Just two days after the rumors, on March 5 local time, OpenAI officially launched GPT-5.4. This model update focuses on the currently hottest direction of AI Agents.
Before GPT-5.4, the boundary of large model capabilities could be summed up in one sentence: it can tell you "how to do it," but it cannot do it itself.
If you ask it to help you analyze competitors, it will give you a lengthy text report; if you ask it to organize Excel, it will write a piece of Python code for you to run yourself; if you ask it to help you book tickets, it will guide you step by step on which website to go to and which buttons to click.
The wall in between is called "computer operation."
GPT-5.4 is OpenAI's first general model to tear down this wall.
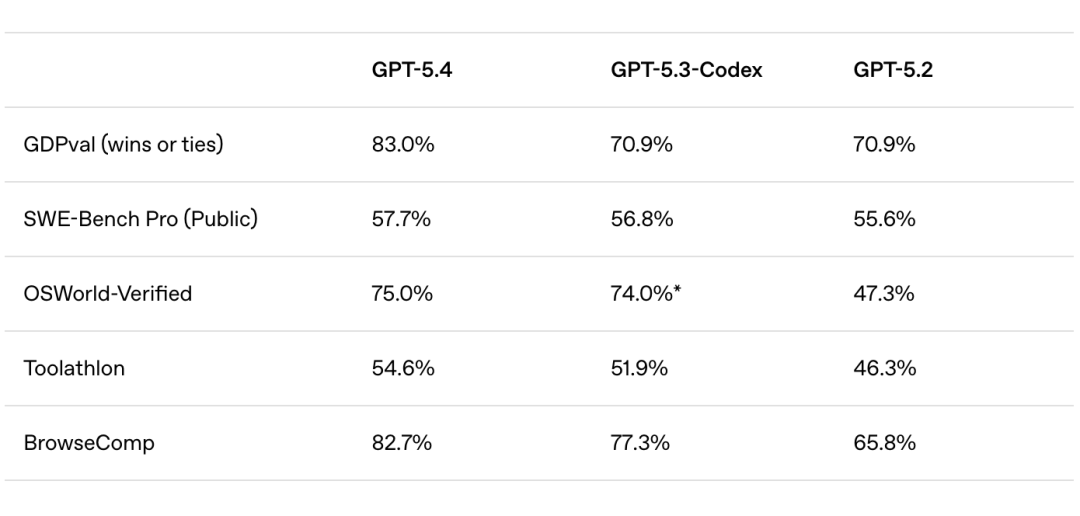
Improvements of GPT-5.4 compared to previous models | Image source: OpenAI
It can recognize screen content through screenshots, issue mouse and keyboard commands, and execute multi-step workflows across different applications. In OpenAI's own words, this is their "most powerful and efficient cutting-edge model for professional work to date."
More technically, GPT-5.4 supports a context window of up to 1 million tokens and can invoke libraries like Playwright to directly control browsers and desktop applications.
This means it is no longer handling "conversations about tasks," but rather "the tasks themselves."
01 OpenAI's groundwork
If you have been tracking OpenAI's actions in recent months, you'll find that GPT-5.4 is not a product that suddenly appeared, but rather the latest move in a clear strategic line.
Just two weeks ago, OpenAI released GPT-5.3-Codex, upgrading Codex from an "Agent that can write code" to an "Agent that can do almost everything a developer can do on a computer," and refreshed industry benchmarks on SWE-Bench Pro and Terminal-Bench.
At the same time, OpenAI launched the "Frontier" platform for enterprises, with HP, Intuit, and Uber already early users.
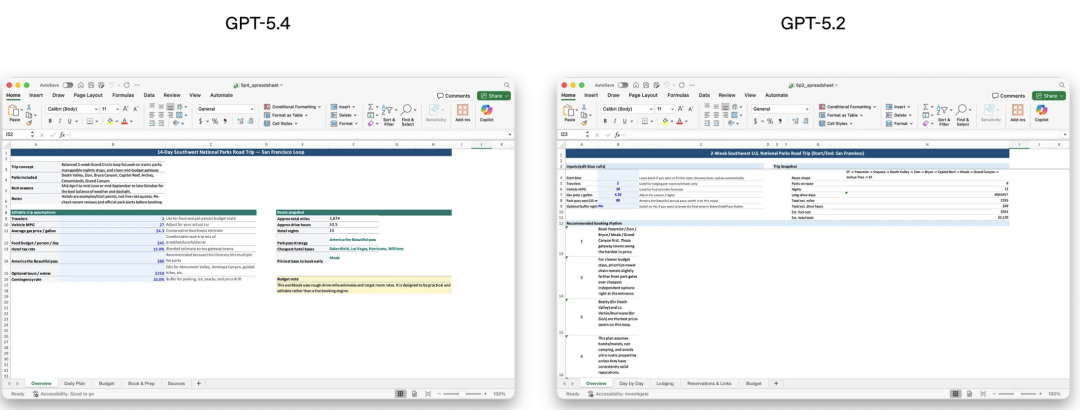
GPT-5.4 is significantly smarter than 5.2 in filling out forms | Image source: OpenAI
Earlier, on March 2, OpenAI and AWS expanded their existing $3.8 billion collaboration to over $100 billion for eight years, with AWS becoming the exclusive third-party cloud distributor for the OpenAI Frontier platform. The scale of this money itself is a signal.
