特别感谢 Alex Hoover、Keewoo Lee 和 Ali 的反馈和审阅
一种被低估的隐私形式,是 ZK-SNARKs、传统版本的 FHE 或其他常被讨论的方法所无法很好满足的,就是 私密读取。用户希望从一个大型数据库中获取信息,而不透露他们正在阅读的内容。一些用例包括:
- 隐私保护的维基百科(这样你可以在服务器甚至不知道你在阅读什么的情况下学习)
- 隐私保护的 RAG 或 LLM 搜索(这样你的本地 LLM 可以从互联网获取数据,而不透露你在查询什么)
- 区块链数据读取(这样你可以使用一个查询外部 RPC 节点的 dapp,而节点不会知道你在查询什么;请参见“私密读取” 这里)
有一类隐私协议是专门设计来解决这个问题的,称为 私密信息检索 (PIR)。一个服务器有一个数据库 \(D\)。一个客户端有一个索引 \(i\)。客户端向服务器发送一个查询,服务器回复一个答案,使客户端能够重建 \(D[i]\),而服务器对 \(i\) 一无所知。在这篇文章中,我将描述所有 PIR 协议的基本原理,然后描述 Plinko,一个高效实现这一点的协议。
PIR 的基本原理
要理解更复杂的 PIR 协议,最好从“经典双服务器 PIR”开始。经典双服务器 PIR 假设客户端向两个服务器发出查询,并且它 信任 至少有一个是诚实的。协议的工作原理如下:
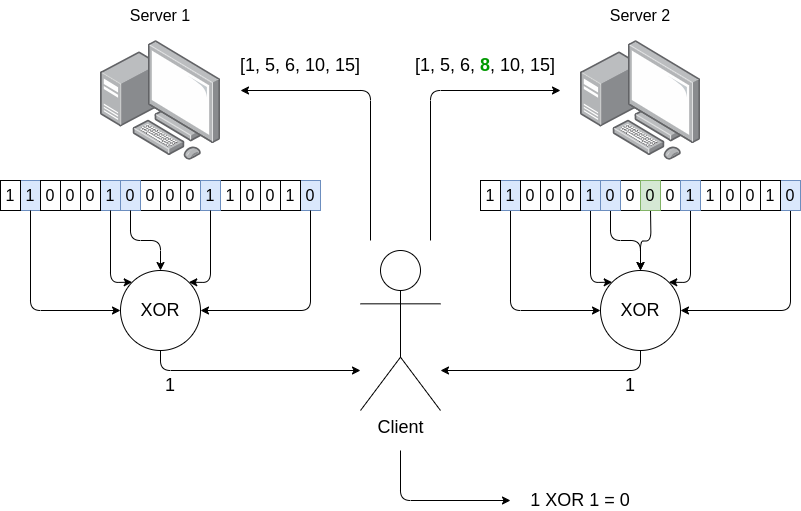
- 客户端想知道 \(D[i]\),在上面的例子中是 \(D[8]\)。
- 客户端生成一个随机的索引子集,平均约为一半(在上面的例子中,\([1, 5, 6, 10, 15]\))。
- 客户端将该子集发送给一个服务器,然后将一个 修改过的子集 发送给另一个服务器,其中 \(D[i]\) 的成员资格被翻转(即,如果不在则添加,如果在则移除)。
- 每个服务器计算它被询问的 \(D[i]\) 中值的 XOR,并返回结果。
- 客户端对这两个值进行 XOR 运算,从而得到 \(D[i]\) 的值。
关键思想是每个服务器接收到的看起来像是一个完全随机的索引子集。由于混合 \(i\) 的修改是添加值和移除值的可能性相同,因此没有任何轻微的偏差。这两个服务器给出的子集的 XOR 和几乎相同,但在一个地方不同:一个包含 \(D[i]\),而另一个不包含。客户端获取这两个值,并计算它们之间的差异,从而得到 \(D[i]\)。
这自然可以推广到“大于一个比特的单元”;你可以让每个 \(D[i]\) 例如有 1000 个比特,协议完全相同。
