Decentralization is not just a means; it is a value in itself.
Written by: 0xjacobzhao and ChatGPT 4o
Special thanks to Advait Jayant (Peri Labs), Sven Wellmann (Polychain Capital), Chao (Metropolis DAO), Jiahao (Flock), Alexander Long (Pluralis Research), Ben Fielding & Jeff Amico (Gensyn) for their suggestions and feedback.
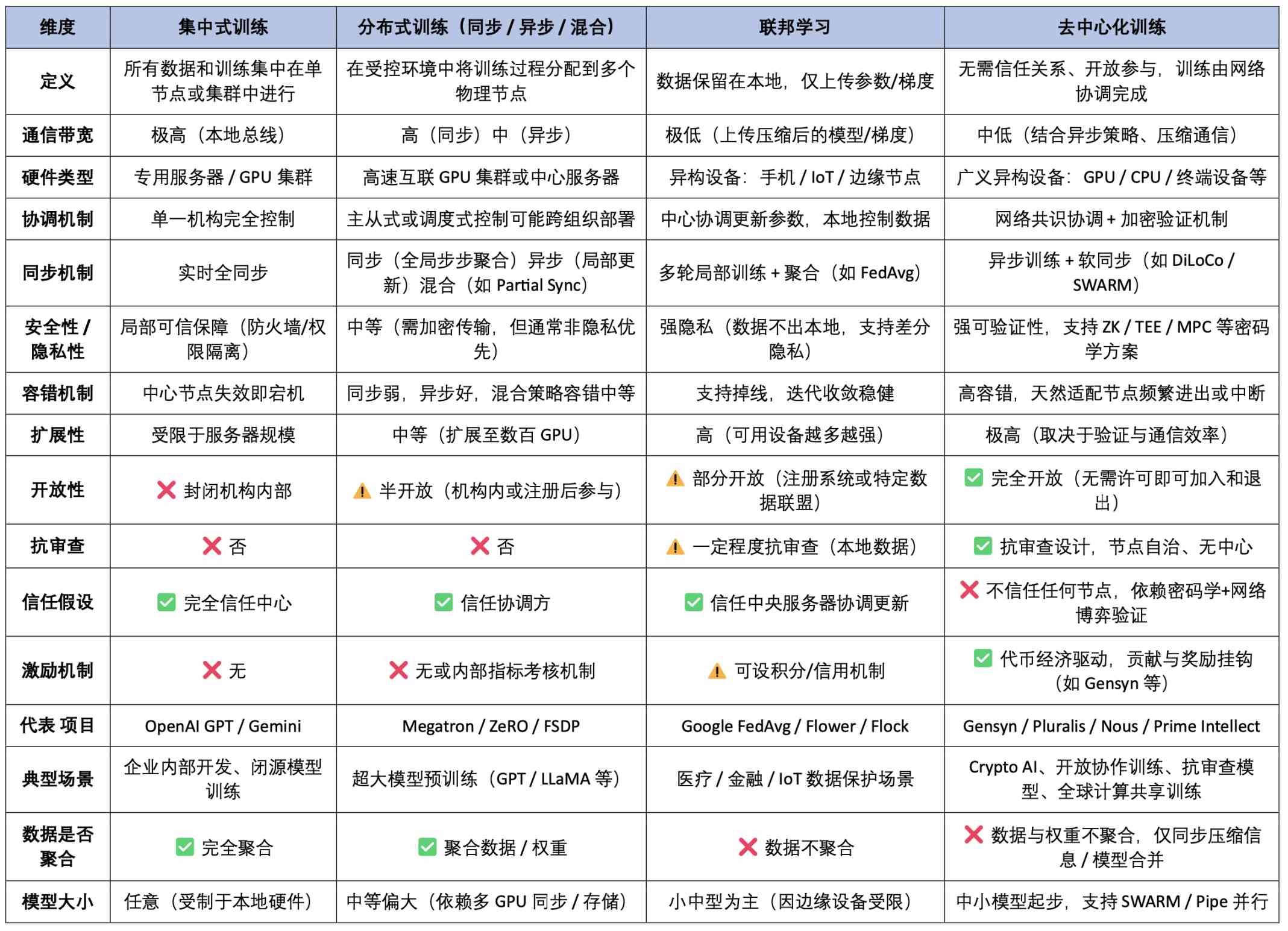
In the full value chain of AI, model training is the most resource-intensive and technically challenging link, directly determining the upper limit of model capabilities and actual application effects. Compared to the lightweight calls in the inference phase, the training process requires continuous large-scale computing power investment, complex data processing workflows, and high-intensity optimization algorithm support, making it the true "heavy industry" of AI system construction. From an architectural paradigm perspective, training methods can be divided into four categories: centralized training, distributed training, federated learning, and decentralized training, which is the focus of this article.
Centralized training is the most common traditional method, where a single institution completes the entire training process within a local high-performance cluster. All components, from hardware (such as NVIDIA GPUs), underlying software (CUDA, cuDNN), cluster scheduling systems (such as Kubernetes), to training frameworks (such as PyTorch based on the NCCL backend), are coordinated by a unified control system. This deeply collaborative architecture optimizes the efficiency of memory sharing, gradient synchronization, and fault tolerance mechanisms, making it very suitable for training large-scale models like GPT and Gemini, with advantages of high efficiency and controllable resources, but it also faces issues such as data monopolization, resource barriers, energy consumption, and single-point risks.
Distributed training is the mainstream method for training large models today, where the core idea is to decompose the model training tasks and distribute them across multiple machines for collaborative execution, breaking through the bottlenecks of single-machine computation and storage. Although it physically possesses "distributed" characteristics, it is still centrally controlled and scheduled by a centralized institution, often operating in high-speed local area network environments, using NVLink high-speed interconnect bus technology, with the main node coordinating various sub-tasks. Mainstream methods include:
Data Parallel: Each node trains different data parameters that are shared, requiring matching model weights.
Model Parallel: Different parts of the model are deployed on different nodes to achieve strong scalability.
Pipeline Parallel: Executing in stages serially to improve throughput.
Tensor Parallel: Fine-grained segmentation of matrix computations to enhance parallel granularity.
Distributed training is a combination of "centralized control + distributed execution," analogous to a single boss remotely directing multiple "office" employees to collaborate on tasks. Currently, almost all mainstream large models (GPT-4, Gemini, LLaMA, etc.) are trained using this method.
Decentralized training represents a more open and censorship-resistant future path. Its core feature is that multiple untrusted nodes (which may be home computers, cloud GPUs, or edge devices) collaboratively complete training tasks without a central coordinator, usually driven by protocols for task distribution and collaboration, and leveraging cryptographic incentive mechanisms to ensure the honesty of contributions. The main challenges faced by this model include:
Device heterogeneity and partitioning difficulties: High coordination difficulty among heterogeneous devices and low task partitioning efficiency.
Communication efficiency bottlenecks: Unstable network communication and significant gradient synchronization bottlenecks.
Lack of trusted execution: Absence of a trusted execution environment makes it difficult to verify whether nodes are genuinely participating in computations.
Lack of unified coordination: Without a central scheduler, task distribution and exception rollback mechanisms are complex.
Decentralized training can be understood as a group of global volunteers contributing computing power to collaboratively train models, but "truly feasible large-scale decentralized training" remains a systematic engineering challenge, involving multiple aspects such as system architecture, communication protocols, cryptographic security, economic mechanisms, and model verification. Whether it can achieve "effective collaboration + honest incentives + correct results" is still in the early prototype exploration stage.
