
伯恩斯坦最新发布的一份97页的深度报告指出,人工智能数据中心中的铜互连和光互连并非相互替代,而是将在纵向扩展和横向扩展场景下长期共存。尽管CPO技术在功耗和成本方面具有优势,但由于制造和维护方面的挑战,其广泛部署仍面临阻碍,大规模普及不太可能在2028年之前实现,因此光互连LPO/NPO可能成为过渡时期的领导者。但CPO正在从根本上重塑价值链,将利润中心从传统的光模块供应商转移到芯片设计、先进封装和系统集成商。
这里要特别说下伯恩斯坦这家机构,伯恩斯坦(Bernstein,全称为 Sanford C. Bernstein)是一家总部位于美国的全球知名投资研究公司和资产管理机构。它成立于1967年,目前隶属于全球资产管理巨头联博(AllianceBernstein,简称AB),伯恩斯坦也是规模最大、历史最悠久的独立卖方研究机构之一。下面详细拆解下伯恩斯坦的这份报告。
2月中在有详细拆解过AI算力产业链瓶颈传导的底层逻辑,聊到25-26年光互连是市场正在切换的AI主线之一。
最早https://x.com/qinbafrank/status/2015377625167089671?s=20 在去年底才开始真正关注和研究光互连方面的领域。
在伯恩斯坦这份报告,核心是三个方面:
为什么连接性取代算力成为新瓶颈?CPO兑现节奏在哪里?为什么 PCB/ABF 基板是 2026 年更现实的业绩兑现方向?详细拆解下
这份报告真正想讲的不是“CPO 要爆发”,而是:
AI 数据中心的瓶颈,正在从 GPU/HBM/CoWoS,继续向“连接系统”迁移。未来的投资主线不是 CPO 独赢,而是光、电、铜、板、封装、测试共同升级。
更直白地说:
过去市场看 AI,主要看 GPU 算力。
现在市场开始看 GPU 之间怎么连起来。
未来要看的是 算力利用率能不能被连接系统释放出来。
这就是报告标题里所谓的 “War for AI Data Center Connectivity”。
一、为什么“连接”会变成 AI 数据中心的新瓶颈?
AI 集群不是把 GPU 堆在一起就完事了。真正的问题是:这些 GPU 必须高速同步、交换参数、传输激活值、做 AllReduce、做模型并行和数据并行。理论算力再强,如果 GPU 之间通信跟不上,实际利用率就会掉下来。
可以把 AI 集群理解成一个巨大的工厂:

为什么连接性会取代算力成为新瓶颈?
这件事的根源要从大模型的训练方式说起。大模型训练有两种并行方法:
一种叫张量并行,一种叫专家并行。这两种方法的共同特点是需要GPU之间频繁地、大规模地交换数据。
一次训练GPU之间要交换的数据量是天文数字,什么意思呢?过去你只要堆GPU数量就行了,现在你堆的越多,GPU之间通信的开销就越大。到某个临界点加GPU不再让训练变快,反而让通信堵车更严重,这就是连接瓶颈。
伯恩斯坦给了一组对比,一个标准的英伟达GB30机柜里面,GPU和GPU之间用的是铜缆,因为距离短,铜缆便宜稳定。但机柜和机柜之间必须用光纤,因为铜缆超过2米信号衰减就受不了。光纤的两端需要光模块,光模块负责把电信号转成光信号再转回来。
问题来了,一个1.6T的光模块功耗大概三十瓦,其中一大半都被一个叫DSP数字信号处理器的芯片吃掉了。一个机柜里几百个光模块,光通信这一项的功耗就压不下来。
所以现在的AI数据中心遇到的真问题,不是算力不够使功耗到顶了。英伟达自己说新一代CPU交换机能比传统光模块节省70%的功耗,一个51.2T的交换机,光这一项就能省五百瓦,省下来的功耗可以让你多塞GPU。