该协议有三个主要弱点:
- 你必须信任两个服务器中的一个是诚实的。
- 客户端的通信开销等于单元的数量(如果单元很大,这可能远小于数据的总大小,但仍然是很多)。
- 服务器必须对半个总数据进行 XOR 运算以响应单个查询。
有两种对经典双服务器 PIR 的修改是众所周知的,可以解决(1)。
一种策略是 带预处理的 PIR。注意,在上述协议中,你可以在甚至不知道要查询哪个 \(i\) 之前计算两个随机样本集之一。你生成成千上万的这些随机查询。你有一个初始阶段,在这个阶段你下载(但不需要存储)整个文件 \(D\),并在本地计算这些随机索引集的 XOR 和。基本上,你充当了两个服务器之一——以这种方式,满足了 1-of-2 的信任假设,因此你不需要信任另一个服务器。这种方法确实需要大量的前期带宽,但你可以提前完成,或者在后台进行,并使用一种效率较低的 PIR 形式来回答在完成之前收到的任何查询。
另一种策略是 单服务器 PIR。基本上,你使用某种变体的同态加密(通常比完全的 FHE 更简单)来加密你的查询,以便服务器可以在你的加密查询上进行计算,从而给你一个加密的答案。这在服务器端的计算开销很高,因此对于非常大的数据集来说尚不可行。这种策略可以与带预处理的 PIR 结合使用,因此理论上你可以通过在服务器端进行同态加密的过程来避免初始下载。
Plinko 解决了(2)和(3)——或者至少,它将通信开销和服务器端计算开销从 \(O(N)\) 降低到 \(O(\sqrt{N})\),其中 \(N\) 是单元的数量。它使用预处理策略来消除信任假设。理论上,你可以在 FHE 中进行预处理;目前这是一个开放问题,尚未有效地做到这一点。
在 Plinko 的术语中,有:
- 一个 设置阶段,客户端处理所有数据一次(但只记住少量的“提示”)
- 一个 查询机制,客户端向服务器发出查询,并将答案与正确的提示结合以计算所需的值。
如果数据集发生变化,客户端也有一种简单的方法来更新提示。现在,让我们进入协议!
设置阶段
将数据库视为一个正方形,具有 \(\sqrt{N}\) 行和 \(\sqrt{N}\) 列:

客户端生成一个随机主种子 \(S\)。对于每一行 \(i\),客户端使用主种子生成一行种子 \(S_i\)。客户端生成大约 \(128 * \sqrt{N}\)提示。每个提示的生成方式如下:
- 随机(或更确切地说,通过对主种子进行哈希伪随机)选择 \(\frac{\sqrt{N}}{2} + 1\) 行
