

CoinW Research Institute
Abstract
Gradients is a decentralized AI training subnet built on Bittensor (SN56), with the core mechanism transforming model training from complex technical processes into a market-driven collaborative network process through "task publishing, miner competition, validation selection," etc. Architecturally, it integrates AutoML and distributed computing power, forming a training market centered on incentive mechanisms, which not only lowers the entry barrier for AI usage but also enhances computing power utilization efficiency. From an ecological and data performance perspective, Gradients has completed the basic network infrastructure, but currently, the incentive weights and capital inflow are relatively limited. Gradients complements the training infrastructure within the TAO ecosystem and explores the new paradigm of "market-driven AI optimization," which has long-term potential to develop into an important entry layer for decentralized AI training.
1. Starting from Web2 AutoML: The Current Status and Limitations of AI Training
1.1 What is AutoML
In traditional understanding, training an AI model is considered a high-barrier task that requires engineers to handle data, select models, repeatedly tune parameters, and evaluate results, making the entire process complex and time-consuming. The emergence of AutoML (Automated Machine Learning) essentially automates these cumbersome steps. It can be understood as a "tool for automatic model building": users only need to provide data and specify their objectives, such as classification, prediction, or recognition, while the system automatically completes the remaining processes, including model selection, parameter tuning, and training optimization. This gradually transforms AI from a tool of a few specialized engineers into an ability that ordinary developers and even enterprises can use, marking an important step towards the popularization of AI.
1.2 Core Limitations of Traditional AutoML
Currently, mainstream implementations of AutoML are primarily concentrated on cloud vendor platforms, such as Google Vertex AI and AWS SageMaker, which provide "AI training as a service." Although Web2 AutoML significantly lowers the entry barrier for AI usage, its underlying model still has obvious limitations. First, there is the issue of centralization—computing power, pricing, and rules are all controlled by the platform, with users having a strong dependency on a single service provider and lacking bargaining power. Secondly, the costs are high and opaque; the GPU resources relied upon for AI training are mainly concentrated in the hands of cloud vendors, and the pricing mechanisms lack market competition. More critically, the optimization efficiency has an upper limit. Traditional AutoML is essentially still "a system helping you find the optimal solution"; regardless of how complex the system is, it fundamentally belongs to optimizing a single technical path. Its exploration space is limited, making it difficult to concurrently try multiple completely different approaches. Thus, current Web2 AI training is a "closed system," where model training, optimization, and resource scheduling occur within an environment controlled by a single platform. While this model is efficient, its boundaries are gradually becoming apparent as demand grows.
2. Gradients: Reconstructing AI Training with "Networks"
2.1 What is Gradients: A Decentralized AutoML Platform
In the previous section, we mentioned that the core issue of traditional Web2 AutoML is the "closed system," where model training depends on a platform, optimization paths are limited, and resource flow is restricted. Gradients is a reconstruction of this model. It originated from a decentralized engineer community initiated by WanderingWeights and is built on the Bittensor network, running as an AI training subnet on Subnet 56. Unlike traditional platforms, it does not provide centralized services but disassembles the training process and hands it over to an open network. Users only need to define task objectives, such as model types and data, and the remaining processes, including training execution, parameter optimization, and result selection, are all completed automatically by the network. In this model, AI training is abstracted from a complex engineering process into a simple process of "submitting requirements and obtaining results," making it closer to a general capability rather than a highly specialized technical task.
2.2 From Closed Systems to Open Collaboration: What Problems Does Gradients Solve?
The core change of Gradients lies in transforming the originally closed training process confined within a single platform into an open collaborative network process. Training tasks are no longer completed by a single system; instead, they are distributed to multiple participants for parallel attempts, and then the best results are selected through a unified evaluation mechanism. This structure first reduces dependency on centralized service providers, allowing training to be built on distributed computing power; at the same time, dispersed GPU resources are integrated into the same network, forming a resource allocation method closer to marketization through competition. More importantly, model optimization is no longer confined to a single path but is continuously approached through parallel exploration of multiple methods, thereby enhancing the overall optimization upper limit.
2.3 Essential Changes: From Tools to "Training Markets"
In traditional AutoML, the platform functions more like a tool that helps users find optimal solutions through internal algorithms. In Gradients, this process is more akin to a continuously operating "market": users publish demands, and different participants compete on the same task, filtering results via evaluation mechanisms. Consequently, model performance is no longer reliant on a single system's capacity but rather stems from continuous competition and iteration among multiple parties. AutoML also shifts from a relatively closed technical optimization issue to a dynamic process driven by incentives, allowing optimization ability to expand as more participants join. This change allows AI training to possess characteristics of self-evolution similar to that of a market.