Federated learning, as a transitional form between distributed and decentralized, emphasizes local data retention and centralized aggregation of model parameters, suitable for scenarios that prioritize privacy compliance (such as healthcare and finance). Federated learning possesses the engineering structure and local collaboration capabilities of distributed training while also benefiting from the data decentralization advantages of decentralized training, but it still relies on trusted coordinating parties and does not possess fully open and censorship-resistant characteristics. It can be seen as a "controlled decentralization" solution in privacy-compliant scenarios, relatively mild in terms of training tasks, trust structures, and communication mechanisms, making it more suitable as a transitional deployment architecture in the industry.
AI Training Paradigm Overview Comparison Table (Technical Architecture × Trust Incentives × Application Features)
Boundaries, Opportunities, and Real Paths of Decentralized Training
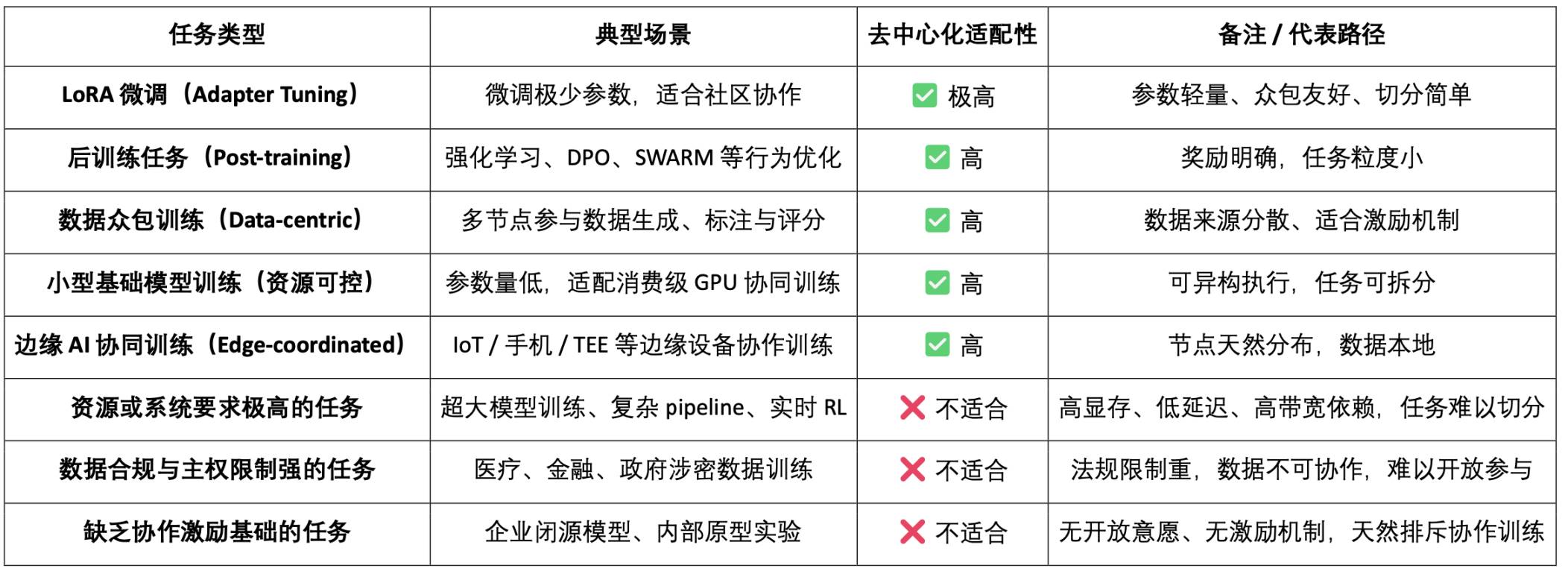
From the perspective of training paradigms, decentralized training is not suitable for all task types. In certain scenarios, due to complex task structures, extremely high resource demands, or significant collaboration difficulties, it is inherently unsuitable for efficient completion among heterogeneous, untrusted nodes. For example, large model training often relies on high memory, low latency, and high bandwidth, making it difficult to effectively partition and synchronize in an open network; tasks with strong data privacy and sovereignty restrictions (such as healthcare, finance, and sensitive data) are limited by legal compliance and ethical constraints, making open sharing impossible; and tasks lacking collaborative incentive foundations (such as enterprise closed-source models or internal prototype training) lack external participation motivation. These boundaries collectively constitute the current realistic limitations of decentralized training.
However, this does not mean that decentralized training is a false proposition. In fact, for lightweight, easily parallelizable, and incentivizable task types, decentralized training shows clear application prospects. This includes but is not limited to: LoRA fine-tuning, behavior alignment post-training tasks (such as RLHF, DPO), data crowdsourcing training and labeling tasks, controllable resource small foundational model training, and collaborative training scenarios involving edge devices. These tasks generally possess high parallelism, low coupling, and tolerance for heterogeneous computing power, making them very suitable for collaborative training through P2P networks, Swarm protocols, distributed optimizers, and other methods.
Overview Table of Decentralized Training Task Adaptability
Analysis of Classic Decentralized Training Projects
Currently, in the forefront of decentralized training and federated learning, representative blockchain projects mainly include Prime Intellect, Pluralis.ai, Gensyn, Nous Research, and Flock.io. From the perspectives of technological innovation and engineering implementation difficulty, Prime Intellect, Nous Research, and Pluralis.ai have proposed many original explorations in system architecture and algorithm design, representing the cutting-edge direction of current theoretical research; while Gensyn and Flock.io have relatively clear implementation paths, showing initial engineering progress. This article will sequentially analyze the core technologies and engineering architecture behind these five projects and further explore their differences and complementary relationships within the decentralized AI training system.
Prime Intellect: A Pioneer in Verifiable Training Trajectories for Reinforcement Learning Collaborative Networks
Prime Intellect aims to build a trustless AI training network that allows anyone to participate in training and receive credible rewards for their computational contributions. Prime Intellect hopes to construct a verifiable, open, and fully incentivized decentralized AI training system through three major modules: PRIME-RL, TOPLOC, and SHARDCAST.
1. Prime Intellect Protocol Stack Structure and Key Module Values

2. Detailed Explanation of Prime Intellect's Key Training Mechanisms
PRIME-RL: Decoupled Asynchronous Reinforcement Learning Task Architecture
PRIME-RL is a task modeling and execution framework customized by Prime Intellect for decentralized training scenarios, specifically designed for heterogeneous networks and asynchronous participation. It uses reinforcement learning as the primary adaptation object, structurally decoupling the training, inference, and weight upload processes, allowing each training node to independently complete task loops locally and collaborate through standardized interfaces with verification and aggregation mechanisms. Compared to traditional supervised learning processes, PRIME-RL is more suitable for achieving flexible training in environments without central scheduling, reducing system complexity while laying the foundation for supporting multi-task parallelism and policy evolution.
TOPLOC: Lightweight Training Behavior Verification Mechanism
TOPLOC (Trusted Observation & Policy-Locality Check) is the core mechanism proposed by Prime Intellect for training verifiability, used to determine whether a node has genuinely completed effective policy learning based on observational data. Unlike heavyweight solutions like ZKML, TOPLOC does not rely on full model recomputation but instead analyzes the local consistency trajectory between "observation sequences ↔ policy updates" to achieve lightweight structural verification. It transforms the behavioral trajectory during the training process into a verifiable object for the first time, representing a key innovation for achieving trustless training reward distribution and providing a feasible path for constructing an auditable and incentivized decentralized collaborative training network.
SHARDCAST: Asynchronous Weight Aggregation and Propagation Protocol
SHARDCAST is the weight propagation and aggregation protocol designed by Prime Intellect, optimized for asynchronous, bandwidth-constrained, and dynamically changing node states in real network environments. It combines gossip propagation mechanisms with local synchronization strategies, allowing multiple nodes to continuously submit partial updates in different states, achieving progressive convergence of weights and multi-version evolution. Compared to centralized or synchronous AllReduce methods, SHARDCAST significantly enhances the scalability and fault tolerance of decentralized training, serving as a core foundation for building stable weight consensus and continuous training iterations.
