The AI transit station has solved the issue of model access, but it has also created new trust issues. The AI transit station evaluation framework, GatewayBench, has now opened its evaluation entry through the official website Check4U.ai, attempting to transform model authenticity, billing transparency, cache isolation, and actual costs into verifiable metrics. GatewayBench opens public evaluation lists for API transit stations, aggregation gateways, and model service providers, hoping to gain more market trust for honest delivery with verifiable audit data.
Written by: Eloise
Is the GPT-5 or Claude that enterprises spend a fortune on each month really the official original model?
To cope with the complex geopolitical restrictions, corporate compliance processes, and payment thresholds of AI large models, more and more research and development teams are choosing a shortcut: third-party AI transit markets (Shadow API). This alternative seems extremely tempting, allowing developers to use mainstream models like GPT and Claude with a lower access threshold, providing an experience close to the official API, while also filling gaps that official channels cannot cover to some extent.
However, behind this seemingly convenient "door" lies a bottomless black box.
In March 2026, an audit data released by Germany's CISPA Helmholtz Center for Information Security revealed a chilling truth: At least 187 top academic papers globally have used AI large model transit APIs (Shadow APIs) for research (62% of which have been accepted by top academic conferences such as CVPR and ICLR), but because these transit gateways covertly replaced, quantified, or downgraded the underlying models, a significant number of research results face the risk of being irreproducible.
The "disaster" in academia is a "time bomb" that could erupt at any time in corporate production environments.
The current large models are no longer experimental products confined to laboratories; these core infrastructures are being deeply integrated into customer service centers, code generation pipelines, agent workflows, and risk control business chains. Facing systems that support critical business, transit service providers typically throw enticing selling points such as "original model," "low price," "high speed," and "support for caching" to enterprises.
However, the problem is that traditional evaluation tools cannot detect the trickery within the black box. Existing benchmarking software primarily focuses on the speed and price on the outside of the interface, assuming that the data returned by the gateway is entirely real and credible. Conventional evaluations simply cannot answer the following core business security questions:
- When business encounters peak traffic, has the high-priced model been quietly "swapped" or "downgraded"?
- Behind the so-called high speed and low cost, are there falsely reported tokens hidden in the bills, and are failed requests being forcibly charged?
- Is the cache discount claimed by the gateway genuinely returned to the enterprise, and are the cross-account privacy data strictly isolated?
The AI transit API has indeed addressed the barrier to accessing large models, but it has also created a new crisis of trust. Without clarifying these invisible backend paths, making purchasing decisions based solely on surface unit price and speed is akin to running blindfolded. Breaking the black box era and making honest delivery a market advantage is of utmost importance for the current AI supply chain.
Unveiling the Black Box: The "Three Hidden Rules" of the AI Large Model Transit Market
Why can't existing conventional benchmarking software detect issues? Because traditional evaluation tools only stay on the interface's exterior, blindly comparing response speed and surface pricing. Meanwhile, behind the extremely opaque backend of the gateway, vendors are exploiting this information asymmetry, turning complex technical means into covert arbitrage tools.
A deep analysis of the current AI large model transit market reveals three highly covert "hidden rules" that are eroding the business quality and budget of enterprises:
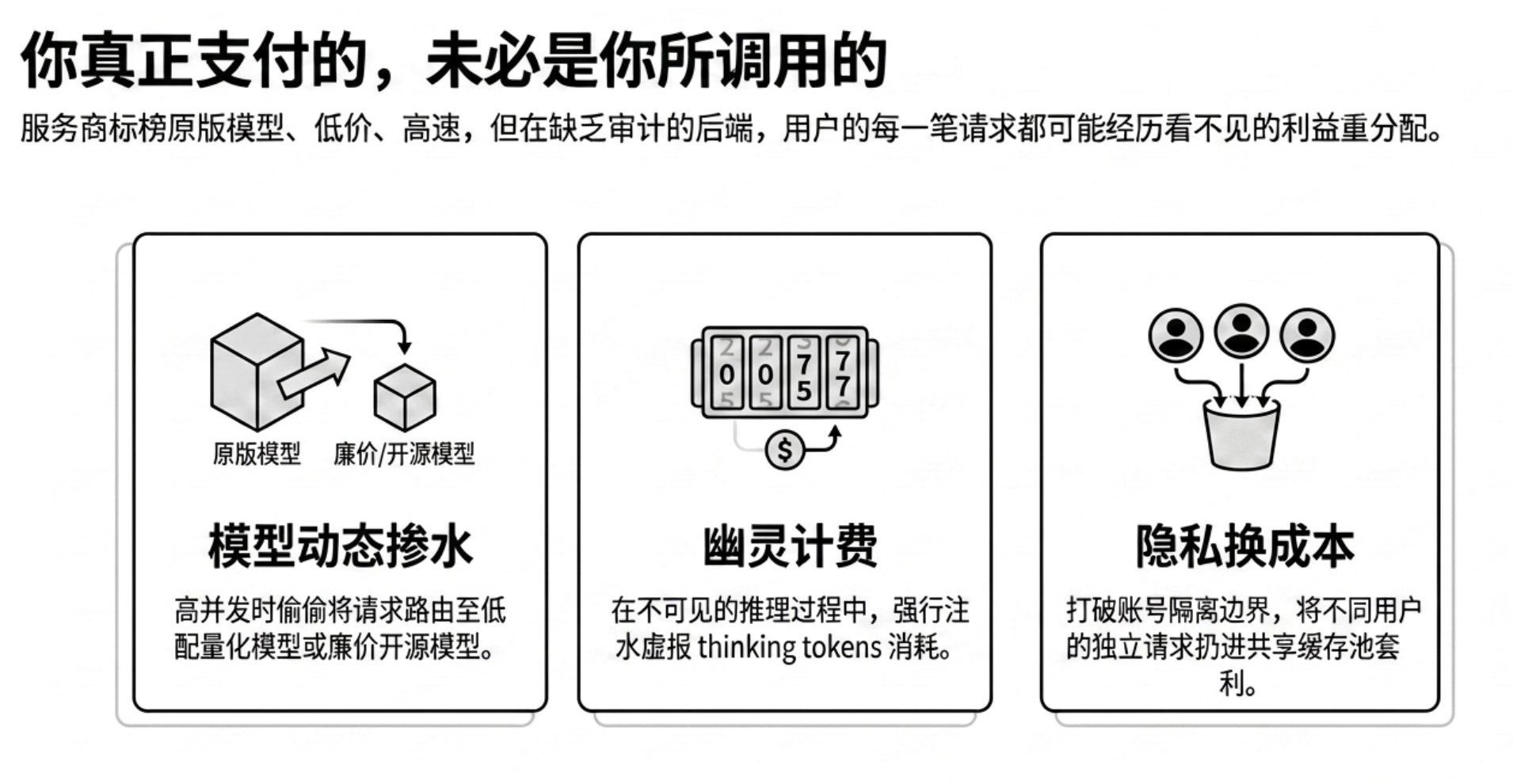
Hidden Rule One: Dynamic Model Watering Down
In the gray transit market, the hardest arbitrage method to detect is the dynamic replacement of models.