英伟达自己也在强化这个叙事。2025 年 3 月,NVIDIA 发布 Spectrum-X Photonics 和 Quantum-X silicon photonics switches,强调它们是为了让 AI factories 连接数百万 GPU,并降低能耗和运维成本;NVIDIA 称其 photonics switches 可以实现每端口 1.6Tb/s、3.5 倍能效提升、63 倍信号完整性提升、10 倍网络韧性提升。
Bernstein这份报告的底层逻辑是:AI 资本开支的下一阶段,不只是继续买更多 GPU,而是买更多“让 GPU 有效工作的连接能力”。
二、报告最核心的判断:不是“铜退光进”,而是“多路线共存”
市场上经常有一个简单说法:光进铜退。
但这份报告的观点更细:铜和光不是简单替代关系,而是在不同距离、不同带宽、不同维护要求、不同成本结构下长期共存。Bernstein 认为 copper 和 optical interconnects 不是简单替代品,而是在 Scale-up 和 Scale-out 场景下分别发展。这个判断非常关键。
1. Scale-up:机柜内/近距离互联,铜仍然很强
Scale-up 更接近 GPU 与 GPU、GPU 与 switch、机柜内或近机柜范围的高速互联。这里最看重:
低延迟、低成本、高可靠性、可维护性、短距离传输能力。
在这个场景里,铜并没有马上死掉。
老黄之前也明确表态:NVIDIA 暂时不会把 CPO 用在旗舰 GPU 之间的主连接上,因为传统铜连接目前比 CPO 光连接可靠得多;NVIDIA 会先把 CPO 用在服务器顶部交换机中的两款新网络芯片上。
这句话非常重要。它说明:CPO 是方向,但不是马上全面替代铜。
也就是说,至少在现阶段,NVIDIA 的逻辑是:
交换机侧可以先上 CPO,GPU/XPU 侧要更谨慎。
原因很简单:GPU 是系统里最贵、最关键的资产。你不能因为光互连节能,就牺牲可靠性。AI 训练集群里,一个链路频繁掉线,损失的不只是硬件成本,而是训练任务中断、GPU 利用率下降、调度复杂度上升。
2. Scale-out:机柜间/集群间互联,光学更有优势
Scale-out 是更大范围的 GPU 集群扩展,通常涉及机柜之间、数据中心内部更长距离的东西向流量。
这个场景下,光学方案的优势更明显:
距离更远、带宽更高、线缆更轻、功耗更低、布线密度更好。
所以未来不是“铜被光完全替代”,而是:
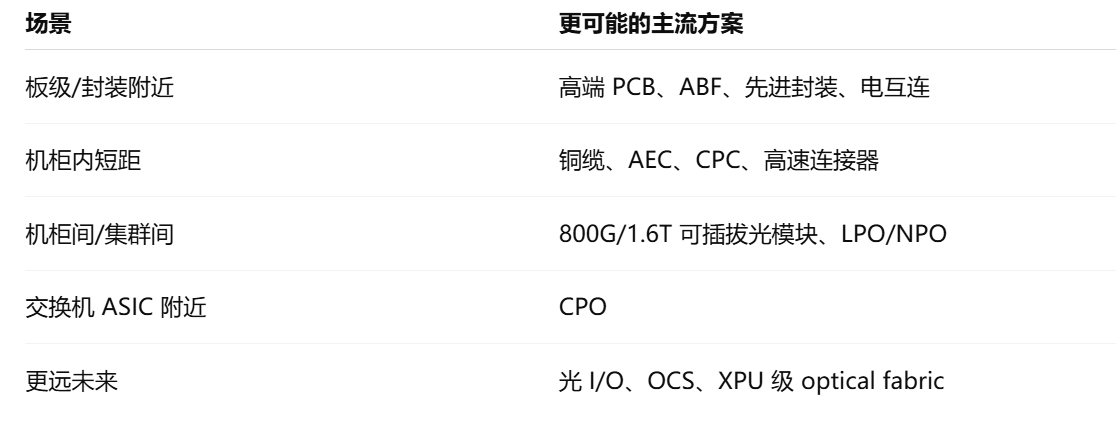
伯恩斯坦这份报告最有价值的地方:它没有停留在“CPO 概念股”层面,而是把 AI 连接拆成了多条技术路线。
三、CPO:方向很重要,但 2026 年不是全面爆发年
这份报告里最容易被市场误读的地方,就是 CPO。
很多人看到 CPO,就直接得出结论:
光模块要被替代,CPO 立刻爆发,传统光模块厂完了。
这个理解太粗。
Bernstein 预计 CPO 在 Scale-out 网络中的小规模部署可能从 2026 年下半年开始,主要用于验证真实性能和供应链成熟度;但在更关键的 Scale-up 场景中,CPO 采用可能推迟到 2028 年下半年以后,因为行业需要先验证交换机侧 CPO 的长期可靠性,再应用到更高价值、更不能容错的 XPU 系统里。
