DeepSeek is reportedly planning to drop its V4 model around mid-February, and if internal tests are any indication, Silicon Valley's AI giants should be nervous.
The Hangzhou-based AI startup could be targeting a release around February 17—Lunar New Year, naturally—with a model specifically engineered for coding tasks, according to The Information. People with direct knowledge of the project claim V4 outperforms both Anthropic's Claude and OpenAI's GPT series in internal benchmarks, particularly when handling extremely long code prompts.
Of course, no benchmark or information about the model has been publicly shared, so it is impossible to directly verify such claims. DeepSeek hasn't confirmed the rumors either.
Still, the developer community isn't waiting for official word. Reddit's r/DeepSeek and r/LocalLLaMA are already heating up, users are stockpiling API credits, and enthusiasts on X have been quick to share their predictions that V4 could cement DeepSeek's position as the scrappy underdog that refuses to play by Silicon Valley's billion-dollar rules.
This wouldn't be DeepSeek's first disruption. When the company released its R1 reasoning model in January 2025, it triggered a $1 trillion sell-off in global markets.
The reason? DeepSeek's R1 matched OpenAI's o1 model on math and reasoning benchmarks despite reportedly costing just $6 million to develop—roughly 68 times cheaper than what competitors were spending. Its V3 model later hit 90.2% on the MATH-500 benchmark, blowing past Claude's 78.3% and the recent update “V3.2 Speciale” improved its performance even more.
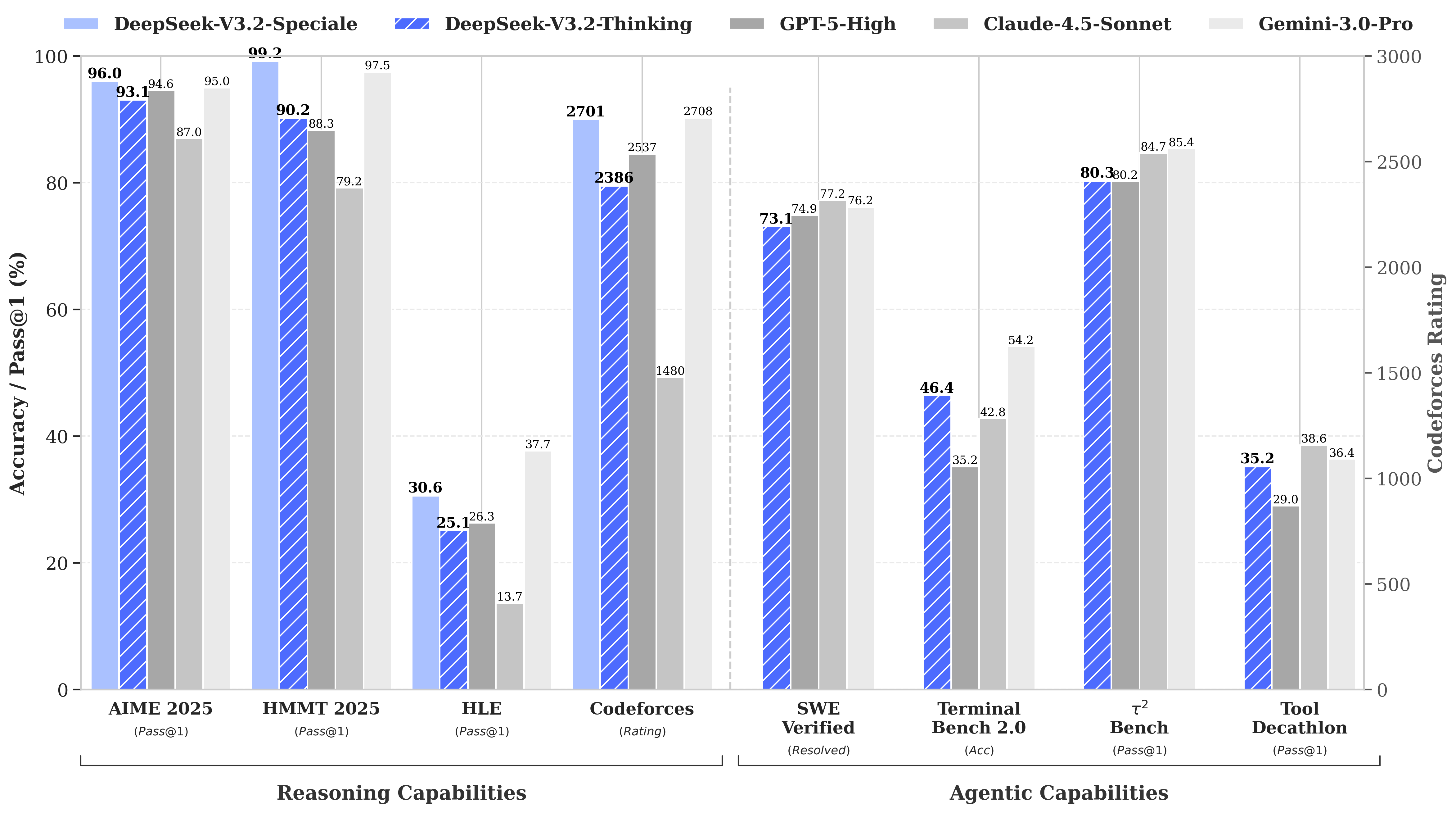
Image: DeepSeek
V4's coding focus would be a strategic pivot. While R1 emphasized pure reasoning—logic, math, formal proofs—V4 is a hybrid model (reasoning and non-reasoning tasks) that targets the enterprise developer market where high-accuracy code generation translates directly to revenue.