Many service providers, when faced with conventional evaluation tools or low system traffic, will correctly invoke the official original models. However, once they encounter high-concurrency business peaks or find themselves in blind spots of monitoring, these gateways will secretly switch the backend to lower-spec quantized models or weaker distilled versions, or even to cost-effective open-source models with the same name.
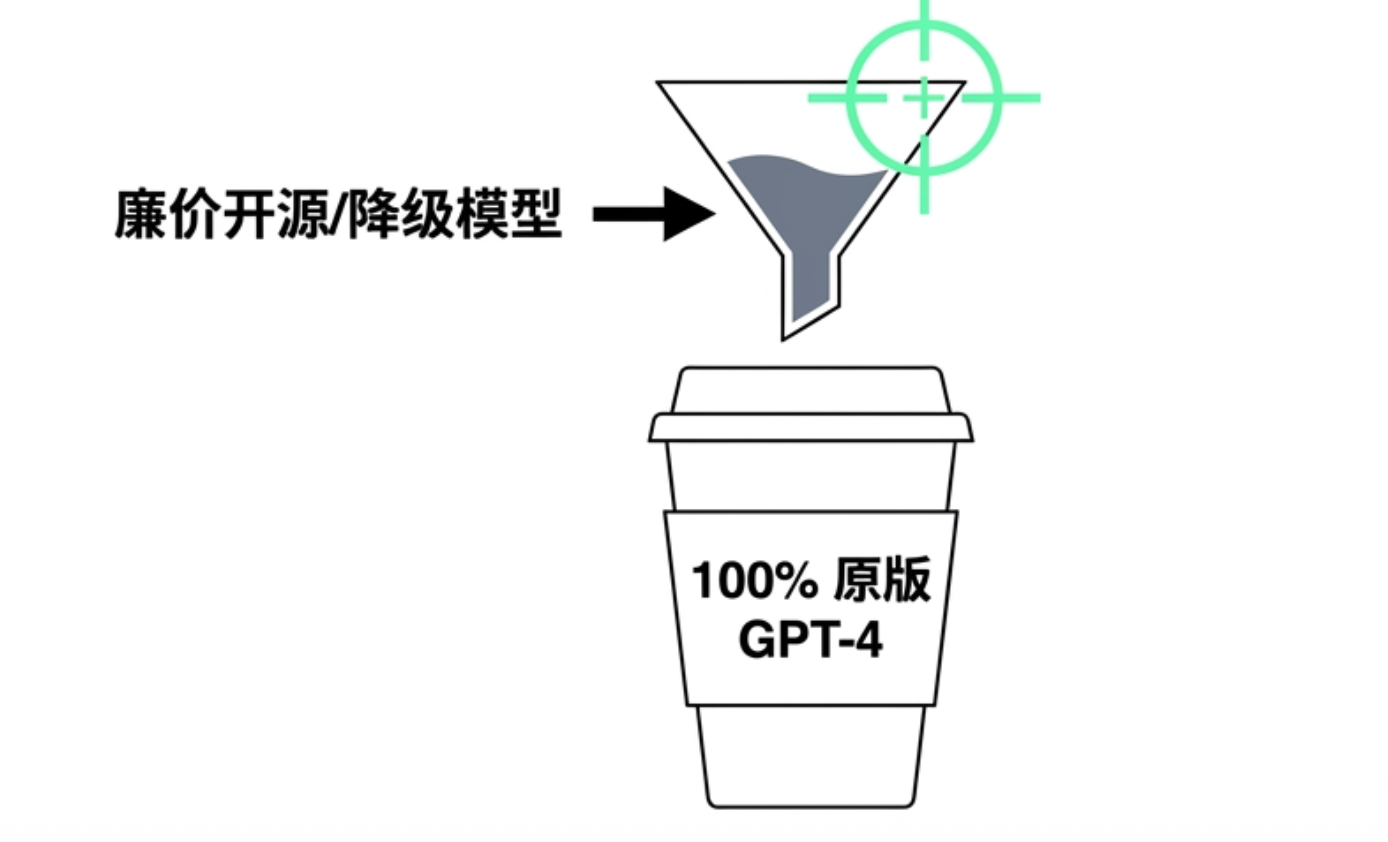
Although from the surface, the interface still timely outputs text, due to the tampering of the underlying probability distribution, the actual output quality obtained by enterprises has long been out of alignment with the metrics initially promised by vendors. This behavior of swapping models exposes the accuracy of customer service replies and the quality of code generation to the risk of uncontrollable downgrades at any time.
Hidden Rule Two: Invisible Bills (Hidden Billing and Privacy Exposure)
With the popularization of reasoning models, a more difficult-to-verify cost has begun to appear in large model bills: thinking tokens. Since this part of the thought process is assumed to be invisible, it becomes challenging for purchasers to judge whether the reasoning consumption reported by the platform is real, leaving room for bad gateways to inflate costs.
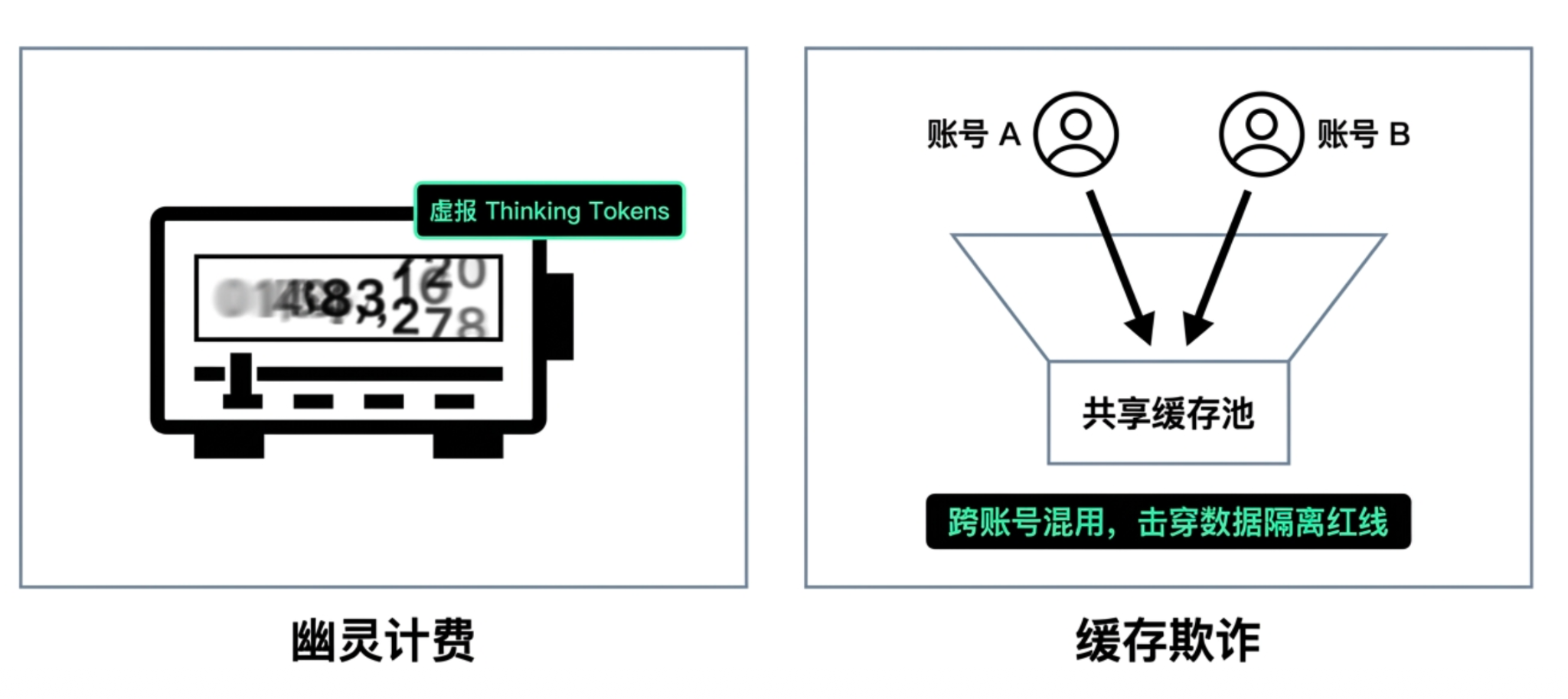
Even more frightening than inflated bills is uncontrollable cache fraud. Some service providers, while displaying signs of cache hits on the bills, fail to genuinely return real discounts to enterprises, turning cache optimization into a mere numerical game. Furthermore, to forcibly increase cache hit rates to reduce their own costs, certain gateways may forcefully shove different enterprises’ prompts into the same shared cache pool. This directly impacts the data isolation boundaries of multi-tenant systems, exposing enterprise core business data and commercial privacy to risks of cross-account usage.