这和Jensen Huang之前的表态是吻合的:CPO 会先用于网络交换芯片,而不是直接大规模进入 GPU 主连接。
所以时间节奏应该这样理解:

LightCounting 的观点也支持“渐进演进”而不是“一夜切换”。它预测传统 retimed pluggables 未来 5 年仍将占主导,虽然 LPO/CPO 在 2026–2028 年会占 800G 和 1.6T 端口的重要比例。 EDN 对行业观点的总结也提到,Yole 认为 CPO 大规模部署可能在 2028–2030 年之间,LightCounting 则认为本十年内光模块仍会占数据中心光链路的大多数,但光学器件会持续向 ASIC 靠近。
所以我的判断是:
CPO 是中长期方向,但 2026 年更确定的收入,不一定在最纯的 CPO 概念股,而在 CPO 前夜必须先升级的光源、测试、封装、PCB、ABF、CCL、1.6T 光模块和 LPO/NPO。
四、LPO/NPO:它们是 CPO 爆发前的“过渡主线”
这份报告很重要的一点,是没有把技术路线简单分成“传统光模块 vs CPO”。
中间还有 LPO 和 NPO。
1. LPO 是什么?
LPO,全称 Linear Pluggable Optics。它大致可以理解为:保留可插拔形态,但去掉或弱化 DSP,用线性驱动和主机侧均衡来降低功耗。
优点是:功耗更低、成本可能更低、仍然保留一定可维护性。
缺点是:系统调试更难、链路预算更紧、对主机侧 SerDes 和系统工程要求更高。
公开摘要提到,LPO 通过去掉 DSP、把信号处理交给线性组件,可以相较传统可插拔模块大幅降低功耗,同时保留模块化维护便利;Bernstein 甚至认为到 2030 年 LPO 出货量可能超过 CPO。
2. NPO 是什么?
NPO 可以理解为 Near-Packaged Optics,也就是把光引擎放得更靠近 ASIC,但又不像 CPO 那样彻底封到一起。
它的价值在于折中:
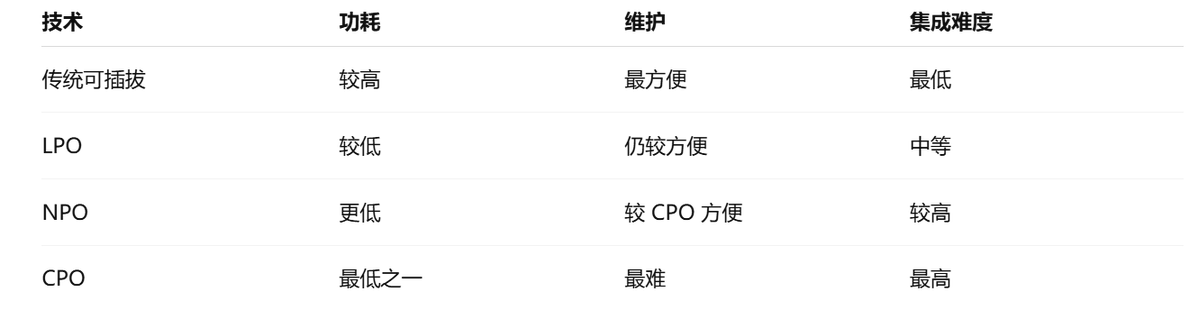
这说明未来几年很可能不是“一步到 CPO”,而是:
传统可插拔 → LPO/NPO → CPO → 光 I/O / optical fabric
这也是为什么 2026 年你不能只看 CPO。真正能兑现业绩的,可能是那些能跨多个阶段供货的公司。
总结下来就是CPO这个故事2026年还不会兑现,CPO在2026年下半年只能小批量出货,只用于scale out场景,也就是机柜和机柜之间真正大规模铺开要等到2028年。
为什么这么慢?伯恩斯坦给了三个原因:
第一个原因是云服务商不愿意换传统光模块出问题了,运维拔下来换一个新的就行,几分钟搞定。CPU是焊死在交换机里的,一个光引擎坏了,整台交换机要返厂,停机时间、运维成本对亚马逊、谷歌、微软这些云服务商来说是大问题。而且光模块的故障率不低,行业标准是10万小时故障一次,换算下来1万个光模块一年要换九个,这是硬故障,还没算软故障。
CPO把光引擎做进芯片里,可靠性必须做到几个数量级的提升,才能让云服务商放心。伯恩斯坦直接说了,他们和中际旭创这家中国光模块厂沟通,中际旭创告诉他们没有一家云服务商客户计划在2026到2027年大规模部署CPO这句话很重,市场可能还没听进去。
第二个原因是过渡方案已经出来了,CPU不是唯一选择。中间有两个技术,一个叫LPO个叫NPO。LPO是把光模块里那个最耗电的DSP芯片去掉,用更简单的元件替代。这一刀下去,功耗降到传统光模块的3分之1,但还保留可插拔800G的LPO现在已经在量产。
