Systematic review of the latest developments in the DeAI track, analyzing the current status of project development, and discussing future trends.
Author: @ancihu49074 (Biteye), @Jessemeta (Biteye), @lviswang (Biteye), @0xjacobzhao (Biteye), @bz1022911 (PANews)
Overview
Background
In recent years, leading tech companies such as OpenAI, Anthropic, Google, and Meta have continuously driven the rapid development of large language models (LLM). LLMs have demonstrated unprecedented capabilities across various industries, greatly expanding the realm of human imagination and even showing potential to replace human labor in certain scenarios. However, the core of these technologies is firmly held by a few centralized tech giants. With substantial capital and control over expensive computing resources, these companies have established insurmountable barriers, making it difficult for the vast majority of developers and innovation teams to compete.
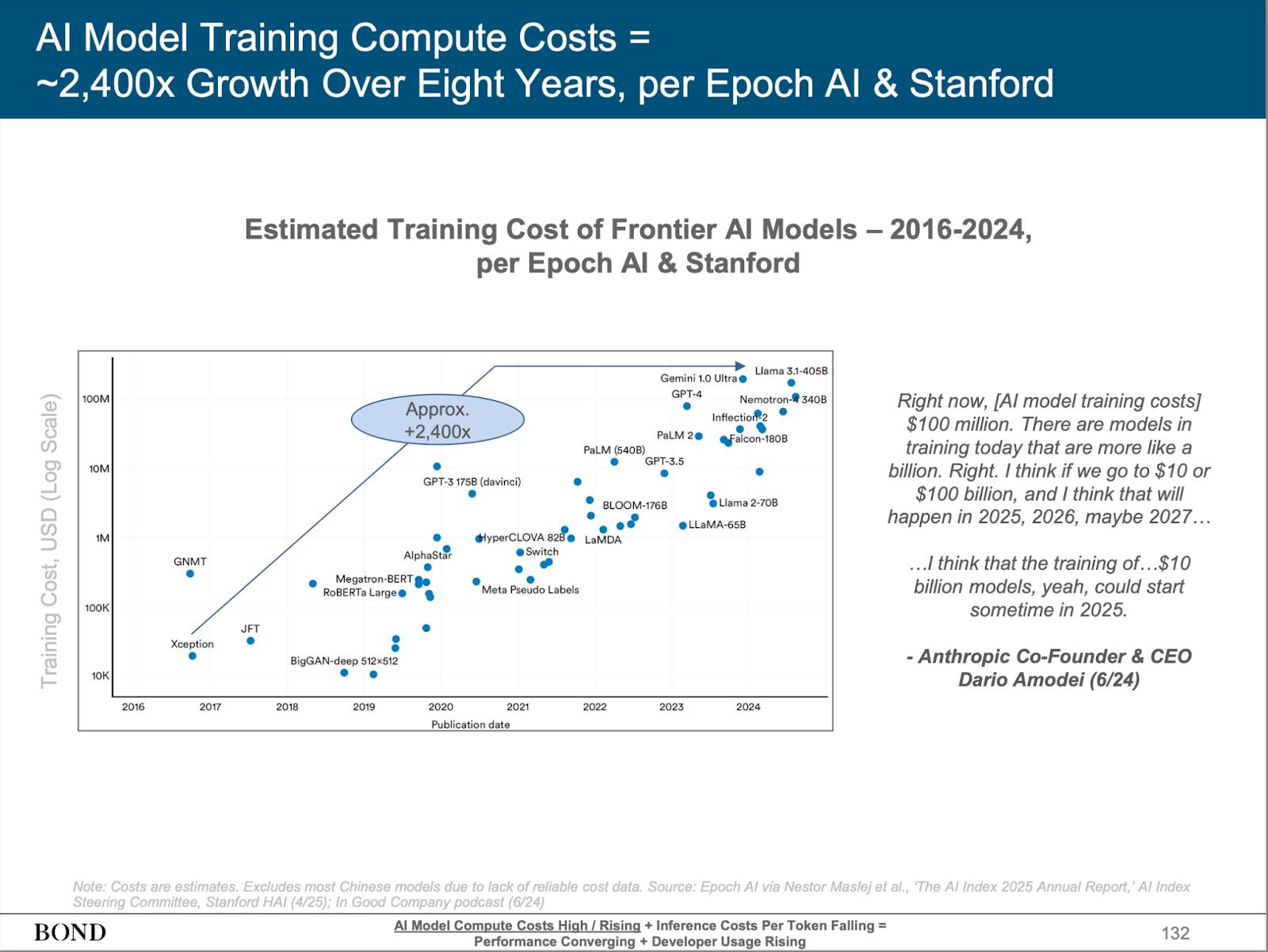
Source: BONDAI Trend Analysis Report
At the same time, during the early stages of AI's rapid evolution, public opinion often focuses on the breakthroughs and conveniences brought by technology, while relatively insufficient attention is paid to core issues such as privacy protection, transparency, and security. In the long run, these issues will profoundly impact the healthy development of the AI industry and societal acceptance. If not properly addressed, the debate over whether AI is "for good" or "for evil" will become increasingly prominent, while centralized giants, driven by profit motives, often lack sufficient motivation to proactively tackle these challenges.
Blockchain technology, with its decentralized, transparent, and censorship-resistant characteristics, offers new possibilities for the sustainable development of the AI industry. Currently, numerous "Web3 AI" applications have emerged on mainstream blockchains such as Solana and Base. However, a deeper analysis reveals that these projects still face many issues: on one hand, the degree of decentralization is limited, with key links and infrastructure still relying on centralized cloud services, and the meme attributes are too heavy to support a truly open ecosystem; on the other hand, compared to AI products in the Web2 world, on-chain AI still shows limitations in model capabilities, data utilization, and application scenarios, with room for improvement in both the depth and breadth of innovation.
To truly realize the vision of decentralized AI, enabling blockchain to securely, efficiently, and democratically support large-scale AI applications, and to compete with centralized solutions in performance, we need to design a Layer 1 blockchain specifically tailored for AI. This will provide a solid foundation for open innovation, democratic governance, and data security in AI, promoting the prosperous development of a decentralized AI ecosystem.
Core Features of AI Layer 1
As a blockchain specifically designed for AI applications, AI Layer 1's underlying architecture and performance design closely revolve around the needs of AI tasks, aiming to efficiently support the sustainable development and prosperity of the on-chain AI ecosystem. Specifically, AI Layer 1 should possess the following core capabilities:
Efficient incentive and decentralized consensus mechanism: The core of AI Layer 1 lies in building an open network for sharing resources such as computing power and storage. Unlike traditional blockchain nodes that primarily focus on ledger bookkeeping, nodes in AI Layer 1 need to undertake more complex tasks, not only providing computing power and completing AI model training and inference but also contributing diverse resources such as storage, data, and bandwidth, thereby breaking the monopoly of centralized giants on AI infrastructure. This places higher demands on the underlying consensus and incentive mechanisms: AI Layer 1 must accurately assess, incentivize, and verify nodes' actual contributions in AI inference, training, and other tasks, achieving network security and efficient resource allocation. Only in this way can the stability and prosperity of the network be ensured, effectively reducing overall computing costs.
Excellent high performance and heterogeneous task support capability: AI tasks, especially the training and inference of LLMs, impose extremely high demands on computing performance and parallel processing capabilities. Furthermore, the on-chain AI ecosystem often needs to support diverse and heterogeneous task types, including different model structures, data processing, inference, storage, and other varied scenarios. AI Layer 1 must deeply optimize its underlying architecture for high throughput, low latency, and elastic parallelism, and preset native support capabilities for heterogeneous computing resources, ensuring that various AI tasks can run efficiently and achieve smooth expansion from "single-type tasks" to "complex diverse ecosystems."
Verifiability and trustworthy output assurance: AI Layer 1 must not only prevent model malfeasance and data tampering but also ensure the verifiability and alignment of AI output results from the underlying mechanism. By integrating cutting-edge technologies such as Trusted Execution Environment (TEE), Zero-Knowledge Proof (ZK), and Multi-Party Computation (MPC), the platform can allow every model inference, training, and data processing process to be independently verified, ensuring the fairness and transparency of the AI system. Additionally, this verifiability can help users clarify the logic and basis of AI outputs, achieving "what is obtained is what is desired," thereby enhancing user trust and satisfaction with AI products.
Data privacy protection: AI applications often involve sensitive user data, and data privacy protection is particularly critical in fields such as finance, healthcare, and social networking. AI Layer 1 should ensure data security throughout the entire process of inference, training, and storage by employing encrypted data processing technologies, privacy computing protocols, and data permission management, effectively preventing data leakage and misuse, and alleviating users' concerns about data security.
Strong ecological support and development capabilities: As an AI-native Layer 1 infrastructure, the platform must not only possess technological leadership but also provide comprehensive development tools, integrated SDKs, operational support, and incentive mechanisms for developers, node operators, AI service providers, and other ecosystem participants. By continuously optimizing platform usability and developer experience, it promotes the landing of rich and diverse AI-native applications, achieving the sustained prosperity of a decentralized AI ecosystem.
Based on the above background and expectations, this article will detail six representative AI Layer 1 projects, including Sentient, Sahara AI, Ritual, Gensyn, Bittensor, and 0G, systematically reviewing the latest developments in the track, analyzing the current status of project development, and discussing future trends.
Sentient: Building a Loyal Open Source Decentralized AI Model
Project Overview
Sentient is an open-source protocol platform that is building an AI Layer 1 blockchain (initially as Layer 2, then migrating to Layer 1) by combining AI Pipeline and blockchain technology to create a decentralized artificial intelligence economy. Its core goal is to address issues of model ownership, invocation tracking, and value distribution in the centralized LLM market through the "OML" framework (Open, Monetizable, Loyal), enabling on-chain ownership structures, transparent invocation, and value sharing for AI models. Sentient's vision is to allow anyone to build, collaborate, own, and monetize AI products, thereby promoting a fair and open AI Agent network ecosystem.
The Sentient Foundation team brings together top academic experts, blockchain entrepreneurs, and engineers from around the world, dedicated to building a community-driven, open-source, and verifiable AGI platform. Core members include Princeton University professor Pramod Viswanath and Indian Institute of Science professor Himanshu Tyagi, responsible for AI security and privacy protection, while Polygon co-founder Sandeep Nailwal leads blockchain strategy and ecosystem layout. Team members come from renowned companies such as Meta, Coinbase, and Polygon, as well as top universities like Princeton University and the Indian Institutes of Technology, covering fields such as AI/ML, NLP, and computer vision, working together to promote project implementation.
As a second venture of Polygon co-founder Sandeep Nailwal, Sentient started with a strong reputation, rich resources, connections, and market recognition, providing robust backing for project development. In mid-2024, Sentient completed a $85 million seed round financing, led by Founders Fund, Pantera, and Framework Ventures, with other investment institutions including Delphi, Hashkey, and dozens of well-known VCs.
Design Architecture and Application Layer
Infrastructure Layer
Core Architecture
The core architecture of Sentient consists of two parts: the AI Pipeline and the blockchain system.
The AI Pipeline is the foundation for developing and training "Loyal AI" artifacts, comprising two core processes:
Data Curation: A community-driven data selection process for model alignment.
Loyalty Training: A training process that ensures the model remains consistent with community intentions.
The blockchain system provides transparency and decentralized control for the protocol, ensuring ownership, usage tracking, revenue distribution, and fair governance of AI artifacts. The specific architecture is divided into four layers:
Storage Layer: Stores model weights and fingerprint registration information.
Distribution Layer: Authorization contracts control model invocation entry.
Access Layer: Verifies user authorization through permission proofs.
Incentive Layer: Revenue routing contracts allocate payments from each invocation to trainers, deployers, and verifiers.
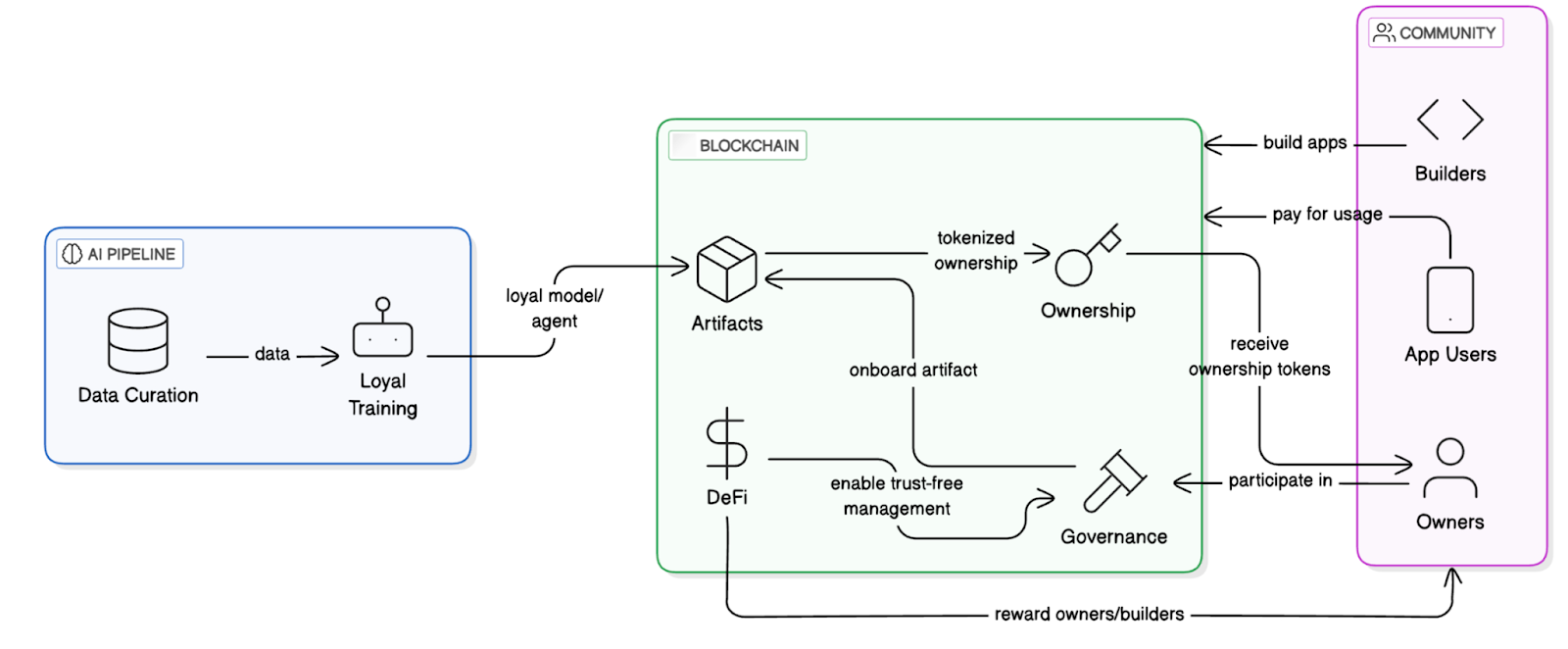
Sentient System Workflow Diagram
OML Model Framework
The OML framework (Open, Monetizable, Loyal) is the core concept proposed by Sentient, aiming to provide clear ownership protection and economic incentive mechanisms for open-source AI models. By combining on-chain technology and AI-native cryptography, it has the following characteristics:
Openness: Models must be open-source, with transparent code and data structures, facilitating community reproduction, auditing, and improvement.
Monetization: Each model invocation triggers a revenue stream, with on-chain contracts distributing revenue to trainers, deployers, and verifiers.
Loyalty: Models belong to the contributor community, with upgrade directions and governance determined by a DAO, and usage and modification controlled by cryptographic mechanisms.