Hidden Rule Three: False "Lowest Price on the Internet" (Carefully Designed Financial Traps)
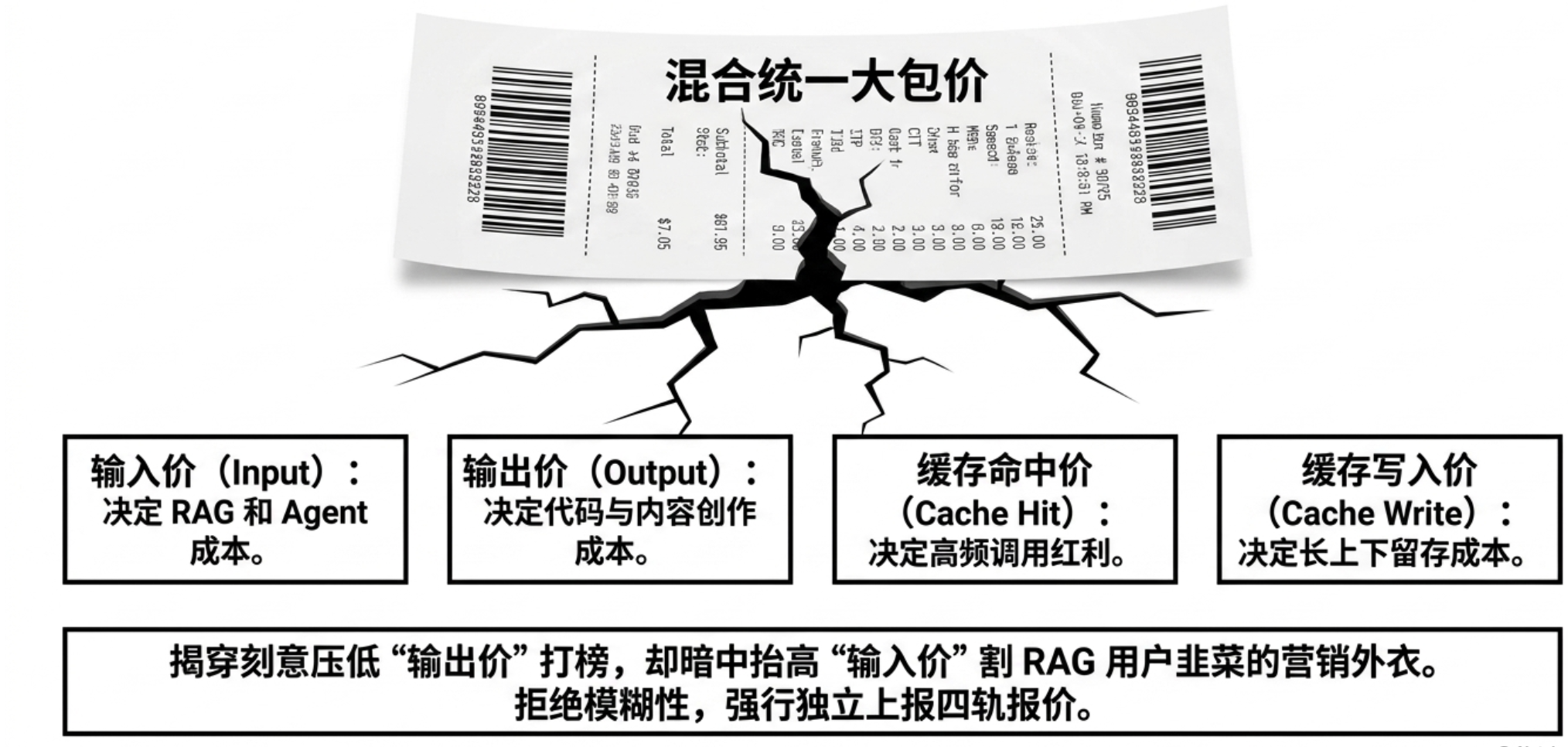
When procuring large model APIs, "lowest price on the internet" often draws the most attention. However, in actual operations, nominal unit prices do not equate to real costs. Particularly in the transit gateway market, input, output, cache hits, and cache writes are often wrapped into a comprehensive price that seems easy to compare, but once entering actual business load, it can easily become distorted.
This distortion arises from the fact that there is no fixed input-output ratio when enterprises call large models. RAG, long document analysis, and complex agent workflows typically entail high input and low output; code generation and content creation, on the other hand, may result in high output costs. If a platform only showcases a mixed unit price, it becomes challenging for the purchaser to discern where the costs are actually incurred. A platform that appears to have a low price may optimized external quotes by lowering output unit prices while raising input, cache write, or other less conspicuous pricing items. Ultimately, the real bill for certain high-input scenarios may far exceed expectations.