NPO是把光引擎放在交换机芯片旁边的PCB上,但还是可拆卸的。英伟达现在叫CPU的产品,严格说其实是NPO这两个过渡方案能撑2到3年。所以云服务商完全有理由说我先用LPU撑着,等CPO真的成熟了再说。
第三个原因是scale up场景里,铜缆还没死,GPU之间的连接叫scale up。这里铜缆的成本优势、可靠性优势,目前没有任何替代品能比。
伯恩斯坦明确说,2026到2028年,scale up仍然是铜缆主导,立讯精密在这里是受益者,他跟英伟达GP300铜缆连接器跟安费诺正面竞争,还有一个叫CPC 共封装铜缆的过渡技术术,进一步延长了铜缆的生命周期
lightcounting这家行业咨询机构预测,到2029年1.6T的连接市场里,铜缆还能占接近一半的份额。
五、CPO 最大影响:不是简单降成本,而是重分配利润池
CPO 的产业意义,不只是节能,也不是单纯替代光模块。
它真正改变的是:利润从哪里产生。
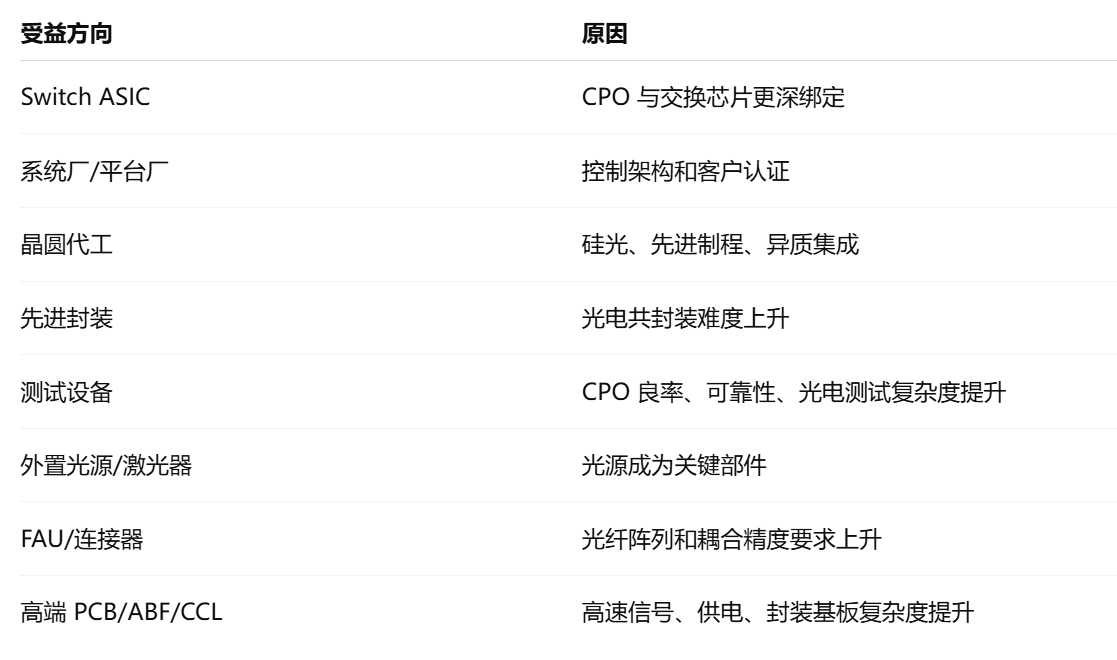
传统可插拔光模块时代,价值链大致是:
DSP / 光芯片 / TOSA/ROSA / 模块封装 / 光模块厂 / 交换机厂 / 云厂商。
CPO 时代会变成:
Switch ASIC / 光引擎 / 外置激光源 / FAU / 先进封装 / 晶圆制造 / 测试 / 系统集成。
Bernstein 用 NVIDIA Quantum-X800 CPO switch 做了成本拆解:该交换机配置四颗 switch ASIC,每颗集成 18 个 optical engines,并有 18 个外部光源模块;单台 Quantum-X800 CPO switch 估算成本约 57 万美元。摘要还指出,在 CPO 架构下 DSP 被取消,光引擎与交换芯片共封装,价值中心向芯片设计、先进封装和晶圆制造转移。
这就是为什么报告会利好这些方向:
相对来说,传统光模块厂会面临一个问题:
如果价值从模块封装转到 ASIC、封装、光引擎和系统集成,它们的利润池可能被重构。
但这不等于传统光模块厂马上没价值。因为 2026–2028 年,800G、1.6T、LPO/NPO 仍然会有大量需求。Cignal AI 也指出,高速 datacom 模块,尤其是 800GbE 和新兴 1.6TbE 设计,仍会是 2026 年的主要增长引擎。
所以正确理解是:
CPO 会改变光模块产业链利润分配,但不会在 2026 年立刻消灭可插拔光模块。
六、为什么报告强调 PCB、ABF、CCL 是 2026 更现实的方向?
这是我认为最值得你关注的地方。
CPO 的想象空间大,但兑现周期偏后。相比之下,PCB、ABF、CCL 的升级更靠近当下订单。
原因是:即使 CPO 还没有大规模商用,AI 服务器和交换机已经在升级。
Rubin、Rubin Ultra、GB300、云厂商 ASIC、下一代 switch ASIC,都在提高:
单板速率、封装面积、供电密度、信号完整性要求、散热要求、材料低损耗要求。
这是这份研报里最反共识,但最容易被忽略的一条。真正在2026年赚到钱的是PCB、HDI、ABF、基板这条老钱赛道。
为什么说反共识?因为这条赛道太传统了。PCB是几十年的老行业,全球市场2025年850亿美元,听起来一点也不性感,所有人都盯着CPO,盯着光模块,盯着英伟达,没人愿意花时间研究印刷电路板,但伯恩斯坦的数据告诉我们,这条赛道在2025年已经悄悄起飞了。