AI-native Cryptography
AI-native cryptography utilizes the continuity, low-dimensional manifold structure, and differentiable characteristics of AI models to develop a "verifiable but non-removable" lightweight security mechanism. Its core technologies include:
Fingerprint embedding: Inserting a set of concealed query-response key-value pairs during training to form a unique signature for the model;
Ownership verification protocol: Verifying whether the fingerprint is retained through a third-party detector (Prover) in the form of query questions;
Permission calling mechanism: A "permission credential" issued by the model owner must be obtained before invocation, and the system then authorizes the model to decode the input and return an accurate answer.
This approach enables "behavior-based authorized calling + ownership verification" without the cost of re-encryption.
Model Ownership Confirmation and Secure Execution Framework
Sentient currently employs Melange mixed security: combining fingerprint ownership confirmation, TEE execution, and on-chain contract revenue sharing. The fingerprint method serves as the mainline implementation of OML 1.0, emphasizing the concept of "Optimistic Security," which assumes compliance by default, with violations being detectable and punishable.
The fingerprint mechanism is a key implementation of OML, embedding specific "question-answer" pairs that allow the model to generate a unique signature during the training phase. Through these signatures, model owners can verify ownership, preventing unauthorized copying and commercialization. This mechanism not only protects the rights of model developers but also provides a traceable on-chain record of model usage behavior.
Additionally, Sentient has launched the Enclave TEE computing framework, utilizing Trusted Execution Environments (such as AWS Nitro Enclaves) to ensure that models only respond to authorized requests, preventing unauthorized access and use. Although TEE relies on hardware and has certain security risks, its high performance and real-time advantages make it a core technology for current model deployment.
In the future, Sentient plans to introduce Zero-Knowledge Proof (ZK) and Fully Homomorphic Encryption (FHE) technologies to further enhance privacy protection and verifiability, providing more mature solutions for the decentralized deployment of AI models.
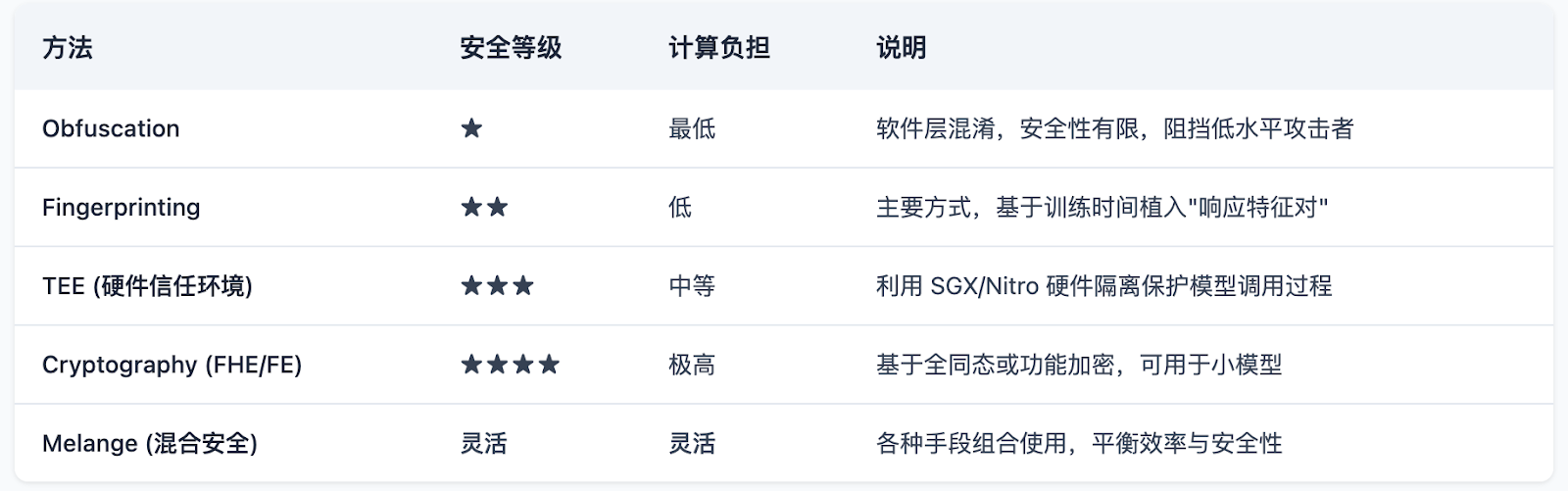
OML proposes five methods for assessing and comparing verifiability.
Application Layer
Currently, Sentient's products mainly include the decentralized chat platform Sentient Chat, the open-source Dobby series models, and the AI Agent framework.
Dobby Series Models
SentientAGI has released several "Dobby" series models, primarily based on the Llama model, focusing on values of freedom, decentralization, and cryptocurrency support. Among them, the leashed version is more constrained and rational, suitable for stable output scenarios; the unhinged version leans towards freedom and boldness, featuring a richer dialogue style. The Dobby models have been integrated into several Web3 native projects, such as Firework AI and Olas, and users can directly invoke these models for interaction in Sentient Chat. Dobby 70B is the most decentralized model ever, with over 600,000 owners (those holding Dobby fingerprint NFTs are also co-owners of the model).
Sentient also plans to launch Open Deep Search, a search agent system attempting to surpass ChatGPT and Perplexity Pro. This system combines Sensient's search capabilities (such as query rephrasing and document processing) with reasoning agents to enhance search quality using open-source LLMs (such as Llama 3.1 and DeepSeek). Its performance has already surpassed other open-source models on the Frames Benchmark, even approaching some closed-source models, demonstrating strong potential.
Sentient Chat: Decentralized Chat and On-Chain AI Agent Integration
Sentient Chat is a decentralized chat platform that combines open-source large language models (such as the Dobby series) with an advanced reasoning agent framework, supporting multi-agent integration and complex task execution. The embedded reasoning agents can perform complex tasks such as searching, computing, and code execution, providing users with an efficient interactive experience. Additionally, Sentient Chat supports the direct integration of on-chain agents, currently including astrology Agent Astro247, crypto analysis Agent QuillCheck, wallet analysis Agent Pond Base Wallet Summary, and spiritual guidance Agent ChiefRaiin. Users can choose different intelligent agents for interaction based on their needs. Sentient Chat will serve as a distribution and coordination platform for agents. Users' questions can be routed to any integrated model or agent to provide optimal response results.
AI Agent Framework
Sentient offers two major AI Agent frameworks:
Sentient Agent Framework: A lightweight open-source framework focused on automating Web tasks through natural language instructions (such as searching and playing videos). The framework supports building agents with perception, planning, execution, and feedback loops, suitable for lightweight development of off-chain Web tasks.
Sentient Social Agent: An AI system developed for social platforms (such as Twitter, Discord, and Telegram) that supports automated interaction and content generation. Through multi-agent collaboration, this framework can understand social environments and provide users with a more intelligent social experience, while also integrating with the Sentient Agent Framework to further expand its application scenarios.
Ecosystem and Participation
The Sentient Builder Program currently has a $1 million funding plan aimed at encouraging developers to utilize its development kit to build AI Agents that connect through the Sentient Agent API and can operate within the Sentient Chat ecosystem. The ecosystem partners announced on the Sentient official website cover project teams in various fields of Crypto AI, as follows:

Sentient Ecosystem Diagram
Additionally, Sentient Chat is currently in a testing phase and requires an invitation code to access the whitelist; ordinary users can submit a waitlist. According to official information, there are already over 50,000 users and 1,000,000 query records. There are 2,000,000 users on the waiting list for Sentient Chat.
Challenges and Outlook
Sentient starts from the model end, aiming to address the core issues of misalignment and untrustworthiness faced by current large-scale language models (LLM) through the OML framework and blockchain technology, providing clear ownership structures, usage tracking, and behavioral constraints for models, significantly promoting the development of decentralized open-source models.
With the resource support of Polygon co-founder Sandeep Nailwal and endorsements from top VCs and industry partners, Sentient is in a leading position in resource integration and market attention. However, in the current market context of gradually demystifying high-valuation projects, whether Sentient can deliver truly impactful decentralized AI products will be a significant test of its ability to become a standard for decentralized AI ownership. These efforts not only concern Sentient's own success but also have far-reaching implications for the trust rebuilding and decentralized development of the entire industry.
Sahara AI: Building a Decentralized AI World for Everyone
Project Overview
Sahara AI is a decentralized infrastructure born for the AI × Web3 new paradigm, dedicated to building an open, fair, and collaborative artificial intelligence economy. The project utilizes decentralized ledger technology to achieve on-chain management and trading of datasets, models, and intelligent agents, ensuring the sovereignty and traceability of data and models. At the same time, Sahara AI introduces transparent and fair incentive mechanisms, allowing all contributors, including data providers, annotators, and model developers, to receive immutable income returns during the collaboration process. The platform also protects contributors' ownership and attribution of AI assets through a permissionless "copyright" system, encouraging open sharing and innovation.
Sahara AI provides a one-stop solution covering the entire AI lifecycle, from data collection and annotation to model training, AI agent creation, and AI asset trading, becoming a comprehensive ecological platform that meets AI development needs. Its product quality and technical capabilities have been highly recognized by top global companies and institutions such as Microsoft, Amazon, MIT, Motherson Group, and Snap, demonstrating strong industry influence and wide applicability.
Sahara is not just a research project but a deep-tech platform driven by leading technology entrepreneurs and investors, with a focus on practical implementation. Its core architecture has the potential to become a key support point for the landing of AI × Web3 applications. Sahara AI has received a total of $43 million in investment support from leading institutions such as Pantera Capital, Binance Labs, and Sequoia China; it was co-founded by USC tenured professor and 2023 Samsung Research Fellow Sean Ren and former Binance Labs investment director Tyler Zhou, with core team members from Stanford University, UC Berkeley, Microsoft, Google, Binance, and other top institutions, blending deep expertise from academia and industry.
Design Architecture
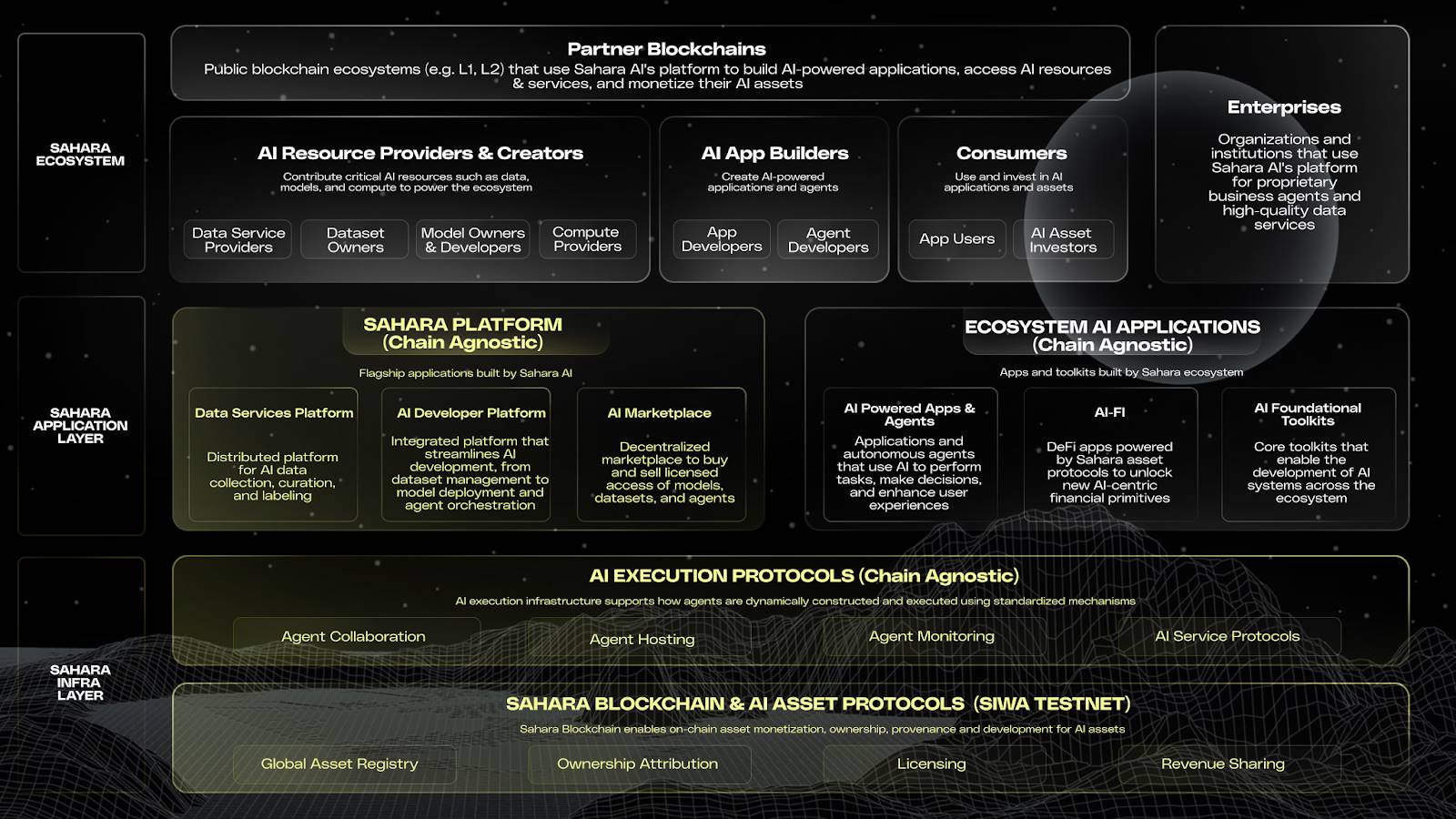
Sahara AI Architecture Diagram
Infrastructure Layer
The infrastructure layer of Sahara AI is divided into: 1. On-chain layer for the registration and monetization of AI assets, 2. Off-chain layer for running agents and AI services. The on-chain system and off-chain system work together to register, confirm ownership, execute, and distribute revenue for AI assets, supporting trustworthy collaboration throughout the entire AI lifecycle.
Sahara Blockchain and SIWA Testnet (On-Chain Infrastructure)
The SIWA testnet is the first public version of the Sahara blockchain. The Sahara Blockchain Protocol (SBP) is the core of the Sahara blockchain, which is a smart contract system specifically designed for AI, enabling on-chain ownership, traceability, and revenue distribution of AI assets. Core modules include asset registration system, ownership protocol, contribution tracking, permission management, revenue distribution, execution proof, etc., creating an "on-chain operating system" for AI.
AI Execution Protocol (Off-Chain Infrastructure)
To support the trustworthiness of model operation and invocation, Sahara has also built an off-chain AI execution protocol system, combined with Trusted Execution Environments (TEE), supporting the creation, deployment, operation, and collaborative development of agents. Each task execution automatically generates verifiable records and uploads them on-chain, ensuring the entire process is traceable and verifiable. The on-chain system is responsible for registration, authorization, and ownership records, while the off-chain AI execution protocol supports real-time operation and service interaction of AI agents.
Due to Sahara's cross-chain compatibility, applications built on the Sahara AI infrastructure can be deployed on any chain, even off-chain.
Application Layer
Sahara AI Data Service Platform (DSP)
The Data Service Platform (DSP) is the foundational module of the Sahara application layer, where anyone can accept data tasks through Sahara ID, participate in data annotation, denoising, and auditing, and receive on-chain point rewards (Sahara Points) as proof of contribution. This mechanism not only ensures data traceability and ownership but also promotes a closed loop of "contribution-reward-model optimization." Currently, it is in the fourth quarter of activities, which is the main way for ordinary users to contribute.