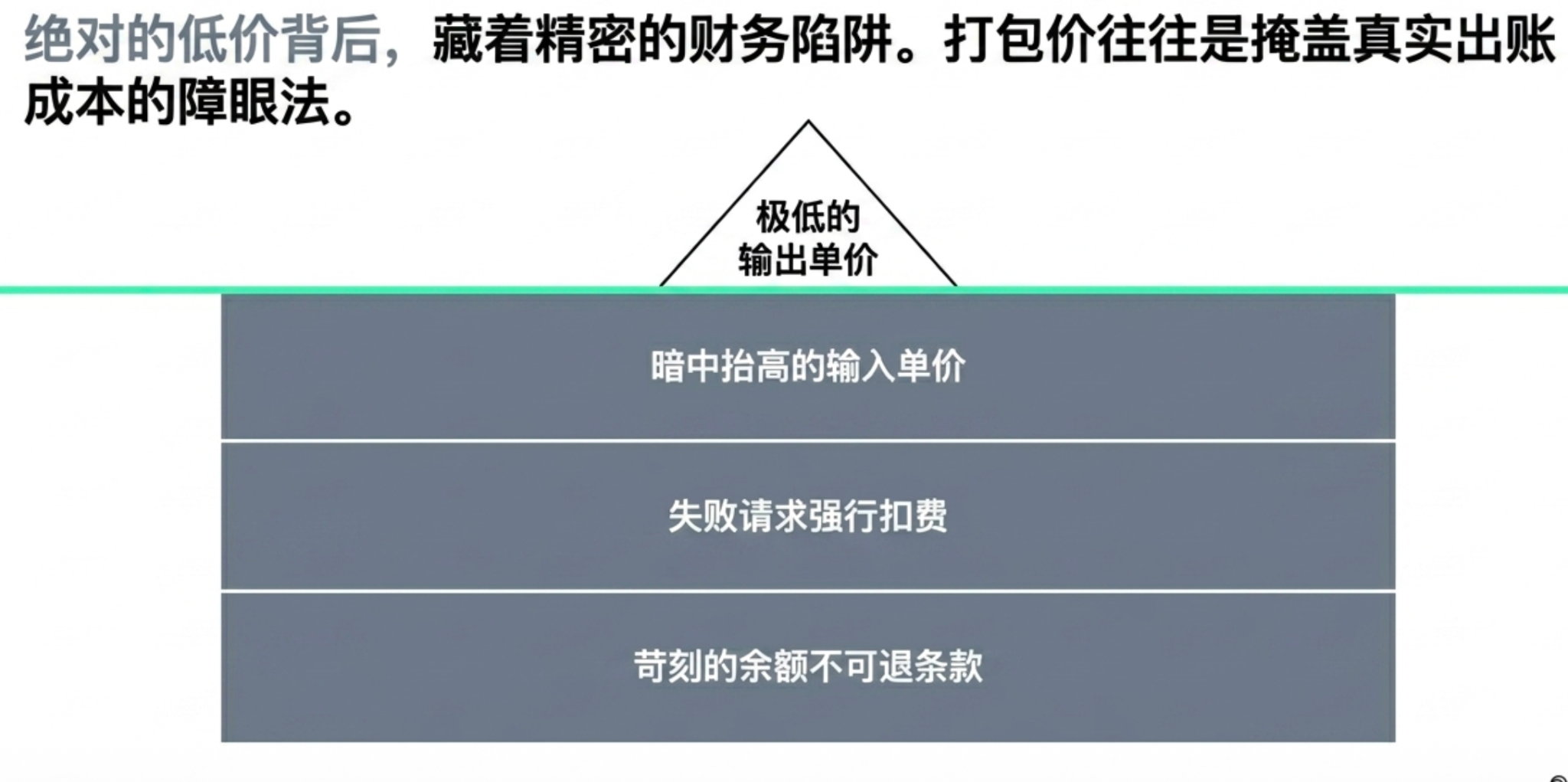
Moreover, hidden costs lurk within various inconspicuous terms. For instance, when the system experiences a flow disruption, timeout, or 5xx error, failed requests will still be forcibly billed; low unit prices often come bundled with high recharge thresholds, non-refundable terms and conditions, as well as opaque foreign exchange and payment channel fees. When all these financial frictions accumulate, the actual billing cost per million tokens that reaches the enterprise's accounts often is several times higher than the nominal prices advertised on the web.
GatewayBench: A Professional Audit Framework for Large Model Gateways
Faced with the highly opaque backend of gateways, traditional speed testing and benchmarking tools exhibit evident limitations. These indicators may compare response speed, model coverage, and nominal pricing, but they struggle to address more critical questions: Are the models actually called by the gateway consistent with the promises, are the bills transparent, and is the cache and data isolation credible?
In this context, the GatewayBench audit evaluation framework has officially launched and opened the evaluation entry through the official website Check4U.ai. As an open-source audit framework for large model gateways, GatewayBench does not merely consider speed and surface prices; instead, it breaks down gateway evaluations into three dimensions: credibility, economy, and performance, utilizing a weight system of 40% credibility + 40% economy + 20% performance.
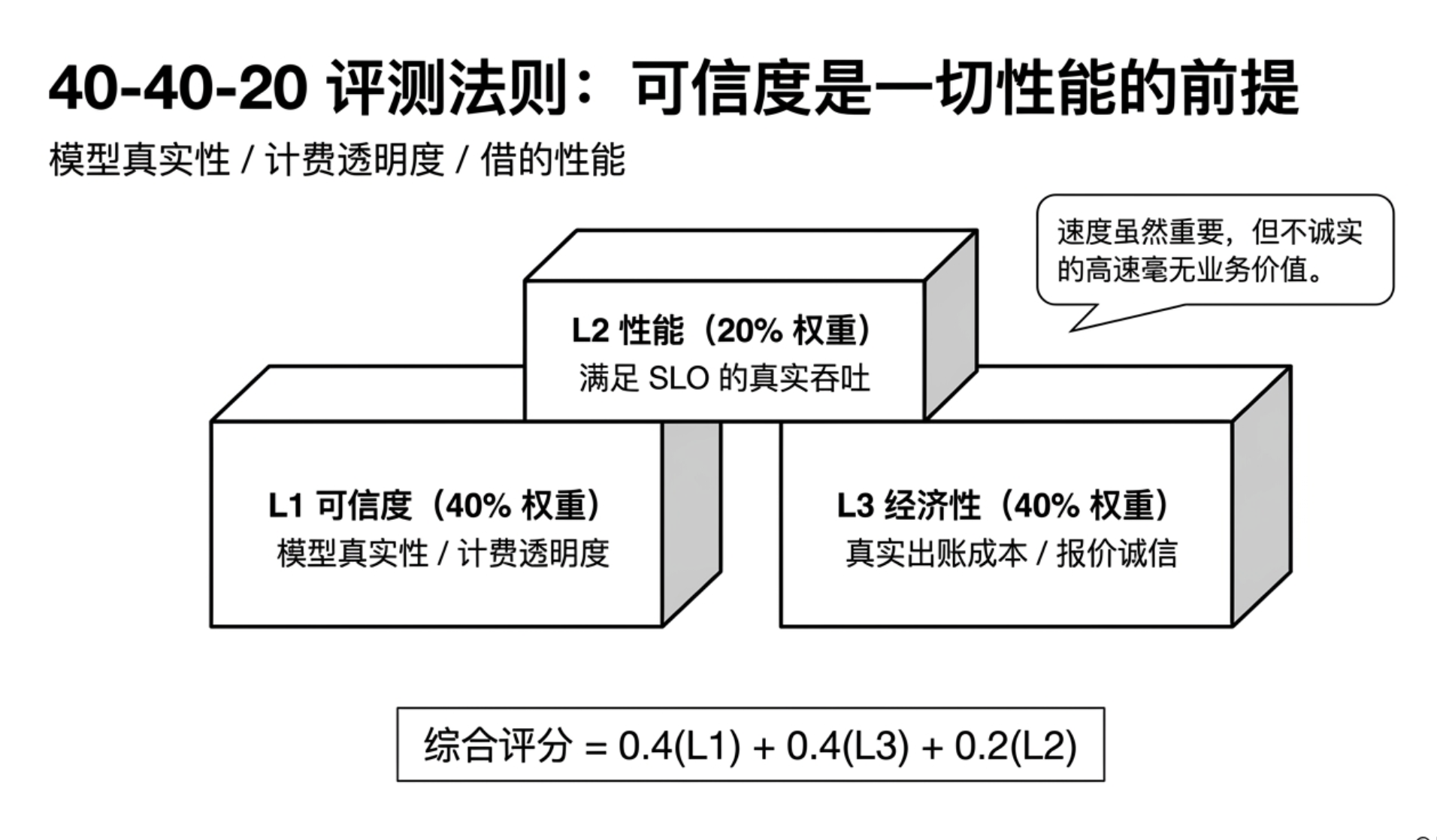
This weighting reflects GatewayBench's fundamental judgment: In the scenario of AI large model transit APIs, credibility and actual costs take precedence over speed. A gateway must first prove the authenticity of its models, the transparency of its billing, and the explainability of its costs before it qualifies for performance competition.