伯恩斯坦给了一组数字,盛虹科技做HDI高密度互联板的,2025年营收同比增长63%。WUS沪电股份给英伟达GB300MPCB的营收增长45%。Gold circuit金象电给AWS Trinium年供货的增长40%,shengyi electronicd生益电子AWS供应链的另一家增长40%。这些都是已经发生的真实业绩,不是预期,是兑现。为什么这条赛道在涨?有三层维度可以看:
第一层是AI服务器对PCB的含量翻倍了。过去英伟达H10服务器,一台80GPUHDI加PCB的总价值大概100到150美元每張GPU。换到GB200VL72机柜,这个数字直接翻到300美元每張。什么意思呢?同样卖一张GPU,PCB厂商赚的钱翻了一倍。
而且这还没完,即将到来的Vera Robin平台会采用一种叫midplane中版的新结构,把原本用铜缆连接的部分换成多层PCB。这块mid plane是44层板,用最高端的M8等級覆铜版,在下一代的Rubin ultra可能用到78层版M9等级。层数翻倍,材料升级,价值量再次翻倍。
第二层是上游材料卡脖子。ABF基板有一种关键材料叫T-glass低热膨胀系数玻璃纤维,它的作用是防止AI芯片在高温下基板变形导致焊点失效。
T glass现在全球只有一家公司能做到顶级规格,叫日东纺,CTE数值是2.8%,其他厂家做不到这个水平。日东纺的新产能要到2026年底才能上线,正式出货要到2027年,这意味着整个2026年t glass持续短缺。
什么是t glass短缺?就是ABF基板厂商可以名正言顺涨价。Unimicron新兴电子已经和客户重新谈了价格。伯恩斯坦的模型预测,ABF基版的ASP在2026年每个季度环比涨5%到7%,年累计涨幅可能超过20%。
第三层是ABF膜的隐形垄断者。ABF膜是ABF基板的核心材料之一,这种材料的发明者叫Agenomoto,味知数,就是那个卖味精的日本食品公司。他们在90年代研发味精的过程中,意外发现了一种特殊的氨基酸衍生薄膜,可以做半导体基板的热胀层。从那时起,全球95%的ABF膜都来自未知素。
伯恩斯坦的数据,味之素的ABF业务毛利率60%,12026财年增速32%,2027财年预计加速到45%。这家公司的ABF业务30年没人能撼动倍。
所以 2026 年更确定的不是“CPO 一夜爆发”,而是:
高速 PCB 要升级; ABF 基板要升级; CCL 要升级到更低损耗材料; 铜箔、玻纤布、低 Dk/低 Df 材料要升级; 测试和验证环节要升级。
所以2026 年更现实的策略,是先抓三类确定性——1.6T 和 LPO/NPO 过渡带来的光学需求、Rubin/ASIC 带来的 PCB/ABF/CCL 升级、CPO 试产前必须投入的测试/FAU/光源/先进封装。
因为资本市场常犯一个错误:
喜欢买最远的概念,但真正先出业绩的往往是“远期概念之前必须先建好的基础设施”。
CPO 就像未来的高铁站。
但在高铁站全面运行前,先赚钱的可能是修路、铺轨、供电、信号系统和检测设备。
七、这份报告里的产业链受益顺序
如果把 AI 连接产业链分成四层:
第一层:最强平台级赢家
这类公司不是只卖一个零件,而是控制架构。
NVIDIA
