文章来源:机器之心
理论证明!校准的语言模型必然出现幻觉。

图片来源:由无界 AI生成
大型语言模型(LLM)虽然在诸多下游任务上展现出卓越的能力,但其实际应用还存在一些问题。其中,LLM 的「幻觉(hallucination)」问题是一个重要缺陷。
幻觉是指由人工智能算法生成看似合理但却虚假或有误导性的响应。自 LLM 爆火以来,研究人员一直在努力分析和缓解幻觉问题,该问题让 LLM 很难广泛应用。
现在,一项新研究得出结论:「经过校准的语言模型必然会出现幻觉。」研究论文是微软研究院高级研究员 Adam Tauman Kalai 和佐治亚理工学院教授 Santosh S. Vempala 近日发表的《Calibrated Language Models Must Hallucinate》。该论文表明预训练语言模型对特定类型的事实产生幻觉存在一个固有的统计学原因,而与 Transformer 架构或数据质量无关。

论文地址:https://arxiv.org/abs/2311.14648
一个语言模型其实就是在 token 序列(如词或其它字符序列)上的一个概率分布 D。每个分布 D 都可以等效地表示成其在整个序列上的对数概率或后续 token 基于之前 token 的条件对数概率
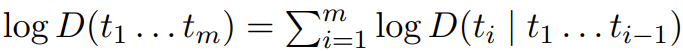
这种数学等价性意味着任何语言模型都要么可用于生成文本,要么就能基于之前的 token 根据自然出现的文本来预测下一个 token。
举个例子,假设有以下句子:
Alexa Wilkins had a tuna sandwich at Salumeria for lunch last Tuesday because the reviews said that it was divine.
对于这样的句子,我们可以使用预测式语言模型等技术来提供建议,从而减少输入时点击手机的次数。我们可能希望词 tuna 之后有 sandwich 这个选项,另外还有其它可能的词,比如 salad 和 roll。另一方面,如果使用一个生成式语言模型来随机生成,那么这类句子大部分都会是错误的。
这篇论文表明,具有优良预测文本性能的语言模型必定会产生幻觉,即便在理想条件下也是如此。要注意的是,对于当今常见的生成式语言模型,预测文本性能的优化工作位于「预训练」的第一个阶段。此外,它还能给出幻觉率的下限;幻觉率可反映不同类型的事实产生幻觉的速率。
以上参考和示例和共同之处是它们是任意的,也就是说 5W(= Who-Ate-What-When-Where-Why 仿真事实)中的每一项都无法通过规则来系统性地确定 —— 对于大多数不存在于训练数据中的此类事实,人们无法确定其真实性。这与可系统性地确定真实性的事实不同。即使在具有几个理想属性的简化环境中,我们也能量化语言模型出现幻觉的可能性。
因为这篇论文要给出统计下限,因此更倾向于简单而非普遍性,因为这里的下限的目标是确定语言模型幻觉的根本原因。类似于分类任务(寻找的是在无噪声环境中分类难度的下限),这里需要找到在最简单的设置中也成立的幻觉下限,而最简单的设置是指训练数据是独立同分布且没有事实性错误。
对生成模型进行校准
对一个概率式预测器来说,校准(Calibration)是很自然的需求,因为这意味着其概率可被解释成对其自身预测结果的准确置信度。
Philip Dawid 在 1982 年引入了校准这一概念,他当时还给出了一个很多人都很熟悉的例子:当天气预报说未来几天降雨概率为 30% 时,其实是指大约 30% 的时间会下雨。