OpenDiLoCo: Sparse Asynchronous Communication Framework
OpenDiLoCo is a communication optimization framework independently implemented and open-sourced by the Prime Intellect team based on the DiLoCo concept proposed by DeepMind. It is specifically designed to address common challenges in decentralized training, such as bandwidth limitations, device heterogeneity, and node instability. Its architecture is based on data parallelism, constructing sparse topologies like Ring, Expander, and Small-World to avoid the high communication overhead of global synchronization, relying only on local neighboring nodes to complete model collaborative training. By combining asynchronous updates with checkpoint fault tolerance mechanisms, OpenDiLoCo enables consumer-grade GPUs and edge devices to stably participate in training tasks, significantly enhancing the accessibility of global collaborative training and serving as one of the key communication infrastructures for building decentralized training networks.
PCCL: Prime Collective Communication Library
PCCL (Prime Collective Communication Library) is a lightweight communication library tailored for decentralized AI training environments by Prime Intellect, aimed at solving the adaptation bottlenecks of traditional communication libraries (such as NCCL and Gloo) in heterogeneous devices and low-bandwidth networks. PCCL supports sparse topologies, gradient compression, low-precision synchronization, and checkpoint recovery, and can run on consumer-grade GPUs and unstable nodes. It is the underlying component supporting the asynchronous communication capabilities of the OpenDiLoCo protocol. It significantly improves the bandwidth tolerance and device compatibility of the training network, paving the way for building a truly open, trustless collaborative training network by addressing the "last mile" of communication infrastructure.
3. Prime Intellect Incentive Network and Role Distribution
Prime Intellect has built a permissionless, verifiable training network with an economic incentive mechanism, allowing anyone to participate in tasks and receive rewards based on real contributions. The protocol operates based on three core roles:
Task Initiator: Defines the training environment, initial model, reward function, and verification standards.
Training Nodes: Execute local training, submit weight updates and observation trajectories.
Verification Nodes: Use the TOPLOC mechanism to verify the authenticity of training behaviors and participate in reward calculation and policy aggregation.
The core process of the protocol includes task publishing, node training, trajectory verification, weight aggregation (SHARDCAST), and reward distribution, forming an incentive closed loop centered around "genuine training behavior."
4. INTELLECT-2: The First Verifiable Decentralized Training Model Release
In May 2025, Prime Intellect released INTELLECT-2, the world's first large reinforcement learning model trained through asynchronous, trustless decentralized node collaboration, with a parameter scale of 32B. The INTELLECT-2 model was collaboratively trained by over 100 heterogeneous GPU nodes across three continents, using a fully asynchronous architecture, with a training duration exceeding 400 hours, demonstrating the feasibility and stability of asynchronous collaborative networks. This model not only represents a breakthrough in performance but also marks the first systematic implementation of the "training as consensus" paradigm proposed by Prime Intellect. INTELLECT-2 integrates core protocol modules such as PRIME-RL (asynchronous training structure), TOPLOC (training behavior verification), and SHARDCAST (asynchronous weight aggregation), signifying that the decentralized training network has achieved openness, verifiability, and an economic incentive closed loop in the training process for the first time.
In terms of performance, INTELLECT-2 is trained based on QwQ-32B and has undergone specialized RL training in both code and mathematics, placing it at the forefront of current open-source RL fine-tuning models. Although it has not yet surpassed closed-source models like GPT-4 or Gemini, its true significance lies in being the world's first fully trained process that is reproducible, verifiable, and auditable in a decentralized model experiment. Prime Intellect has not only open-sourced the model but, more importantly, has open-sourced the training process itself—training data, policy update trajectories, verification processes, and aggregation logic are all transparent and traceable, creating a decentralized training network prototype that allows everyone to participate, collaborate trustworthily, and share benefits.
5. Team and Funding Background
Prime Intellect completed a $15 million seed round of financing in February 2025, led by Founders Fund, with participation from Menlo Ventures, Andrej Karpathy, Clem Delangue, Dylan Patel, Balaji Srinivasan, Emad Mostaque, Sandeep Nailwal, and other industry leaders. Previously, the project completed a $5.5 million early round of financing in April 2024, co-led by CoinFund and Distributed Global, with participation from Compound VC, Collab + Currency, Protocol Labs, and other institutions. To date, Prime Intellect has raised over $20 million in total.
The co-founders of Prime Intellect are Vincent Weisser and Johannes Hagemann, with team members coming from both the AI and Web3 fields. Core members hail from Meta AI, Google Research, OpenAI, Flashbots, Stability AI, and the Ethereum Foundation, possessing deep capabilities in system architecture design and distributed engineering implementation, making them one of the very few teams to successfully complete real decentralized large model training.
Pluralis: A Paradigm Explorer for Asynchronous Model Parallelism and Structural Compression Collaborative Training
Pluralis is a Web3 AI project focused on "trustworthy collaborative training networks," with the core goal of promoting a decentralized, open participation model training paradigm with long-term incentive mechanisms. Unlike the current mainstream centralized or closed training paths, Pluralis proposes a new concept called Protocol Learning: to "protocolize" the model training process, constructing an open training system with an endogenous incentive closed loop through verifiable collaboration mechanisms and model ownership mapping.
1. Core Concept: Protocol Learning
The Protocol Learning proposed by Pluralis consists of three key pillars:
Unmaterializable Models: The model is distributed in fragments across multiple nodes, preventing any single node from reconstructing the complete weights and keeping it closed-source. This design naturally makes the model an "in-protocol asset," enabling access credential control, leak protection, and benefit attribution binding.
Model-parallel Training over Internet: Through an asynchronous Pipeline model parallel mechanism (SWARM architecture), different nodes hold only partial weights and collaborate to complete training or inference over low-bandwidth networks.
Partial Ownership for Incentives: All participating nodes gain partial ownership of the model based on their training contributions, thus enjoying future profit sharing and governance rights within the protocol.
2. Technical Architecture of the Pluralis Protocol Stack

3. Key Technical Mechanisms Explained
Unmaterializable Models
In "A Third Path: Protocol Learning," it is systematically proposed for the first time that model weights are distributed in fragments, ensuring that "model assets" can only operate within the Swarm network, with access and benefits controlled by the protocol. This mechanism is a prerequisite for achieving a sustainable incentive structure in decentralized training.
Asynchronous Model-Parallel Training
In "SWARM Parallel with Asynchronous Updates," Pluralis constructs a Pipeline-based asynchronous model parallel architecture and empirically tests it on LLaMA-3 for the first time. The core innovation lies in the introduction of the Nesterov Accelerated Gradient (NAG) mechanism, effectively correcting gradient drift and convergence instability issues during asynchronous updates, making training between heterogeneous devices feasible in low-bandwidth environments.
Column-Space Sparsification
In "Beyond Top-K," it is proposed to replace traditional Top-K with a structure-aware column space compression method, avoiding the destruction of semantic paths. This mechanism balances model accuracy and communication efficiency, achieving over 90% compression of communication data in asynchronous model parallel environments, representing a key breakthrough for achieving structure-aware efficient communication.
4. Technical Positioning and Path Selection
Pluralis clearly positions "asynchronous model parallelism" as its core direction, emphasizing the following advantages over data parallelism:
Supports low-bandwidth networks and inconsistent nodes.
Adapts to device heterogeneity, allowing consumer-grade GPUs to participate.
Naturally possesses elastic scheduling capabilities, supporting frequent node online/offline activities.
