Alibaba's Qwen team dropped the Qwen-Robot Suite on Tuesday: three foundation models forming what they call a "full stack for embodied intelligence." Qwen-RobotNav handles mobility. Qwen-RobotManip handles manipulation. Qwen-RobotWorld simulates the physics that make both possible. Each works independently. Together, they're the Android moment for robotics—the operating system, not the hardware.
Alibaba is right now the only company in China spanning chips, cloud, models, serving platforms, and applications. For the company, robotics is the most physical expression of that bet, what is known as embodied AI.
AI agents currently rely on LLMs to power their decisions. The usual way robots work is by machine-learning models which, although advanced, lack the adaptability of generative AI. Physical agents face a different, harder class of failure modes: physics, not prompts.
For these use cases, Alibaba introduced this new AI suite with different components:
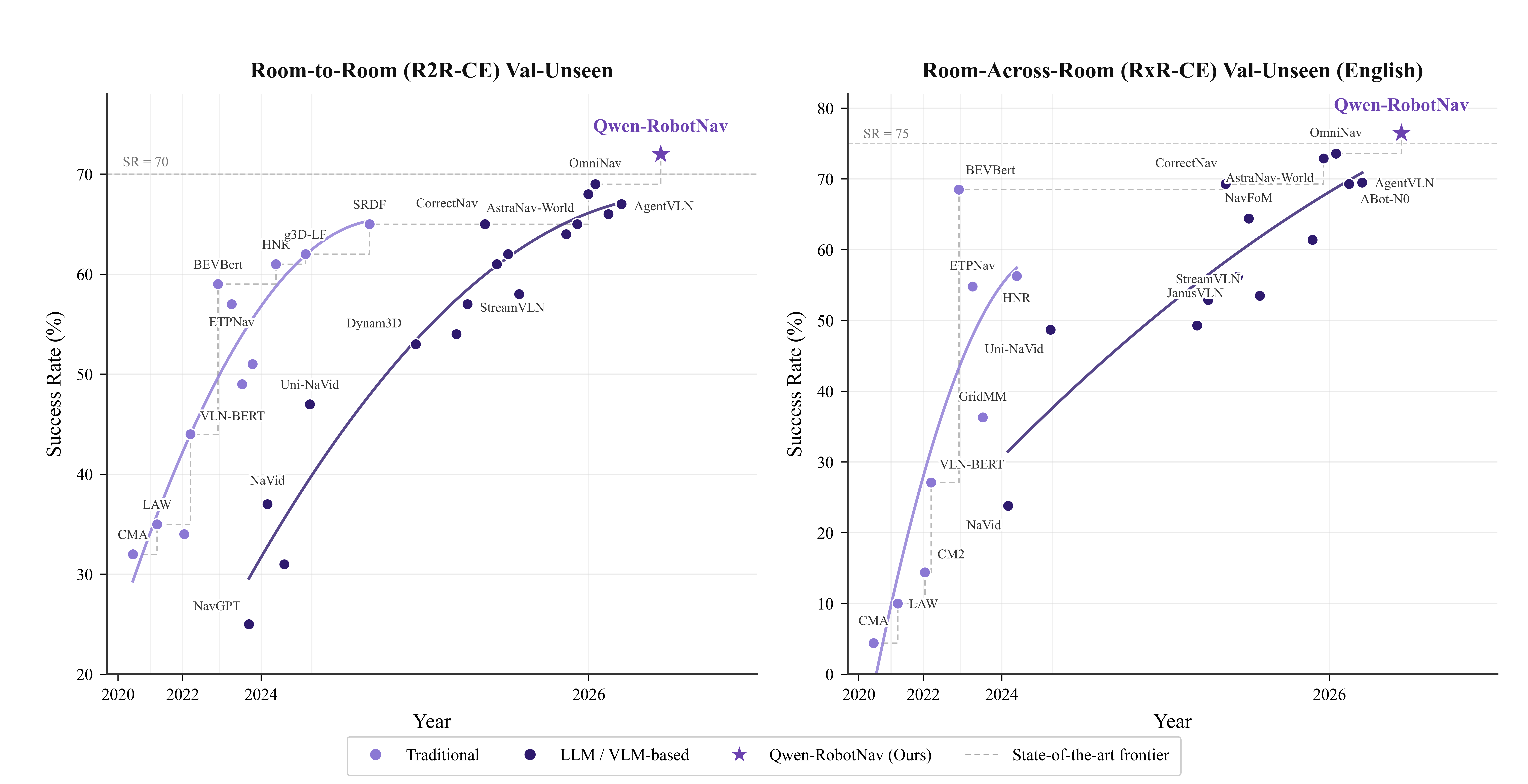
Qwen-RobotNav unifies five navigation tasks—instruction following, point-goal navigation, object search, target tracking, and autonomous driving—each demanding different visual memory strategies. Most models hardcode one strategy. Qwen-RobotNav exposes a parameterized interface: token budget, temporal decay, per-camera weights that a planner can reconfigure mid-episode.