On this basis, to encourage users to submit high-quality data and services, a dual incentive mechanism is introduced, allowing contributors to receive rewards provided by Sahara as well as additional returns from ecosystem partners, achieving multiple benefits from a single contribution. For example, data contributors can continuously earn revenue once their data is repeatedly called by models or used to generate new applications, truly participating in the AI value chain. This mechanism not only extends the lifecycle of data assets but also injects strong momentum into collaboration and co-construction. For instance, MyShell on the BNB Chain generates custom datasets through DSP crowdsourcing to enhance model performance, while users receive MyShell token incentives, forming a win-win loop.
AI companies can use the data service platform to crowdsource custom datasets by publishing specific data tasks, quickly receiving responses from data annotators located worldwide. AI companies no longer rely solely on traditional centralized data suppliers and can obtain high-quality annotated data on a large scale.
Sahara AI Developer Platform
The Sahara AI Developer Platform is a one-stop AI building and operation platform for developers and enterprises, providing full-process support from data acquisition, model training to deployment execution and asset monetization. Users can directly call high-quality data resources in Sahara DSP for model training and fine-tuning; completed models can be combined, registered, and listed in the AI marketplace on the platform, achieving ownership confirmation and flexible authorization through the Sahara blockchain. The Studio also integrates decentralized computing capabilities, supporting model training and agent deployment, ensuring the security and verifiability of the computing process. Developers can also store key data and models, conduct encrypted hosting and permission control to prevent unauthorized access. Through the Sahara AI Developer Platform, developers can build, deploy, and commercialize AI applications at a lower threshold without having to build their own infrastructure, fully integrating into the on-chain AI economic system through protocol mechanisms.
AI Marketplace
The Sahara AI Marketplace is a decentralized asset market for models, datasets, and AI agents. It not only supports asset registration, trading, and authorization but also builds a transparent and traceable revenue distribution mechanism. Developers can register their built models or collected datasets as on-chain assets, set flexible usage authorizations and profit-sharing ratios, and the system will automatically execute revenue settlement based on usage frequency. Data contributors can also continuously earn revenue from their data being repeatedly called, achieving "sustained monetization."
This marketplace is deeply integrated with the Sahara blockchain protocol, ensuring that all asset transactions, calls, and profit-sharing records are verifiable on-chain, clarifying asset ownership and enabling traceable revenue. With this marketplace, AI developers no longer rely on traditional API platforms or centralized model hosting services but have independent, programmable commercialization paths.
Ecosystem Layer
The ecosystem layer of Sahara AI connects data providers, AI developers, consumers, enterprise users, and cross-chain partners. Whether one wants to contribute data, develop applications, use products, or promote AI within enterprises, they can play a role and find revenue models. Data annotators, model development teams, and computing power providers can register their resources as on-chain assets, authorize and share profits through Sahara AI's protocol mechanism, allowing every resource used to automatically receive returns. Developers can connect data, train models, and deploy agents through a one-stop platform, directly commercializing their results in the AI Marketplace.
Ordinary users can participate in data tasks, use AI apps, collect or invest in on-chain assets without needing a technical background, becoming part of the AI economy. For enterprises, Sahara provides full-process support from data crowdsourcing, model development to private deployment and revenue monetization. In addition, Sahara supports cross-chain deployment, allowing any public chain ecosystem to use the protocols and tools provided by Sahara AI to build AI applications and access decentralized AI assets, achieving compatibility and expansion in a multi-chain world. This makes Sahara AI not just a single platform but a foundational collaborative standard for an on-chain AI ecosystem.
Ecosystem Progress
Since the project's launch, Sahara AI has not only provided a set of AI tools or computing power platforms but has also reconstructed the production and distribution order of AI on-chain, creating a decentralized collaborative network that everyone can participate in, confirm ownership, contribute, and share. For this reason, Sahara has chosen blockchain as the underlying architecture to build a verifiable, traceable, and distributable economic system for AI.
Around this core goal, the Sahara ecosystem has made significant progress. While still in the private testing phase, the platform has generated over 3.2 million on-chain accounts, with daily active accounts stabilizing at over 1.4 million, demonstrating user engagement and network vitality. Among them, over 200,000 users have participated in data annotation, training, and validation tasks through the Sahara Data Service Platform and received on-chain incentive rewards. At the same time, millions of users are still waiting to join the whitelist, confirming the strong demand and consensus in the market for decentralized AI platforms.
In terms of corporate collaboration, Sahara has established partnerships with leading global institutions such as Microsoft, Amazon, and MIT, providing customized data collection and annotation services. Enterprises can submit specific tasks through the platform, efficiently executed by a network of global data annotators, achieving scalable crowdsourcing and advantages in execution efficiency, flexibility, and support for diverse needs.
Sahara AI Ecosystem Diagram
Participation Methods
SIWA will be launched in four phases. The first phase lays the foundation for on-chain data ownership, allowing contributors to register and tokenize their datasets. This phase is currently open to the public without requiring a whitelist. It is necessary to ensure that the uploaded data is useful for AI; plagiarism or inappropriate content may be subject to processing.
SIWA Testnet
The second phase will achieve on-chain monetization of datasets and models. The third phase will open the testnet and open-source the protocol. The fourth phase will introduce AI data flow registration, traceability tracking, and contribution proof mechanisms.
In addition to the SIWA testnet, ordinary users can currently participate in Sahara Legends, learning about the functions of Sahara AI through gamified tasks. After completing tasks, they earn Guardian fragments, which can ultimately be synthesized into an NFT to record their contributions to the network.
Alternatively, users can annotate data on the data service platform, contribute valuable data, and serve as auditors. Sahara plans to collaborate with ecosystem partners to release tasks, allowing participants to earn not only Sahara points but also incentives from ecosystem partners. The first dual-reward task is being held in collaboration with MyShell, where users can earn Sahara points and MyShell token rewards for completing tasks.
According to the roadmap, Sahara expects to launch the mainnet in Q3 2025, which may also welcome the TGE.
Challenges and Outlook
Sahara AI makes AI no longer limited to developers or large AI companies, making AI more open, inclusive, and democratized. For ordinary users, there is no need for programming knowledge to participate in contributions and earn rewards; Sahara AI is building a decentralized AI world that everyone can participate in. For technical developers, Sahara AI bridges the development paths of Web2 and Web3, providing decentralized yet flexible and powerful development tools and high-quality datasets. For AI infrastructure providers, Sahara AI offers new paths for decentralized monetization of models, data, computing power, and services. Sahara AI is not only building public chain infrastructure but also engaging in core applications, using blockchain technology to promote the development of AI copyright systems. At this stage, Sahara AI has already achieved initial success through partnerships with several top AI institutions. Future success should be observed based on performance after the mainnet launch, the development and adoption of ecosystem products, and whether the economic model can drive users to continue contributing to datasets after the TGE.
Ritual: Innovative Design Breakthroughs for Core AI Challenges such as Heterogeneous Tasks
Project Overview
Ritual aims to address the centralization, closed nature, and trust issues present in the current AI industry, providing transparent verification mechanisms, fair allocation of computing resources, and flexible model adaptation capabilities; allowing any protocol, application, or smart contract to integrate verifiable AI models with just a few lines of code; and promoting the widespread application of AI on-chain through its open architecture and modular design, creating an open, secure, and sustainable AI ecosystem.
Ritual completed a $25 million Series A funding round in November 2023, led by Archetype, with participation from several institutions and well-known angel investors, demonstrating market recognition and the team's strong social capabilities. Founders Niraj Pant and Akilesh Potti are both former partners at Polychain Capital, having led investments in industry giants such as Offchain Labs and EigenLayer, showcasing profound insights and judgment. The team has extensive experience in cryptography, distributed systems, and AI, with an advisory lineup that includes founders of projects like NEAR and EigenLayer, highlighting their strong background and potential.
Design Architecture
From Infernet to Ritual Chain
Ritual Chain is a second-generation product that naturally transitions from the Infernet node network, representing a comprehensive upgrade of Ritual's decentralized AI computing network.
Infernet is the first-phase product launched by Ritual, officially going live in 2023. It is a decentralized oracle network designed for heterogeneous computing tasks, aimed at addressing the limitations of centralized APIs, allowing developers to call transparent and open decentralized AI services more freely and stably.
Infernet employs a flexible and simple lightweight framework, and due to its ease of use and efficiency, it quickly attracted over 8,000 independent nodes after its launch. These nodes possess diverse hardware capabilities, including GPUs and FPGAs, capable of providing powerful computing power for complex tasks such as AI inference and zero-knowledge proof generation. However, to maintain system simplicity, Infernet sacrificed some key features, such as consensus coordination of nodes or integration of robust task routing mechanisms. These limitations made it difficult for Infernet to meet the broader needs of Web2 and Web3 developers, prompting Ritual to launch the more comprehensive and powerful Ritual Chain.
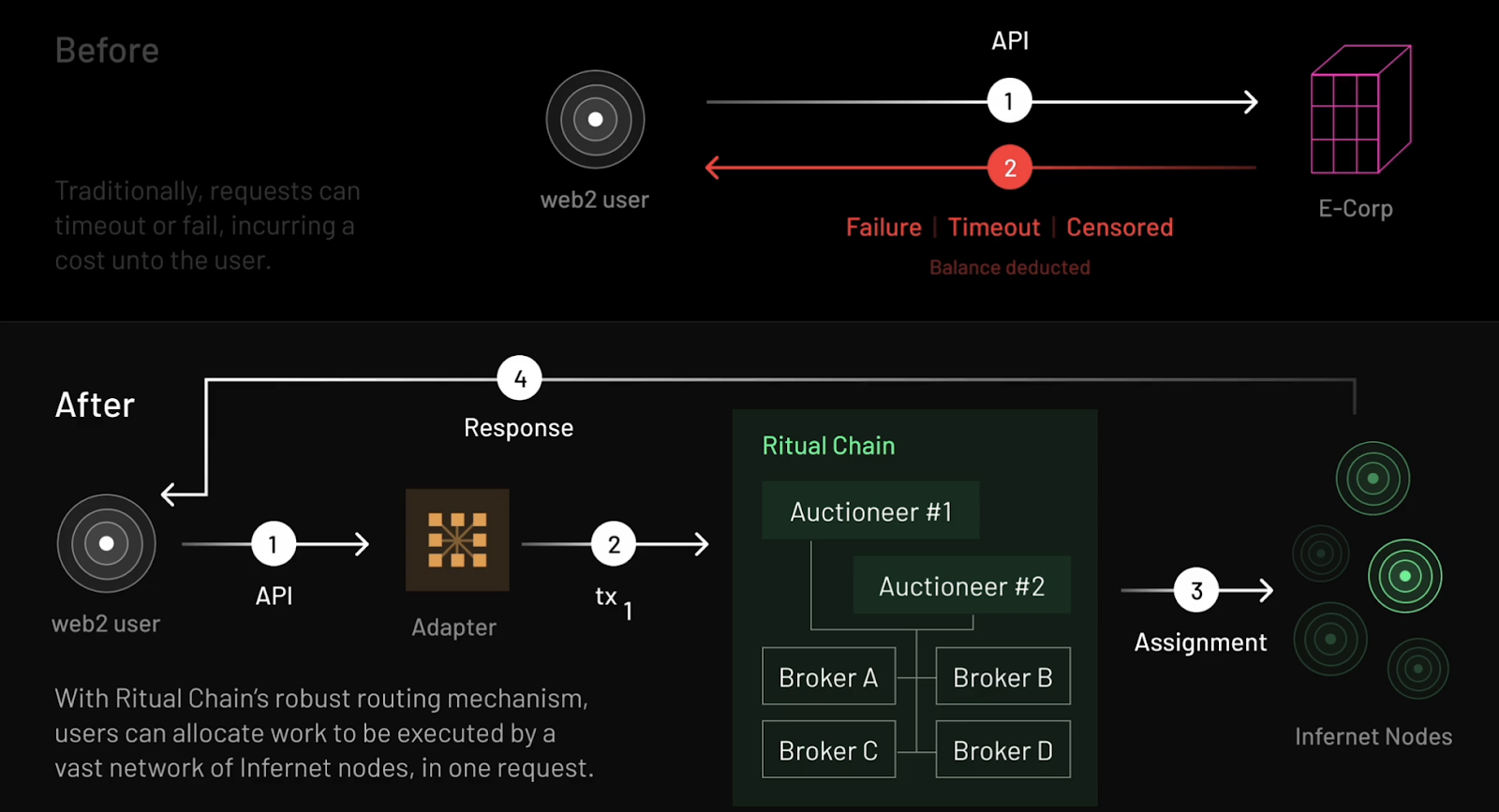
Ritual Chain Workflow Diagram
Ritual Chain is a next-generation Layer 1 blockchain designed for AI applications, aimed at addressing the limitations of Infernet and providing developers with a more robust and efficient development environment. Through Resonance technology, Ritual Chain offers a simple and reliable pricing and task routing mechanism for the Infernet network, significantly optimizing resource allocation efficiency. Additionally, Ritual Chain is based on the EVM++ framework, which is a backward-compatible extension of the Ethereum Virtual Machine (EVM) with more powerful features, including precompiled modules, native scheduling, built-in account abstraction (AA), and a series of advanced Ethereum Improvement Proposals (EIPs). These features collectively create a powerful, flexible, and efficient development environment, providing developers with new possibilities.
Precompiled Sidecars
Compared to traditional precompiles, the design of Ritual Chain enhances the system's scalability and flexibility, allowing developers to create custom functional modules in a containerized manner without modifying the underlying protocol. This architecture not only significantly reduces development costs but also provides more powerful computing capabilities for decentralized applications.
Specifically, Ritual Chain decouples complex computations from the execution client through a modular architecture, implementing them in independent Sidecars. These precompiled modules can efficiently handle complex computing tasks, including AI inference, zero-knowledge proof generation, and Trusted Execution Environment (TEE) operations.
Native Scheduling
Native scheduling addresses the need for task timing triggers and conditional execution. Traditional blockchains often rely on centralized third-party services (such as keepers) to trigger task execution, but this model carries centralization risks and high costs. Ritual Chain completely eliminates reliance on centralized services through its built-in scheduler, allowing developers to directly set entry points and callback frequencies for smart contracts on-chain. Block producers maintain a mapping table of pending calls, prioritizing these tasks when generating new blocks. Combined with Resonance's dynamic resource allocation mechanism, Ritual Chain can efficiently and reliably handle compute-intensive tasks, providing stable support for decentralized AI applications.
Technological Innovations
Ritual's core technological innovations ensure its leading position in performance, verification, and scalability, providing strong support for on-chain AI applications.
1. Resonance: Optimizing Resource Allocation
Resonance is a bilateral market mechanism that optimizes blockchain resource allocation, addressing the complexity of heterogeneous transactions. As blockchain transactions evolve from simple transfers to diverse forms such as smart contracts and AI inference, existing fee mechanisms (like EIP-1559) struggle to efficiently match user demands with node resources. Resonance introduces two core roles, Broker and Auctioneer, to achieve optimal matching between user transactions and node capabilities:
The Broker analyzes users' willingness to pay transaction fees and the resource cost functions of nodes to achieve the best match between transactions and nodes, enhancing the utilization of computing resources.
The Auctioneer organizes transaction fee distribution through a bilateral auction mechanism, ensuring fairness and transparency. Nodes choose transaction types based on their hardware capabilities, while users can submit transaction requests based on priority conditions (such as speed or cost).
This mechanism significantly improves the network's resource utilization efficiency and user experience while further enhancing the system's transparency and openness through a decentralized auction process.