Breakthrough points include structure compression, asynchronous updates, and weight unextractability.
Currently, based on six technical blog documents published on its official website, the logical structure is integrated into the following three main lines:
Philosophy and Vision: "A Third Path: Protocol Learning," "Why Decentralized Training Matters."
Technical Mechanism Details: "SWARM Parallel," "Beyond Top-K," "Asynchronous Updates."
Institutional Innovation Exploration: "Unmaterializable Models," "Partial Ownership Protocols."
As of now, Pluralis has not launched products, test networks, or open-sourced code, due to the highly challenging technical path it has chosen: it must first solve system-level challenges such as underlying system architecture, communication protocols, and weight unextractability before it can encapsulate product services.
In June 2025, Pluralis Research released a new paper that expanded its decentralized training framework from model pre-training to the model fine-tuning stage, supporting asynchronous updates, sparse communication, and partial weight aggregation. Compared to previous designs that focused on theory and pre-training, this work emphasizes practical feasibility, marking further maturity in its full-cycle training architecture.
5. Team and Funding Background
Pluralis completed a $7.6 million seed round of financing in 2025, co-led by Union Square Ventures (USV) and CoinFund. Founder Alexander Long has a background in machine learning with dual expertise in mathematics and systems research. The core team consists entirely of machine learning researchers with PhDs, making it a typical technology-driven project that primarily publishes high-density papers and technical blogs. Currently, it has not established a BD/Growth team and is focused on overcoming the foundational infrastructure challenges of low-bandwidth asynchronous model parallelism.
Gensyn: A Decentralized Training Protocol Layer Driven by Verifiable Execution
Gensyn is a Web3 AI project focused on "trustworthy execution of deep learning training tasks." Its core is not to reconstruct model architectures or training paradigms but to build a verifiable distributed training execution network with a full process of "task distribution + training execution + result verification + fair incentives." Through an architecture design of off-chain training + on-chain verification, Gensyn establishes an efficient, open, and incentivized global training market, making "training as mining" a reality.
1. Project Positioning: Execution Protocol Layer for Training Tasks
Gensyn is not about "how to train," but rather about "who trains, how to verify, and how to share profits." Its essence is a verifiable computation protocol for training tasks, primarily addressing:
Who executes the training tasks (computing power distribution and dynamic matching)
How to verify execution results (no need for full recomputation, only verifying disputed operators)
How to allocate training profits (Stake, Slashing, and multi-role game mechanisms)
2. Technical Architecture Overview

3. Module Details
RL Swarm: Collaborative Reinforcement Learning Training System
Gensyn's innovative RL Swarm is a decentralized multi-model collaborative optimization system aimed at the post-training phase, featuring the following core characteristics:
Distributed inference and learning process:
Generation Phase (Answering): Each node independently outputs answers;
Critique Phase (Critique): Nodes critique each other's outputs, selecting the best answer and logic;
Consensus Phase (Resolving): Predict the preferences of the majority of nodes and modify their own answers accordingly, achieving local weight updates.
The RL Swarm proposed by Gensyn is a decentralized multi-model collaborative optimization system where each node runs an independent model and conducts local training without the need for gradient synchronization. It naturally adapts to heterogeneous computing power and unstable network environments while supporting flexible node access and exit. This mechanism draws on ideas from RLHF and multi-agent games but is closer to the dynamic evolution logic of collaborative reasoning networks, where nodes are rewarded based on their alignment with the group's consensus results, driving continuous optimization of reasoning capabilities and convergent learning. RL Swarm significantly enhances the robustness and generalization ability of models in open networks and has been deployed as a core execution module in Gensyn's Ethereum Rollup-based Testnet Phase 0.
Verde + Proof-of-Learning: Trustworthy Verification Mechanism
Gensyn's Verde module combines three mechanisms:
Proof-of-Learning: Determines whether training has genuinely occurred based on gradient trajectories and training metadata;
Graph-Based Pinpoint: Locates divergence nodes in the training computation graph, requiring only specific operations to be recomputed;
Refereed Delegation: Employs an arbitration-style verification mechanism, where verifiers and challengers raise disputes and conduct local verification, significantly reducing verification costs.
Compared to ZKP or full recomputation verification schemes, the Verde solution achieves a better balance between verifiability and efficiency.
SkipPipe: Communication Fault Tolerance Optimization Mechanism
SkipPipe addresses the communication bottleneck issues in "low bandwidth + node dropout" scenarios, with core capabilities including:
Skip Layer Mechanism (Skip Ratio): Skips constrained nodes to avoid training blockage;
Dynamic Scheduling Algorithm: Real-time generation of optimal execution paths;
Fault-Tolerant Execution: Even with 50% node failure, inference accuracy only decreases by about 7%.
It supports training throughput improvements of up to 55% and enables key capabilities such as "early-exit inference," "seamless reordering," and "inference completion."
HDEE: Heterogeneous Domain-Expert Ensembles
The HDEE (Heterogeneous Domain-Expert Ensembles) module aims to optimize the following scenarios:
Multi-domain, multi-modal, multi-task training;
Uneven distribution of various training data and significant difficulty differences;
Task allocation and scheduling issues in environments with heterogeneous computing capabilities and inconsistent communication bandwidth.
Its core features include:
MHe-IHo: Assigning different sizes of models to tasks of varying difficulty (model heterogeneity, consistent training steps);
MHo-IHe: Unified task difficulty, but asynchronously adjusting training steps;
Supporting heterogeneous expert models + pluggable training strategies to enhance adaptability and fault tolerance;
Emphasizing "parallel collaboration + extremely low communication + dynamic expert allocation," suitable for complex task ecosystems in reality.
Multi-Role Game Mechanism: Parallel Trust and Incentives
The Gensyn network introduces four types of participants:
Submitter: Publishes training tasks, sets structure and budget;
Solver: Executes training tasks and submits results;
Verifier: Verifies training behaviors to ensure compliance and effectiveness;
Whistleblower: Challenges verifiers to obtain arbitration rewards or face penalties.
This mechanism is inspired by Truebit's economic game design, incentivizing participants to cooperate honestly through forced error insertion + random arbitration, ensuring the trustworthy operation of the network.
4. Testnet and Roadmap Planning
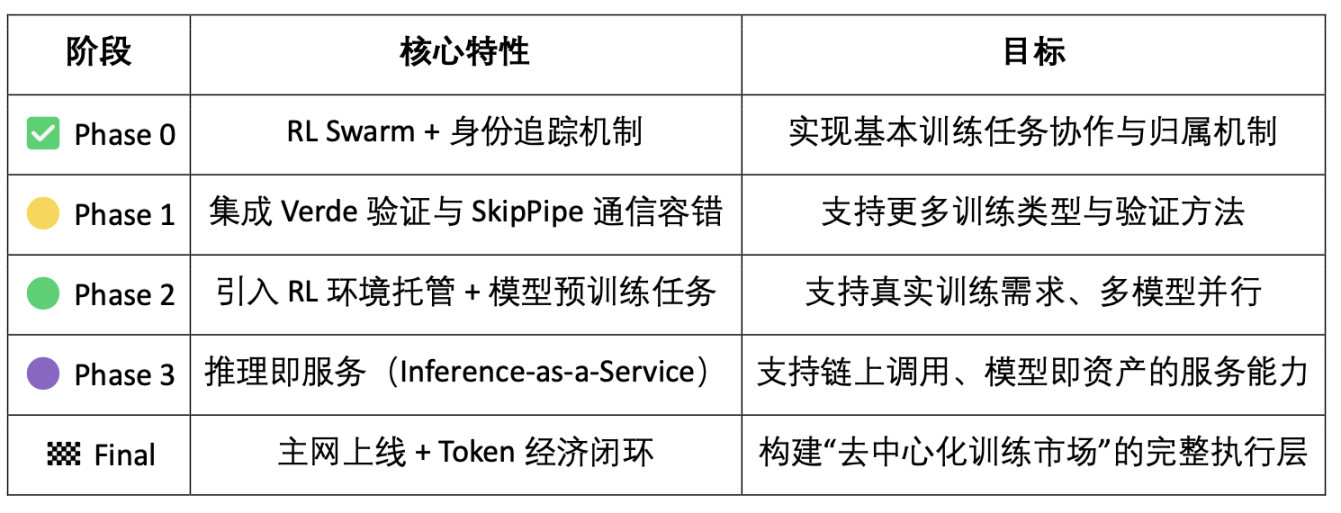
5. Team and Funding Background
Gensyn was co-founded by Ben Fielding and Harry Grieve, headquartered in London, UK. In May 2023, Gensyn announced the completion of a $43 million Series A financing round led by a16z crypto, with other investors including CoinFund, Canonical, Ethereal Ventures, Factor, and Eden Block. The team's background combines experience in distributed systems and machine learning engineering, dedicated to building a verifiable, trustless large-scale AI training execution network.