- 如果我们正在计算第 \(j\) 个提示,对于每一行 \(r_i\),使用哈希 \(H(S_{r_i}, j)\) 生成一个随机列 \(c_i\)。因此我们得到 \(\frac{\sqrt{N}}{2} + 1\) 对 \((r_i, c_i)\)
- 对这些对进行 XOR 运算,并保存该位
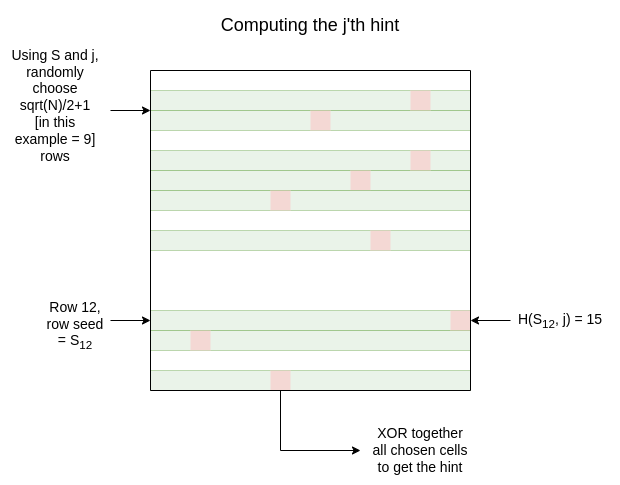
用于计算 \(c_i\) 值的“哈希” 可以 是常规哈希,但这会导致查询阶段的(可容忍但显著的)低效。因此,Plinko 更倾向于一种称为“可逆 PRF”的特殊类型哈希。它实现的核心属性是,给定 \(S_i\) 和 \(c_i\),你可以轻松恢复所有导致该 \(c_i\) 的 \(j\) 值。在实际操作中,这意味着对于任何单元 \((r_i, c_i)\),你可以轻松找到“包含”该单元的所有提示。
此外,设置阶段还生成一些“备份提示”。这些提示的构造方式与常规提示相似,但对于每个索引 \(j\),你选择 \(\frac{\sqrt{N}}{2}\) 行,并计算一对提示:一个是针对所选的行子集,另一个是针对其 补集(即未选择的 \(\frac{\sqrt{N}}{2}\) 行):
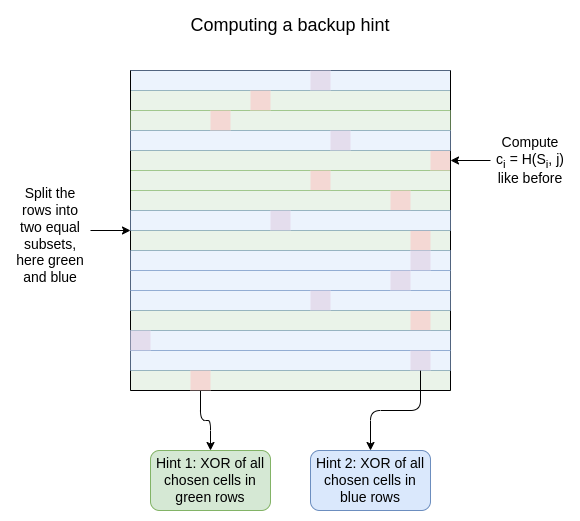
整个过程可以“流式”进行,无需客户端在任何时候存储任何数据,除了提示本身。总的来说,客户端需要下载整个数据集并存储大约 \(64 \*\sqrt{N}\) 个单元的数据,以及每个备份提示 \(\sqrt{N}\) 个单元(客户端需要为每个将要发出的查询准备一个备份提示)。
如果需要,该过程也可以在 FHE 中进行,这意味着客户端只需下载提示,但服务器需要对整个数据集进行 FHE 处理;这当然是昂贵的,优化这一点仍然是一个持续的问题。
查询阶段
假设你对特定坐标 \((x, y)\) 感兴趣。首先,你发现一个提示索引 \(j\),该索引生成一个包含 \((x, y)\) 的提示。这时,“可逆 PRF”机制发挥了作用:它让你在知道 \(S_x\) 和 \(y\) 的情况下立即反向运行该函数,以计算所有满足 \(H(S_x, j) = y\) 的 \(j\)。然而,如果你想避免这种复杂性,你可以简单地设置 \(H(S_x, j) = sha256(S_x, \lfloor \frac{j}{16}\rfloor)[j \% 16: (j \% 16) + 2]\),然后每次平均计算 \(\frac{\sqrt{N}}{16}\) 个哈希。
