The Great Model Battle: Competing in Capability and "Cost"
Author: Wang Lu, Dingjiao One (dingjiaoone) Original
DeepSeek has completely unsettled the global landscape.
Yesterday, Musk showcased "the smartest AI on Earth"—Gork 3—during a live stream, claiming its "reasoning ability surpasses all known models." In terms of reasoning-test time scores, it also outperformed DeepSeek R1 and OpenAI o1. Not long ago, the national application WeChat announced its integration with DeepSeek R1, currently undergoing gray testing. This explosive combination is believed by outsiders to signal a major shift in the AI search field.
Now, global tech giants like Microsoft, NVIDIA, Huawei Cloud, and Tencent Cloud have all integrated DeepSeek. Netizens have also developed novel applications such as fortune-telling and lottery predictions, with its popularity directly translating into real money, propelling DeepSeek's valuation to reach as high as $100 billion.
DeepSeek's breakout success can be attributed not only to its free and user-friendly nature but also to the fact that it trained the DeepSeek R1 model, comparable in capability to OpenAI o1, with a mere GPU cost of $5.576 million. After all, in the past few years of the "hundred model battle," AI model companies both domestically and internationally have spent tens of billions or even over a hundred billion dollars. The cost of Gork 3 becoming "the world's smartest AI" was also steep, with Musk stating that Gork 3's training consumed a total of 200,000 NVIDIA GPUs (each costing about $30,000), while industry insiders estimate DeepSeek used only over 10,000.
However, some are also competing with DeepSeek on cost. Recently, the team led by Li Feifei claimed to have trained a reasoning model S1 with cloud computing costs of less than $50, achieving performance in math and coding ability tests comparable to OpenAI's o1 and DeepSeek's R1. It should be noted that S1 is a medium-sized model, which differs significantly from DeepSeek R1's parameter scale of over 100 billion.
Even so, the vast difference in training costs—from $50 to over $10 billion—raises curiosity. On one hand, people want to know how powerful DeepSeek really is and why various companies are trying to catch up or even surpass it. On the other hand, how much does it actually cost to train a large model? What are the involved stages? In the future, is it possible to further reduce training costs?
DeepSeek: Misunderstood in Generalization
From the perspective of practitioners, before answering these questions, several concepts need to be clarified.
First is the misunderstanding of DeepSeek as a generalization. People are amazed by one of its many large models—the reasoning model DeepSeek-R1—but it has other large models as well, each with different functionalities. The $5.576 million figure refers to the GPU costs during the training process of its general large model DeepSeek-V3, which can be understood as the net computing power cost.
A simple comparison:
- General Large Model:
Receives clear instructions, breaks down steps, and users need to describe tasks clearly, including the order of responses, such as whether the user needs a summary first followed by a title, or vice versa.
Response speed is relatively fast, based on probabilistic predictions (quick reactions), predicting answers through a large amount of data.
- Reasoning Large Model:
Receives straightforward, goal-focused tasks, and users can directly state their needs; it can plan on its own.
Response speed is slower, based on chain thinking (slow thinking), reasoning through steps to arrive at answers.
The main technical difference between the two lies in the training data: the general large model uses question + answer, while the reasoning large model uses question + thought process + answer.
Second, due to the higher attention on DeepSeek's reasoning large model DeepSeek-R1, many mistakenly believe that reasoning large models are inherently superior to general large models.
It is important to affirm that reasoning large models belong to the cutting-edge model type, a new paradigm introduced by OpenAI after the pre-training paradigm hit a wall, which increases computing power during the reasoning phase. Compared to general large models, reasoning large models are more costly and take longer to train.
However, this does not mean that reasoning large models are always more useful than general large models; in fact, for certain types of questions, reasoning large models may even be less effective.
Renowned expert in the large model field, Liu Cong, explained to "Dingjiao One" that for simple questions like asking for the capital of a country or the provincial capital of a place, reasoning large models are not as effective as general large models.

DeepSeek-R1's overthinking when faced with simple questions
He stated that for such relatively simple questions, reasoning large models not only have lower response efficiency than general large models but also incur higher computing power costs, and may even exhibit overthinking, potentially leading to incorrect answers.
He suggested using reasoning models for complex tasks like solving math problems or challenging coding, while general models are more effective for simpler tasks like summarization, translation, and basic Q&A.
Third is the true strength of DeepSeek.
Based on authoritative rankings and statements from practitioners, "Dingjiao One" ranked DeepSeek in both reasoning large models and general large models.
The first tier of reasoning large models mainly includes four companies: OpenAI's o series models (like o3-mini), Google's Gemini 2.0; and domestically, DeepSeek-R1 and Alibaba's QwQ.