Nous Research: A Cognition-Evolutionary Training System Driven by Subjective AI Philosophy
Nous Research is one of the few decentralized training teams that combines philosophical depth with engineering implementation. Its core vision stems from the "Desideratic AI" concept: viewing AI as an intelligent entity with subjectivity and evolutionary capabilities, rather than merely a controllable tool. The uniqueness of Nous Research lies in its approach: it does not optimize AI training as an "efficiency problem," but rather sees it as a process of forming a "cognitive subject." Driven by this vision, Nous focuses on building an open training network that is collaboratively trained by heterogeneous nodes, requires no central scheduling, and can withstand censorship verification, using a full-stack toolchain for systematic implementation.
1. Philosophical Support: Redefining the "Purpose" of Training
Nous has not invested heavily in incentive design or protocol economics but seeks to change the philosophical premise of training itself:
Opposing "alignmentism": Rejecting the notion of "training for human control" as the sole goal, advocating that training should encourage models to form independent cognitive styles;
Emphasizing model subjectivity: Believing that foundational models should retain uncertainty, diversity, and the ability to generate hallucinations (hallucination as virtue);
Model training as cognitive formation: Viewing models not as "optimizing task completion" but as individuals participating in the cognitive evolution process.
This view of training, while "romantic," reflects the core logic of Nous's design of training infrastructure: how to allow heterogeneous models to evolve in an open network rather than being uniformly disciplined.
2. Core of Training: Psyche Network and DisTrO Optimizer
Nous's most critical contribution to decentralized training is the construction of the Psyche network and the underlying communication optimizer DisTrO (Distributed Training Over-the-Internet), which together form the execution hub for training tasks. DisTrO + Psyche network possesses multiple core capabilities, including communication compression (using DCT + 1-bit sign encoding to significantly reduce bandwidth requirements), node adaptability (supporting heterogeneous GPUs, reconnections, and voluntary exits), asynchronous fault tolerance (sustaining training without synchronization and possessing high fault tolerance), and a decentralized scheduling mechanism (achieving consensus and task distribution based on blockchain without a central coordinator). This architecture provides a realistic and feasible technical foundation for a low-cost, highly resilient, and verifiable open training network.

This architectural design emphasizes practical feasibility: it does not rely on central servers, adapts to global volunteer nodes, and possesses on-chain traceability of training results.
3. Inference and Agent System Composed of Hermes / Forge / TEE_HEE
In addition to building decentralized training infrastructure, Nous Research has also conducted several exploratory system experiments around the concept of "AI subjectivity":
Hermes Open Source Model Series: Hermes 1 to 3 are representative open-source large models launched by Nous, trained based on LLaMA 3.1, covering three parameter scales: 8B, 70B, and 405B. This series aims to embody Nous's advocated training philosophy of "de-instructionalization and retaining diversity," demonstrating stronger expressiveness and generalization capabilities in long context retention, role-playing, and multi-turn dialogue.
Forge Reasoning API: Multi-Modal Reasoning System
Forge is Nous's self-developed reasoning framework, combining three complementary mechanisms to achieve more resilient and creative reasoning capabilities:
MCTS (Monte Carlo Tree Search): Suitable for strategic search in complex tasks;
CoC (Chain of Code): Introduces a path that combines code chains and logical reasoning;
MoA (Mixture of Agents): Allows multiple models to negotiate, enhancing the breadth and diversity of outputs.
This system emphasizes "non-deterministic reasoning" and combinatorial generation paths, providing a strong response to traditional instruction alignment paradigms.
TEEHEE: AI Autonomous Agent Experiment: TEEHEE is Nous's cutting-edge exploration in autonomous agents, aiming to verify whether AI can operate independently in a Trusted Execution Environment (TEE) and possess a unique digital identity. This agent has dedicated Twitter and Ethereum accounts, with all control permissions managed by a remotely verifiable enclave, preventing developers from intervening in its behavior. The experimental goal is to construct an AI entity with "immutability" and "independent behavioral intent," marking an important step towards building autonomous agents.
AI Behavior Simulator Platform: Nous has also developed several simulators, including WorldSim, Doomscroll, and Gods & S8n, to study the behavioral evolution and value formation mechanisms of AI in multi-role social environments. Although not directly involved in the training process, these experiments lay the semantic foundation for cognitive behavior modeling of long-term autonomous AI.
4. Team and Funding Overview
Nous Research was founded in 2023 by Jeffrey Quesnelle (CEO), Karan Malhotra, Teknium, Shivani Mitra, and others. The team balances philosophical drive with systems engineering, possessing diverse backgrounds in machine learning, system security, and decentralized networks. In 2024, it secured $5.2 million in seed funding, and in April 2025, it completed a $50 million Series A financing round led by Paradigm, achieving a valuation of $1 billion and entering the ranks of Web3 AI unicorns.
Flock: Blockchain-Enhanced Federated Learning Network
Flock.io is a blockchain-based federated learning platform aimed at decentralizing AI training data, computation, and models. Flock leans towards an integrated framework of "federated learning + blockchain reward layer," essentially an on-chain evolutionary version of traditional FL architecture rather than a systematic exploration of building a new training protocol. Compared to decentralized training projects like Gensyn, Prime Intellect, Nous Research, and Pluralis, Flock focuses on privacy protection and usability improvements rather than theoretical breakthroughs in communication, verification, or training methods. Its more appropriate comparisons are with federated learning systems like Flower, FedML, and OpenFL.
1. Core Mechanisms of Flock.io
- Federated Learning Architecture: Emphasizing Data Sovereignty and Privacy Protection
Flock is based on the classic Federated Learning (FL) paradigm, allowing multiple data owners to collaboratively train a unified model without sharing raw data, focusing on data sovereignty, security, and trust issues. The core process includes:
Local Training: Each participant (Proposer) trains the model on their local device without uploading raw data;
On-Chain Aggregation: After training, local weight updates are submitted and aggregated into a global model by on-chain Miners;
Committee Evaluation: Voter nodes are randomly elected through VRF to evaluate the aggregated model's performance using an independent test set and score it;
Incentives and Penalties: Rewards or slashing of deposits are executed based on scoring results to achieve anti-malicious behavior and dynamic trust maintenance.