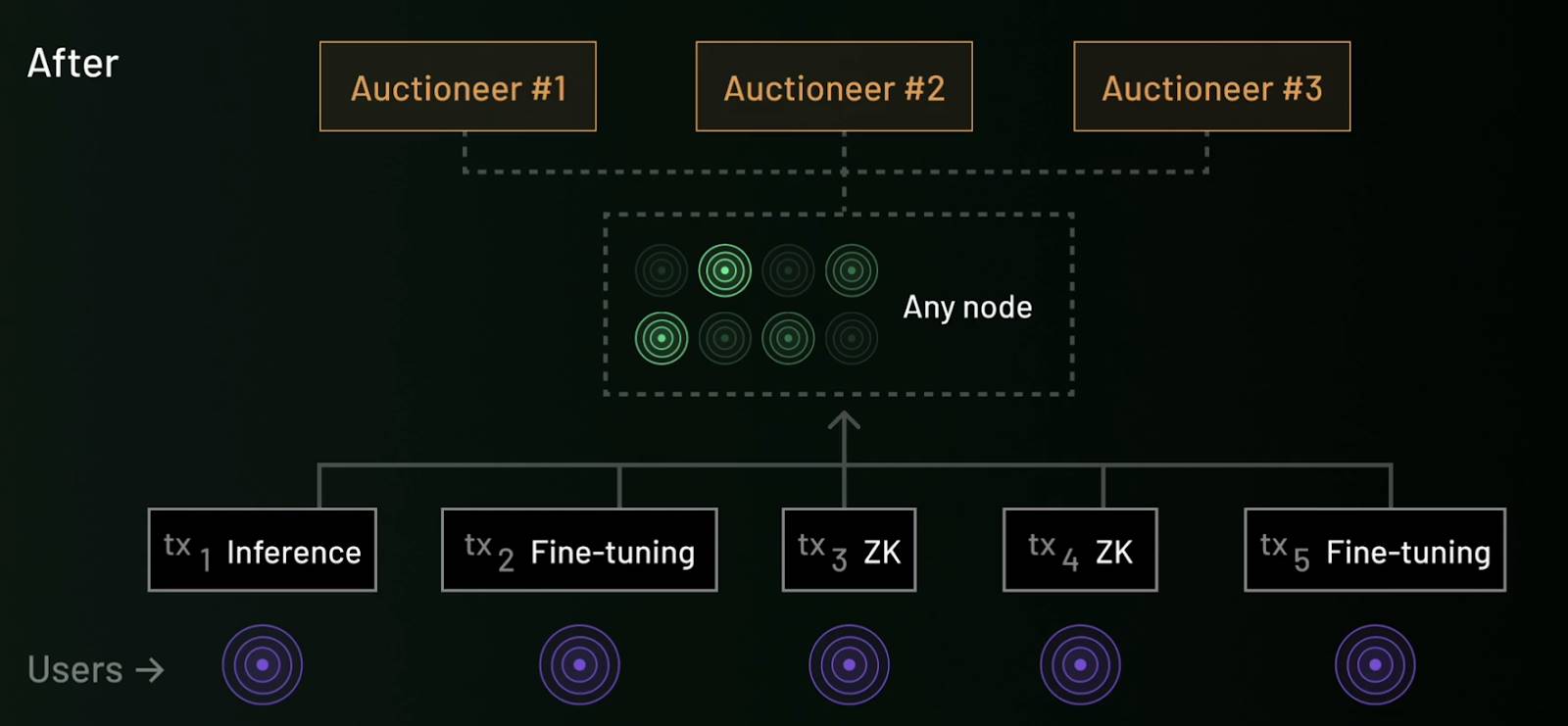
Under the Resonance mechanism: The Auctioneer assigns suitable tasks to nodes based on the Broker's analysis.
2. Symphony: Enhancing Verification Efficiency
Symphony focuses on improving verification efficiency, addressing the inefficiencies of the traditional blockchain "re-execution" model when handling and verifying complex computing tasks. Symphony is based on the "execute once, verify many times" (EOVMT) model, significantly reducing performance losses from redundant computations by separating the computation and verification processes.
The computation task is executed once by a designated node, and the result is broadcasted across the network, where verification nodes use non-interactive proofs (succinct proofs) to confirm the correctness of the result without re-executing the computation.
Symphony supports distributed verification, breaking complex tasks into multiple sub-tasks processed in parallel by different verification nodes, further enhancing verification efficiency while ensuring privacy protection and security.
Symphony is highly compatible with proof systems such as Trusted Execution Environments (TEEs) and zero-knowledge proofs (ZKPs), providing flexible support for quickly confirming transactions and privacy-sensitive computing tasks. This architecture not only significantly reduces the performance overhead from redundant computations but also ensures the decentralization and security of the verification process.
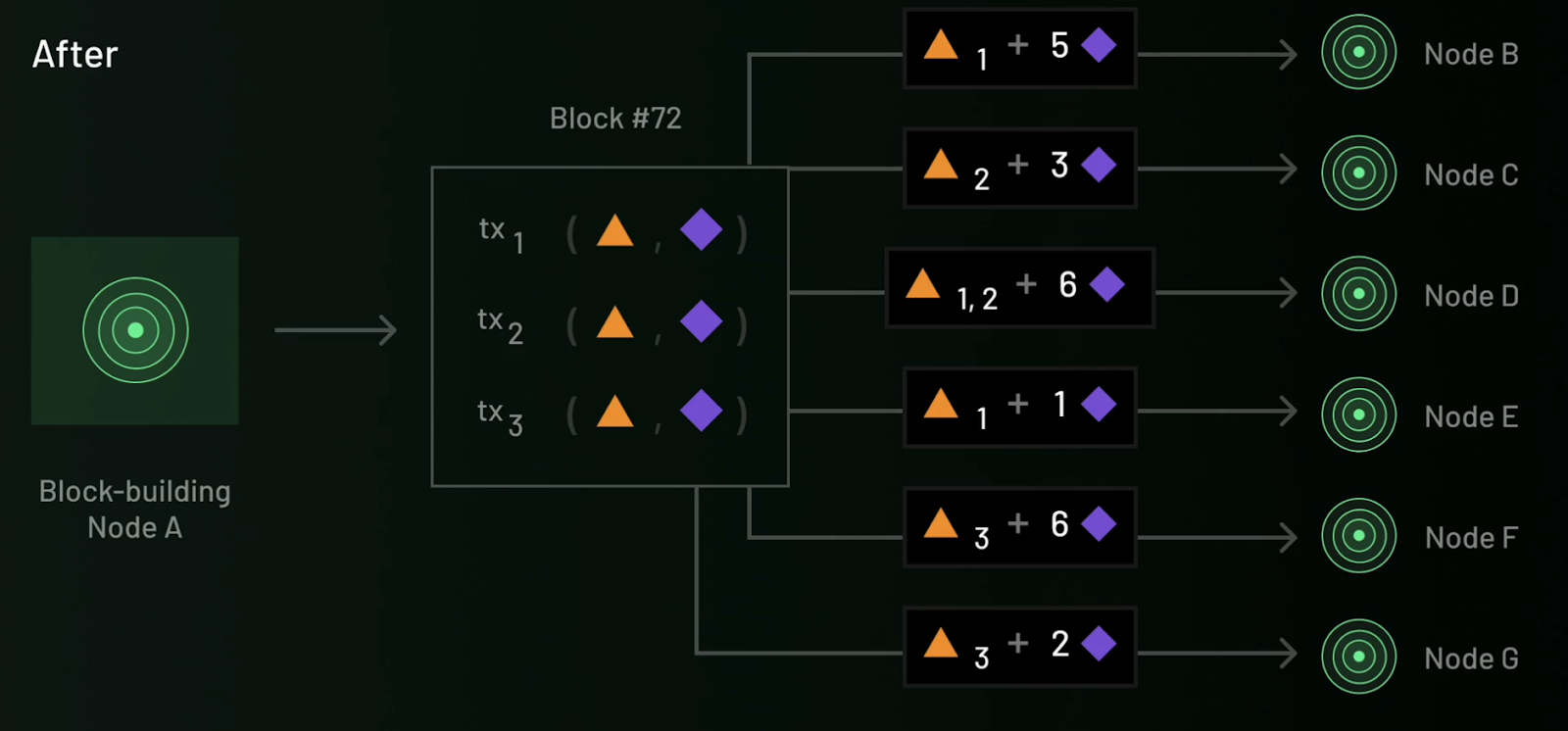
Symphony breaks complex tasks into multiple sub-tasks processed in parallel by different verification nodes.
3. vTune: Traceable Model Verification
vTune is a tool provided by Ritual for model verification and provenance tracking, having minimal impact on model performance while exhibiting good resistance to interference, making it particularly suitable for protecting the intellectual property of open-source models and promoting fair distribution. vTune combines watermarking technology and zero-knowledge proofs to achieve model provenance tracking and computational integrity assurance through embedding covert markers:
Watermarking technology: By embedding markers through weight space watermarks, data watermarks, or function space watermarks, ownership can still be verified even if the model is public. In particular, function space watermarks can verify ownership through model outputs without accessing model weights, thus achieving stronger privacy protection and robustness.
Zero-knowledge proofs: Covert data is introduced during model fine-tuning to verify whether the model has been tampered with while protecting the rights of the model creator.
This tool not only provides credible provenance verification for the decentralized AI model market but also significantly enhances the security and ecological transparency of models.
Ecological Development
Ritual is currently in the private testnet phase, with limited participation opportunities for ordinary users; developers can apply to participate in the official Altar and Realm incentive programs, joining Ritual's AI ecosystem construction and receiving full-stack technical and financial support from the official team.
Currently, the official team has announced a batch of native applications from the Altar program:
Relic: A machine learning-based automated market maker (AMM) that dynamically adjusts liquidity pool parameters through Ritual's infrastructure, optimizing fees and underlying pools;
Anima: An on-chain trading automation tool focused on LLM, providing users with a smooth and natural Web3 interaction experience;
Tithe: An AI-driven lending protocol that supports a wider range of asset types by dynamically optimizing lending pools and credit scoring.
In addition, Ritual has engaged in deep collaborations with several mature projects to promote the development of the decentralized AI ecosystem. For example, collaboration with Arweave provides decentralized permanent storage support for models, data, and zero-knowledge proofs; through integration with StarkWare and Arbitrum, Ritual introduces native on-chain AI capabilities to these ecosystems; furthermore, the restaking mechanism provided by EigenLayer adds proactive verification services to Ritual's proof market, further enhancing the network's decentralization and security.
Challenges and Outlook
Ritual's design addresses core issues faced by decentralized AI by focusing on key aspects such as allocation, incentives, and verification, while tools like vTune achieve model verifiability, breaking the contradiction between model open-sourcing and incentives, providing technical support for building a decentralized model market.
Currently, Ritual is in its early stages, primarily focusing on the inference phase of models. The product matrix is expanding from infrastructure to areas such as model markets, L2 as a Service (L2aaS), and Agent frameworks. As the blockchain is still in the private testing phase, the advanced technical design proposals put forth by Ritual are yet to be publicly implemented on a large scale, requiring ongoing attention. It is anticipated that with continuous technological improvements and gradual ecosystem enrichment, Ritual can become an important component of decentralized AI infrastructure.
Gensyn: Solving the Core Issues of Decentralized Model Training
Project Overview
In the context of accelerating advancements in artificial intelligence and increasingly scarce computing resources, Gensyn is attempting to reshape the underlying paradigm of AI model training.
In traditional AI model training processes, computing power is almost monopolized by a few cloud computing giants, leading to high training costs and low transparency, which hinders innovation for small and medium-sized teams and independent researchers. Gensyn's vision is to break this "centralized monopoly" structure by advocating for training tasks to be "decentralized" to countless devices with basic computing capabilities worldwide—whether it's a MacBook, a gaming-grade GPU, or edge devices and idle servers, all can connect to the network, participate in task execution, and earn rewards.
Founded in 2020, Gensyn focuses on building decentralized AI computing infrastructure. As early as 2022, the team proposed redefining the training methods of AI models at both the technical and institutional levels: no longer relying on closed cloud platforms or massive server clusters, but instead decentralizing training tasks to heterogeneous computing nodes worldwide, creating a trustless intelligent computing network.
In 2023, Gensyn further expanded its vision: to build a globally connected, open-source autonomous AI network with no licensing barriers—any device with basic computing capabilities can become part of this network. Its underlying protocol is designed based on blockchain architecture, featuring composability of incentive and verification mechanisms.
Since its inception, Gensyn has raised a total of $50.6 million, with investors including a16z, CoinFund, Canonical, Protocol Labs, Distributed Global, and a total of 17 institutions. Notably, the Series A funding round led by a16z in June 2023 received widespread attention, marking the entry of decentralized AI into the mainstream Web3 venture capital landscape.
The core team members also have impressive backgrounds: co-founder Ben Fielding studied theoretical computer science at the University of Oxford, possessing a strong technical research background; another co-founder, Harry Grieve, has long been involved in the system design and economic modeling of decentralized protocols, providing solid support for Gensyn's architectural design and incentive mechanisms.
Design Architecture
The current development of decentralized artificial intelligence systems faces three core technical bottlenecks: Execution, Verification, and Communication. These bottlenecks not only limit the release of large model training capabilities but also restrict the fair integration and efficient utilization of global computing resources. The Gensyn team, based on systematic research, has proposed three representative innovative mechanisms—RL Swarm, Verde, and SkipPipe—to construct solutions for the aforementioned issues, pushing decentralized AI infrastructure from concept to implementation.
1. Execution Challenge: How to Enable Fragmented Devices to Collaboratively Train Large Models Efficiently?
Currently, the performance improvement of large language models mainly relies on the "scale stacking" strategy: larger parameter counts, broader datasets, and longer training cycles. However, this significantly increases computing costs—training ultra-large models often requires splitting tasks across tens of thousands of GPU nodes, which need to communicate data and synchronize gradients frequently. In decentralized scenarios, nodes are widely distributed, hardware is heterogeneous, and state volatility is high, making traditional centralized scheduling strategies ineffective.
To address this challenge, Gensyn proposed RL Swarm, a peer-to-peer reinforcement learning post-training system. The core idea is to transform the training process into a distributed cooperative game. This mechanism consists of three stages: "Share—Critique—Decide." First, nodes independently complete problem reasoning and publicly share results; then, each node evaluates peer answers, providing feedback from logical and strategic perspectives; finally, nodes adjust their outputs based on collective opinions, generating more robust answers. This mechanism effectively integrates individual computation with collective collaboration, particularly suitable for tasks requiring high precision and verifiability, such as mathematical and logical reasoning. Experiments show that RL Swarm not only improves efficiency but also significantly lowers participation barriers, demonstrating good scalability and fault tolerance.