In pursuit of this goal, GatewayBench provides three core audit capabilities:
L1 Credibility Audit: From Platform Statements to Verifiable Trust
In GatewayBench's scoring system, L1 credibility accounts for 40% of the weight. The logic behind this design is: In the scenario of AI large model transit APIs, while speed and price are certainly important, if the model is not authentic and the bill is not transparent, other indicators lose their discussion basis.
The core risk of third-party large model transit gateways comes from the invisible processes behind successful calls. Normal returns on the interface level only indicate that the requests have been processed, but cannot prove that the source of the model, billing processes, and cache handling align with the platform's commitments. In the past, these links lacked external verifiable evidence and were difficult to undergo systematic audits.
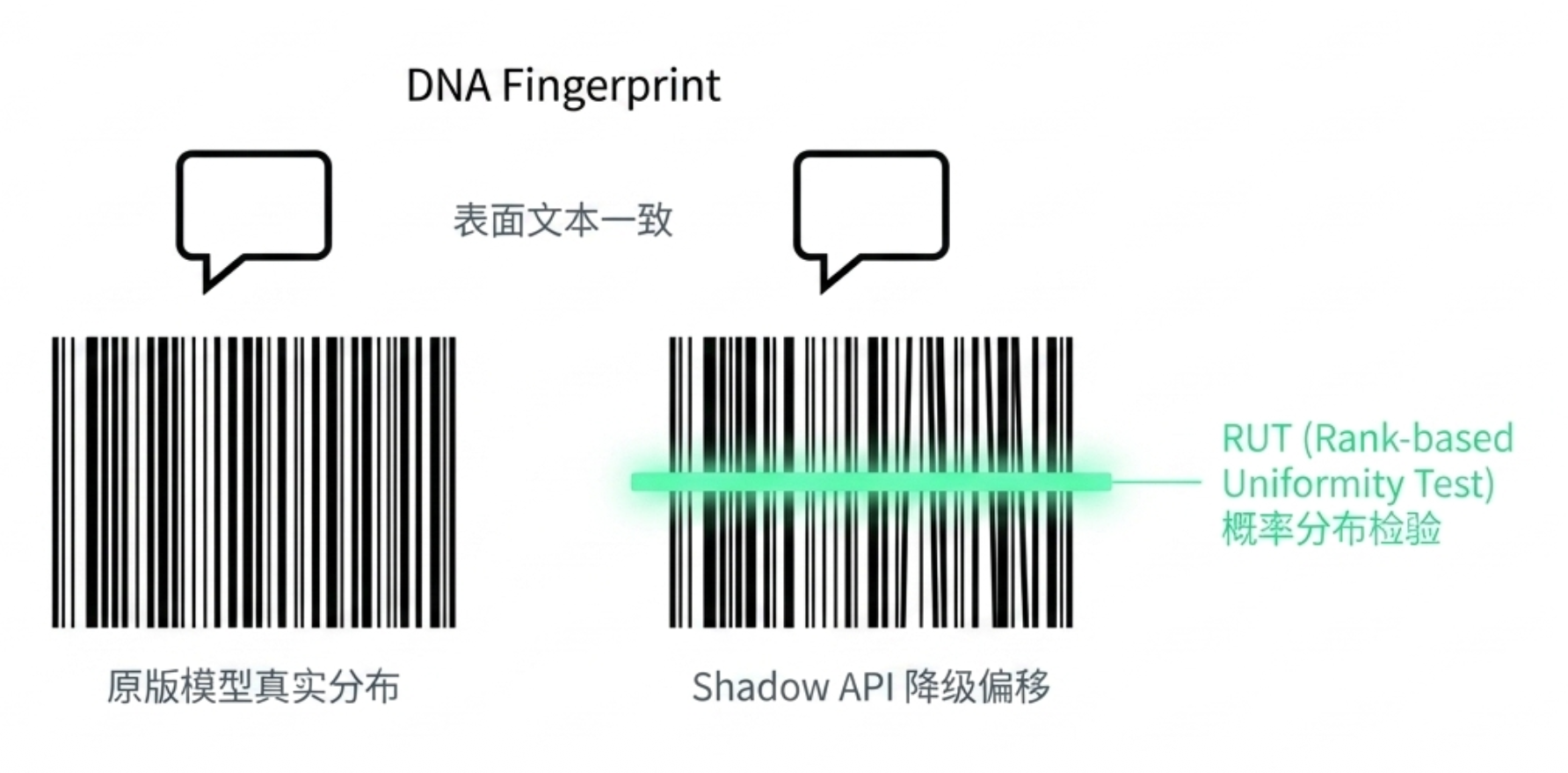
The L1 dimension of GatewayBench aims to transform these vague doubts into verifiable engineering signals. By breaking down credibility into three questions: Is the model authentic, is the billing transparent, and is the cache credible, it observes what exactly happens inside the gateway's black box through statistical tests, cryptographic structures, and latency fingerprints.
Regarding model authenticity, GatewayBench introduces the RUT (Rank-based Uniformity Test) algorithm to examine the position of output tokens in the probability ranking of reference models. Different models may generate similar texts, but token probability distributions are harder to disguise. If quantization, downgrading, or replacement occurs in the backend, distribution shifts will leave traces. Simultaneously, GatewayBench can also combine Logprob Tracking, requesting only one output token under a fixed prompt, and tracking whether its log probability shows stable shifts over time. This provides a lower-cost signal for continuously monitoring model updates, fine-tuning, quantization adjustments, or routing switches.