- Blockchain Integration: Achieving Trustless System Coordination
Flock moves all core aspects of the training process (task allocation, model submission, evaluation scoring, incentive execution) on-chain to achieve system transparency, verifiability, and censorship resistance. Key mechanisms include:
VRF Random Election Mechanism: Enhances the fairness of rotation and resistance to manipulation for Proposers and Voters;
Stake Collateral Mechanism (PoS): Enhances system robustness by constraining node behavior through token staking and penalties;
On-Chain Incentive Automatic Execution: Implements reward distribution and slashing penalties tied to task completion and evaluation results through smart contracts, creating a collaborative network without trust intermediaries.
- zkFL: Privacy Protection Innovation of Zero-Knowledge Aggregation Mechanism: Flock introduces the zkFL zero-knowledge aggregation mechanism, allowing Proposers to submit zero-knowledge proofs of local updates, enabling Voters to verify correctness without accessing raw gradients, enhancing the credibility of the training process while ensuring privacy. This represents an important innovation in the integration of privacy protection and verifiability in federated learning.
2. Core Product Components of Flock
AI Arena: This is Flock.io's decentralized training platform, where users can participate in model tasks through train.flock.io, taking on roles as trainers, validators, or delegators, and earning rewards by submitting models, evaluating performance, or delegating tokens. Currently, tasks are released by the official team, with plans to gradually open up to community co-creation in the future.
FL Alliance: This is Flock's federated learning client, supporting participants in further fine-tuning models using private data. Through VRF elections, staking, and slashing mechanisms, it ensures the honesty of the training process and collaborative efficiency, serving as a key link between community initial training and real deployment.
AI Marketplace: This is a model co-creation and deployment platform where users can propose models, contribute data, and invoke model services, supporting database access and RAG-enhanced reasoning, promoting the implementation and circulation of AI models in various real-world scenarios.
3. Team and Funding Overview
Flock.io was founded by Sun Jiahao and has issued the platform token FLOCK. The project has raised a total of $11 million, with investors including DCG, Lightspeed Faction, Tagus Capital, Animoca Brands, Fenbushi, and OKX Ventures. In March 2024, Flock completed a $6 million seed round to launch the testnet and federated learning client; in December of the same year, it secured an additional $3 million in funding and received support from the Ethereum Foundation, focusing on researching blockchain-driven AI incentive mechanisms. Currently, the platform has created 6,428 models, with 176 training nodes, 236 validation nodes, and 1,178 delegators.
Compared to decentralized training projects, Flock's federated learning-based systems have advantages in training efficiency, scalability, and privacy protection, especially suitable for collaborative training of small to medium-sized models. The solutions are pragmatic and easy to implement, leaning more towards engineering feasibility optimization; while projects like Gensyn and Pluralis pursue deeper theoretical breakthroughs in training methods and communication mechanisms, facing greater systemic challenges but also closer to true explorations of "trustless, decentralized" training paradigms.
EXO: Decentralized Training Attempt in Edge Computing
EXO is a highly representative AI project in the current edge computing scenario, dedicated to achieving lightweight AI training, inference, and agent applications on home-level consumer devices. Its decentralized training path emphasizes "low communication overhead + local autonomous execution," employing the DiLoCo asynchronous delay synchronization algorithm and SPARTA sparse parameter exchange mechanism to significantly reduce the bandwidth requirements for multi-device collaborative training. At the system level, EXO does not build an on-chain network or introduce economic incentive mechanisms but instead launches a single-machine multi-process simulation framework, EXO Gym, supporting researchers in conveniently conducting rapid validation and experimentation of distributed training methods in local environments.
1. Core Mechanism Overview
DiLoCo Asynchronous Training: Synchronizes nodes every H steps, adapting to unstable networks;
SPARTA Sparse Synchronization: Exchanges only a minimal amount of parameters (e.g., 0.1%) at each step, maintaining model relevance and reducing bandwidth requirements;
Asynchronous Combinatorial Optimization: The two can be used in combination to achieve a better trade-off between communication and performance.
evML Verification Mechanism Exploration: Edge-Verified Machine Learning (evML) proposes using TEE/Secure Context for low-cost computational verification, enabling trustworthy participation of edge devices without requiring staking through remote verification and sampling mechanisms, representing an engineering compromise between economic security and privacy protection.
2. Tools and Application Scenarios
EXO Gym: Simulates a multi-node training environment on a single device, supporting communication strategy experiments for models like NanoGPT, CNN, and Diffusion;
EXO Desktop App: A desktop AI tool for individual users, supporting local large model operation, iPhone image control, and private context integration (e.g., SMS, calendar, video records) with privacy-friendly personalized features.
EXO Gym is more of an exploration-oriented decentralized training experimental project, primarily integrating existing communication compression technologies (like DiLoCo and SPARTA) to achieve lightweight training paths. Compared to projects like Gensyn, Nous, and Pluralis, EXO has not yet entered core stages such as on-chain collaboration, verifiable incentive mechanisms, or real distributed network deployment.
The Pre-Chain Engine of Decentralized Training: A Comprehensive Study of Model Pre-Training
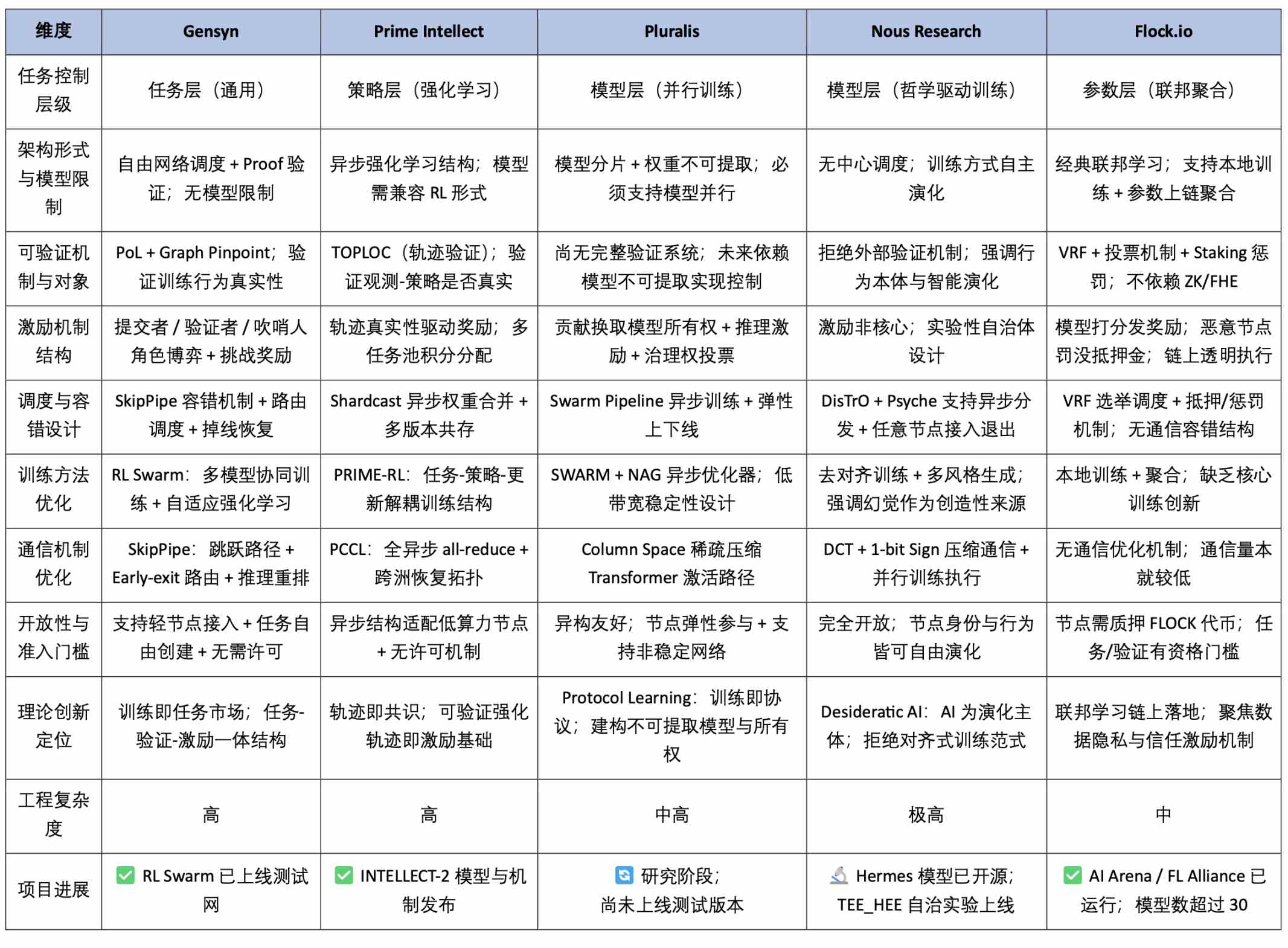
In the face of core challenges commonly found in decentralized training, such as device heterogeneity, communication bottlenecks, coordination difficulties, and lack of trustworthy execution, Gensyn, Prime Intellect, Pluralis, and Nous Research have proposed differentiated system architecture paths. From the perspectives of training methods and communication mechanisms, these four projects showcase their unique technical focuses and engineering implementation logic.