Trained on 15.6 million samples with randomization across all parameters, it achieves 76.5% success on VLN-CE RxR, a benchmark for vision-and-language navigation in real-world environments, and 90% tracking on EVT-Bench, which evaluates an agent's ability to consistently follow moving targets.
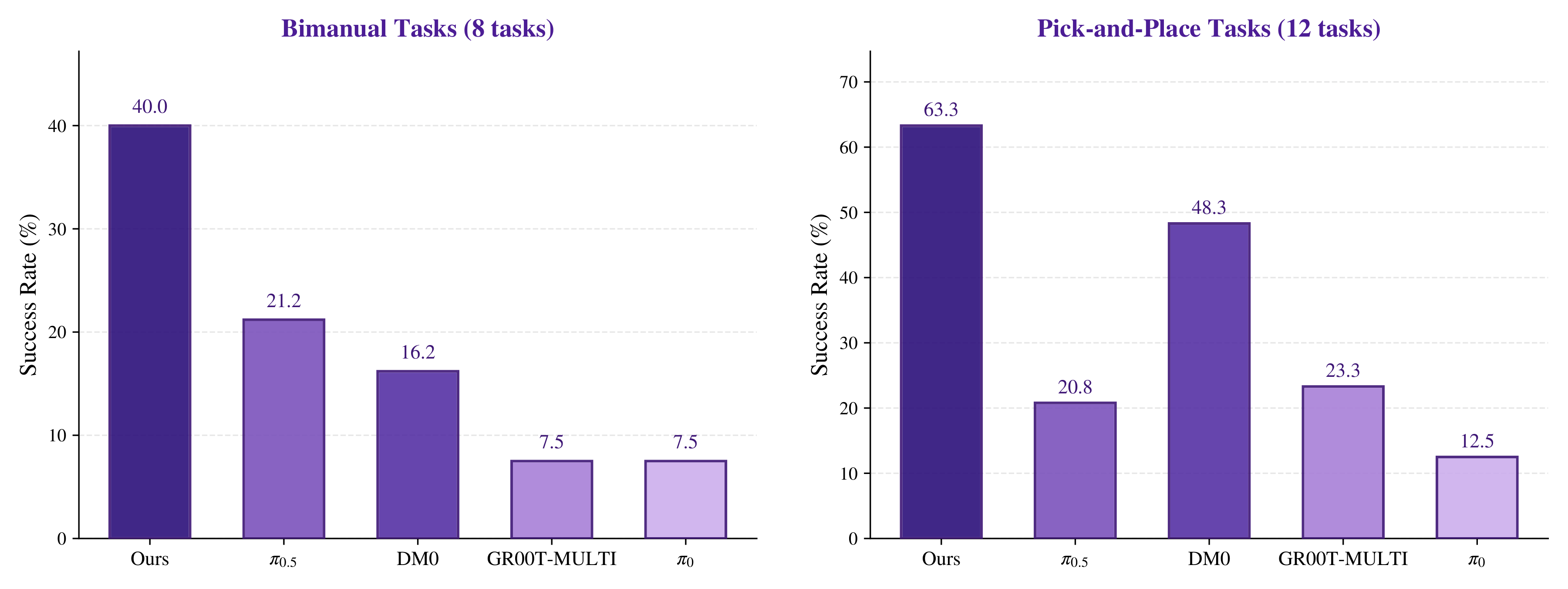
Qwen-RobotManip tackles one of the biggest challenges in robotic manipulation: different robots represent actions in fundamentally different ways. A Franka arm (a type of robot with seven axis of movement) operates through joint angles, while an ALOHA robot (a low-cost bimanual robot platform widely used in robotics research) represents actions through the position and orientation of its grippers (end-effector poses). Humanoids add another layer of complexity, using whole-body coordinates.