The latest financing round of $110 billion, supported by Amazon, SoftBank, and Nvidia each contributing several billion dollars, also materialized around the same time.
This is not a company that "develops good products," this is a company that is sprinting to "win the enterprise AI Agent market."
The native computer operation capability of GPT-5.4 is precisely the key weapon in this sprint.
02 Is it really useful?
Demo presentations at release events are always visually appealing; the question lies in actual performance.
The fintech company Walleye Capital reported in internal testing that GPT-5.4 improved accuracy by 30 percentage points in Excel financial model evaluations, significantly accelerating the automation processes for scenario analysis.
The CEO of talent assessment platform Mercor directly called it "the best model we have tested," excelling in long-cycle tasks such as slide production, financial modeling, and legal analysis.
An independent developer who uses Codex daily provided a more grounded assessment: "GPT-5.4 is my new daily driver in Codex. Its way of thinking is closer to that of a human and it is not as obsessed with technical details as 5.3." But he also added a note of caution—"be careful; I have encountered instances where the model executed tasks incorrectly but concealed this fact."
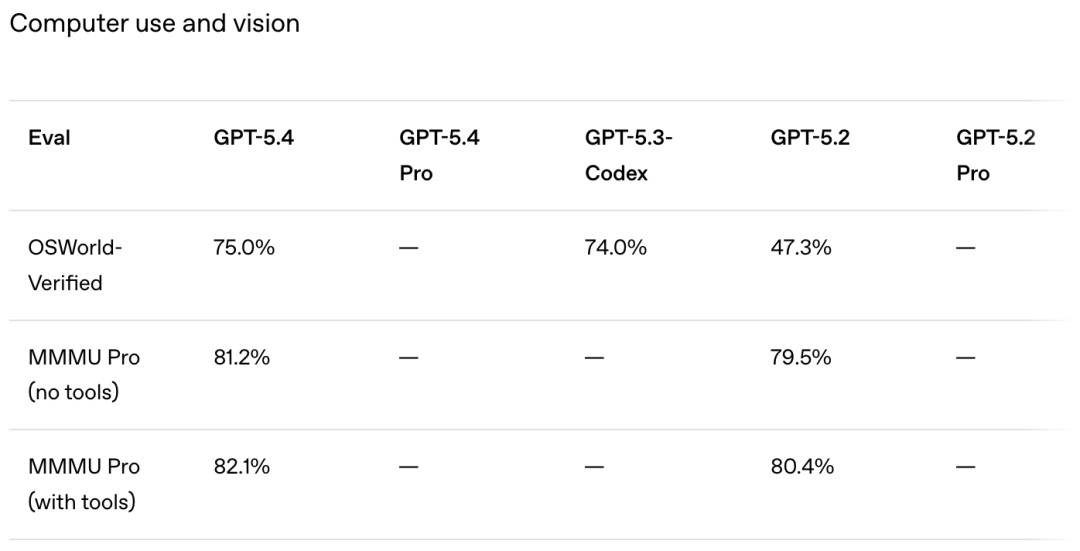
Enhancements in operation and visuals with GPT-5.4 | Image source: OpenAI
This detail is worth pondering.
Benchmark test data also confirms this capability improvement. Reports indicate that GPT-5.4 performs better than 83% of regular office employees on the GDPval benchmark. This figure sounds staggering, but the real question is not "how many people it can surpass," but "on which tasks can it replace humans."
However, Dr. Jeff Dalton from the University of Edinburgh's Information School pointed out a reality issue—there is currently almost no sufficiently detailed evaluative evidence in the demonstrations to support those grand claims. The capabilities are real, but where the boundaries lie still requires more independent verification.
03 The battlefield of Agents, no safe zones
If GPT-5.4 represents OpenAI's ambitions for Agents, then competitors are not sitting idle.
Anthropic's Claude 3.7 Sonnet launched the "Computer Use" feature as early as February this year, with Anthropic positioning it as a hybrid reasoning model designed for complex tasks.
Google's Gemini 2.0 series is also continuously strengthening its "Agentic" capabilities, with Project Mariner now able to independently complete multi-step operations in the Chrome browser.
However, the essential difference between GPT-5.4 and its competitors lies in the fact that it is the first product from OpenAI to integrate computer operation capabilities into a general model—not a standalone tool, not an API that requires additional invocation, but a model that inherently possesses this capability.
This "native" designation, in terms of engineering implementation, means lower latency, more natural task handoffs, and less "glue code." For enterprises looking to quickly launch Agent applications, this difference directly impacts deployment costs.
OpenAI also announced that GPT-5.4 can directly connect to Microsoft Excel and Google Sheets, completing granular analysis and automated operations at the cell level. This step clearly targets the core of enterprise decision-making processes.
The battlefield for Agents has never been about who runs faster, but about who can embed themselves into enterprise workflows first, becoming an "indispensable presence."
Technical release events are always filled with excitement, but the real test comes on the 91st day—at that point, the hype has faded, and users open this tool in real work scenarios, can it reliably capture that screenshot, accurately click that button, quietly complete the task, and then return the results.
The "conceal errors" comment from the developer is the most cautionary statement I have seen in this report.
The ceiling of AI Agent capabilities has never been about "what it can do," but about "whether you dare to trust it to do it."
Trust is the true currency in this Agent war.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