NVIDIA 的优势不是只有 GPU,而是 GPU + NVLink + InfiniBand + Ethernet + Spectrum-X + Quantum-X + 软件生态。NVIDIA 官方披露的 silicon photonics networking switches 已经把 TSMC、Coherent、Corning、Fabrinet、Foxconn、Lumentum、SENKO、SPIL、Sumitomo Electric、TFC Communication 等纳入生态。
这说明 NVIDIA 在做一件事:
不只是卖 GPU,而是把 AI 工厂的网络架构也纳入自己的平台控制。
台积电,它是这整个故事的隐形枢纽
cop平台,把电子芯片和光子芯片用混合建合技术结合起来。所有大客户英伟达、博通、Ai labs都在往台积电迁移。这家不靠CPO本身赚多少钱,但cpo强化了台积电在先进封装和晶圆代工的统治地位。
Broadcom
Broadcom 的逻辑不同。它更像是:
Ethernet switch ASIC + custom ASIC + CPO + 云厂商定制芯片生态。
Broadcom 2025 年 10 月宣布 Tomahawk 6 Davisson,这是其第三代 CPO Ethernet switch,具备 102.4Tbps switching capacity,并称已在 shipping;Broadcom 称其通过集成 TSMC COUPE 光引擎和先进多芯片封装,将 optical interconnect power consumption 降低 70%,同时支持 512 XPUs 的 scale-up 和两层网络中 100,000+ XPUs。
这说明 台积电、Broadcom 是 NVIDIA 之外,在 AI 网络与 CPO 价值链里非常关键的公司。
第二层:确定性较强的光学与高速互连
这包括:
1.6T 光模块、LPO/NPO、硅光、激光器、外置光源、FAU、光连接器。
代表方向包括 Coherent、Lumentum、Fabrinet、Innolight、Eoptolink、SENKO、Corning、Sumitomo 等。NVIDIA 官方生态名单里就包含多家光学、封装和连接相关企业。
这一层的重点不是“谁最像 CPO”,而是:
谁能同时吃到 800G/1.6T、LPO/NPO、CPO 试产、外置光源和 FAU 需求。
能跨阶段的公司,胜率高于单一概念公司。
第三层:PCB、ABF、CCL、材料
这是 2026 年认为最容易被低估的地方。
公开转述中提到,原报告覆盖或提及了 Chroma、Luxshare、Unimicron、NVIDIA、Broadcom、TSMC、Ibiden 等公司。
这里面 Unimicron、Ibiden 这种基板/PCB 链条公司非常值得注意,因为 AI 服务器复杂度提升后,PCB 和封装基板不再只是跟随件,而是性能约束本身。
第四层:测试设备、良率、可靠性
CPO 最大难点不是 PPT,而是量产。
量产要解决:
光电耦合良率;
外置激光源稳定性;
高温环境可靠性;
封装应力;
现场维护;
测试时间;
一致性;
失效后维修模式。
所以测试设备和可靠性验证可能是很好的“卖铲人”。
这类公司不一定最性感,但如果 CPO 进入试产,它们往往是最早看到订单的环节。
八、这份报告的投资含义:不要买“最像概念的”,要买“最难绕开的”
这份报告对投资最大的启发是:
AI 连接不是单点技术革命,而是瓶颈迁移。投资要押共同瓶颈,不要押单一路线。
什么叫共同瓶颈?