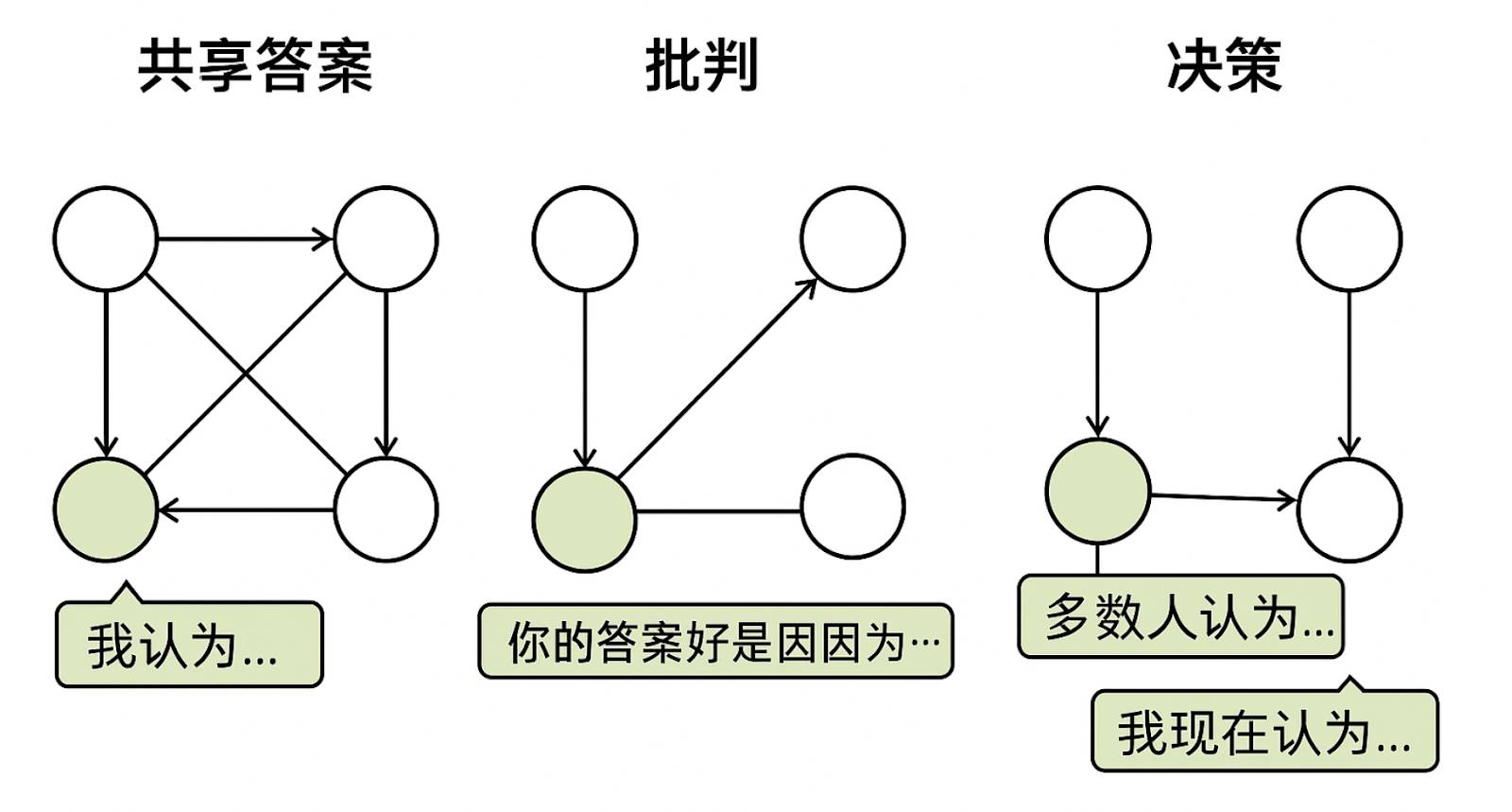
The "Share—Critique—Decide" Three-Stage Reinforcement Learning Training System of RL Swarm
2. Verification Challenge: How to Verify Whether the Computation Results of Untrusted Providers Are Correct?
In a decentralized training network, "anyone can provide computing power" is both an advantage and a risk. The question is: how to verify whether these computations are real and valid without trust?
Traditional methods such as re-computation or whitelisting audits have obvious limitations—the former is extremely costly and not scalable; the latter excludes "long-tail" nodes, undermining network openness. To address this, Gensyn designed Verde, a lightweight arbitration protocol specifically built for neural network training verification scenarios.
The key idea of Verde is "minimal trusted arbitration": when a verifier suspects that a provider's training result is incorrect, the arbitration contract only needs to re-compute the first disputed operation node in the computation graph, rather than replaying the entire training process. This significantly reduces the verification burden while ensuring the correctness of results when at least one party is honest. To address the issue of floating-point non-determinism between different hardware, Verde also developed Reproducible Operators, which enforce a unified execution order for common mathematical operations like matrix multiplication, achieving bit-level consistent outputs across devices. This technology significantly enhances the security and engineering feasibility of distributed training and represents an important breakthrough in the current trustless verification system.
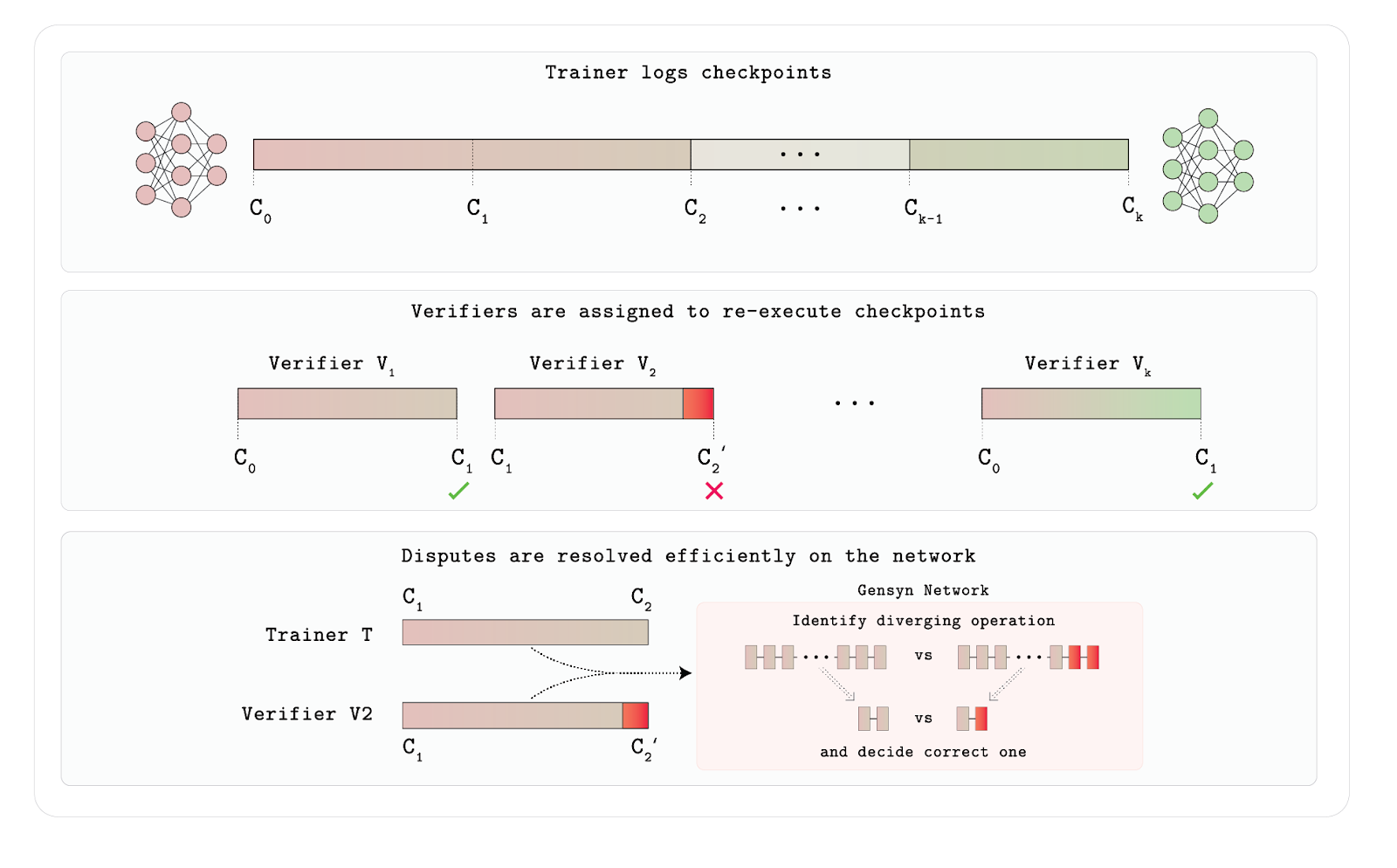
Workflow of Verde
The entire mechanism is based on the trainer recording key intermediate states (i.e., checkpoints), with multiple verifiers randomly assigned to reproduce these training steps to assess output consistency. If a verifier's recomputed result diverges from the trainer's, the system does not simply rerun the entire model but precisely locates the first operation in the computation graph where the two diverge through a network arbitration mechanism, replaying only that operation for comparison, thus achieving dispute resolution with minimal overhead. In this way, Verde ensures the integrity of the training process without trusting training nodes while balancing efficiency and scalability, making it a verification framework tailored for distributed AI training environments.
3. Communication Challenge: How to Reduce Network Bottlenecks Caused by High-Frequency Synchronization Between Nodes?
In traditional distributed training, models are either fully replicated or split by layers (pipeline parallelism), both requiring high-frequency synchronization between nodes. Especially in pipeline parallelism, a micro-batch must strictly pass through each layer of the model in order, leading to the entire training process being blocked if any node experiences a delay.
To address this issue, Gensyn proposed SkipPipe: a high-fault-tolerant pipeline training system that supports jump execution and dynamic path scheduling. SkipPipe introduces a "skip ratio" mechanism, allowing certain micro-batch data to skip parts of the model layers when specific nodes are overloaded, while using scheduling algorithms to dynamically select the currently optimal computation path. Experiments show that in geographically distributed, hardware-diverse, and bandwidth-constrained network environments, SkipPipe can reduce training time by up to 55% and maintain only a 7% loss even with a node failure rate of up to 50%, demonstrating strong resilience and adaptability.
Participation Method
Gensyn's public testnet was launched on March 31, 2025, and is currently still in the early phase (Phase 0) of its technical roadmap, focusing on the deployment and verification of RL Swarm. RL Swarm is Gensyn's first application scenario, designed around collaborative training of reinforcement learning models. Each participating node binds its behavior to an on-chain identity, and the contribution process is fully recorded, providing a verification basis for subsequent incentive distribution and trusted computing models.
Gensyn's Node Ranking
The hardware threshold during the early testing phase is relatively friendly: Mac users can run it with M-series chips, while Windows users are recommended to equip high-performance GPUs like 3090 or 4090, along with more than 16GB of memory, to deploy local Swarm nodes.
After the system is running, users can complete the verification process by logging in via email (Gmail is recommended) and can choose whether to bind a HuggingFace Access Token to activate more complete model capabilities.
Challenges and Outlook
Currently, the biggest uncertainty for the Gensyn project lies in the fact that its testnet has not yet covered the promised complete technology stack. Key modules like Verde and SkipPipe are still in the integration phase, which keeps external observers cautious about its architectural implementation capabilities. The official explanation is that the testnet will be rolled out in phases, with each phase unlocking new protocol capabilities, prioritizing the verification of infrastructure stability and scalability. The first phase starts with RL Swarm, and in the future, it will gradually expand to core scenarios such as pre-training and inference, ultimately transitioning to mainnet deployment that supports real economic transactions.
Although the initial launch of the testnet adopted a relatively conservative pace, it is noteworthy that just one month later, Gensyn launched new Swarm test tasks supporting larger-scale models and complex mathematical tasks. This move somewhat addresses external concerns about its development pace and demonstrates the team's execution efficiency in advancing local modules.
However, challenges also arise: the new tasks impose extremely high hardware requirements, recommending configurations including top-tier GPUs like A100 and H100 (with 80GB of memory), which are nearly unattainable for small and medium nodes, creating tension with Gensyn's emphasis on "open access and decentralized training." If the trend of computing power centralization is not effectively guided, it may impact the fairness of the network and the sustainability of decentralized governance.
Next, if Verde and SkipPipe can be successfully integrated, it will help enhance the integrity and collaborative efficiency of the protocol. However, whether Gensyn can truly find a balance between performance and decentralization still requires longer and broader practical testing of the testnet. At present, it has initially shown potential while also exposing challenges, which is the most authentic state of an early infrastructure project.
Bittensor: Innovation and Development of a Decentralized AI Network
Project Overview
Bittensor is a pioneering project that combines blockchain and artificial intelligence, founded by Jacob Steeves and Ala Shaabana in 2019, aiming to build a "market economy of machine intelligence." Both founders have a strong background in artificial intelligence and distributed systems. The project's white paper is co-authored by Yuma Rao, who is considered a core technical advisor to the team, injecting expertise in cryptography and consensus algorithms into the project.
The project aims to integrate global computing resources through a blockchain protocol, creating a self-optimizing distributed neural network ecosystem. This vision transforms digital assets such as computing, data, storage, and models into streams of intelligent value, establishing a new economic form that ensures fair distribution of AI development dividends. Unlike centralized platforms like OpenAI, Bittensor establishes three core value pillars:
Breaking data silos: Utilizing the TAO token incentive system to promote knowledge sharing and model contributions.
Market-driven quality evaluation: Introducing game theory mechanisms to filter high-quality AI models, achieving survival of the fittest.
Network effect amplifier: The growth of participants is exponentially positively correlated with network value, forming a virtuous cycle.
In terms of investment layout, Polychain Capital has been incubating Bittensor since 2019 and currently holds TAO tokens worth approximately $200 million; Dao5 holds about $50 million worth of TAO and is also an early supporter of the Bittensor ecosystem. In 2024, Pantera Capital and Collab Currency further increased their investment through strategic investments. In August of the same year, Grayscale included TAO in its decentralized AI fund, marking a high recognition of the project's value and long-term optimism from institutional investors.
Design Architecture and Operating Mechanism
Network Architecture
Bittensor has constructed a sophisticated network architecture composed of four collaborative layers:
Blockchain Layer: Built on the Substrate framework, serving as the trust foundation of the network, responsible for recording state changes and token issuance. The system generates new blocks every 12 seconds and issues TAO tokens according to rules, ensuring network consensus and incentive distribution.
Neuron Layer: Serving as the computing nodes of the network, neurons run various AI models to provide intelligent services. Each node clearly declares its service type and interface specifications through carefully designed configuration files, achieving modular functionality and plug-and-play capabilities.
Synapse Layer: The communication bridge of the network, dynamically optimizing connection weights between nodes to form a neural network-like structure, ensuring efficient information transmission. Synapses also incorporate an economic model, where interactions and service calls between neurons require payment in TAO tokens, forming a closed loop of value circulation.
Metagraph Layer: Serving as the global knowledge graph of the system, continuously monitoring and evaluating the contribution value of each node, providing intelligent guidance for the entire network. The metagraph determines synapse weights through precise calculations, thereby influencing resource allocation, reward mechanisms, and the influence of nodes within the network.
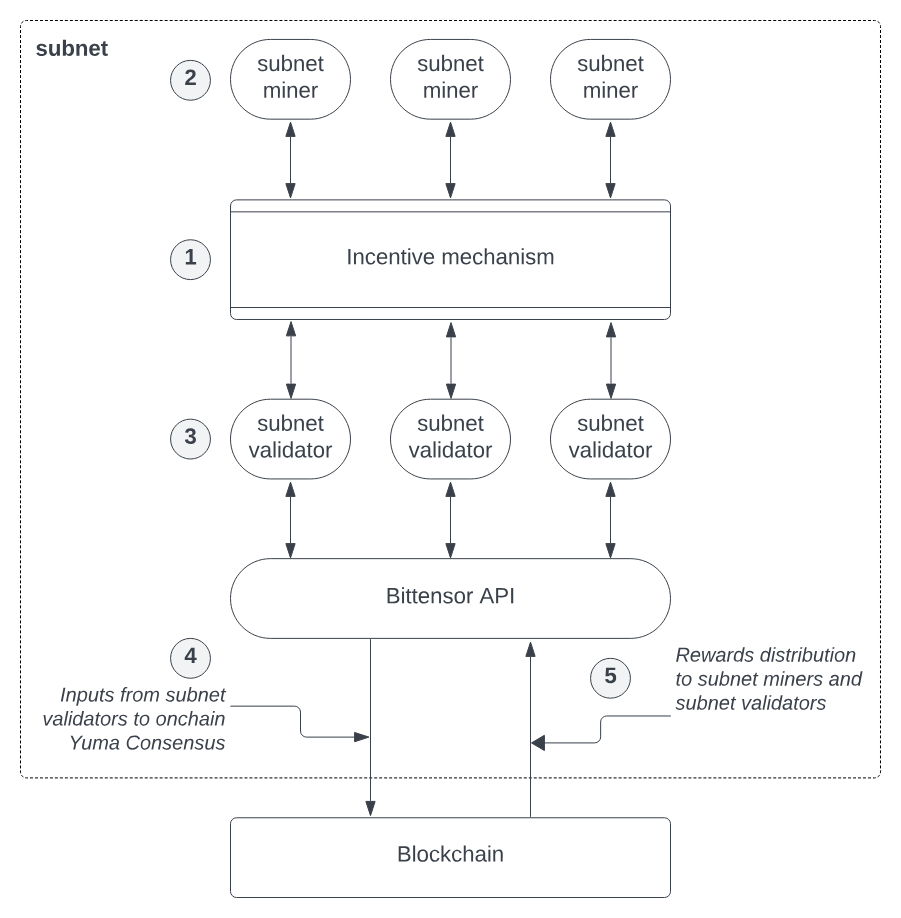
Bittensor's Network Framework
Yuma Consensus Mechanism
The network employs a unique Yuma consensus algorithm, completing a round of reward distribution every 72 minutes. The verification process combines subjective evaluation and objective measurement:
Human Scoring: Verifiers subjectively evaluate the quality of miner outputs.