To bridge these incompatible action spaces, Alibaba synthesized approximately 38,100 hours of training data from open-source robot datasets and human videos—without relying on proprietary data collection. The model ranks first on RoboChallenge Table30-v1, outperforming previous approaches by 20%.
Qwen-RobotWorld is the most ambitious: a language-conditioned video world model treating natural language as a universal action interface. "Pick up the red cup and pour water on the flower" works whether the actor is a gripper, an autonomous vehicle, or a mobile navigation agent.
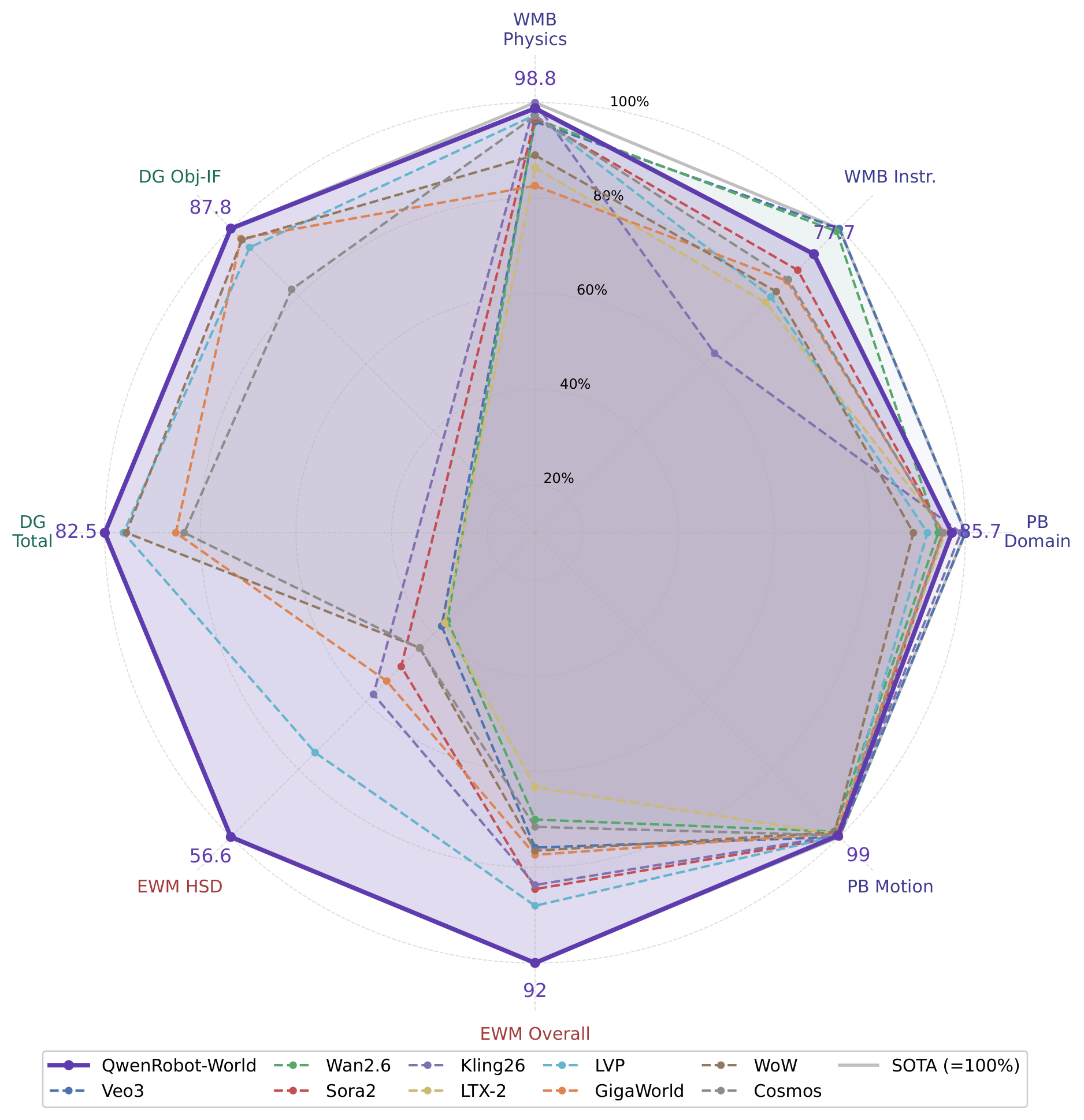
The Embodied World Knowledge corpus spans 8.6 million video-text pairs—200 million frames—across manipulation (5.9 million samples, 1,300+ skills, 20+ morphologies), autonomous driving (Waymo, NVIDIA PhysicalAI-AD, Bench2Drive), indoor navigation (VLNVerse), and human-to-robot transfer across 14 robot arms.
It ranks first on EWMBench and DreamGen Bench, two benchmarks that evaluate if world models predict and generate realistic physical environments. It also beats all open-source models on WorldModelBench and PBench, and scores perfectly on physics adherence: Newton's laws, mass conservation, fluid dynamics, gravity.
The ChatGPT of robots?
While Western labs (Google DeepMind, Nvidia, Figure, Physical Intelligence) pursue similar goals, most focus on navigation or manipulation, not a unified, composable suite. Alibaba's vertical integration from chips through applications means they control the full stack. The open-source foundation differentiates against competitors relying on private robot data.