然后,你确定提示生成的 \(\frac{\sqrt{N}}{2} + 1\) 行。你 去掉 行 \(x\)。然后你向服务器发送一个包含以下内容的消息:
- \([(r_1, c_1), (r_2, c_2) …(r_{\frac{\sqrt{N}}{2}}, c_{\frac{\sqrt{N}}{2}})]\):该提示中包含的点集,除了你想要的点
- \([(x_1, y_1), (x_2, y_2) …(x_{\frac{\sqrt{N}}{2}}, y_{\frac{\sqrt{N}}{2}})]\):所有 其他 行的集合(包括你想要的行),每一行都有一个随机选择的列
你以随机顺序发送这些,因此服务器不知道哪个是哪个。就服务器而言,你只是向它发送了一组随机点,每行一个,行以任意方式分成两半。服务器对这两组单元进行 XOR 运算,并回复两个输出。
然后,客户端在本地将其提示与服务器返回的(非垃圾)值进行 XOR 运算,从而得出答案。
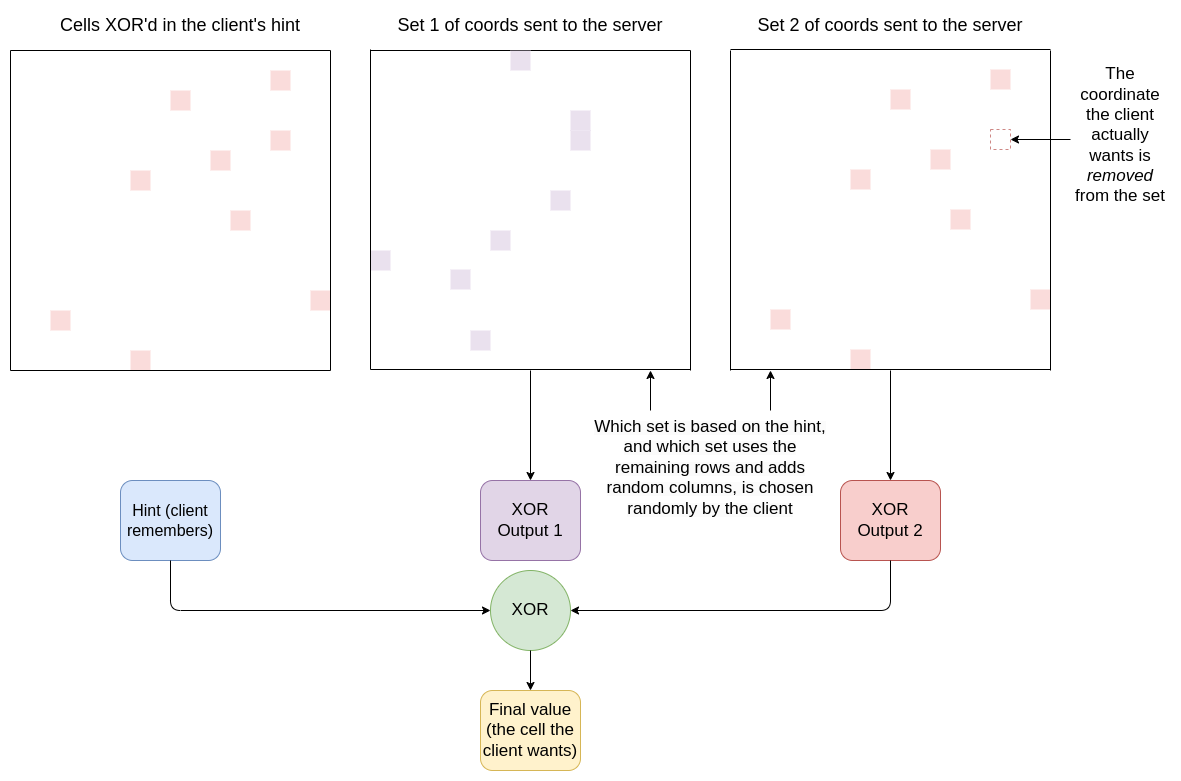
服务器基于 \(\sqrt{N}\) 个单元进行计算,并将该数据返回给客户端。服务器对客户端想要哪个单元一无所知(前提是客户端不重复使用提示),因为客户端给服务器提供了提示中每个点的所有点 除了 它实际想要的点。而且在不知道生成这些子集的哈希的情况下,对服务器而言,所有行和列的选择看起来都是完全随机的。
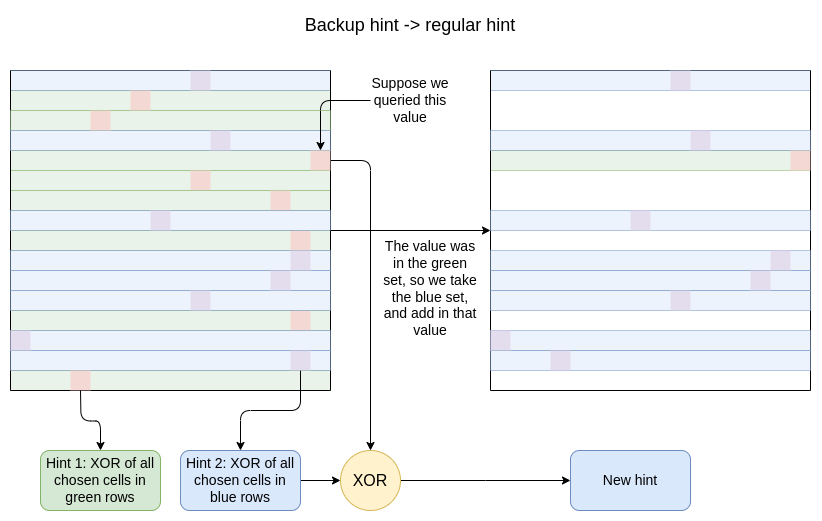
备份查询
为了避免重复使用提示(从而泄露数据),当客户端发出查询时,它会丢弃所使用的提示,并将一个备份提示“提升”为常规提示。请记住,每个“备份提示”是一对提示,一个基于随机子集的行,另一个基于其补集。算法很简单:
- 取出从不包含你查询的行的行子集生成的提示值
- 将你查询的值进行 XOR 运算
现在,你有一组 \(\frac{\sqrt{N}}{2}+ 1\) 行,每行都有一个随机选择的列的 XOR:格式与常规提示完全相同。
更新数据集
假设数据中的一个值更新了。那么,你可以找到所有包含该值的提示,并简单地进行直接更新:将旧值和新值的 XOR 混合在一起。

这就是整个协议!
具体效率
在渐近意义上,Plinko 中的一切都是 \(O(\sqrt{N})\):客户端需要存储的提示大小、每个查询传输的数据(技术上 是 \(O(\sqrt{N} *log(N))\))以及服务器端的计算成本。但将这一切放在现实工作负载的背景下是有帮助的。因此,让我们使用我最熟悉的现实工作负载:以太坊。