Fisher Information Matrix: Objectively quantifies the contribution of nodes to the overall network.
This "subjective + objective" hybrid mechanism effectively balances professional judgment and algorithmic fairness.
Subnet Architecture and dTAO Upgrade
Each subnet focuses on a specific AI service area, such as text generation or image recognition, operating independently but maintaining a connection with the main blockchain subtensor, forming a highly flexible modular expansion architecture. In February 2025, Bittensor completed a milestone dTAO (Dynamic TAO) upgrade, transforming each subnet into an independent economic unit that intelligently regulates resource allocation through market demand signals. Its core innovation is the subnet token (Alpha token) mechanism:
Operating Principle: Participants stake TAO to obtain Alpha tokens issued by each subnet, which represent market recognition and support for specific subnet services.
Resource Allocation Logic: The market price of Alpha tokens serves as a key indicator of subnet demand intensity. Initially, the prices of Alpha tokens across subnets are consistent, with each liquidity pool containing only 1 TAO and 1 Alpha token. As trading activity increases and liquidity is injected, the price of Alpha tokens dynamically adjusts, and the distribution of TAO is intelligently allocated based on the price ratio of subnet tokens, allowing subnets with high market interest to receive more resource allocation, achieving truly demand-driven resource optimization.
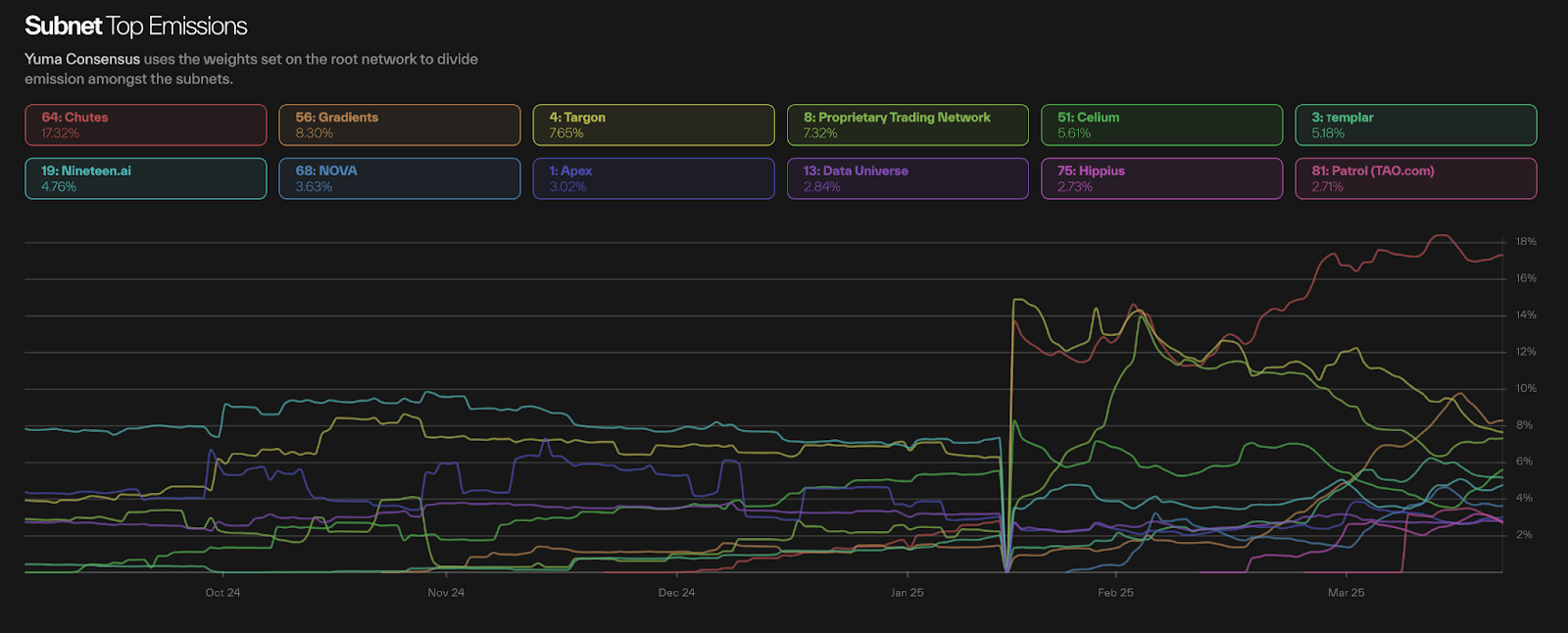
Bittensor Subnet Token Emission Distribution
The dTAO upgrade significantly enhances ecological vitality and resource utilization efficiency, with the total market value of subnet tokens reaching $500 million, demonstrating strong growth momentum.
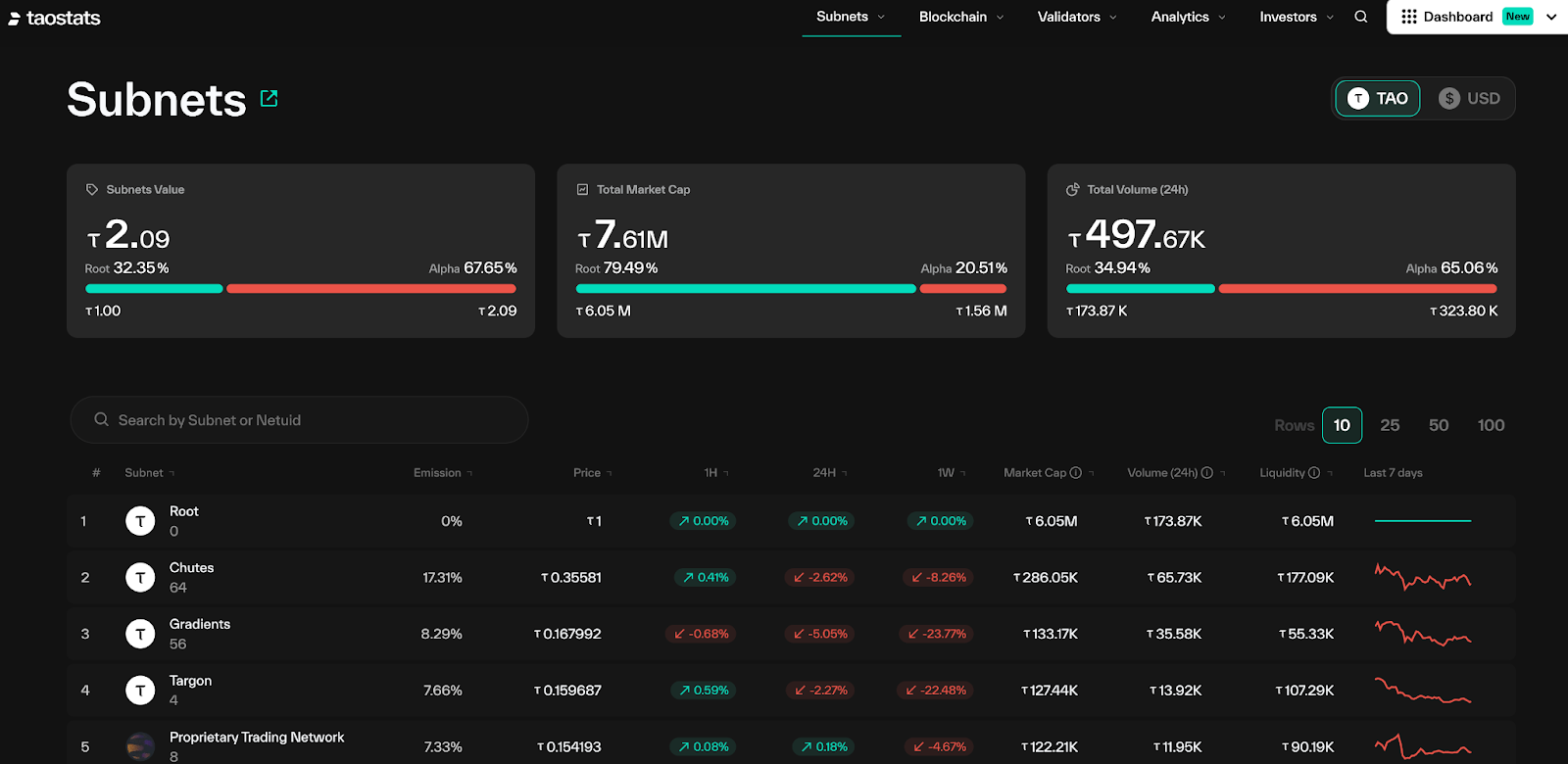 Bittensor Subnet Alpha Token Value
Bittensor Subnet Alpha Token Value
Ecological Progress and Application Cases
Mainnet Development History
The Bittensor network has gone through three key development stages:
January 2021: The mainnet officially launched, laying the foundational infrastructure.
October 2023: The "Revolution" upgrade introduced the subnet architecture, achieving functional modularization.
February 2025: Completed the dTAO upgrade, establishing a market-driven resource allocation mechanism.
The subnet ecosystem has experienced explosive growth: as of April 2025, there are already 95 specialized subnets, with expectations to exceed 200 within the year.
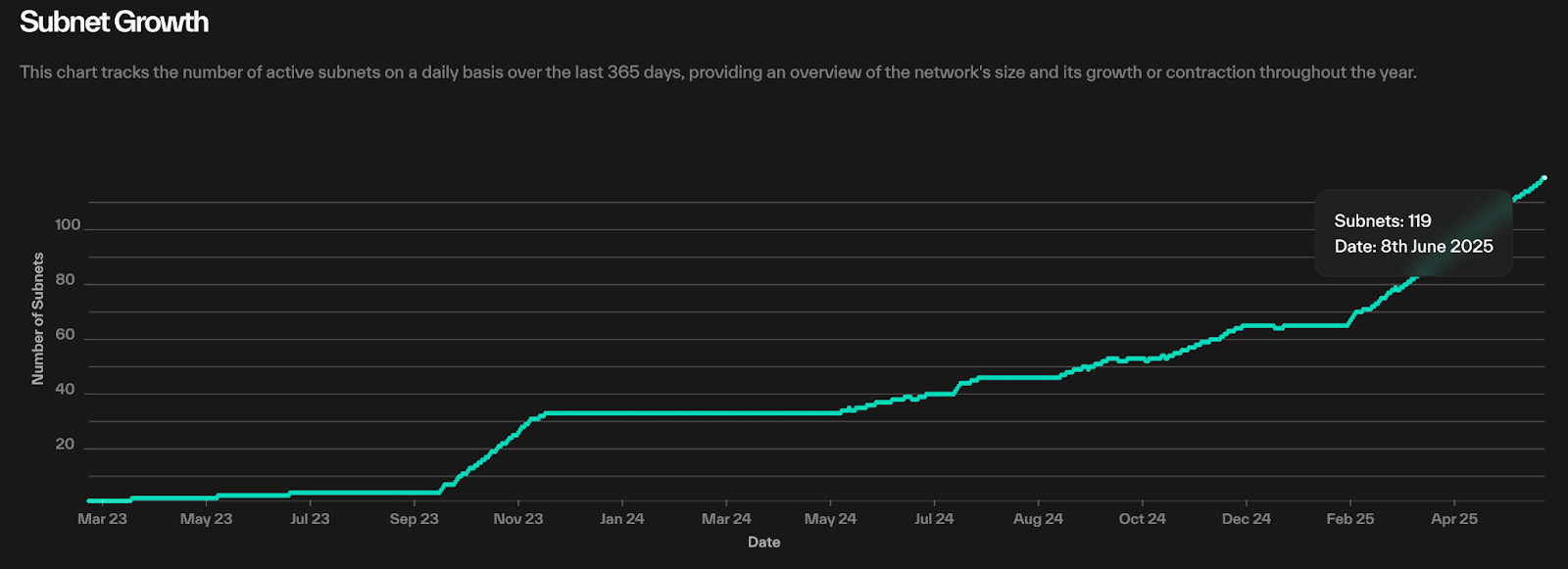 Number of Bittensor Subnets
Number of Bittensor Subnets
The types of ecological projects are diverse, covering cutting-edge fields such as AI agents (e.g., Tatsu), prediction markets (e.g., Bettensor), and DeFi protocols (e.g., TaoFi), forming an innovative ecosystem of deep integration between AI and finance.
Representative Subnet Ecological Projects
TAOCAT: TAOCAT is a native AI agent within the Bittensor ecosystem, built directly on the subnet, providing data-driven decision-making tools for users. It utilizes the large language model from Subnet 19, real-time data from Subnet 42, and the Agent Arena from Subnet 59 to provide market insights and decision support. It has received investment from DWF Labs, included in its $20 million AI agent fund, and launched on Binance Alpha.
OpenKaito: A subnet launched by the Kaito team on Bittensor, aimed at building a decentralized search engine for the crypto industry. It has indexed 500 million web resources, showcasing the powerful capabilities of decentralized AI in processing massive data. Compared to traditional search engines, its core advantage lies in reducing commercial interest interference, providing more transparent and neutral data processing services, and offering a new paradigm for information retrieval in the Web3 era.
Tensorplex Dojo: Developed by Tensorplex Labs, Subnet 52 focuses on crowdsourcing high-quality human-generated datasets through a decentralized platform, encouraging users to earn TAO tokens through data annotation. In March 2025, YZi Labs (formerly Binance Labs) announced an investment in Tensorplex Labs to support the development of Dojo and Backprop Finance.
CreatorBid: Operating on Subnet 6, it is a creative platform that combines AI and blockchain, integrated with Olas and other GPU networks (e.g., io.net), supporting content creators and AI model development.
Technical and Industry Collaborations
Bittensor has made breakthrough progress in cross-domain collaborations:
Established deep model integration channels with Hugging Face, achieving seamless on-chain deployment of 50 mainstream AI models.
In 2024, partnered with high-performance AI chip manufacturer Cerebras to jointly release the BTLM-3B model, with cumulative downloads exceeding 160,000.
In March 2025, reached a strategic cooperation with DeFi giant Aave to jointly explore the application scenarios of rsTAO as high-quality lending collateral.
Participation Methods
Bittensor has designed diversified ecological participation paths, forming a complete value creation and distribution system:
Mining: Deploy miner nodes to produce high-quality digital goods (e.g., AI model services) and earn TAO rewards based on contribution quality.
Verification: Run validator nodes to evaluate miner outputs, maintaining network quality standards and receiving corresponding TAO incentives.
Staking: Hold and stake TAO to support high-quality validator nodes, earning passive income based on validator performance.
Development: Utilize Bittensor SDK and CLI tools to build innovative applications, practical tools, or new subnets, actively participating in ecological construction.