2.4 Role in the TAO Ecosystem: AI Training Infrastructure Layer
Within the subnet framework of Bittensor, different Subnets have distinct functionalities such as inference, data processing, and training, with Gradients positioned at the training layer. It is responsible for converting dispersed computing power into actual model outputs and utilizes task distribution and evaluation mechanisms to allow for continuous scheduling and optimization of these resources. At the same time, it connects the supply of computing power with the demand for models, transforming training from a purely resource consumption process into a network collaborative process that can be organized and optimized. In this framework, Gradients acts more like a central node, converting distributed resources into available AI capabilities and supporting the development of upper-layer applications.
3. Core Architecture: How AI Training is Achieved in the Network
In the previous chapter, we mentioned that Gradients has transformed AI training from "completion within a platform" to "completion through network collaboration." So, how exactly does this network operate? The core of this chapter is to break this process down into a more intuitive manner.
3.1 Distributed Training: How a Task is Completed by "Multiple Persons"
You can think of Gradients as a continuously running "training collaboration network." When a user submits a training task, this task is not handed over to a specific system for completion; it is simultaneously distributed to multiple participants in the network. These participants will attempt different training methods based on the same data and objectives, and submit results within a specified timeframe. Subsequently, the system conducts a unified evaluation of these results, filtering out the best-performing solutions. In the end, the more outstanding results receive rewards, while other solutions are eliminated. From the user's perspective, this process requires initiating just one task, equivalent to simultaneously "calling" various optimization ideas and automatically selecting the optimal solution. The key to this method lies not in how strong each individual node is, but rather in the parallel attempts by multiple participants and automatic filtering which brings the results closer to optimal.
In this network, there are primarily three types of participants: users, miners, and validators. Users are responsible for articulating training demands; miners provide computing power and attempt different training methods; validators assess results and select the best models. This division of labor allows the training process to continuously operate while continually screening for better solutions. Overall, it forms a collaborative network driven by "demand, supply, and evaluation."
3.2 Market-Driven AutoML
As can be seen in the previous breakdown of mechanisms, Gradients is not merely transferring AutoML onto the blockchain; rather, by introducing multiple participants and incentive mechanisms, it alters the underlying logic of model optimization. Traditional AutoML relies on a single system to find the optimal solution within limited paths, whereas in Gradients, this process is extended throughout the network: different participants continuously attempt various methods around the same task and filter and iterate through unified evaluations. This ensures that model optimization is no longer a one-time computational process but evolves into a dynamic process that can be repeated. Under this mechanism, higher-performing results will gain greater rewards, continuously attracting participants to optimize strategies and pushing overall performance to rise.
4. Incentives and Competition Mechanisms: How AI Training Forms a "Positive Cycle"
4.1 Incentive Mechanism (TAO Driven): From Training Behavior to Revenue Return
The key to Gradients' long-term operation lies in the incentive mechanism behind it. This relies on the native incentive system provided by Bittensor. Among them, TAO is the native token of the Bittensor network and serves as the "value carrier" within the whole network: on the one hand, it is used to reward participants providing computing power and model contributions, and on the other hand, it participates in the allocation of subnet weights through staking and other means, influencing how resources flow between different subnets.
The Bittensor mainnet continuously generates new incentives, namely TAO (currently approximately 3600 TAO daily), which are allocated to different subnets according to certain rules. The allocation for each subnet depends on its "performance" in the entire network, such as activity level, contribution quality, and funding support. For the subnet where Gradients is located, the TAO allocated here will be reallocated internally to participants. The core basis for allocation is that those who contribute better models will obtain more rewards.
Specifically, when miners submit training results, validators are responsible for testing and scoring these results. The system calculates each participant's "contribution weight" based on the scoring situation and then allocates rewards according to this weight. Models that perform better (e.g., with stronger generalization abilities and more stable results) will yield higher rewards, while validators who score more accurately and can better reflect true quality will also receive more incentives. This design means that "doing better" directly corresponds to "earning more," thus driving participants to continuously optimize models.
4.2 Competition Between Subnets: Not Only Internal Competition but External Ranking
In addition to internal competition within the subnet, Gradients also faces "horizontal competition" within the entire Bittensor network. Since the distribution of TAO is dynamic, different subnets vie for higher weights. Only those subnets that continuously produce high-quality results and attract more participants can garner more significant reward shares. Therefore, the incentives for Gradients depend not only on internal model performance but also on its relative competitiveness within the entire ecosystem. The entire system forms a multi-layered cycle: there is competition among models internally in the subnet; there is overall performance competition between subnets. In the end, computing power investment, model effects, and economic returns are tied together, forming a continuously operating positive feedback mechanism.
