Currently, #AI and #RWA are the key research areas for our team. We review dozens of white papers or business plans every day. To be honest, there are too many projects that are just "riding the wave." Terms like "#AI+#Web3" sound impressive, but when you ask about the practical logic, nine times out of ten, it's empty. However, after reading the #OpenLedger white paper, I felt a jolt: this project is genuinely substantial, not just PPT financing, but it has pinpointed the pain points in the #AI industry and is working diligently to address them.
As #AI has developed to this point, several core pain points are particularly evident:
1️⃣ Contributors aren't making money
Data providers, model developers, annotators, and even users providing feedback to models are basically working for big companies. They contribute hard work, but in the end, the platform takes all the profits, and the ecosystem can't sustain itself.
2️⃣ Models are black boxes
How exactly is the #AI that everyone uses trained? Whose data was used? Why does it produce this result? No one can explain clearly. This is a significant flaw in fields like healthcare and finance—if you're not transparent, others won't dare to use it.
3️⃣ General models are not omnipotent
Large models like GPT-4 are indeed powerful, but when it comes to vertical fields (like cancer diagnosis or financial risk control), they struggle. The future trend will definitely be towards smaller, specialized models, but this requires precise data and incentive mechanisms.
🎯 The technical solution adopted in the #OpenLedger white paper is particularly straightforward: using blockchain's transparency and incentive mechanisms to solve the issues of data incentives, value attribution, and trustworthiness in #AI.
Several core points of #OpenLedger that I find particularly impressive:
✅ Proof of Attribution
This is equivalent to an "accounting system" for #AI. Who contributed data, who trained the model, who provided computing power—all of this can be recorded. More importantly—when the model is used for inference and generates value, the profits will automatically be distributed proportionally to these contributors.
Now, everyone is no longer just "working for the platform for free," but rather "partners." The greater the contribution, the more one earns. This mechanism directly addresses the issues of data scarcity and insufficient incentives.
✅ Native AI Economic System
Previously, the internet economy relied on advertising and SEO, but the era driven by #AI is different. #OpenLedger provides a complete "AI economic infrastructure": every time a model is called or inference is made, a fee is required, and this money will be transparently distributed. Essentially, this is a sustainable #AI supply-demand market, rather than just simple subsidies or empty operations.
✅ Focus on Specialized Models
It doesn't aim to directly compete with GPT but rather builds a toolchain (Datanets, ModelFactory, OpenLoRA) that makes it easier for developers to train models in vertical fields. In areas like healthcare, finance, and cybersecurity, specialized models are easier to implement and have greater commercial value.
Why do I have confidence in #OpenLedger?
1️⃣ Solving Real Pain Points
What #AI currently lacks is not computing power, but rather incentive mechanisms and trust. #OpenLedger's "Proof of Attribution" hits the core issue; once it gets going, it creates a flywheel effect: more people contribute data → better models → more users → more profits flowing back to contributors.
2️⃣ Complete Tech Stack
It’s not just empty slogans; the white paper has a clear architecture: EVM-compatible chain, proof of attribution, tool suite. What I see is not a fantasy, but a functioning system that has already been implemented.
3️⃣ Reasonable Token Economic Design
OpenLedger's token $OPEN is not just a "transaction token," but the "lifeblood" of the entire ecosystem:
• Used to pay for model inference fees and training fees
• Used to incentivize data and model contributions
• Used for governance of the protocol
• Used for Gas
The token is tightly bound to its use cases; the more people use it, the greater the demand for the token. This is one of the healthiest Tokenomics I have seen.
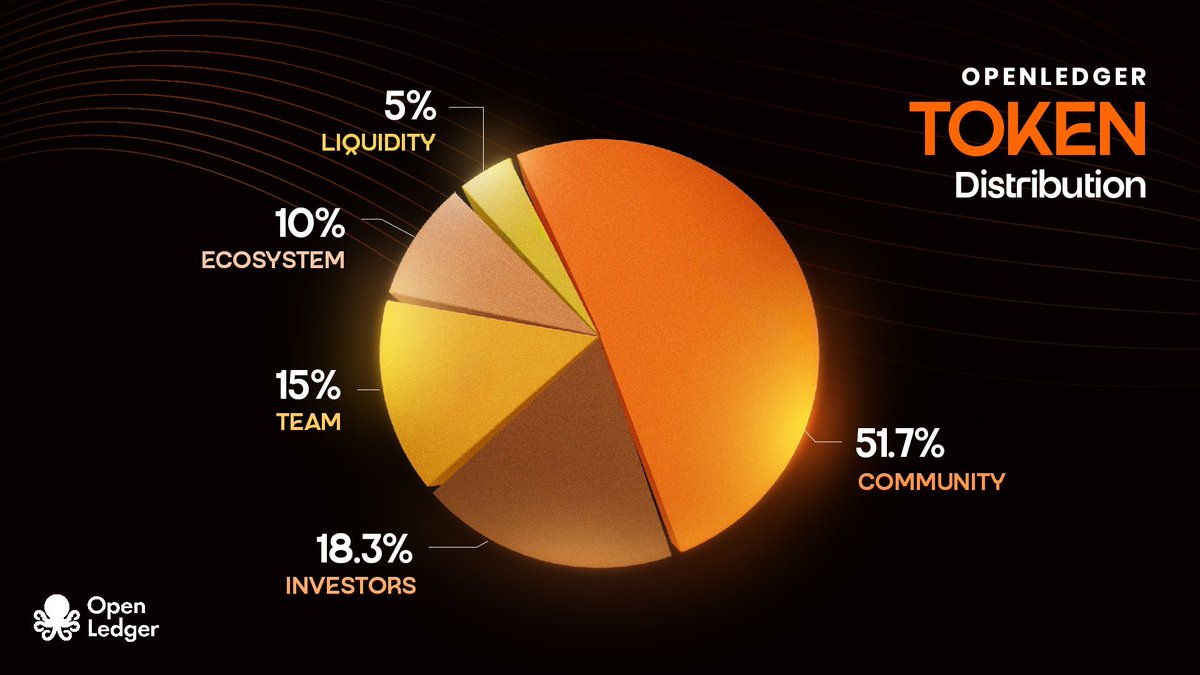
Additionally, I also looked at the token distribution:
• Total supply of 1 billion tokens
• Community + ecosystem accounts for 61.7% (with 5% for airdrops, which is quite generous), indicating that the project team genuinely wants to build an ecosystem rather than just raise money and leave.
• Investors and team have a 12-month cliff + 36 months of linear release, which is a reasonable design to avoid early dumping.
• TGE circulation is 21.55%, ensuring liquidity and startup rewards.
Overall, #OpenLedger's TGE feels relatively stable, protecting ecosystem development while avoiding short-term bubbles.
If ChatGPT has shown everyone the potential of AI, then projects like #OpenLedger are laying the foundation for the #AI economy. It allows data and value to return to contributors, promoting the development of specialized models. Once this step is successfully taken, it will become an indispensable infrastructure in the #AI field, worthy of close attention and consideration. 🧐

免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