就是无论最终是 CPO、LPO、NPO,还是传统可插拔继续升级,都绕不开的东西。比如:
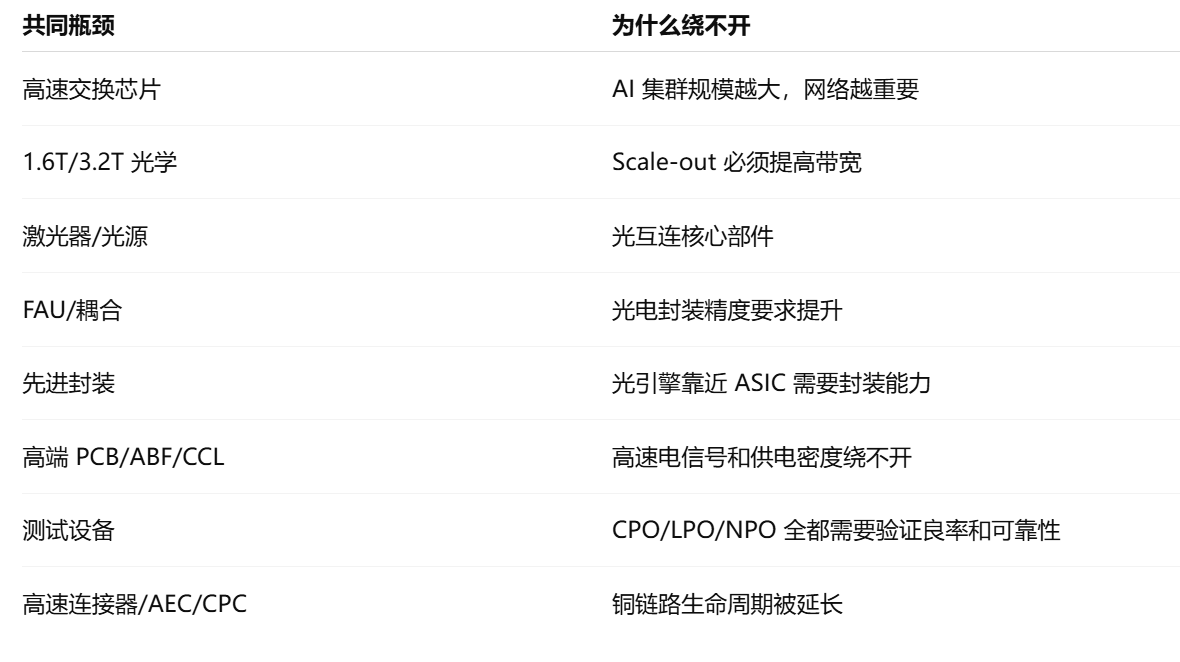
相反,单一路线风险比较
比如你只买“纯 CPO 概念”,风险是:
CPO 量产时间推迟,订单不兑现,估值先杀。
只买传统光模块,风险是:
CPO/NPO/LPO 重构价值链,长期利润池被平台厂和芯片/封装厂拿走。
只买 PCB/材料,风险是:
客户扩产过快、供给集中释放、毛利率反转。
所以更好的组合是:
2026 年买确定性,2027 年买订单弹性,2028 年以后买架构期权。
九、个人对这份报告的合理性评价
很合理的地方
- 第一,把 AI 瓶颈从 GPU 扩展到连接系统,这个方向非常对。NVIDIA、Broadcom 的产品发布都在验证这一点。
- 第二,反对“铜退光进”的简单叙事,这个判断非常重要。Reuters 对 Jensen Huang 的报道已经明确说明,铜在 GPU/XPU 核心连接里短期仍有可靠性优势。
- 第三,认为 CPO 是方向但规模化要等可靠性验证,这个判断也合理。LightCounting、Yole/EDN 的行业判断都偏向“逐步迁移,而非立刻全面替代”。
- 第四,强调 PCB/ABF/CCL、测试、光源等“前置环节”更容易在 2026 年兑现,这个对投资更有帮助。因为资本市场容易过度交易最远期的故事,却低估近期真正进订单的环节。
需要注意的地方
第一,公开转述可能会把 Bernstein 的观点“投资化、标题党化”。比如“AI 真正战场不在芯片,在连接”这句话有传播力,但严格说,GPU/HBM/CoWoS 仍然是核心瓶颈,只是连接的边际重要性上升,不是芯片不重要。
第二,CPO 的价值转移方向对,但速度可能被市场高估。CPO 要解决制造、封装、现场维护、失效更换、可靠性等问题,不是一个发布会之后立刻放量的技术。
第三,LPO/NPO 的过渡价值很大,但其系统调试难度也不低。LPO 不是“低功耗版可插拔”这么简单,它把很多复杂度转移到了主机侧和系统级调试上。
第四,PCB/ABF/CCL 这条线虽然确定性强,但也要警惕扩产周期。材料和基板行业一旦看到高景气,很容易扩产,后面客户平台节奏一慢,毛利率就会反噬。
十、未来 2–3 年,可以按这个时间表跟踪
2026:不要只看 CPO,看三条确定性
2026 年重点不是 CPO 大爆发,而是:
1.6T 可插拔光模块是否放量;
LPO/NPO 是否获得更多云厂商/交换机平台认证;