4.3 Gradients 5.0: From Competition to "Tournament Mechanism"
Based on early continuous competition, Gradients further evolved into a more structured mechanism, namely "tournament-style training." This can be understood as a periodic competition: each training round sets a time window, and multiple participants compete on the same task, gradually eliminating through multiple rounds of filtering, ultimately choosing the best solution. This format emphasizes periodic comparisons and centralized evaluations. An important change is that miners no longer directly submit training results; they submit "training methods" (code), which are then executed uniformly by validation nodes. This enhances fairness by avoiding disruptions caused by different computational environments and best protects the privacy of data and training processes. Moreover, winning solutions often get archived, becoming reusable methods, akin to a continually accumulating "best practices" library. In the long term, this mechanism not only selects the optimal model but also builds a continuously evolving repository of training methodologies.
5. Ecological Status
5.1 Participant Structure: A Collaborative Network Composed of Demand, Supply, and Evaluation
The Gradients ecosystem comprises three core roles: users (demand side), miners (supply side), and validators (evaluation side). Users mainly include AI developers, small and medium enterprises, and Web3 builders; this group typically possesses a certain level of technical foundation but lacks computing power or complete model training capabilities, thus preferring Gradients to complete model building at a lower cost. Miners provide GPU computing power and participate in competitive training tasks, driven primarily by the motivation to earn TAO rewards; validators are responsible for evaluating and ranking training results and play a key role in ensuring model quality and the effective operation of the mechanism.
From a more granular user profile perspective, Gradients' actual user base exhibits a distinct "semi-developer" characteristic: differing from top-tier AI labs and not fully non-technical ordinary users, it primarily consists of developers with a certain level of engineering capability and Web3 technology users. This is reflected in its community structure, currently predominated by English, with core users mainly distributed among the developer community in North America and Europe, while also covering some Southeast Asian miners and global GPU resource providers. Overall, it resembles a technology-driven developer community.
5.2 Current Operational Status of the Ecosystem
As of May 12, the price of Gradients' alpha token is approximately 0.0255 TAO, with about 4,890 token-holding addresses, 243 miners, and 12 validators, with an Emission percentage of 1.61%. Simultaneously, in its liquidity pool, TAO comprises 2.19%, while Alpha accounts for 97.81%. In terms of price and number of holdings, Gradients has established a certain user base and attention but is still in the early diffusion stage overall. Compared to the leading project in the TAO ecosystem, Chutes, the daily price of the alpha token is 0.0877 TAO, with 13,409 token-holding addresses.
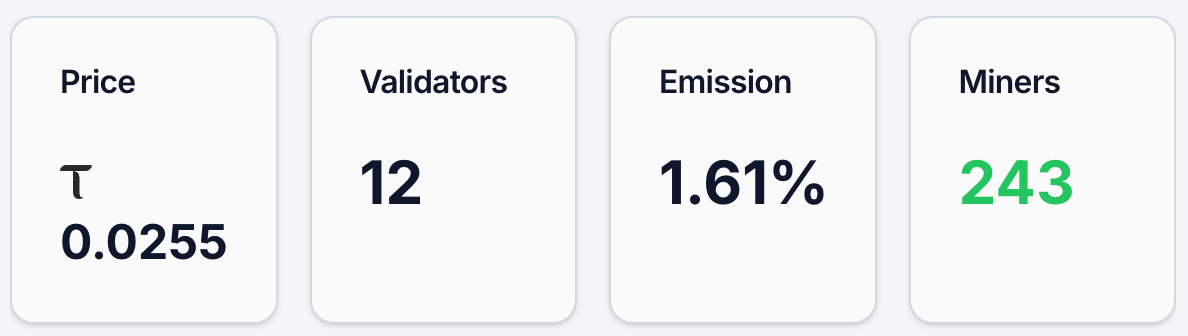
Figure 1. Gradients data. Source: https://bittensormarketcap.com/subnets/56
Next is the Emission incentive mechanism. In the Bittensor system, Emission refers to the real-time distribution weight of incentives granted to this subnet within the overall network’s new rewards. The Bittensor network continuously produces new TAO and allocates them to various subnets based on weights, while Gradients' current 1.61% signifies that it only receives a small fraction of the overall new incentives. This indicator essentially reflects the market's "voting result" through financial flow (e.g., staking) regarding different subnets. Consequently, a 1.61% level typically indicates that current market recognition and capital inflow are relatively limited, implying there remains room for increasing weights in the future. From a funding structure (liquidity pool) perspective, the TAO percentage is merely 2.19%, while Alpha has soared to 97.81%, signaling that external capital inflow is still constrained, with the current scenario being primarily dominated by internal subnet supply. Prices are sensitive to new money; once more TAO flows in, it may trigger a more pronounced amplification effect.