There are some misconceptions that could be worth clearing: These are not robots but software models—brains, not bodies. They run on hardware from AgileX, Franka, Universal Robots, Unitree, and others.
Also, despite these being generative AI models for robots, these aren't LLMs like your typical ChatGPT. A language model predicts tokens. These models must understand physics, spatial relationships, and consequences of physical actions. A language model tells you a glass breaks if dropped. Qwen-RobotWorld predicts how it breaks—shatter pattern, fluid dynamics, secondary collisions. Qwen-RobotManip plans a grasp that prevents the drop entirely.
Don't expect to have your own housemaid robot anytime soon. The gap between a controlled demo of a robot placing fruit in a basket and a robot reliably working in your home is enormous. RoboCasa365, LIBERO-Plus, RoboTwin-Clean2Rand—these are simulation benchmarks. Real-world deployment introduces sensor noise, actuator drift, and the long tail of edge cases that have humbled every robotics effort in history, and Alibaba recognizes this.
The technical achievements are real, though. RobotManip's alignment-first approach solves a genuine bottleneck in cross-embodiment training. RobotNav's parameterized observation interface is a clever solution to the context-strategy problem. RobotWorld's language-as-universal-action-interface is the right abstraction for cross-domain world modeling.
Alibaba hasn't disclosed pricing, timelines, or which customers get access beyond pilot programs.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