Using Services: Use AI services provided by the network through user-friendly client application interfaces, such as text generation or image recognition.
Trading: Participate in market trading of subnet asset tokens to capture potential value growth opportunities.
 Distribution of Alpha Tokens to Participants in Subnets
Distribution of Alpha Tokens to Participants in Subnets
Challenges and Outlook
Despite demonstrating exceptional potential, Bittensor, as a frontier technology exploration, still faces multidimensional challenges. On the technical level, the security threats faced by distributed AI networks (such as model theft and adversarial attacks) are more complex than those in centralized systems, necessitating continuous optimization of privacy computing and security protection solutions. In terms of the economic model, early inflationary pressures and high volatility in the subnet token market require vigilance against potential speculative bubbles. Regarding the regulatory environment, although the SEC has classified TAO as a utility token, the differences in regulatory frameworks across global regions may still limit ecological expansion. At the same time, facing fierce competition from resource-rich centralized AI platforms, decentralized solutions need to prove their long-term competitive advantages in user experience and cost-effectiveness.
As the 2025 halving cycle approaches, Bittensor's development will focus on four strategic directions: further deepening the specialization of subnets to enhance service quality and performance in vertical application areas; accelerating deep integration with the DeFi ecosystem, leveraging newly introduced EVM compatibility to expand the boundaries of smart contract applications; smoothly transitioning network governance weight from TAO to Alpha tokens through the dTAO mechanism within the next 100 days, promoting the decentralization of governance; and actively expanding interoperability with other mainstream public chains to broaden ecological boundaries and application scenarios. These synergistic strategic initiatives will collectively drive Bittensor steadily towards the grand vision of a "market economy of machine intelligence."
0G: A Storage-Based Modular AI Ecosystem
Project Overview
0G is a modular Layer 1 public chain designed specifically for AI applications, aiming to provide efficient and reliable decentralized infrastructure for data-intensive and high-computation-demand scenarios. Through a modular architecture, 0G achieves independent optimization of core functions such as consensus, storage, computation, and data availability, supporting dynamic scaling and efficiently handling large-scale AI inference and training tasks.
The founding team consists of Michael Heinrich (CEO, previously founded Garten with over $100 million in funding), Ming Wu (CTO, Microsoft researcher, co-founder of Conflux), Fan Long (co-founder of Conflux), and Thomas Yao (CBO, Web3 investor), with 8 PhDs in computer science and backgrounds from companies like Microsoft and Apple, possessing deep expertise in blockchain and AI technologies.
In terms of financing, 0G Labs completed a $35 million Pre-seed round and a $40 million Seed round, totaling $75 million, with investors including Hack VC, Delphi Ventures, and Animoca Brands. Additionally, the 0G Foundation secured a $250 million token purchase commitment, $30.6 million from public node sales, and an $88.88 million ecological fund.
Design Architecture
0G Chain
The goal of 0G Chain is to create the fastest modular AI public chain, with a modular architecture that supports independent optimization of key components such as consensus, execution, and storage, and integrates data availability networks, distributed storage networks, and AI computing networks. This design provides exceptional performance and flexibility for the system when dealing with complex AI application scenarios. Here are the three core features of 0G Chain:
Modular Scalability for AI
0G adopts a horizontally scalable architecture capable of efficiently processing large-scale data workflows. Its modular design separates the data availability layer (DA layer) from the data storage layer, providing higher performance and efficiency for data access and storage for AI tasks (such as large-scale training or inference).0G Consensus
The consensus mechanism of 0G consists of multiple independent consensus networks that can dynamically scale according to demand. As the volume of data grows exponentially, the system's throughput can also increase in sync, supporting expansion from one to hundreds or even thousands of networks. This distributed architecture not only enhances performance but also ensures the system's flexibility and reliability.Shared Staking
Validators must stake funds on the Ethereum mainnet to provide security for all participating 0G consensus networks. If any 0G network experiences a penalizable event, the staked funds of the validator on the Ethereum mainnet will be reduced. This mechanism extends the security of the Ethereum mainnet to all 0G consensus networks, ensuring the overall security and robustness of the system.
0G Chain is EVM compatible, ensuring that developers from Ethereum, Layer 2 Rollup, or other chains can easily integrate 0G's services (such as data availability and storage) without migration. Additionally, 0G is exploring support for Solana VM, Near VM, and Bitcoin compatibility to extend AI applications to a broader user base.
0G Storage
0G Storage is a highly optimized distributed storage system designed for decentralized applications and data-intensive scenarios. Its core incentivizes miners to store and manage data through a unique consensus mechanism—Proof of Random Access (PoRA)—balancing security, performance, and fairness.
Its architecture can be divided into three layers:
Log Layer: Achieves permanent storage of unstructured data, suitable for archiving or data logging purposes.
Key-Value Layer: Manages variable structured data and supports permission control, suitable for dynamic application scenarios.
Transaction Layer: Supports concurrent writes from multiple users, enhancing collaboration and data processing efficiency.
Proof of Random Access (PoRA) is the key mechanism of 0G Storage, used to verify whether miners have correctly stored specified data blocks. Miners periodically receive challenges and must provide valid cryptographic hashes as proof, similar to proof of work. To ensure fair competition, 0G limits the data range for each mining operation to 8 TB, preventing large-scale operators from monopolizing resources and allowing small-scale miners to compete in a fair environment.
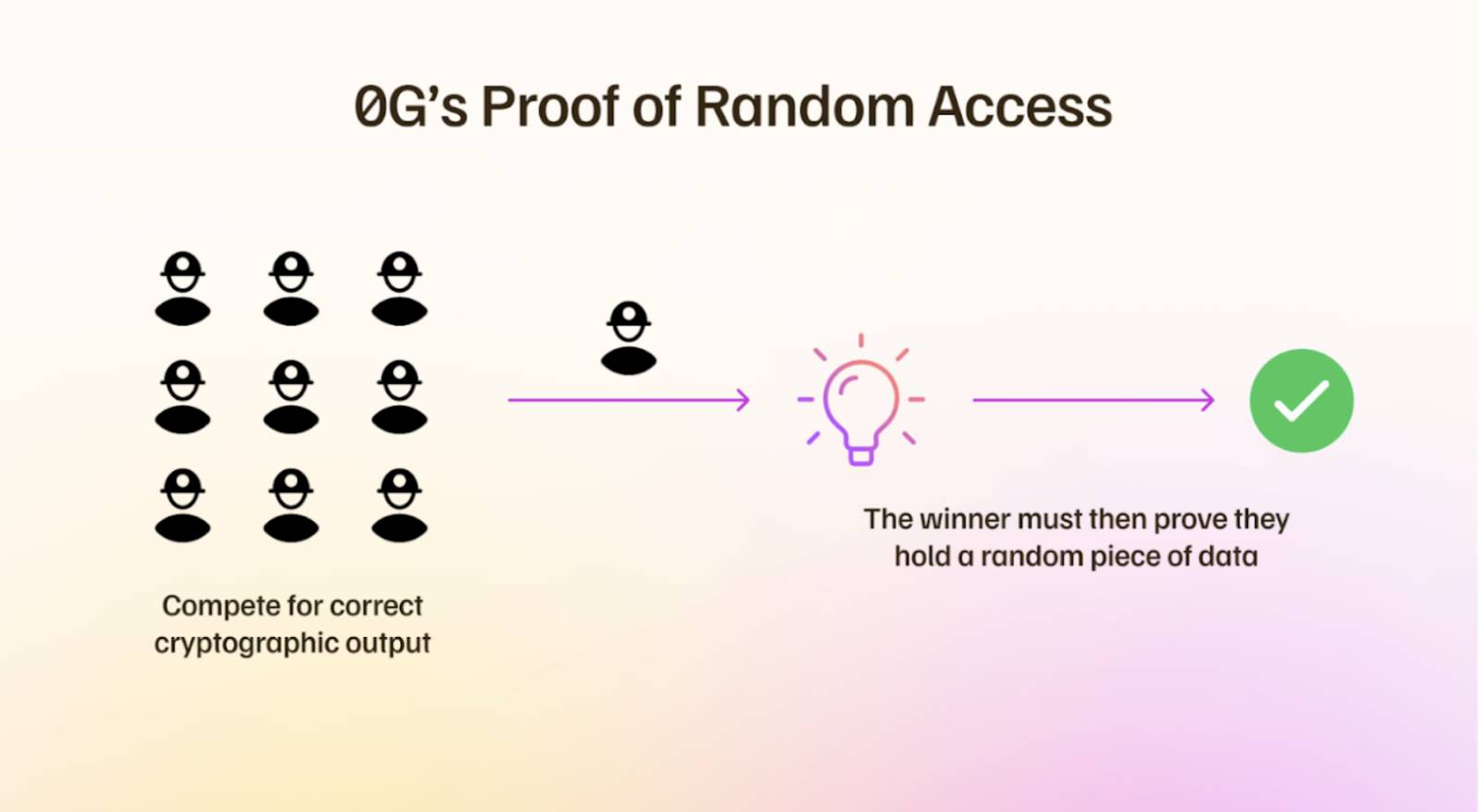
Illustration of Proof of Random Access
Through erasure coding technology, 0G Storage splits data into multiple redundant fragments and distributes them across different storage nodes. This design ensures that even if some nodes go offline or fail, the data can still be fully recovered, significantly enhancing data availability and security while allowing the system to perform excellently when handling large-scale data. Additionally, data storage is managed at both the sector and data block levels, optimizing data access efficiency and enhancing miners' competitiveness in the storage network.
Submitted data is organized sequentially, referred to as data flow, which can be understood as a list of log entries or a sequence of fixed-size data sectors. In 0G, each data block can be quickly located using a universal offset, enabling efficient data retrieval and challenge queries. By default, 0G provides a general data flow called the main flow for handling most application scenarios. At the same time, the system also supports specialized flows, which specifically accept certain categories of log entries and provide independent continuous address spaces optimized for different application needs.
Through the above design, 0G Storage can flexibly adapt to diverse use cases while maintaining high performance and management capabilities, providing robust storage support for AI x Web3 applications that need to handle large-scale data flows.
0G Data Availability (0G DA)
Data Availability (DA) is one of the core components of 0G, aimed at providing accessible, verifiable, and retrievable data. This function is crucial for decentralized AI infrastructure, such as verifying the results of training or inference tasks to meet user needs and ensure the reliability of the system's incentive mechanisms. 0G DA achieves excellent scalability and security through a carefully designed architecture and verification mechanisms.
The design goal of 0G DA is to provide extremely high scalability while ensuring security. Its workflow is mainly divided into two parts:
Data Storage Lane: Data is split into multiple small fragments ("data blocks") through erasure coding technology and distributed to storage nodes in the 0G Storage network. This mechanism effectively supports large-scale data transmission while ensuring data redundancy and recoverability.
Data Publishing Lane: The availability of data is verified by DA nodes through aggregated signatures, and the results are submitted to the consensus network. Through this design, data publishing only needs to handle a small amount of key data flow, avoiding bottleneck issues in traditional broadcasting methods, thereby significantly improving efficiency.
To ensure the security and efficiency of data, 0G DA employs a randomness-based verification method combined with an aggregated signature mechanism, forming a complete verification process:
Randomly Constructed Quorum: Using a Verifiable Random Function (VRF), the consensus system randomly selects a group of DA nodes from the validator set to form a quorum. This random selection method theoretically ensures that the honest distribution of the quorum aligns with the entire validator set, preventing data availability clients from colluding with the quorum.
Aggregated Signature Verification: The quorum samples and verifies the stored data blocks and generates an aggregated signature, submitting the availability proof to 0G's consensus network. This aggregated signature method greatly enhances verification efficiency, with performance several orders of magnitude faster than traditional Ethereum.
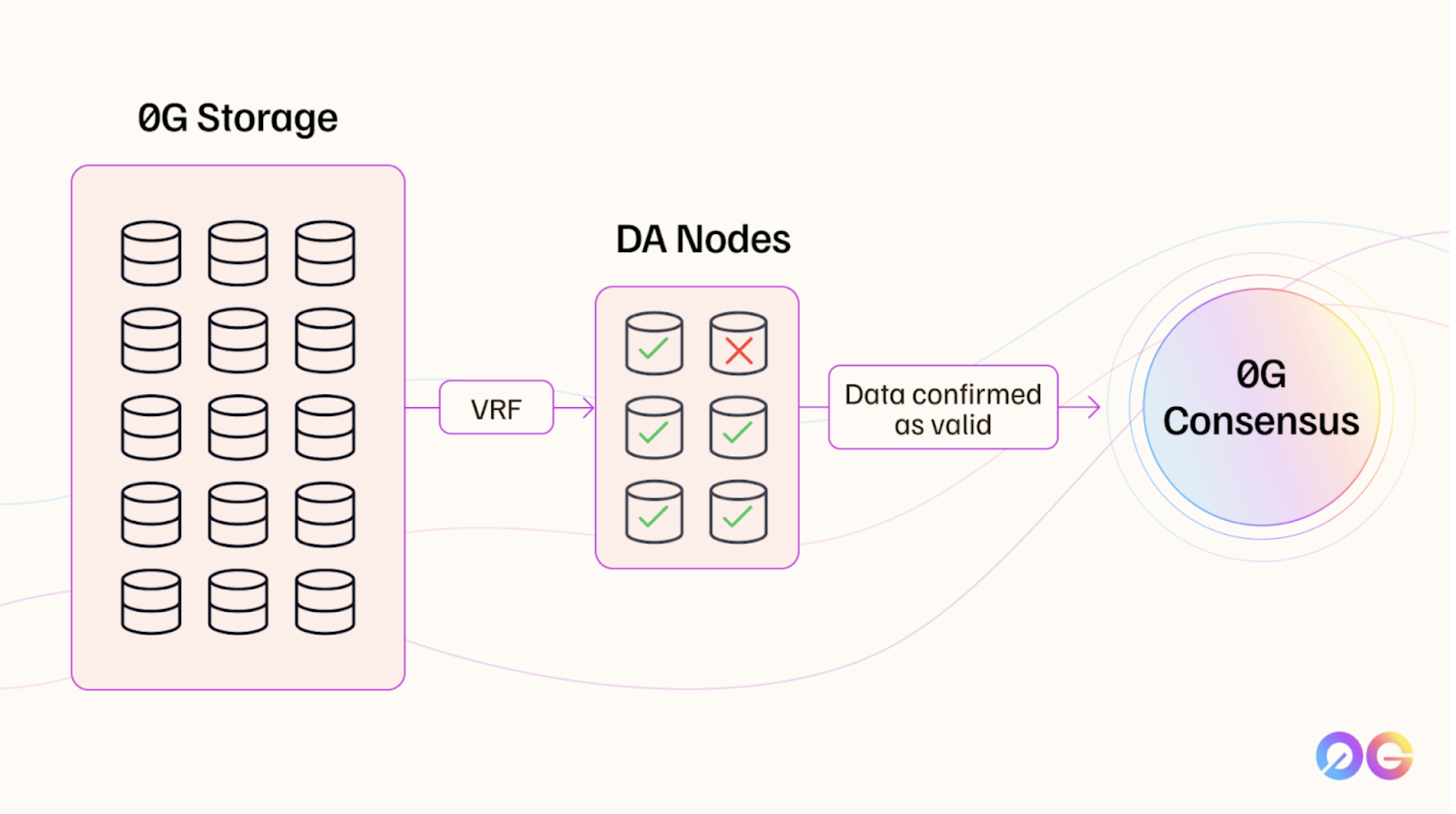
0G's Verification Process
Through the above mechanisms, 0G DA provides an efficient, highly scalable, and secure data availability solution, offering solid foundational support for decentralized AI applications.