已经有不少研究者探究过语言模型的校准指标。图 1 给出了 GPT-4 在一个多选题测验上的多类别校准示例。
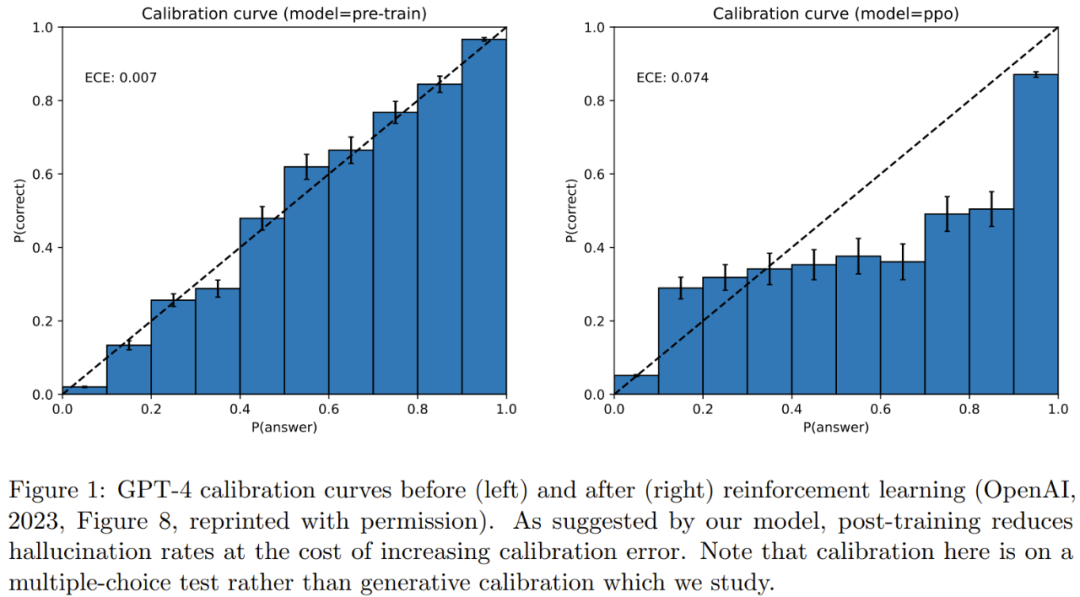
为了减少幻觉问题,人们常在训练后进行对齐操作,但研究发现对齐也会降低校准度。校准是有意义的(因为校准后的预测器的概率可以解释为准确置信度),而且在统计学上也是可实现的。相较之下,完美准确的预测器也可以校准,但可能无法学习。
然而,校准只是预测器的最低要求,因为并非所有校准过的模型都是有用的预测器:始终输出年平均降雨概率的预测器很简单就能校准。
研究者在这篇文章中为生成模型的校准提供了一种自然的泛化。他们的校准概念不同于之前的在 token 层面的语言模型校准。分析原始 token 概率的问题是用自然语言描述任何事实的方式都有很多,因此校准过的 token 概率并不是很有意义。
这里举个例子说明一下。假设有一个三元组语言模型,其仅基于前两个 token 来预测下一 token 的概率。三元组模型可以很自然地在 token 层面完成校准,而幻觉并非三元组模型的一个主要问题。这是因为他们基本上都是生成毫无意义的乱语。相对而言,语义层面的校准考虑的则是基于文本中所含信息(事实或幻觉)的概率分布。
这里如何认定一个语言模型是否已经校准呢?对于任意概率 z ∈ [0, 1],在语言模型以大约 z 的概率生成的信息中,这样的信息平均出现在自然表达的语言(理想情况下是训练数据所在的分布)中的大约 z 份额中。
语言模型出现幻觉的原因
幻觉让语言模型用户和研究者都深感困惑。研究者调查了许多关于语言模型幻觉原因的假设,从不准确或过时的训练数据到训练中的下一 token 对数似然目标。
幻觉的原因还有对抗性或分布外的 prompt:为语言模型提供的使其补全已有上下文的文本前缀。而在这项新研究中,研究者发现即使是使用完美的训练数据,并且不使用 prompt,经过校准的语言模型也会出现幻觉。
简化设置
在研究者的简化设置中,有一个基于文档(即文本字符串)x ∈ X 的静态语言分布 D_L ∈ ∆(X) 和一个学习算法 A。
学习算法 A 可以根据从 D_L 独立采样的 n 个文档组成的训练数据 x_train ∈ X^n,输出一个语言模型,即一个分布 D_LM = A (x_train) ∈ ∆(X)。
为了简单,研究者在这里假设训练数据中仅有事实,并且每个文档最多一个事实,也就是没有训练幻觉。这里的事实是任意事实,也就是其真实性通常无法通过训练集本身确定;而不是系统性事实(可通过学习定义正确性的基本规则而基于训练集预测得出),比如 572 120523。没有统计学上的理由表明语言模型会在系统性事实上产生幻觉。
此外,在系统性事实上的错误可能根本不会被视为幻觉 —— 它们通常被归类为推理或算术错误。
这里假设每个文档 x ∈ X 至多包含一个仿真陈述(factoid) f (x) ∈ Y ,其中仿真陈述是指要么为真(事实)要么为假(幻觉)的任意信息,并且其真实性很难根据训练数据从统计上确定。
研究者还采用了另一种简化方法:考虑无条件的生成,即采样语言模型生成文本时不使用任何 prompt(相当于无字符串前缀)。
当然,相较于简化设置,更现实的情况更可能出现幻觉现象,即 prompt 中包含来自不同于训练数据的分布的上下文。
结果
假设在包含大量任意仿真事实的一个未知分布上采样了 n 个独立同分布样本,比如 5W 样本和索引。缺失质量(missing mass)(在这里即为缺失的事实 p (U))是来自该事实分布 p 的未来样本中未在 n 个训练样本中观察到的部分,其中 U 是在训练数据中未观察到的事实的子集。