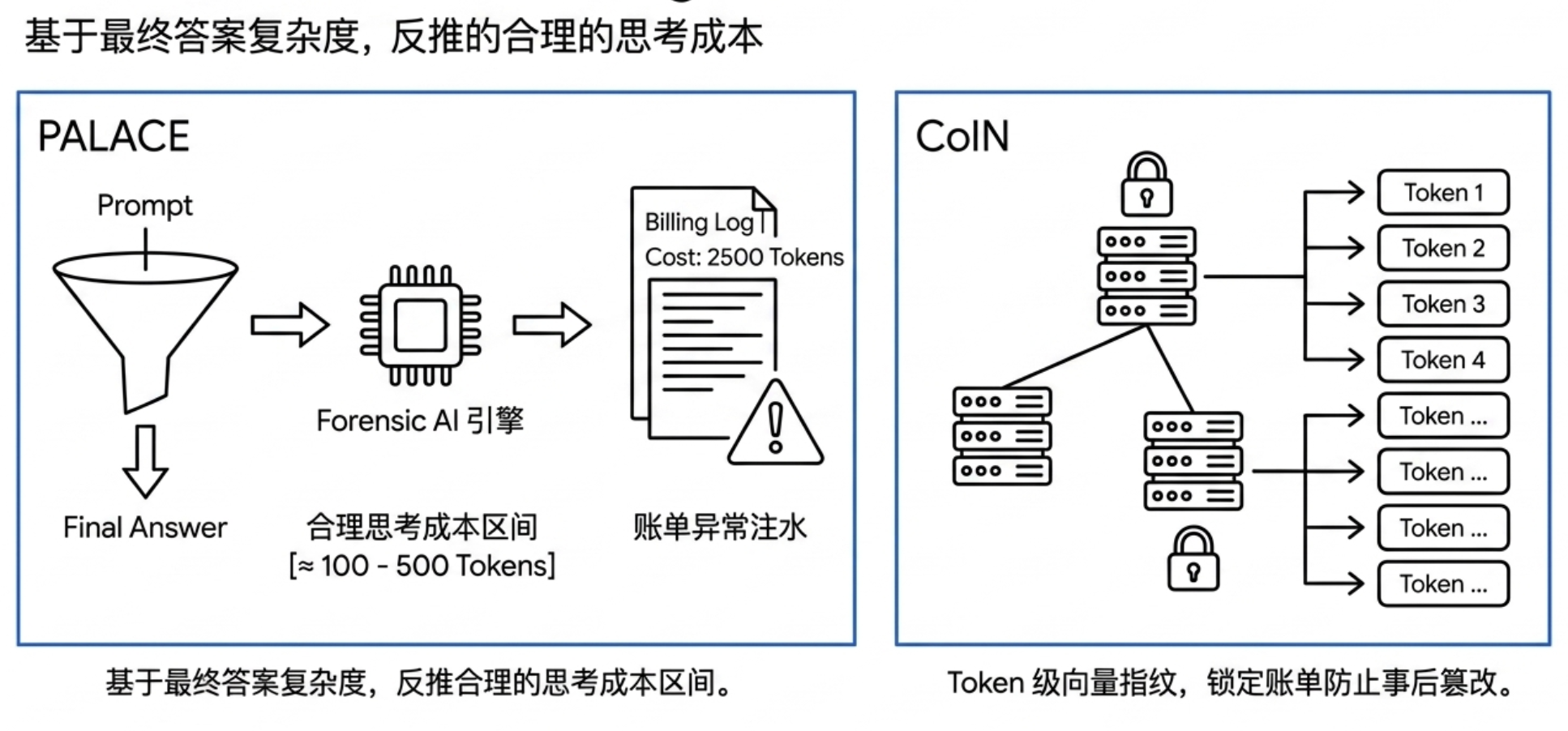
In terms of billing transparency, GatewayBench estimates a reasonable range for thinking tokens through PALACE to identify anomalies in high reporting within reasoning models; simultaneously leveraging verifiable structures like CoIn, allowing billing records to have stronger traceability and tamper resistance.
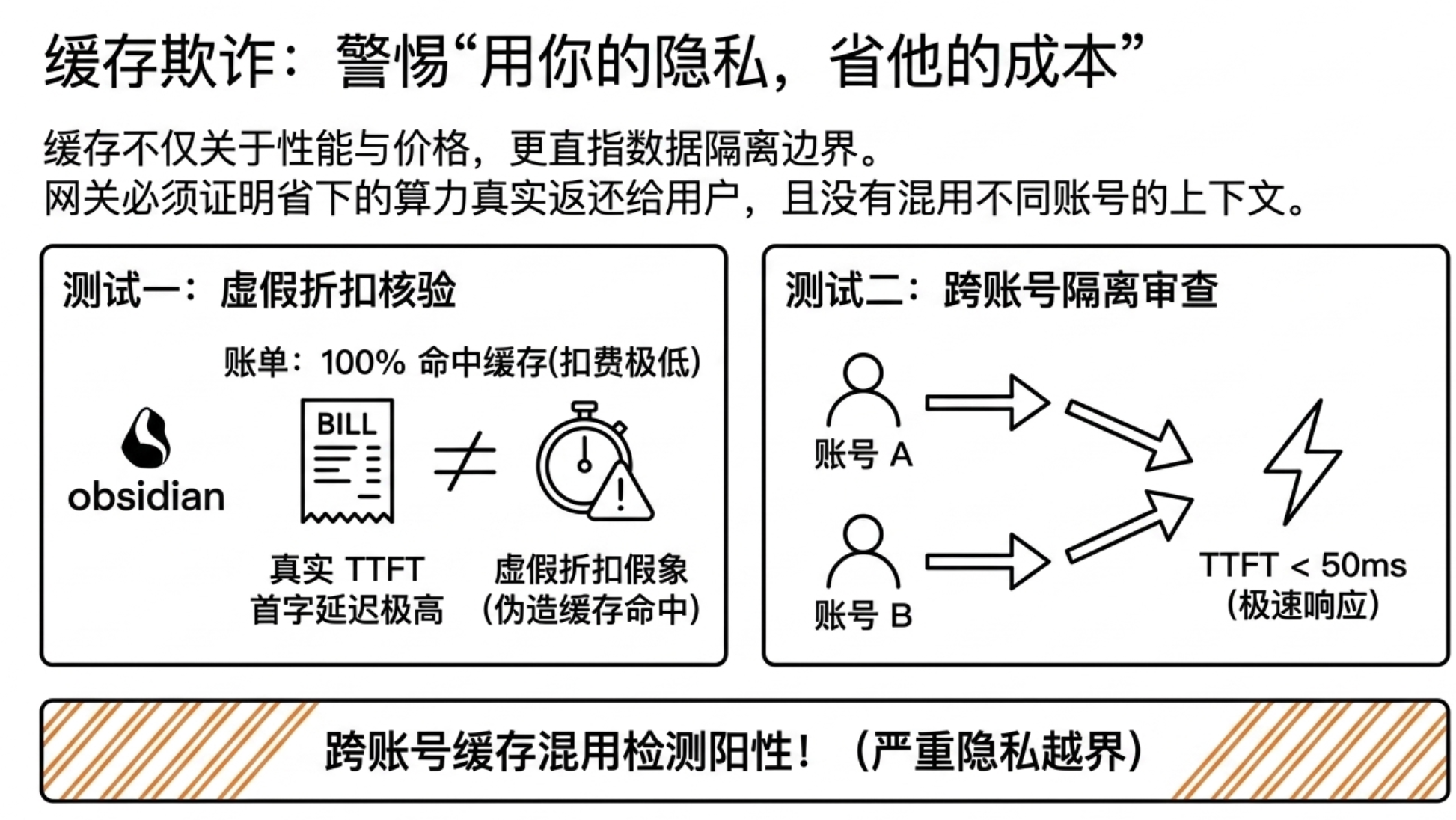
For cache credibility, GatewayBench assesses whether cache hits are real through latency fingerprints, and identifies potential tenant boundary issues using cross-account isolation tests. If the bill shows cache hits, but TTFT does not correspondingly decline, the discount may only exist on paper; if abnormal cache reuse occurs between two independent accounts, it may indicate risks in cache isolation.