6. Competitive Landscape and Advantages
6.1 Industry Positioning: Decentralized AutoML Training Infrastructure
Gradients is positioned in the niche track of "AI training infrastructure + Decentralized AutoML." It attempts to liberate model training from centralized platforms and achieve more efficient resource utilization and model optimization through network mechanisms. This niche has relatively matured within the Web2 system, with typical representatives including Google Vertex AI and AWS SageMaker. These platforms offer developers one-stop model training and deployment services through cloud computing, but their essence remains centralized architecture. In contrast, Gradients' difference lies not in "more features," but in divergent underlying logic: it transitions training from "platform service" to "network collaboration" and selects optimal results through competitive mechanisms, rendering it a more market-oriented training system.
6.2 Horizontal Comparison: Differences Between Web2 and Web3 AutoML
From a macro perspective, the difference between Web2 and Web3 in the AutoML direction essentially compares two distinct paradigms. The Web2 model emphasizes efficiency and stability by concentrating resources and engineering enhancements to provide a controllable and mature service experience, while the Web3 model emphasizes openness and incentive mechanisms, allowing for continuous evolution in model optimization via the introduction of multiple participants. Specifically, Web2 AutoML resembles "a powerful tool," where users hand tasks to the platform, and solutions are internally computed; whereas Web3 AutoML, represented by Gradients, resembles "an open market," where users publish demands with different participants providing solutions, followed by results selected through evaluation mechanisms. The direct influence of such differences is that the former is more stable and controllable but has limited optimization paths; while the latter has greater exploratory space and potential upside, yet still needs improvement in stability and maturity.
6.3 Gradients' Differentiation in Web3
In the current Web3 AI track, most projects are still focused on the inference layer or AI agent directions, while relatively few projects concentrate on "training infrastructure." Some projects attempt to integrate computing power networks or data networks to provide training capacities, but overall, most remain at the resource scheduling or computing power market level. Gradients' differentiation lies in not only providing computing power matching but further extending upwards to the "model optimization mechanism," introducing assessment and competition systems that grant the training process continuous evolution capability. This indicates it not only addresses "where computing power comes from" but also "how to utilize this computing power more efficiently." From a positioning standpoint, Gradients is closer to a "results-oriented training network," rather than a mere computing power market or tool platform, which is its core distinction from most Web3 AI projects.
6.4 Core Advantages: Mechanism-Driven Efficiency Enhancements
In summary, Gradients' advantages primarily lie in its mechanism design. Firstly, it lowers usage barriers through task abstraction, enabling users to obtain model results without deeply engaging in complex training processes, thus expanding the potential user base. Secondly, on the resource front, the introduction of distributed computing power makes training no longer reliant on a single cloud vendor, theoretically allowing a more resilient cost structure through competition. More importantly, the shift in its optimization approach enables Gradients to offer a solution different from traditional single-path optimization, providing models the opportunity to achieve better performance in a shorter time. This "competition-driven optimization" model is its most core advantage.
6.5 Potential Challenges
Model quality could potentially have stability issues. Decentralized training relies on multi-party participation; while it can enhance upper limits, it could also introduce result fluctuations, presenting a certain level of uncertainty regarding controllability compared to centralized systems. Secondly, there are enterprise-level trust issues. For enterprise users, data security and verifiability of the training process are crucial, and ensuring that data is not misused and results are auditable in a decentralized environment remains a key challenge. Lastly, there is a dependency on token economics. Gradients' operation is highly reliant on the incentive mechanism; if the attraction of TAO rewards declines, it may impact miner participation and overall network activity. Hence, its long-term sustainability is partly contingent on whether the economic model can form a stable positive cycle.
7. Future Outlook: Can Decentralized AutoML Establish Itself?
At the current stage, Gradients remains in its early phase, and its future capability to effectively operate hinges on several key points. The most critical factor is whether it can continually attract real training demand, rather than merely participation based on incentives; the second is model quality, whether the decentralized method can stably produce usable or even superior results; and lastly, whether the economic mechanism can establish a positive cycle to maintain long-term balance between computing power supply and rewards.
In a broader industry context, AI training is differentiating into two paths. One path is the Web2 model, dominated by major tech companies, continuously enhancing model performance by concentrating resources and engineering capability, characterized by stability and maturity; the other is the Web3 path represented by Gradients, which utilizes open networks and incentive mechanisms, allowing more participants to engage in model optimization and continually enhance upper limits through competition. The former aims at "building a stronger system," while the latter resembles "constructing a self-evolving network."
From this perspective, Gradients' exploration represents a new possibility: AI training is no longer just a technical problem but a combination of "computing power + data + market mechanisms." If this model can be established, it has the potential to become the training entry for decentralized AI and play a key infrastructural role in the Bittensor ecosystem. Of course, this direction still requires time for validation, but it has already provided a different evolutionary approach to AutoML compared to traditional paths.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






