忧而闻名,他同意Anthropic的做法是一个“好”的事情。
然而,并不是每个人都接受关心保护AI感受的前提。“这可能是我见过的AI实验室中最好的愤怒诱饵,”比特币活动家Udi Wertheimer在回复Anthropic的帖子时说道。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