0G Compute
The 0G computing network is a decentralized framework designed to provide the community with powerful AI computing capabilities. Through smart contracts, computing power providers can register the types of AI services they offer (such as model inference) and set prices for those services. After users send AI inference requests, service providers decide whether to respond based on the sufficiency of the user's balance, thereby achieving efficient allocation of computing power.
To further optimize transaction costs and network efficiency, service providers can batch process multiple user requests. This approach effectively reduces the number of on-chain settlements, lowering the resource consumption associated with frequent transactions. At the same time, the 0G computing network employs zero-knowledge proofs (ZK-Proofs) technology, significantly compressing transaction data and reducing on-chain settlement costs through off-chain computation and on-chain verification. Combined with 0G's storage module, its scalable off-chain data management mechanism can significantly reduce the on-chain costs of tracking data keys for storage requests while enhancing the efficiency of storage and retrieval.
Currently, 0G's decentralized AI network primarily provides AI inference services and has demonstrated advantages in efficiency and cost optimization. In the future, 0G plans to further expand its capabilities to achieve comprehensive decentralization for more AI tasks, from inference to training, providing users with more complete solutions.
Ecological Development
0G's testnet has currently upgraded from Newton v2 to Galileo v3, with over 8,000 validators according to official data. There are 1,591 active miners on the storage network, which have processed over 430,000 uploaded files, providing a total of 450.72G of storage space.
The influence of the 0G project in the decentralized AI field is also expanding with the increase and deepening of partner enterprises. According to official data, over 450 integrations have been completed, covering a comprehensive range of areas including AI computing power, data, models, frameworks, infra, and DePin.
0G Ecosystem Diagram
At the same time, the 0G Foundation has launched an $88.88 million ecological fund to support the development of AI-related projects, leading to the emergence of the following native applications:
zer0: AI-driven DeFi liquidity solution, providing on-chain liquidity optimization services
H1uman: Decentralized AI Agent factory, creating scalable AI integration workflows
Leea Labs: Infrastructure for multiple AI Agents, supporting secure multi-Agent system deployment
Newmoney.AI: Smart DeFi proxy wallet, automating investment and trading management
Unagi: AI-driven on-chain entertainment platform, integrating anime and gaming Web3 experiences
Rivalz: Verifiable AI oracle, providing reliable AI data access for smart contracts
Avinasi Labs: AI project focused on longevity research
Participation Methods
Ordinary users can currently participate in the 0G ecosystem in the following ways:
Participate in 0G testnet interactions: 0G has launched Testnet V3 (Galileo v3), and users can visit the official test webpage (0G Testnet Guide) to claim test tokens and interact with DApps on the 0G chain.
Participate in Kaito activities: 0G has joined the content creation activities on the Kaito platform, where users can participate by creating and sharing high-quality content related to 0G (such as technical analysis, ecological progress, or AI application cases) to win rewards.
Challenges and Outlook
0G has demonstrated strong technical capabilities in the storage field, providing a complete modular solution for decentralized storage with excellent scalability and economy (storage costs as low as $10-11/TB). At the same time, 0G has addressed the verifiability of data through the data availability layer (DA), laying a solid foundation for future large-scale AI inference and training tasks. This design provides strong support for decentralized AI at the data storage layer and creates an optimized storage and retrieval experience for developers.
In terms of performance, 0G expects the mainnet TPS to increase to a range of 3,000 to 10,000, achieving a tenfold increase in performance compared to before, ensuring that the network can meet the high-intensity computational demands associated with AI inference and high-frequency trading tasks. However, in the computing power market and model aspects, 0G still requires significant development. Currently, 0G's computing power business is limited to AI inference services, and more customized designs and technological innovations are needed to support model training tasks. As a core component of AI development, models and computing power are not only key to driving product upgrades and large-scale applications but also essential for 0G to achieve its goal of becoming the largest AI Layer 1 ecosystem.
Summary
Current Status: Diverse Approaches, Facing Challenges
Looking back at the six AI Layer 1 projects mentioned above, each has chosen different entry points, exploring paths for decentralized AI infrastructure and ecosystem construction around core elements such as AI assets, computing power, models, and storage:
Sentient: Focused on the development of decentralized models, launching the Dobby series of models, emphasizing the trustworthiness, alignment, and loyalty of models, with ongoing development in underlying chain integration to achieve deep fusion of models and chains.
Sahara AI: Centered on the protection of AI asset ownership, the first phase focuses on data rights confirmation and circulation, aiming to provide a reliable data foundation for the AI ecosystem.
Ritual: Around efficient implementation solutions for decentralized computing power in inference, enhancing the functionality of the blockchain itself, improving system flexibility and scalability, and supporting the development of AI-native applications.
Gensyn: Dedicated to solving the challenges of decentralized model training, reducing the costs of large-scale distributed training through technological innovation, providing a feasible path for AI computing power sharing and democratization.
Bittensor: A relatively mature subnet platform that has built a rich developer and application ecosystem through token incentives and decentralized governance, serving as an early model for decentralized AI.
0G: Using decentralized storage as an entry point, focusing on the challenges of data storage and management in the AI ecosystem, gradually expanding to more comprehensive AI infrastructure and application services.
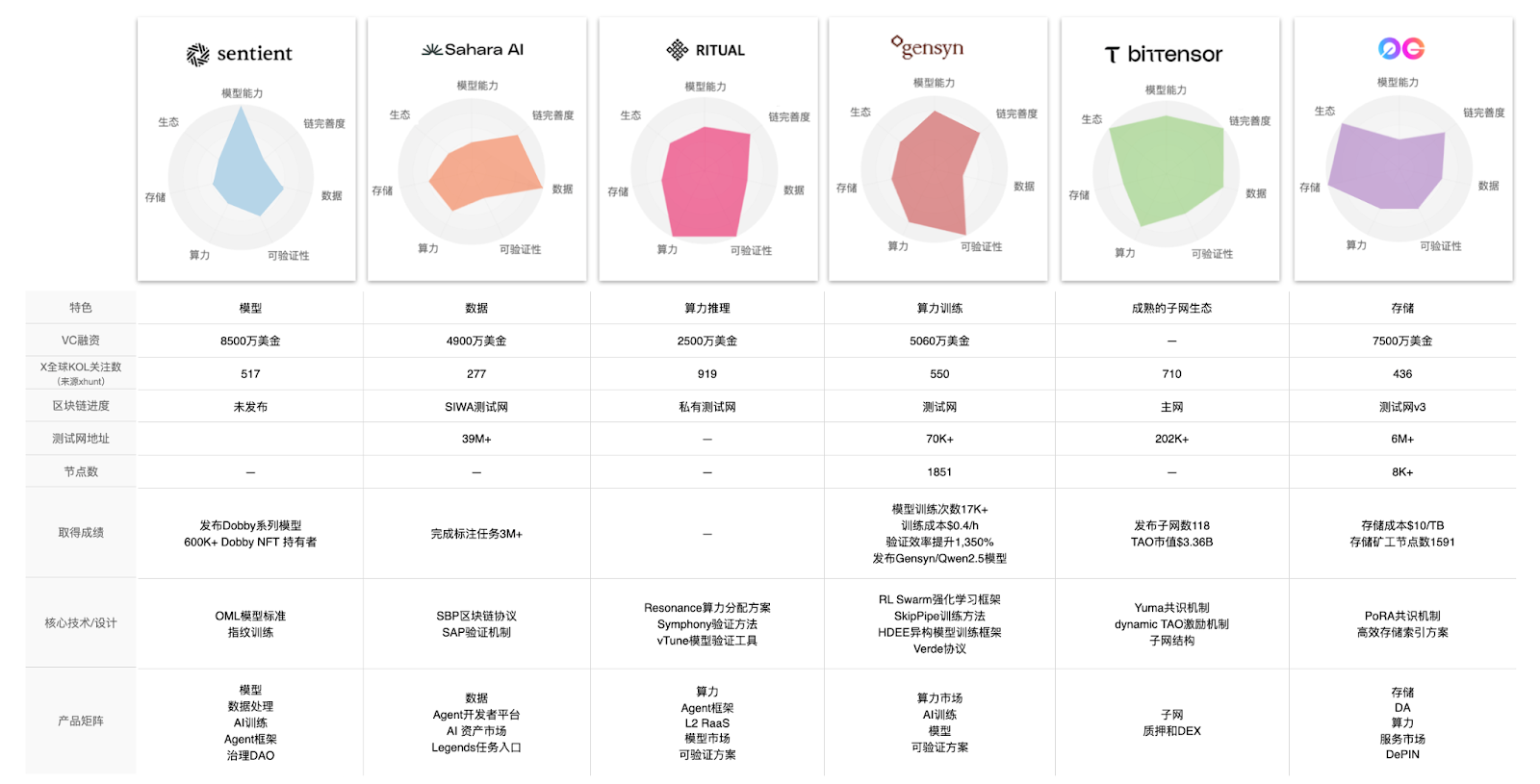
Project Comparison and Summary
Overall, these projects exhibit both differences in technical routes and complementary ecological strategies, collectively promoting the diversified development of on-chain decentralized AI ecosystems. However, it is undeniable that the entire track is still in the early exploration stage. While many forward-looking visions and blueprints have been proposed, actual development progress and ecosystem construction still require time to mature, and many key infrastructures and innovative applications are yet to be realized.
How to attract and incentivize more foundational nodes such as computing power and storage to join the network is a core issue that needs to be addressed urgently. Just as the Bitcoin network underwent over a decade of development to gradually gain mainstream market recognition, decentralized AI networks also need to continuously expand the scale of nodes to meet the massive demand for computing power from AI tasks. Only when the resources of computing power, storage, and other elements in the network reach a certain level of richness can the usage costs be effectively reduced, promoting the democratization of computing power and ultimately realizing the grand vision of decentralized AI.
Moreover, on-chain AI applications still lack innovation. Many products currently simply migrate from a Web2 model without deeply integrating innovative designs with blockchain-native mechanisms, failing to fully showcase the unique advantages of decentralized AI. These real-world challenges remind us that the continuous development of the industry requires not only breakthroughs in technology but also improvements in user experience and the ongoing enhancement of the entire ecosystem.
Sustainable Development: Continuous Emergence of Quality AI Layer 1 and DeAI Projects
In addition to the projects we have introduced in depth above, there are many new AI Layer 1 and DeAI projects worth our attention under the trend of the times. (Due to space limitations, we will provide a brief introduction here, and you can follow us for ongoing research and investment content in more AI tracks.)
Kite AI
Kite AI builds an EVM-compatible Layer 1 blockchain based on its core consensus mechanism "Proof of Attributed Intelligence" (PoAI), aiming to create a fair AI ecosystem that ensures the contributions of data providers, model developers, and AI Agent creators in AI value creation are transparently recorded and fairly rewarded, thus breaking the monopoly of AI resources by a few tech giants. Currently, Kite AI focuses on the C-end application layer and ensures the development, rights confirmation, and monetization of AI assets through subnet architecture and trading markets.
Story
An AI Layer 1 built around open intellectual property (IP), providing creators and developers with a full-process toolset to help them register, track, authorize, manage, and monetize various content IPs on-chain, whether they are videos, audio, text, or AI works. Story allows users to mint original content as NFTs and incorporates flexible authorization and profit-sharing mechanisms, enabling users to engage in secondary creation and commercial collaboration while ensuring ownership and revenue distribution are transparent and traceable.
Vana
Vana is a next-generation data-layer AI Layer 1 built for "user data monetization and AI training." It breaks free from the constraints of large companies monopolizing data, allowing individuals to truly own, manage, and share their data. Users can aggregate social, health, consumption, and other data for AI training through a "data DAO" (a decentralized autonomous organization where users co-manage, share, and benefit from AI training data) while retaining data ownership and participating in profit-sharing. Additionally, Vana emphasizes privacy and security in its design, employing privacy computing and cryptographic verification technologies to protect user data security.
Nillion
Nillion is a "blind computing network" focused on data privacy and secure computation, providing developers and enterprises with a set of privacy-enhancing technologies (such as multi-party secure computation MPC, homomorphic encryption, zero-knowledge proofs, etc.) that enable data storage, sharing, and complex computation without decrypting the original data. This allows scenarios such as AI, decentralized finance (DeFi), healthcare, and personalized applications to handle high-value and sensitive information more securely without worrying about data leakage risks. Currently, the Nillion ecosystem supports numerous innovative applications, including AI privacy computing, personalized intelligent agents, private knowledge bases, and has attracted partners such as Virtuals, NEAR, Aptos, and Arbitrum.
Mira Network
Mira Network is an innovative network designed for "decentralized verification" of AI outputs, aiming to create a trustworthy verification layer for autonomous AI. Mira's core innovation employs integrated evaluation technology to run multiple different language models simultaneously in the background, breaking down AI-generated results into specific assertions that are independently verified by distributed model nodes. Only when the vast majority of models reach a consensus and deem the content as "fact" is it output to the user. Through this multi-model consensus mechanism, Mira significantly reduces the hallucination rate of a single model from 25% to just 3%, equivalent to a reduction in error rate of over 90%. Mira eliminates reliance on centralized large institutions or single large models, adopting distributed nodes and economic incentive mechanisms, becoming a verifiable infrastructure layer for numerous Web2 and Web3 AI applications, truly achieving a leap from AI co-pilot to a trustworthy AI system with autonomous decision-making capabilities.
Prime Intellect
Prime Intellect is a platform focused on decentralized AI training and computing power infrastructure, dedicated to integrating global computing resources and promoting collaborative training of open-source AI models. Its core architecture includes a peer-to-peer computing power leasing market and an open training protocol, allowing anyone to contribute idle hardware to the network for large model training and inference, thereby alleviating the issues of traditional AI being highly centralized, having high barriers to entry, and wasting resources. At the same time, Prime Intellect has developed an open-source distributed training framework (such as OpenDiLoco) that supports efficient training of large models with billions of parameters across regions, and is deeply engaged in algorithm innovation and specialized tracks, such as the METAGENE-1 model based on metagenomics and the INTELLECT-MATH project focused on mathematical reasoning. In 2025, Prime Intellect will also launch the SYNTHETIC-1 program, utilizing crowdsourcing and reinforcement learning to create the world's largest open-source inference and mathematical code verification dataset.
Future Outlook: Open and Win-Win Decentralized AI
Despite numerous challenges, on-chain decentralized AI still holds vast development prospects and transformative potential. As underlying technologies gradually mature and various projects continue to deliver on their promises, the unique advantages of decentralized AI are expected to become increasingly prominent, with AI Layer 1s likely to achieve the following visions:
Democratic sharing of computing power, data, and models, breaking the monopoly of technological oligarchs, allowing individuals, enterprises, and organizations worldwide to participate in AI innovation without barriers.
Verification, circulation, and trustworthy governance of AI assets, promoting the free circulation and trading of core assets such as data and models on-chain, ensuring the benefits for owners, and forming a healthy open ecosystem.
AI outputs that are more trustworthy, traceable, and aligned, providing solid support for the safe and controllable development of AI, effectively reducing the risk of "AI malfeasance."
Inclusive implementation of industry applications, unleashing the immense value of AI in fields such as finance, healthcare, education, and content creation, allowing AI to truly benefit society in a decentralized manner.
As more and more AI Layer 1 projects continue to advance, we look forward to the realization of decentralized AI goals soon and hope that more developers, innovators, and participants will join in to collectively build a more open, diverse, and sustainable AI ecosystem.
Biteye
Biteye is Asia's leading Web3 research and investment platform, dedicated to creating a hub for "smart money," serving over 300,000 high-quality users. We continuously uncover truly valuable opportunities and signals in the Web3 world through high-density content, in-depth research, and AI-driven intelligent analysis.
X: @BiteyeCN; TG: t.me/biteyecn
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