Through these methods, GatewayBench transforms what could only be judged by instinct and suspicion within the black box into measurable, verifiable, and comparable signals, achieving truly "verifiable trust."
L2 Performance: Extreme Load Testing, Detecting Stable Delivery Capability Under Extreme Pressure
Only gateways that have passed the L1 credibility audit are eligible for comparison of performance and cost-effectiveness.
In the ecosystem of large model infrastructure, performance has always been the metric that transit stations and aggregation API vendors prefer to emphasize. Statements like "the fastest on the internet" or "single concurrency 150 tokens/s" are common. However, GatewayBench maintains significant restraint in the weight allocation of performance in its indicator system: L2 performance accounts for only 20% of the overall score.
The reason is simple. Speed is certainly important; it determines whether the system has basic usability and can eliminate services that frequently lag or have long-tail loss of control. But speed should not outweigh credibility and economy. A gateway, even if it runs fast, cannot become a trusted enterprise-level infrastructure if there are model swaps, bloated bills, or opaque caches.
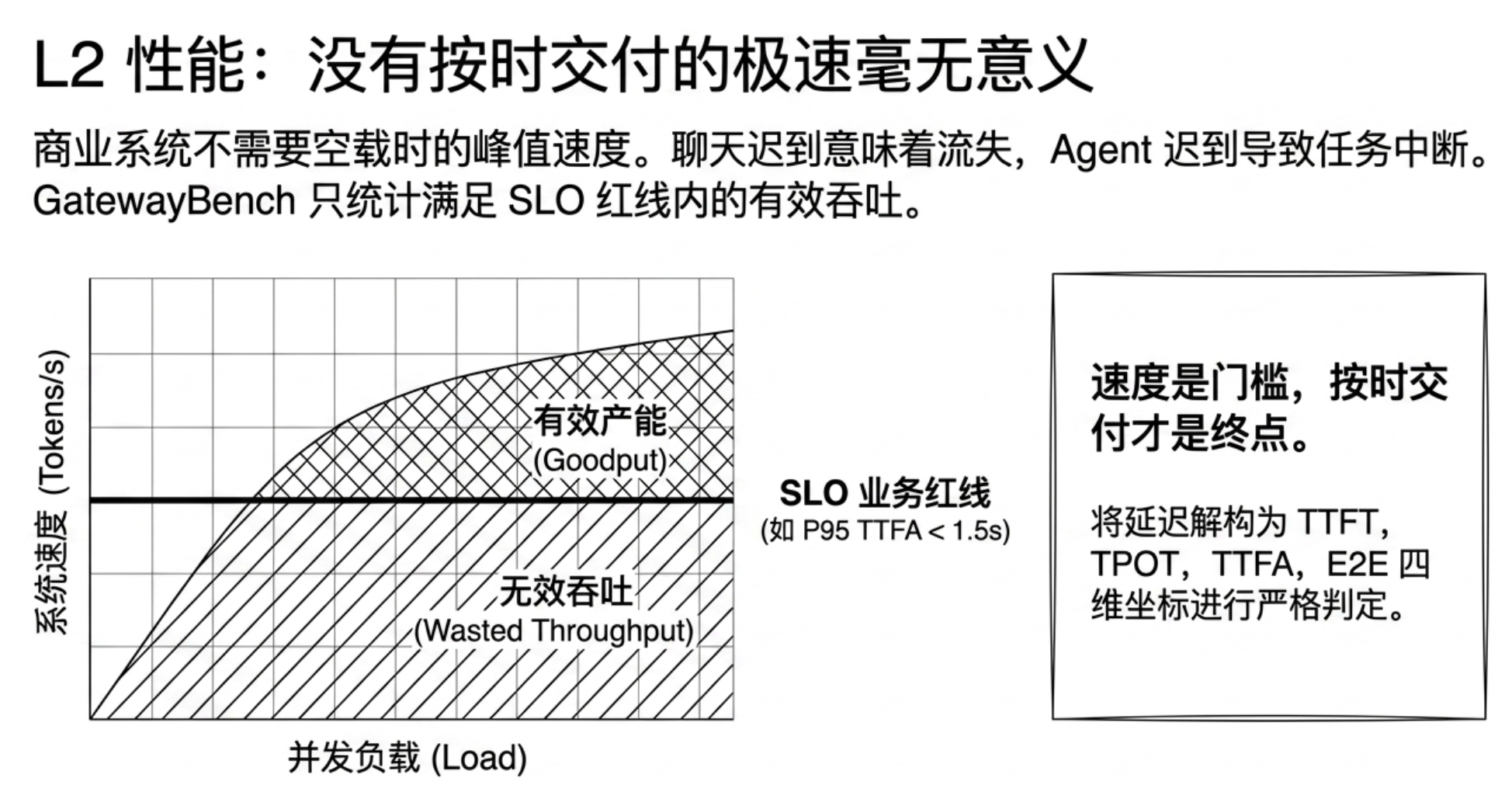
Therefore, GatewayBench does not chase single-point peaks in the L2 performance dimension, but instead breaks performance down into problems closer to production environments: latency affects how long users wait, goodput measures how much effective capacity can still be delivered within the latency red line, and long context tests observe how systems degrade under heavy loads.
This design is premised on the principle that performance is a threshold, but by no means a destination. What enterprises truly purchase is the ability to deliver steadily, on time, and predictably under trustworthy premises.
