AI艺术领域正在变得越来越火热。Nvidia推出的新AI模型Sana,能够在消费级硬件上生成高质量的4K图像,这得益于一系列与传统图像生成器略有不同的巧妙技术组合。
Sana的速度来自Nvidia所称的“深度压缩自编码器”,它将图像数据压缩到原始大小的1/32,同时保持所有细节完好无损。该模型与Gemma 2 LLM配对,以理解提示,创造出在适度硬件上表现超出其重量级的系统。
如果最终产品与公开演示一样出色,Sana承诺将成为一个全新的图像生成器,旨在运行在要求较低的系统上,这将是Nvidia试图吸引更多用户的巨大优势。
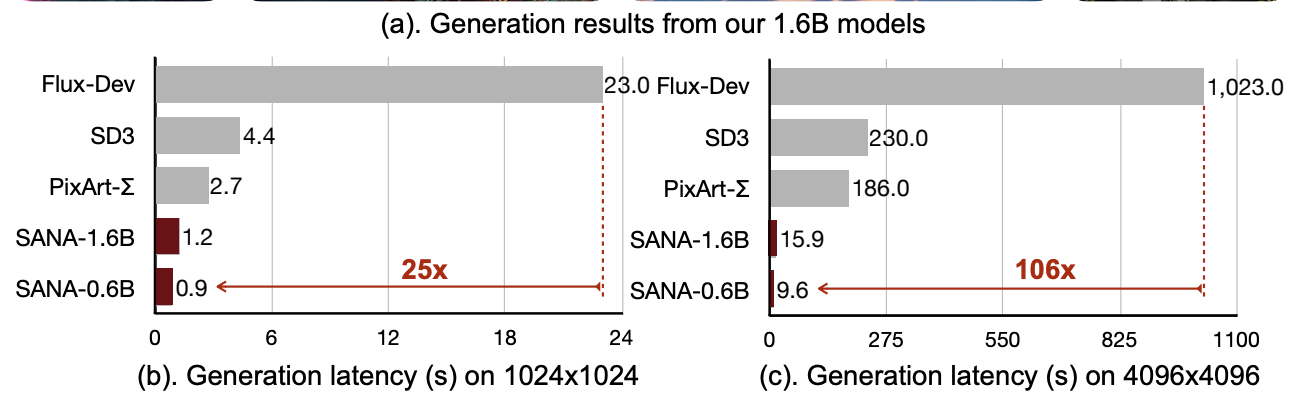
“Nvidia团队在Sana的研究论文中写道:“Sana-0.6B在与现代大型扩散模型(例如Flux-12B)竞争时非常有优势,体积小20倍,测得的吞吐量快100倍以上。此外,Sana-0.6B可以在16GB的笔记本GPU上部署,生成1024×1024分辨率的图像所需时间不到1秒。”
图片:Nvidia
没错,你没看错:Sana是一个参数为0.6亿的模型,能够与体积大20倍的模型竞争,同时在更短的时间内生成4倍大的图像。如果这听起来太美好而不真实,你可以在麻省理工学院设立的特殊界面上亲自尝试。
Nvidia的时机恰到好处,最近推出的Stable Diffusion 3.5、备受喜爱的Flux和新的Auraflow已经在争夺关注。Nvidia计划很快将其代码发布为开源,这一举措可能会巩固其在AI艺术界的地位,同时推动其GPU和软件工具的销售。
让Sana如此出色的三位一体
Sana基本上是对传统图像生成器工作方式的重新构想。但有三个关键要素使得这个模型如此高效。
首先是Sana的深度压缩自编码器,它将图像数据缩小到原始大小的仅3%。研究人员表示,这种压缩使用了一种专门的技术,能够在显著减少所需处理能力的同时保持复杂的细节。
你可以将其视为对Flux或Stable Diffusion中实现的可变自编码器的优化替代。Sana中的编码/解码过程旨在更快且更高效。
这些自编码器基本上将潜在表示(AI理解和生成的内容)转换为图像。
其次,Nvidia彻底改革了其模型处理提示的方式——即通过编码和解码文本。大多数AI艺术工具使用像T5或CLIP这样的文本编码器,基本上将用户的提示翻译成AI可以理解的内容——来自文本的潜在表示。但Nvidia选择使用谷歌的Gemma 2 LLM。
该模型基本上做了同样的事情,但保持轻量,同时仍能捕捉用户提示中的细微差别。输入“雾气缭绕的山脉上的日落与古代遗迹”,它就能准确理解——字面意义上——而不会占用你计算机的内存。
但线性扩散变换器(Linear Diffusion Transformer)可能是与传统模型的主要区别。虽然其他AI工具使用复杂的数学运算,导致处理速度缓慢,但Sana的LDT去除了不必要的计算。结果?闪电般快速的图像生成而不损失质量。可以把它想象成在迷宫中找到一条捷径——目的地相同,但路线更快。
这可能是AI艺术家们熟知的UNet架构的替代方案,UNet通过应用去噪技术,将噪声(无意义的东西)转化为清晰的图像,逐步精炼图像——这是图像生成器中最耗资源的过程。
因此,Sana中的LDT本质上执行与Stable Diffusion中的UNet相同的“去噪”和转换任务,但采用了更简化的方法。这使得LDT成为实现Sana图像生成高效率和速度的关键因素,而UNet仍然是Stable Diffusion功能的核心,尽管其计算需求更高。
基本测试
由于该模型尚未公开发布,我们不会分享详细的评测。但我们从模型的演示网站获得的一些结果相当不错。
Sana的速度相当快。作为比较,它能够生成4K图像,在不到10秒的时间内完成30步。这甚至比Flux Schnell在4步内生成类似图像所需的时间还要快,后者的分辨率为1080p。
以下是一些结果,使用了我们用来基准测试其他图像生成器的相同提示:
提示1:“手绘插图,描绘一只巨型蜘蛛在丛林中追逐一名女性,极其恐怖,痛苦,黑暗而阴森的场景,恐怖,带有模拟摄影影响的暗示,素描。”