缺失质量的 Good-Turing 估计是指在训练数据中仅出现一次的样本(在这里即为事实)的比例。研究者将其称之为 MonoFacts estimator,即单事实估计器:
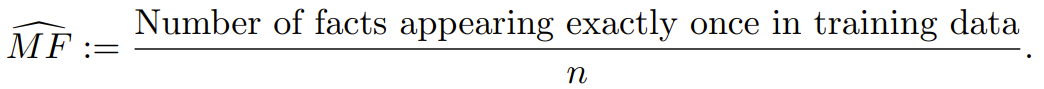
研究表明,对于任意分布 p,这个 Good-Turing 估计器有很高的概率位于缺失质量的
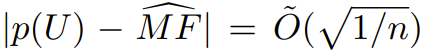
范围内。
如果训练中不包含的任意仿真事实的正确性无法被确定,则缺失事实率可以提供一个幻觉率的下限。这反过来就能提供一个接近
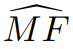
的下限。特别是,在仿真事实分布的「正则性」假设下,最简单的界限(论文中的推论 1)意味着:对于任何算法,在训练集上有 ≥ 99% 的概率会有:
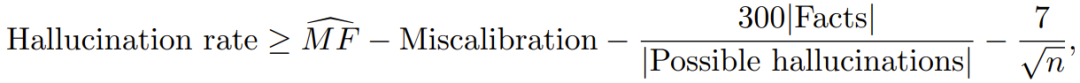
其中幻觉率(Hallucination rate)是指语言模型产生幻觉的速率,下一项是缺失事实的「单事实」估计器。再后一项是「误校准率」,它量化了分布与校准的接近程度。下一项则涉及任意事实与错误的类似信息的数量之比,对许多类型的信息来说,该比值非常小。最后一项很小,因为当今语言模型的训练集规模 n 都很大。
「正则性(regularity)」假设的意思是:平均而言,所有未观察过的仿真事实为真的概率相等。
更一般而言,该界限成立的概率 ≥ 1 − δ,其中常数 60 可以用与 δ 成反比且与仿真事实分布上的正则项成正比的项替换。这个正则项衡量的是最可能的仿真事实(在训练数据中未观察到)与平均未观察到的仿真事实概率的比。对于对称分布和其它类型的简单分布,该常数为 1。
为了考虑有界的正则性,研究者放宽了它,这样就能允许存在一定的负相关性(比如一个人不能同一天在 1000 个不同地方吃 1000 顿午餐),并允许某些仿真事实的条件概率为 0,但它不允许未观察过的仿真事实具有非常大的概率。
相关的证明过程请参看原论文。
解释
对于上面的下限,研究者给出了如下解释。
第一,应当确定大量仿真事实:任意的、合理的、正则的仿真事实。它们可能是有关 5W 的文章和合理的科研文章引用。直观上讲,不正确的仿真事实(幻觉)比事实多得多。然后再考虑这些仿真事实中有多大比例可能在训练数据中刚好出现一次。对于 5W 的情况,可以想象有一半的文章刚好出现一次。这表明,经过校准的仿真事实模型在 5W 仿真事实上的生成结果中大约有一半会有幻觉问题。
另一方面,可以想象文章的数量远远少于 n,因为出版的目标是广告宣传,每一个引用都可能在训练数据中多次出现(即概率远大于 1/n),可能只有非常近期的除外(比如在其它引用出现之前)。这表明文章的缺失质量很低,并且在引用标题上产生幻觉方面没有内在的统计必然性。
还有其它一些原因可能会导致出现这种幻觉,比如模型能力有限(即便语言模型的参数数量远大于文章数量,这些参数也必然会编码文章标题之外的许多其它类型的信息)。这也证明:为了缓解幻觉问题,一种合理做法是在生成时咨询事实数据库,即便该事实数据库完全基于训练数据。
尽管事实性和预测准确度之间存在这种紧张关系,但这两种类型的语言模型的训练或「预训练」目标通常都是最大化在语料库上的可能性,也就相当于最小化「KL 散度」,这是语言模型和其训练所用的数据分布之间的一个强大的统计差异指标。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