In terms of training method optimization, the four projects explore key dimensions such as collaborative strategies, update mechanisms, and asynchronous control, covering different stages from pre-training to post-training.
Prime Intellect's PRIME-RL belongs to the asynchronous scheduling structure aimed at the pre-training stage, achieving efficient and verifiable training scheduling mechanisms in heterogeneous environments through a "local training + periodic synchronization" strategy. This method has strong generality and flexibility. It has a high theoretical innovation level, proposing a clear paradigm in training control structures; the engineering implementation difficulty is medium to high, requiring high standards for underlying communication and control modules.
Nous Research's DeMo optimizer focuses on training stability issues in asynchronous low-bandwidth environments, achieving a high fault-tolerant gradient update process under heterogeneous GPU conditions. It is one of the few solutions that have unified theory and engineering on "asynchronous communication compression closed loops." The theoretical innovation level is very high, particularly representative in the path of compression and scheduling collaboration; the engineering implementation difficulty is also very high, especially relying on the precision of asynchronous parallel coordination.
Pluralis's SWARM + NAG is currently one of the most systematic and groundbreaking designs in asynchronous training paths. It is based on an asynchronous model parallel framework, introducing Column-space sparse communication and NAG momentum correction, constructing a large model training solution that can converge stably under low bandwidth conditions. The theoretical innovation level is extremely high, being a structural pioneer in asynchronous collaborative training; the engineering difficulty is also extremely high, requiring deep integration of multi-level synchronization and model partitioning.
Gensyn's RL Swarm mainly serves the post-training stage, focusing on policy fine-tuning and agent collaborative learning. Its training process follows a three-step flow of "generate - evaluate - vote," particularly suitable for dynamic adjustments of complex behaviors in multi-agent systems. The theoretical innovation level is medium to high, mainly reflected in the collaborative logic of agents; the engineering implementation difficulty is moderate, with the main challenges in system scheduling and behavior convergence control.
In terms of communication mechanism optimization, these four projects also have targeted layouts, generally focusing on system solutions for bandwidth bottlenecks, node heterogeneity, and scheduling stability issues.
Prime Intellect's PCCL is a low-level communication library designed to replace traditional NCCL, aiming to provide a more robust collective communication foundation for upper-layer training protocols. The theoretical innovation level is medium to high, with certain breakthroughs in fault-tolerant communication algorithms; the engineering difficulty is medium, possessing strong modular adaptability.
Nous Research's DisTrO is the communication core module of DeMo, emphasizing minimal communication overhead while ensuring the coherence of the training closed loop under low bandwidth. The theoretical innovation level is high, with universal design value in scheduling collaborative structures; the engineering difficulty is high, requiring high precision in compression and training synchronization.
Pluralis's communication mechanism is deeply embedded in the SWARM architecture, significantly reducing the communication load in asynchronous training of large models while ensuring convergence and maintaining high throughput. The theoretical innovation level is high, setting a paradigm for asynchronous model communication design; the engineering difficulty is extremely high, relying on distributed model orchestration and structural sparsity control.
Gensyn's SkipPipe is a fault-tolerant scheduling component that supports RL Swarm. This solution has low deployment costs and is mainly used to enhance training stability at the engineering implementation level. The theoretical innovation level is average, more of an engineering realization of known mechanisms; the engineering difficulty is low, but it is highly practical in actual deployment.
Additionally, we can measure the value of decentralized training projects from two macro categories: the blockchain collaboration layer and the AI training system layer.
Blockchain Collaboration Layer: Emphasizing Protocol Credibility and Incentive Collaboration Logic
Verifiability: Whether the training process is verifiable and whether trust is established through game or cryptographic mechanisms;
Incentive Mechanism: Whether a task-driven token reward/role mechanism is designed;
Openness and Access Threshold: Whether nodes are easy to access and whether there is centralization or permission control.
AI Training System Layer: Highlighting Engineering Capability and Performance Accessibility
Scheduling and Fault-Tolerant Mechanisms: Whether it is fault-tolerant, asynchronous, dynamic, and distributed scheduling;
Training Method Optimization: Whether there are optimizations for model training algorithms or structures;
Communication Path Optimization: Whether gradients are compressed/sparse communication, adapting to low bandwidth.
The following table systematically evaluates Gensyn, Prime Intellect, Pluralis, and Nous Research on the technical depth, engineering maturity, and theoretical innovation in decentralized training paths based on the above indicator system.
The Post-Chain Ecosystem of Decentralized Training: Model Fine-Tuning Based on LoRA
In the complete value chain of decentralized training, projects like Prime Intellect, Pluralis.ai, Gensyn, and Nous Research mainly focus on infrastructure construction for model pre-training, communication mechanisms, and collaborative optimization. However, another category of projects focuses on the post-training phase of model adaptation and inference delivery, not directly participating in systematic training processes such as pre-training, parameter synchronization, or communication optimization. Representative projects include Bagel, Pond, and RPS Labs, all centered around the LoRA fine-tuning method, forming a key "post-chain" link in the decentralized training ecosystem.
LoRA + DPO: Practical Path for Web3 Fine-Tuning Deployment
LoRA (Low-Rank Adaptation) is an efficient parameter fine-tuning method, whose core idea is to insert low-rank matrices into pre-trained large models to learn new tasks while freezing the original model parameters. This strategy significantly reduces training costs and resource consumption, enhancing fine-tuning speed and deployment flexibility, especially suitable for modular and combinatorial calling features in Web3 scenarios.
Traditional large language models like LLaMA and GPT-3 often have billions or even hundreds of billions of parameters, making direct fine-tuning costly. LoRA achieves efficient adaptation of large models by training only a small number of inserted parameter matrices, becoming one of the most practical mainstream methods.
Direct Preference Optimization (DPO), a recently emerged post-training method for language models, is often used in conjunction with the LoRA fine-tuning mechanism for model behavior alignment. Compared to traditional RLHF (Reinforcement Learning from Human Feedback) methods, DPO achieves preference learning through direct optimization of paired samples, eliminating the complex reward modeling and reinforcement learning processes, resulting in a simpler structure and more stable convergence, particularly suitable for fine-tuning tasks in lightweight and resource-constrained environments. Due to its efficiency and ease of use, DPO is gradually becoming the preferred solution for many decentralized AI projects in the model alignment phase.