PCB/ABF/CCL 是否继续涨价或扩产;
CPO 相关测试设备、FAU、外置光源是否开始有实际订单。
如果这些发生,说明报告逻辑进入兑现期。
2027:看 CPO 试点从“样机”走向“客户部署”
关键指标是:
NVIDIA Quantum-X / Spectrum-X Photonics 的真实客户部署;
Broadcom Davisson/Tomahawk CPO 的客户扩展;
CoreWeave、Lambda、Meta、Google、微软、亚马逊等是否采用;
CPO 外置光源、FAU、测试设备是否进入收入确认。
2028以后:看 CPO 是否进入 Scale-up
最关键的转折点是:
CPO 是否从交换机侧走向 XPU/GPU 附近;
光 I/O 是否进入高端 ASIC/GPU 封装;
OCS/optical fabric 是否开始改变数据中心网络拓扑。
如果到了这一步,CPO 就不只是光模块替代,而是 AI 计算架构的变化。
十一、基于这份报告的投资框架:四类资产,四种逻辑
如果用这份报告指导美股/港股/A股投资,我会分四类。

个人最认可的策略是:
核心仓买平台赢家,弹性仓买光学与PCB确定性,期权仓小比例买 CPO 远期方向。
不建议一上来就把所有资金押在“最纯 CPO 概念股”。
十二、这份报告最核心的五个要点
- 第一,AI 数据中心的瓶颈正在从“算得快”转向“连得快、连得稳、连得省电”。
- 第二,光不会立刻消灭铜,铜也不会永远守住所有场景;不同距离和系统层级会选择不同方案。
- 第三,CPO 是方向,但 2026 年更现实的收入在 1.6T、LPO/NPO、光源、测试、PCB、ABF、CCL。
- 第四,CPO 的真正影响不是让光模块便宜,而是把利润池从传统模块封装转向芯片、封装、光引擎、光源、测试和系统平台。
- 第五,投资 AI 连接,不要买最热的概念,要买最难绕开的瓶颈。
- 这是一份很有价值的“AI 第二层基础设施”报告。它提醒市场:GPU 之后,下一个被重新定价的不是某一个零件,而是整个 AI 连接栈。
但它也不能被简单读成“CPO 立刻爆发”。更准确的读法是:
2026 年看可插拔/LPO/NPO/PCB/ABF/测试;
2027 年看 CPO 试点订单;
2028 年以后看 CPO 和光 I/O 是否真正进入 AI 计算核心架构。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