More than one practitioner believes that while the outside world discusses DeepSeek-R1 as a top domestic model capable of surpassing OpenAI, there is still a certain gap compared to OpenAI's latest o3 from a technical perspective.
Its more significant meaning is that it has greatly narrowed the gap between top domestic and international levels. "If the previous gap was 2-3 generations, with the emergence of DeepSeek-R1, it has now shrunk to 0.5 generations," said Jiang Shu, a senior practitioner in the AI industry.
He shared his experiences using the four models, detailing their strengths and weaknesses:
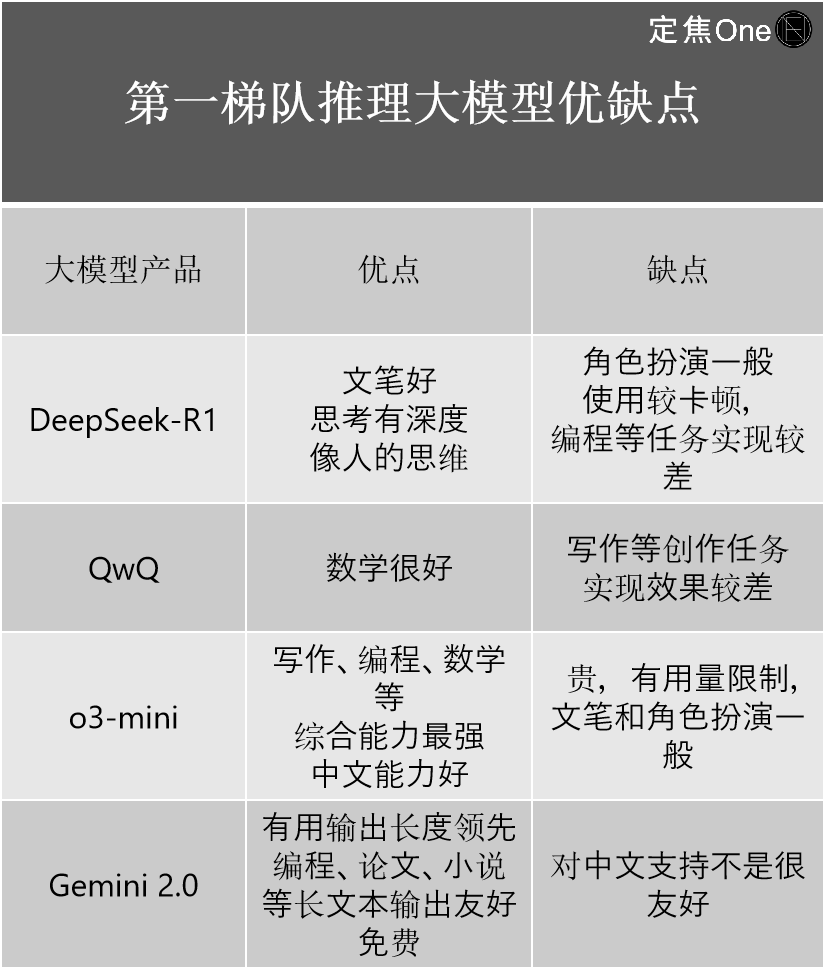
In the field of general large models, according to the LM Arena (an open-source platform for evaluating and comparing the performance of large language models (LLMs)) rankings, the first tier includes five companies: Google's Gemini (closed-source), OpenAI's ChatGPT, Anthropic's Claude; domestically, DeepSeek and Alibaba's Qwen.
Jiang Shu also listed his experiences using them.
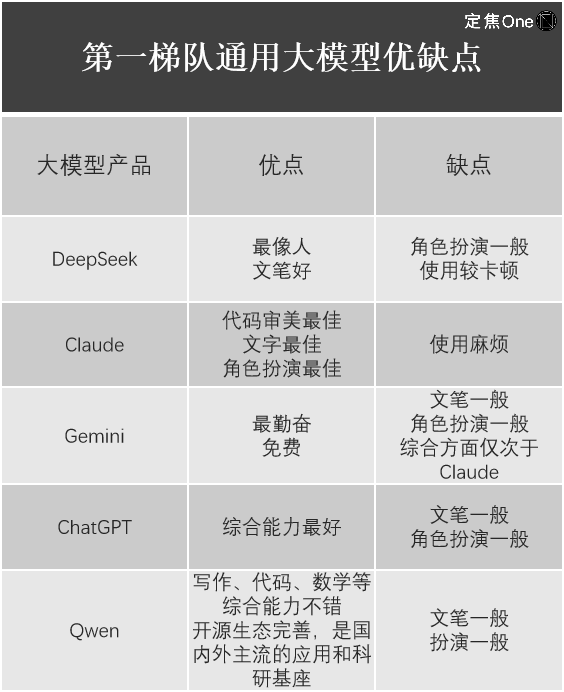
It is evident that although DeepSeek-R1 has shocked the global tech community, its value is undeniable, but each large model product has its own advantages and disadvantages, and DeepSeek is not flawless. For instance, Liu Cong found that DeepSeek's latest multimodal large model Janus-Pro, focused on image understanding and generation tasks, performs only moderately.