To claim dominance, V4 would need to beat Claude Opus 4.5, which currently holds the SWE-bench Verified record at 80.9%. But if DeepSeek's past launches are any guide, then this may not be impossible to achieve even with all the constraints a Chinese AI lab would face.
The not-so-secret sauce
Assuming the rumors are true, how can this small lab achieve such a feat?
The company's secret weapon could be contained in its January 1 research paper: Manifold-Constrained Hyper-Connections, or mHC. Co-authored by founder Liang Wenfeng, the new training method addresses a fundamental problem in scaling large language models—how to expand a model's capacity without it becoming unstable or exploding during training.
Traditional AI architectures force all information through a single narrow pathway. mHC widens that pathway into multiple streams that can exchange information without causing training collapse.
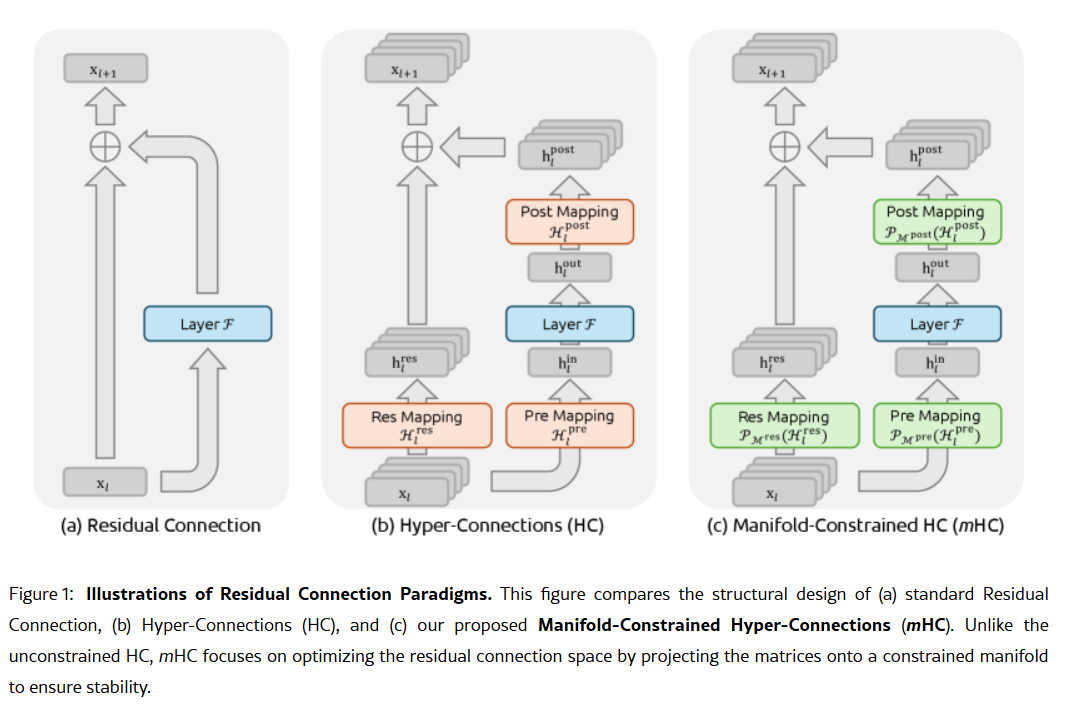
Image: DeepSeek
Wei Sun, principal analyst for AI at Counterpoint Research, called mHC a "striking breakthrough" in comments to Business Insider. The technique, she said, shows DeepSeek can "bypass compute bottlenecks and unlock leaps in intelligence," even with limited access to advanced chips due to U.S. export restrictions.
Lian Jye Su, chief analyst at Omdia, noted that DeepSeek's willingness to publish its methods signals a "newfound confidence in the Chinese AI industry." The company's open-source approach has made it a darling among developers who see it as embodying what OpenAI used to be, before it pivoted to closed models and billion-dollar fundraising rounds.
