Author: Zhang Aila
Today, let's talk about transit hubs.
In simple terms, a model transit hub connects different models like OpenAI, Claude, Gemini, DeepSeek, etc., to the same entry point. It allows developers to use a single interface, one account, and a unified bill to call multiple models, making it easier to choose, switch, and back up between different models or vendors.
Of course, for domestic users, the bigger reason to use a transit hub is to access overseas models and for cost-effectiveness.
This is well understood; we won't say much about domestic transit hubs, but today we will mainly introduce OpenRouter.

By 2026, OpenRouter had already raised $113 million in Series B funding, and its valuation had approached $1.3 billion.
In other words, it is already a unicorn company.
Let's analyze why a "non-model" model transit hub is worth so much.
What exactly does OpenRouter do?
OpenRouter officially positions itself as a unified interface for large models.
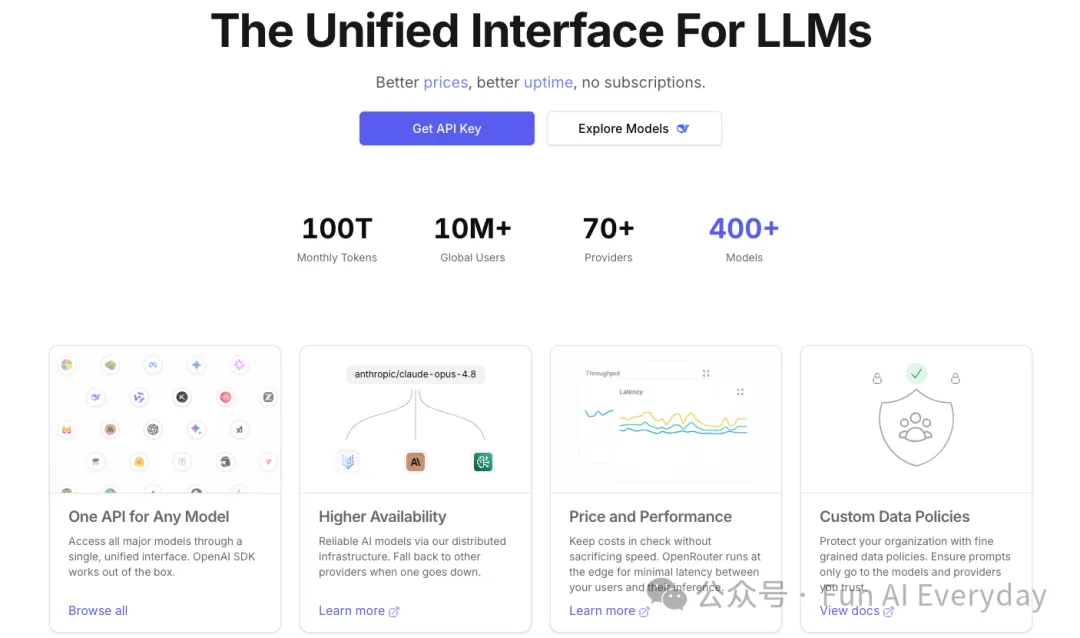
OpenRouter currently supports over 400 models from more than 70 model vendors.
The official website also reveals that the platform's monthly processing volume has reached 100 trillion tokens, with over 10 million users worldwide.
In the announcement of its Series B financing in May 2026, it was also mentioned that in the past six months, OpenRouter's weekly processing volume increased from 50 trillion tokens to 250 trillion tokens, serving over 8 million developers.
These numbers indicate one thing:
OpenRouter is no longer a niche developer tool; it is a significant entry point for AI calls.
Using it is also straightforward for developers.
Previously, you had to connect to OpenAI, Anthropic, Google, DeepSeek, Mistral, xAI, etc., separately.
Each connection required documentation review, API key application, billing binding, handling interface discrepancies, reviewing rate-limiting rules, and exception handling.
With OpenRouter, developers can call different models through the same interface.
Many times, the code that originally used the OpenAI interface only needs to change the base URL, switch the API key, and specify the model name to call other models through OpenRouter.
This has also been one of the reasons for its rapid early growth: low migration costs.
Why don't developers connect directly to model companies?
It seems that developers can completely bypass OpenRouter and go directly to the model company's official website to activate the API.