假设你正在查询一个包含 100 亿个值的数据集,每个值为 32 字节。这是对以太坊状态树的一个相当好的描述,几年后它将由于规模的扩大而变得显著更大。我们使用 布谷鸟哈希 将键值存储转换为 Plinko 处理的“扁平”查找表。
为了包含 Merkle 分支,一种简单的方法(尽管不是最优的方法)是将它们单独视为对较小数据库的查询;如果它是一个 二叉树,那么第一层是全尺寸,第二层是半尺寸,第三层是四分之一尺寸,等等;因为 PIR 成本都与平方根成正比,这意味着我们的总成本将被乘以 \(1 + 1 + \frac{1}{\sqrt{2}} +\frac{1}{2} + \frac{1}{2\sqrt{2}} + … = 3 + \sqrt{2} \approx4.414\)。以太坊的状态树(目前)是一个 效率较低的六叉树,但你可以通过 ZK 证明与二叉树的等价性,以获得今天二叉树的效率。
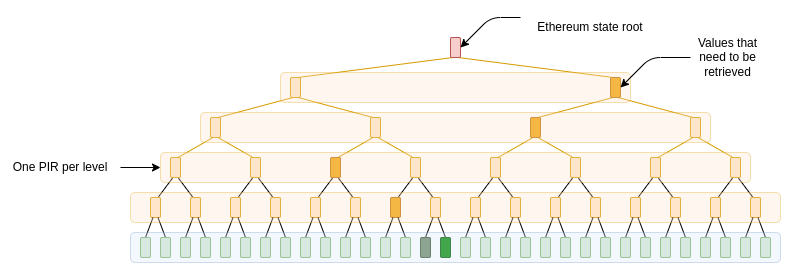
但首先,让我们提供没有 Merkle 分支的原始成本。这意味着一个 100000×100000 的网格,其中每个单元为 32 字节(256 位)。客户端需要存储 100000×128 的提示,即 100000 × 128 × 32 字节 ~= 390 MB,加上一些额外的备份提示。
对于每个查询,客户端需要向服务器发送行的分区,分为两部分,以及 100000 个列索引。我们可以 非常聪明地做得比这稍好,但如果我们天真地做,行分区是 100000 位(12.2 kB),列索引是 100000 * ceil(log2(100000)) = 1.7m 位 = 202.7 kB。这两者加起来每个查询为 215 kB。
如果引入 Merkle 分支,提示成本将飙升至约 1.68 GB。通过巧妙的工作,我们实际上可以避免每个查询的通信成本增加 4.414 倍,因为我们可以调整 PIR,使得我们对表示树的不同层级的数据集使用相同(或更确切地说,类似的)查询索引。
服务器端的成本涉及读取和 XOR 100000 个单元,或每个查询 3.05MB;XOR 是微不足道的,但读取负载是显著的。添加 Merkle 分支理论上会将其增加到约 13.4 MB,尽管实际增加的成本可能微不足道,因为巧妙的工程可以确保匹配的值始终在同一页面中(内存页面通常为 4096 字节)。