How Much Does It Cost to Train a Large Model?
Returning to the cost issue of training large models, how exactly is a large model born?
Liu Cong stated that the birth of a large model mainly consists of pre-training and post-training stages. If we compare a large model to a child, pre-training and post-training are about helping the child progress from only crying at birth to understanding adult conversations, and then to actively speaking with adults.
Pre-training mainly refers to training data. For example, feeding a large amount of text data to the model allows the child to absorb knowledge, but at this point, they have only learned knowledge and cannot yet apply it.
Post-training involves teaching the child how to use the knowledge they have learned, which includes two methods: model fine-tuning (SFT) and reinforcement learning (RLHF).
Liu Cong stated that whether it is a general large model or a reasoning large model, domestically or internationally, everyone follows this process. Jiang Shu also told "Dingjiao One" that all companies use Transformer models, so there is no essential difference in the underlying model composition and training steps.
Many practitioners noted that the training costs of large models vary significantly, mainly concentrated in hardware, data, and labor, with each part potentially employing different methods, leading to different corresponding costs.
Liu Cong provided examples: for hardware, whether to buy or rent makes a big difference in price; if buying, the initial one-time investment is substantial, but later costs drop significantly, mainly just electricity bills. If renting, the initial investment may be low, but this cost cannot be avoided. The training data can vary greatly depending on whether it is directly purchased or manually crawled. Each training cost also differs; for instance, the first time requires writing crawlers and filtering data, but the next version can reuse operations from the previous version, reducing costs. Additionally, the number of iterations before the final model is presented also affects costs, but large model companies are tight-lipped about this.
In summary, every stage involves many high hidden costs.
Outsiders have estimated GPU costs, with top models like GPT-4 having training costs of about $78 million, Llama3.1 over $60 million, and Claude3.5 around $100 million. However, since these top large models are closed-source and it is difficult to know if there is any waste of computing power, it is hard to ascertain. Until DeepSeek appeared in the same tier with a cost of $5.576 million.

Image source / Unsplash
It is important to note that the $5.576 million is the training cost of the foundational model DeepSeek-V3 mentioned in DeepSeek's technical report. "The training cost for the V3 version only represents the cost of the last successful training; earlier research, architecture, and algorithm trial-and-error costs are not included; and the specific training cost of R1 is not mentioned in the paper," Liu Cong stated. In other words, $5.576 million is only a small part of the total model cost.
The semiconductor market analysis and forecasting company SemiAnalysis pointed out that considering factors like server capital expenditures and operating costs, DeepSeek's total cost could reach $2.573 billion over four years.
Practitioners believe that compared to the tens of billions invested by other large model companies, even at $2.573 billion, DeepSeek's costs are low.
Moreover, the training process of DeepSeek-V3 only required 2,048 NVIDIA GPUs, with GPU hours used being only 2.788 million, while OpenAI consumed tens of thousands of GPUs, and Meta's training of the Llama-3.1-405B model used 30.84 million GPU hours.
DeepSeek is not only more efficient in the model training phase but also more efficient and cost-effective in the inference phase.
From the pricing of various model APIs provided by DeepSeek (developers can call large models via API for functions such as text generation, conversational interaction, and code generation), it is evident that their costs are lower than those of "OpenAI and others." It is generally believed that APIs with high development costs usually need to recover costs through higher pricing.
The API pricing for DeepSeek-R1 is: 1 yuan per million input tokens (cache hit), and 16 yuan per million output tokens. In contrast, OpenAI's o3-mini charges $0.55 (4 yuan) for input (cache hit) and $4.4 (31 yuan) for output per million tokens.
A cache hit means reading data from the cache rather than recalculating or calling the model to generate results, which can reduce data processing time and lower costs. The industry enhances the competitiveness of API pricing by distinguishing between cache hits and misses, and lower prices also make it easier for small and medium-sized enterprises to access.
Recently, the promotional period for DeepSeek-V3 ended, and although the pricing was raised from the original 0.1 yuan per million input tokens (cache hit) and 2 yuan per million output tokens to 0.5 yuan and 8 yuan respectively, the prices still remain lower than those of other mainstream models.