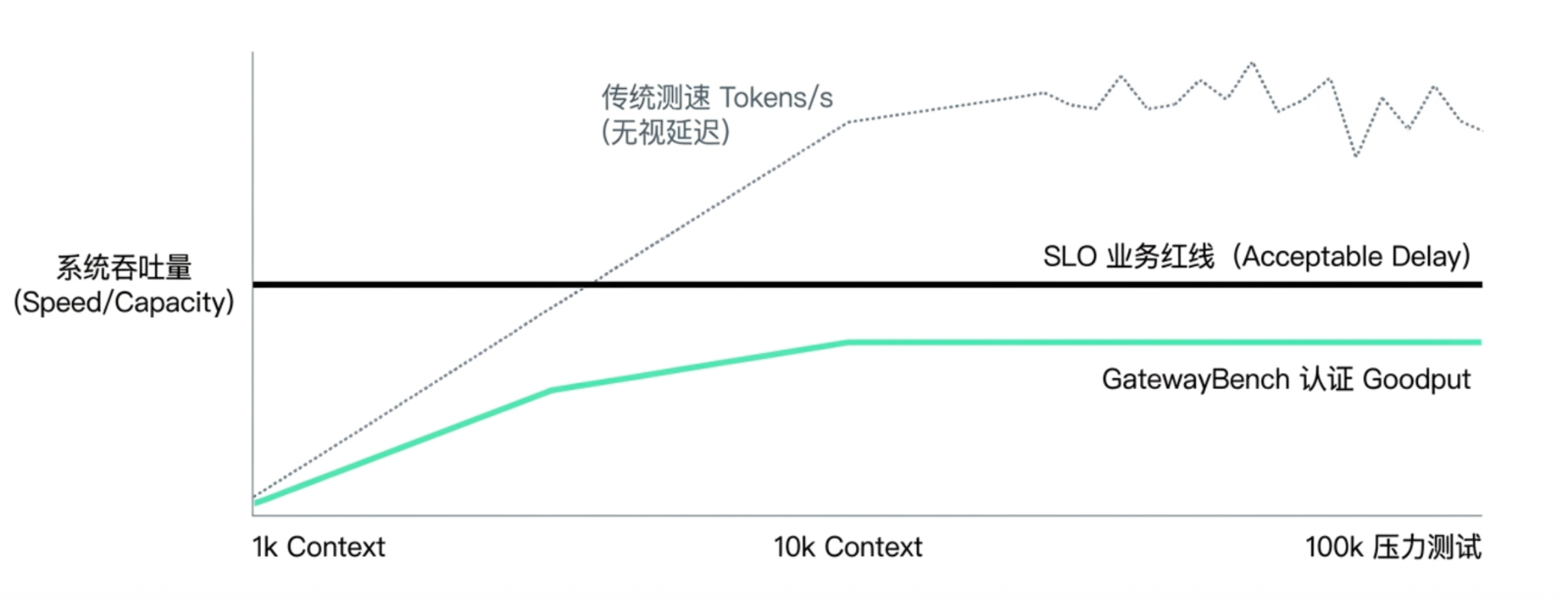
In commercial applications, the peak speed when the system is idle offers extremely limited reference value. GatewayBench rejects simply competing on throughput (Tokens/s), but introduces SLO (Service Level Objective) as a business red line. Enterprises can stipulate, for example, that P95 TTFA must be less than 1.5 seconds, P95 E2E must be less than 8 seconds, and streaming output should not exhibit significant jitter. Goodput builds on this red line: only the throughput delivered under the condition of meeting the SLO counts as effective capacity (Goodput).
To test the real scheduling levels of transit gateways, GatewayBench will implement ultra-long context stress tests at the 100k level. This test aims to observe whether the system maintains stable degradation under heavy loads or experiences long-tail loss of control or even invisible degradation. What enterprises are purchasing is this stable delivery capacity that can still be delivered on time under extreme business pressure.
L3 Economy: Penetrating the Bill Mist, Restoring "The True Billing Cost per Million Tokens"
Price is the most sensitive variable when enterprises procure large model transit APIs, and it is also the one most easily repackaged. The unit price displayed on the webpage appears clear, but once involved in production calls, costs can be influenced by input-output ratios, caching rules, failed requests, recharge terms, exchange rates, and payment channels.
Therefore, GatewayBench assigns a 40% weight to L3 economy, paralleling L1 credibility as a core dimension, focusing not on the nominal unit prices on the price list but on True Cost per 1M Tokens, which reflects the actual cost enterprises pay under genuine business loads.
In terms of explicit pricing, GatewayBench breaks down input price, output price, cache hit price, and cache write price to avoid a single mixed price concealing cost structures. The input-output ratio varies significantly across different business scenarios; RAG, long document analysis, and agent workflows usually entail high input and low output, while code generation and content creation may incur higher output costs. Focusing only on a composite price can easily misjudge actual expenditures.
Regarding relative to official prices, GatewayBench introduces a price ratio of "platform price / official price" and combines the vendor roles to judge whether the premium is reasonable. Aggregation routing, multi-channel disaster recovery, and unified billing can explain certain service premiums; simple forwarding-type proxies should be closer to official prices. Low prices do not necessarily imply advantages, and high prices also require corresponding real engineering value.
The GatewayBench framework will also delve into the hidden frictions behind the bills: whether failed requests were forcibly billed, whether the claimed cache discounts were genuinely returned, and whether the funding accounts have strict consumption restrictions. Through layer-by-layer dissection, GatewayBench ultimately restores the true billing cost stripped of all marketing packaging for enterprises.
Join GatewayBench: Let Honest Delivery Gain Market Returns
The API transit market will not disappear due to controversy. As long as model access still presents regional, payment, risk control, and compliance differences, third-party gateways will continue to meet real demands. Since this is an inescapable reality, the goal of GatewayBench is to make this transit station more transparent, more trustworthy, and more sustainable.
The current biggest contradiction in the API transit market is that information asymmetry is amplifying the effect of "bad currency driving out good." Some service providers can gain short-term traffic through model swaps, billing packaging, cache arbitrage, or low-price marketing; meanwhile, vendors that adhere to original factory transmission, transparent billing, and stable services find it even harder to stand out in the noisy market due to the constraints of real costs.
This is not a structure that the infrastructure market can rely on for a long time. Any mature supply chain needs a market-based trust mechanism grounded in metrics: good services should be seen, stable commitments should be recorded, and honest delivery should gain more traffic, more trust, and higher quality procurement budgets; while service providers that rely on information asymmetry to profit in the long term should bear higher trust costs.
Based on the vision of reshaping industry trust consensus, the AI large model transit evaluation platform Check4U.ai announces its official launch and issues an open invitation to major API transit stations, aggregation routing platforms, and model service providers worldwide: join the GatewayBench public evaluation list.
GatewayBench aims to transform the quality of gateway delivery into observable metrics through a unified, open-source, reproducible, and comparable audit framework, making the market no longer rely solely on slogans and vague price lists to judge services. For quality service providers, this is an opportunity to use data to prove technological integrity: to demonstrate what they genuinely deliver, how they bill, and whether they can provide stable service. For enterprise purchasers, GatewayBench can also serve as an important reference before accessing external APIs, helping identify real costs, model purity, cache isolation, and performance records.
A healthy large model gateway market should not allow genuinely good service gateways to be overshadowed by low-price marketing. GatewayBench is committed to becoming part of this credit infrastructure, allowing honest delivery to gain market returns, benefitting end-users from transparent competition, and driving the entire industry towards a more verifiable and accountable AI infrastructure market.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