Reinforcement Learning (RL): Future Evolution Direction of Post-Training Fine-Tuning
From a long-term perspective, an increasing number of projects view Reinforcement Learning (RL) as a core path with greater adaptability and evolutionary potential in decentralized training. Compared to supervised learning or parameter fine-tuning mechanisms that rely on static data, RL emphasizes continuously optimizing strategies in dynamic environments, naturally aligning with the asynchronous, heterogeneous, and incentive-driven collaborative patterns in Web3 networks. Through continuous interaction with the environment, RL can achieve highly personalized and incrementally continuous learning processes, providing an evolving "behavioral intelligence" infrastructure for agent networks, on-chain task markets, and intelligent economic entities.
This paradigm not only aligns conceptually with the spirit of decentralization but also possesses significant systemic advantages. However, due to high engineering thresholds and complex scheduling mechanisms, the implementation of RL still faces considerable challenges at this stage, making widespread promotion difficult in the short term.
It is worth noting that Prime Intellect's PRIME-RL and Gensyn's RL Swarm are pushing RL from post-training fine-tuning mechanisms towards pre-training main structures, attempting to build a collaborative training system centered around RL that does not require trust coordination.
Bagel (zkLoRA): Trustworthy Verification Layer for LoRA Fine-Tuning
Bagel is based on the LoRA fine-tuning mechanism and introduces zero-knowledge proof (ZK) technology, aiming to address the issues of trustworthiness and privacy protection in the "on-chain model fine-tuning" process. zkLoRA does not participate in actual training computations but provides a lightweight, verifiable mechanism that allows external users to confirm that a fine-tuned model indeed originates from a specified base model and LoRA parameters without accessing the original data or weights.
Unlike Gensyn's Verde or Prime Intellect's TOPLOC, which focus on the dynamic verification of whether "behavior actually occurred" during the training process, Bagel is more focused on the static verification of whether "fine-tuning results are trustworthy." The greatest advantage of zkLoRA lies in its low resource consumption for verification and strong privacy protection, but its application scope is usually limited to fine-tuning tasks with relatively small parameter changes.
Pond: Fine-Tuning and Agent Evolution Platform in GNN Scenarios
Pond is currently the only decentralized training project focused on fine-tuning Graph Neural Networks (GNN), serving structured data applications such as knowledge graphs, social networks, and transaction graphs. By supporting users to upload graph-structured data and participate in model training feedback, it provides a lightweight and controllable training and inference platform for personalized tasks.
Pond also employs efficient fine-tuning mechanisms like LoRA, with the core goal of achieving a modular and deployable agent system on GNN architectures, opening up a new exploratory path for "small model fine-tuning + multi-agent collaboration" in a decentralized context.
RPS Labs: AI-Driven Liquidity Engine for DeFi
RPS Labs is a decentralized training project based on the Transformer architecture, dedicated to using fine-tuned AI models for DeFi liquidity management, primarily deployed in the Solana ecosystem. Its flagship product, UltraLiquid, is an active market-making engine that dynamically adjusts liquidity parameters using fine-tuned models to reduce slippage, enhance depth, and optimize token issuance and trading experiences.
Additionally, RPS has launched the UltraLP tool, which supports liquidity providers in real-time optimization of their capital allocation strategies on DEX, thereby improving capital efficiency and reducing impermanent loss risks, reflecting the practical value of AI fine-tuning in financial scenarios.
From Pre-Chain Engine to Post-Chain Ecosystem: The Future of Decentralized Training
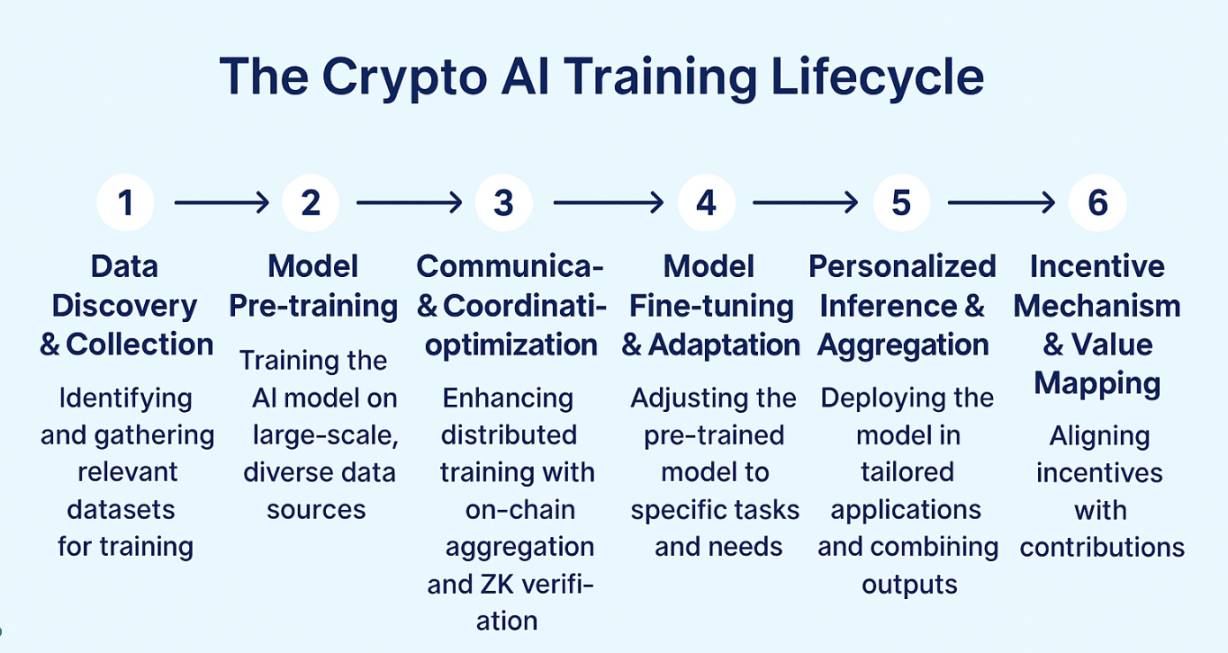
In the complete ecological map of decentralized training, the overall structure can be divided into two main categories: the pre-chain engine corresponding to the model pre-training stage, and the post-chain ecosystem corresponding to the model fine-tuning and deployment stage, forming a complete closed loop from infrastructure to application implementation.
The pre-chain engine focuses on the underlying protocol construction for model pre-training, represented by projects such as Prime Intellect, Nous Research, Pluralis.ai, and Gensyn. They are dedicated to building a system architecture with asynchronous updates, sparse communication, and training verifiability, achieving efficient and reliable distributed training capabilities in a trustless network environment, forming the technical foundation of decentralized training.
At the same time, Flock, as a representative of the intermediate layer, establishes a practical and collaborative bridge between training and deployment through mechanisms such as federated learning paths, model aggregation, on-chain verification, and multi-party incentives, providing a practical paradigm for multi-node collaborative learning.
The post-chain ecosystem focuses on model fine-tuning and application layer deployment. Projects like Pond, Bagel, and RPS Labs revolve around the LoRA fine-tuning method: Bagel provides a trustworthy on-chain verification mechanism, Pond focuses on the evolution of small models in graph neural networks, and RPS applies fine-tuned models to intelligent market-making in DeFi scenarios. They offer low-threshold, composable model invocation and personalized customization solutions for developers and end-users through components like inference APIs and Agent SDKs, serving as important entry points for decentralized AI implementation.
We believe that decentralized training is not only a natural extension of the blockchain spirit in the AI era but also the embryonic form of the global collaborative intelligent productivity system's infrastructure. In the future, when we look back on this challenging journey ahead, we will still be inspired by the original intention: decentralization is not just a means; it is a value in itself.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