Although it is difficult to estimate the total training costs of large models, practitioners unanimously believe that DeepSeek may represent the current lowest cost for top-tier large models, and in the future, other companies are likely to follow DeepSeek's lead in reducing costs.
Cost-Reduction Insights from DeepSeek
Where has DeepSeek saved money? According to practitioners, optimizations have been made in model structure, pre-training, and post-training.
For instance, to ensure the professionalism of responses, many large model companies adopt the MoE (Mixture of Experts) model, which breaks down complex problems into multiple sub-tasks and assigns different experts to solve them. While many large model companies have mentioned this model, DeepSeek has achieved the ultimate level of expert specialization.
The secret lies in employing fine-grained expert segmentation (further subdividing tasks among experts within the same category) and shared expert isolation (isolating certain experts to reduce knowledge redundancy). The benefit of this approach is that it significantly improves the parameter efficiency and performance of MoE, allowing for faster and more accurate answers.
Some practitioners estimate that DeepSeek's MoE achieves results comparable to LLaMA2-7B with only about 40% of the computational load.
Data processing is also a hurdle in large model training, with companies exploring ways to improve computational efficiency while reducing hardware requirements such as memory and bandwidth. DeepSeek's method is to use FP8 low-precision training (to accelerate deep learning training) during data processing. "This approach is relatively advanced among known open-source models, as most large models use FP16 or BF16 mixed-precision training, and FP8 training is significantly faster than them," Liu Cong stated.
In post-training reinforcement learning, strategy optimization is a major challenge, which can be understood as enabling large models to make better decisions. For example, AlphaGo learned to choose the optimal move strategy in Go through strategy optimization.
DeepSeek chooses GRPO (Grouped Relative Policy Optimization) instead of the PPO (Proximal Policy Optimization) algorithm. The main difference between the two lies in whether a value model is used during algorithm optimization; the former estimates the advantage function through relative rewards within groups, while the latter uses a separate value model. By eliminating one model, the computational requirements are naturally smaller, which also saves costs.
Additionally, at the inference level, DeepSeek employs Multi-Head Latent Attention (MLA) instead of traditional Multi-Head Attention (MHA), significantly reducing memory usage and computational complexity, with the most direct benefit being a decrease in API interface costs.
However, the biggest inspiration DeepSeek provided to Liu Cong is that there are various ways to enhance the reasoning capabilities of large models. Pure model fine-tuning (SFT) and pure reinforcement learning (RLHF) can both yield excellent reasoning large models.
Image source / Pexels
In other words, there are currently four ways to create reasoning models:
- Pure Reinforcement Learning (DeepSeek-R1-zero)
- SFT + Reinforcement Learning (DeepSeek-R1)
- Pure SFT (DeepSeek Distillation Model)
- Pure Prompting (Low-cost Small Model)
"Previously, the industry focused on SFT + Reinforcement Learning, and no one thought that pure SFT and pure reinforcement learning could also achieve good results," Liu Cong stated.
DeepSeek's cost reduction not only brings technical inspiration to practitioners but also influences the development paths of AI companies.
Wang Sheng, a partner at Inno Angel Fund, explained that the AI industry often has two different path choices in pursuing AGI: one is the "computational arms race" paradigm, which piles up technology, money, and computing power to first elevate large model performance to a high point before considering industrial implementation; the other is the "algorithm efficiency" paradigm, which aims for industrial implementation from the outset by launching low-cost, high-performance models through architectural innovation and engineering capabilities.
"A series of models from DeepSeek proves that in a situation where the ceiling cannot be raised, focusing on optimizing efficiency rather than capability growth is a viable paradigm," Wang Sheng stated.
Practitioners believe that as algorithms evolve, the training costs of large models will further decrease.
Cathy Wood, founder and CEO of Ark Investment Management, previously pointed out that before DeepSeek, the training costs of artificial intelligence decreased by 75% annually, and inference costs even dropped by 85% to 90%. Wang Sheng also mentioned that the cost of releasing the same model at the end of the year would significantly decrease compared to the model released at the beginning of the year, potentially dropping to 1/10.
An independent research institution, SemiAnalysis, noted in a recent analysis report that the decline in inference costs is one of the signs of continuous progress in artificial intelligence. What once required supercomputers and multiple GPUs to achieve the performance of the GPT-3 large model can now be accomplished by smaller models installed on laptops. Moreover, costs have also decreased significantly; Anthropic's CEO Dario believes that the pricing of algorithms is evolving towards the quality of GPT-3, with costs reduced by 1,200 times.
In the future, the speed of cost reduction for large models will continue to accelerate.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