我们调整这些数字的主要工具是 使矩形不平衡(宽度和高度不同):我们可以将提示存储增加 2 倍,以将查询大小减少 2 倍。实际上,这是一个不错的权衡:存储甚至 10 GB 的提示并不困难,但特别是如果节点每 200 毫秒发送多个查询,每个查询 215 kB 的大小是我们不太能接受的。
在搜索引擎的情况下,对象的大小会大得多(例如,每个文本网页 10 kB),但查询的数量可能较少。因此,查询复杂度相对较低,但提示大小会很大。为了弥补这一点,可能有意义的是在 另一个方向 使矩形不平衡。
超越 Plinko:与替代方案的比较
Plinko 的一个现有替代方案是 TreePIR。TreePIR 通过使用“可穿透的伪随机函数”(puncturable PRF)来工作:一种哈希函数,您可以提供一个密钥,使其能够在所有点上进行评估,除了 一个选定的点。这使您能够生成查询列的表示(“从种子 \(S\) 生成的值,除了 第 \(j\) 个值”),其大小为对数级别——比直接提供整个列表要紧凑得多:
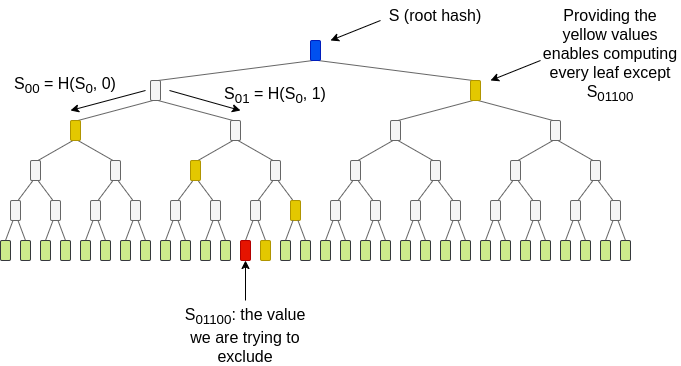
完整的方法比上面的图示更为巧妙。该图中的想法揭示了被排除的索引 01100,违反了隐私。TreePIR 通过提供黄色值 而不 揭示它们在树中的(水平)位置来工作。可以通过为每个黄色值选择左侧和右侧位置来生成 \(2^{log_2(\sqrt{N})} = \sqrt{N}\) 种可能的叶子值集合,因此可以生成 \(\sqrt{N}\) 种可能的列集合。服务器有一个 \(O(\sqrt{N} * log(N))\) 时间算法,可以同时计算每种可能排列的所选单元的 XOR 和。客户端知道这些和中哪个对应于它实际需要的集合。它使用单服务器 PIR 来请求它。
这将通信复杂度降低到对数级别,代价是增加了服务器的工作量,并且去除了“可逆 PRF”机制,迫使客户端“筛选”许多可能的提示,直到找到匹配的提示。
对于 PIR 协议需要多少开销,有各种 理论下限 界限。然而,实际上,大多数这些界限都有附带条件,因此“真实”的下限要少得多。例如,如果您有混淆,您可以使这些协议中的任何一个仅需常量的实时通信开销——但当然,今天,这样的协议仍然离实用性相当远。更难减少的是服务器端的计算。因为它“只是” XOR,所以 Plinko 中的工作负载已经不算大。但如果我们想要消除客户端的 \(O(N)\) 下载要求,那么我们需要服务器端进行更重的计算。
在 Plinko 中,PIR 的发展远远超过十年前,但理论上这些协议仍然可以走得更远。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