But in real development, this is not so simple.
If an AI product is just a demo, one model is enough. However, once it enters real business, it becomes very difficult to rely on just one model.
For example, an AI writing tool may have several different types of tasks:
- Generating titles can be done with cheaper models;
- Writing long articles requires stronger text capabilities;
- Analyzing data needs models with long context;
- Content moderation requires low-cost, high-stability classification abilities;
- Enterprise clients require that data is not retained, so vendors that comply with data policies must be chosen;
- During peak times, if a model is rate-limited, it needs to automatically switch to a backup model.
At this point, the question is not just about "connecting to an API."
The team needs to maintain a complete model calling system:
Which model is responsible for which task, which model is cheaper, which vendor is faster, which vendor has a lower failure rate, how to switch when problems occur, how to attribute bills, and how to isolate enterprise client data.
Moreover, the model market is changing rapidly.
Today, Claude may be better for writing code, tomorrow Gemini might have advantages in long contexts, and the day after tomorrow DeepSeek or some open-source model might drive prices down.
Model capabilities, prices, context lengths, and vendor policies are constantly changing.
The value of OpenRouter lies here.
It does not write AI applications for developers, but manages "which model to use, how to call it, how to ensure redundancy, and how to control costs."
Not just a model supermarket, but a model scheduling layer
If OpenRouter is only understood as a "model supermarket," its value will be underestimated.
A model supermarket addresses the issue of "there are many models here, you can choose."
But the truly important capability of OpenRouter is scheduling between models and vendors.
The same model can be provided with inference services by different vendors.
For example, an open-source model may be hosted by multiple cloud service providers or inference service providers. The prices, speeds, and stability of different vendors vary.
In OpenRouter's documentation, there is a capability called provider routing, which is vendor routing.
Developers can automatically route requests through different vendors based on conditions like price, latency, throughput, and vendor order.
It also supports fallback, meaning that if a certain model or vendor fails, the system automatically switches to backup options.
For developers, OpenRouter effectively separates "model selection" and "error handling" from business code and hands them over to a dedicated platform to handle.
Why do enterprises need this layer?
When enterprises start using AI, the initial question is usually "can it be used," but it quickly shifts to "how to manage it."
A company may have many teams using AI.
Marketing teams use it to create content, customer service teams use it to respond to users, development teams use it to write code, operations teams use it to analyze data, and legal teams use it to process contracts.
If every team connects to models on their own, the problems will multiply:
- Billing cannot be distinguished; model selection is inconsistent;
- Data policies are opaque; different teams re-access models;
- If issues arise, no one knows which path the call took;
- When model vendors change, it becomes challenging for the system to adjust uniformly.
The workspaces, budget control, call logs, vendor strategies, and zero data retention routing provided by OpenRouter are all addressing these issues.
For example, zero data retention.
For many enterprises, not all requests can be sent to any model vendor indiscriminately. Customer information, contract contents, medical data, and financial data can all have strict requirements.
OpenRouter's documentation supports Zero Data Retention, meaning zero data retention.
Developers can set requests to be sent only to vendors that do not store data. This policy can be implemented globally, by model groups, security rules, or for individual requests.
Another example is prompt caching.
Many AI applications repeatedly use long system prompts, knowledge base content, or context. If each request recalculates, the cost will be high.
OpenRouter supports increasing cache hit rates through vendor sticky routing, aiming to let subsequent requests go through the same vendor endpoint to reduce costs for repeated contexts.
These kinds of features may not sound exciting, but they are very practical, and the larger the scale of AI applications, the more obvious the savings.
How does OpenRouter make money?
OpenRouter's business model is very clear: it makes money based on usage.
Developers first purchase capacity on the platform and then pay according to the actual models and tokens they call.
OpenRouter states clearly:
The platform charges a 5.5% fee when purchasing capacity, with a minimum of $0.8; the underlying model vendor's prices are passed on to users at the original price without additional markup on model inference costs.
This is a typical "traffic toll" business.
The advantage of this model is that revenue is tied to usage.
The more developers call, the higher the platform's revenue; the more AI applications there are, and the greater the tokens consumed, the bigger OpenRouter's business will be.
But it also has a characteristic: the single transaction commission is not high, so it must rely on scale.
This is why token processing volume is very important to OpenRouter.