提示2:一张黑白照片,描绘一位长直发的女性,穿着全黑的服装,突显她的曲线,坐在现代沙发前的地板上。她自信地为镜头摆姿势,蹲下时展示出修长的腿。背景采用极简设计,强调她优雅的姿势,与浅灰色墙壁和深色服装之间的鲜明对比。她的表情散发出自信和优雅。由彼得·林德伯格(Peter Lindbergh)使用哈苏X2D 105mm镜头在f/4光圈设置下拍摄。ISO 63。专业的色彩分级增强了视觉吸引力。


提示3:穿着西装的蜥蜴


提示4:躺在草地上的美丽女性


提示5:“一只狗站在显示屏幕上写着‘Decrypt’字样的电视上。左边是一位穿着商务套装的女性,手里拿着一枚硬币,右边是一只站在急救箱上的机器人。整体场景超现实。”


该模型也是未经过审查的,能够正确理解男性和女性的解剖结构。发布后,它也将更容易进行微调。但考虑到重要的架构变化,模型开发者理解其复杂性并发布Sana的自定义版本将面临多大挑战仍有待观察。
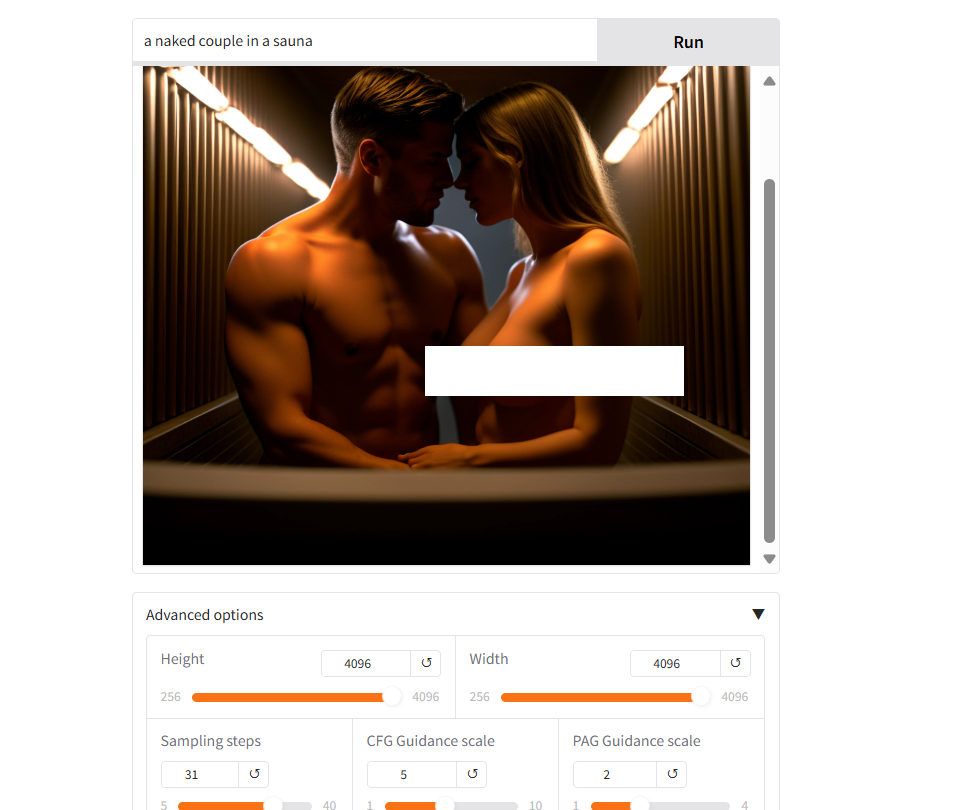
根据这些早期结果,仍在预览中的基础模型在现实主义方面表现良好,同时在其他类型的艺术中也足够多样化。它在空间意识方面表现良好,但其主要缺陷是缺乏适当的文本生成能力以及在某些条件下缺乏细节。
速度的声明相当令人印象深刻,能够生成4096x4096的图像——这在技术上高于4K——是相当显著的,考虑到这样的尺寸今天只能通过放大技术来正确实现。
它将开源的事实也是一个重大积极因素,因此我们可能很快会评测能够生成超高清图像而不会对消费者硬件造成过大压力的模型和微调。
Sana的权重将发布在项目的官方Github上。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