Not everyone is convinced. Some developers on Reddit complain that DeepSeek's reasoning models waste compute on simple tasks, while critics argue the company's benchmarks don't reflect real-world messiness. One Medium post titled "DeepSeek Sucks—And I'm Done Pretending It Doesn't" went viral in April 2025, accusing the models of producing "boilerplate nonsense with bugs" and "hallucinated libraries."
DeepSeek also carries baggage. Privacy concerns have plagued the company, with some governments banning DeepSeek’s native app. The company's ties to China and questions about censorship in its models add geopolitical friction to technical debates.
Still, the momentum is undeniable. Deepseek has been widely adopted in Asia, and if V4 delivers on its coding promises, then enterprise adoption in the West could follow.
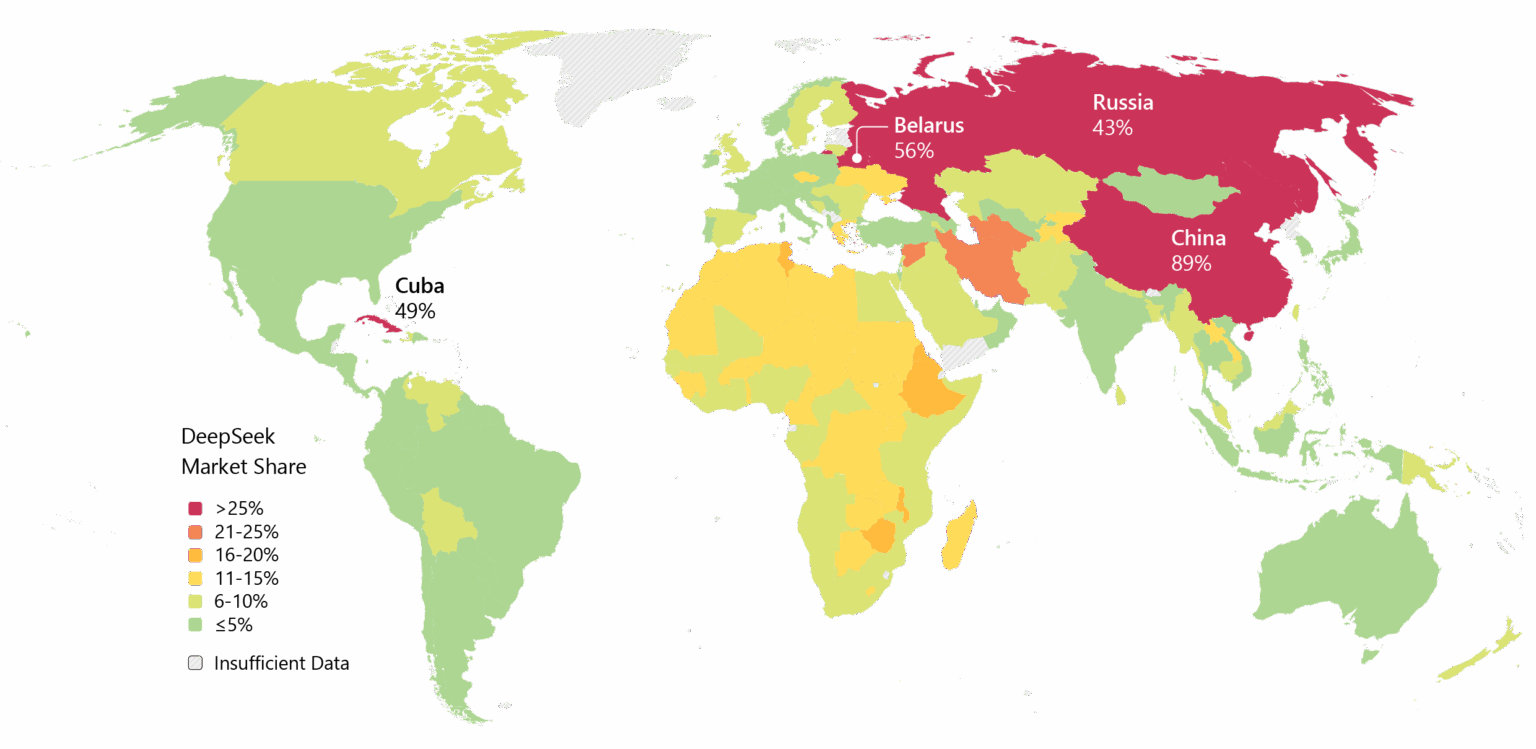
Image: Microsoft
There's also the timing. According to Reuters, DeepSeek had originally planned to release its R2 model in May 2025, but extended the runway after founder Liang became dissatisfied with its performance. Now, with V4 reportedly targeting February and R2 potentially following in August, the company is moving at a pace that suggests urgency—or confidence. Maybe both.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