Its core metric is not the number of registered users but how many tokens flow through it weekly and monthly.
In 2025, OpenRouter's annual processing volume increased from about 100 trillion tokens to over 100 trillion tokens.
By 2026, OpenRouter had reached an annualized processing volume of about 1.5 quadrillion tokens.
This is the underlying logic of this business.
As long as more and more AI applications run on multi-model systems, OpenRouter can continuously extract service fees from these calls.
Why has it been growing so fast recently?
OpenRouter's growth can be summarized as benefiting from three changes.
The first change is that there are more models.
In the past, many teams using AI applications would default to using OpenAI first. Now, it’s different.
Claude, Gemini, DeepSeek, Qwen, Mistral, Llama, Grok, and a large number of open-source and open-weight models have advantages in different scenarios.
This is not a market of "who completely replaces whom."
Some models are good for writing code, some are cheaper, some are strong for long texts, some are fast, some are suitable for role-playing, some for corporate documents, and some for multimodal tasks.
The more models there are, the higher the selection cost; the higher the selection cost, the more valuable the intermediary layer becomes.
The second change is that AI applications are starting to pay attention to costs.
Many products initially used the strongest models to achieve results first.
But once a product has users, model costs can quickly become an issue.
For a customer service chatbot, AI search product, code assistant, or content generation tool, if all requests go through the most expensive model, the gross profit can easily be consumed.
A more mature approach is to break down tasks:
- Use cheaper models for simple tasks;
- Use strong models for complex tasks;
- Prioritize low-latency models for high-frequency tasks;
- Switch to backup models after failures;
- Only use vendors that comply with data policies for sensitive data.
This is precisely the use case for OpenRouter.
It may not necessarily help you find the "strongest model," but it can help you balance between effectiveness, price, speed, and stability.
The third change is that AI applications are moving from chat interfaces to intelligent agents.
Intelligent agents can call tools, read files, search the web, execute tasks, and make multiple continuous calls to models.
Compared to regular chats, intelligent agents consume more tokens and rely more on stability.
This is a positive for OpenRouter.
Because the more calls are made and the longer the chain, the more developers need routing, backup, logging, cost control, and vendor management.
This is also why OpenRouter's financing announcement emphasizes that AI is moving from experiments to critical production applications and intelligent agent scenarios.
Its growth essentially stems from the increase in AI calling volume.
This business also has risks
OpenRouter is well-positioned, but not safe.
It is positioned between model companies, cloud vendors, and application developers. This position has value but can also be easily squeezed.
The first risk is that large companies may build in-house.
For small teams, OpenRouter is very convenient.
But for large enterprises, model routing, permissions, logging, and cost management can also be handled internally or outsourced to cloud vendors.
Especially for clients in finance, healthcare, and government, they may care more about data control and private deployments.
To enter these clients, OpenRouter cannot rely only on "having many models." It must delve deep into permissions, audits, data policies, vendor management, and enterprise support.
The second risk is that cloud vendors will also create model gateways.
AWS, Google Cloud, and Azure, these cloud platforms, already have enterprise clients, billing systems, permission systems, and compliance capabilities.
They can easily integrate multi-model calls, routing, monitoring, and cost management as part of their cloud services.
OpenRouter's advantage is its openness and neutrality, with broader model coverage and faster access.
However, cloud vendors' advantages lie in customer relationships and enterprise procurement processes, making this a long-term competition.
The third risk is the relationship with model vendors.
OpenRouter drives traffic to model companies but also distances model companies from final developers.
As the platform grows larger, it will control more user relationships and model usage data.
Model vendors want distribution but are also concerned about having their bargaining power weakened.
Such intermediary platforms are often welcomed by suppliers in the early stages; however, as they scale, the relationship becomes more delicate.
The fourth risk is the potential to lower platform fees.
OpenRouter charges a 5.5% platform fee, which seems low now.
But if similar services proliferate, developers will compare prices, stability, model coverage, and enterprise features.
If some competitors are willing to offer lower rates or if cloud vendors bundle such capabilities into existing services, OpenRouter will need to prove that it is more than just a "request forwarder."
It must continuously provide better routing, stronger model coverage, more transparent pricing, more stable services, and more comprehensive enterprise control.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







