OpenAI directly calls it the "world simulator," capable of simulating the characteristics of people, animals, and environments in the physical world.
By: Mu Mu
Without being open to public testing, OpenAI has shocked the tech, internet, and social media circles with the trailer made by the text generation video model Sora.
According to the official video released by OpenAI, Sora can generate a complex "super video" up to 1 minute long based on the text information provided by the user. Not only are the visual details realistic, but this model also simulates the sense of camera movement.
From the released video effects, what excites the industry is the ability of Sora to understand the real world. Compared to other large models for text-to-video, Sora shows advantages in semantic understanding, visual presentation, visual coherence, and duration.
OpenAI directly calls it the "world simulator," declaring its ability to simulate the characteristics of people, animals, and environments in the physical world. However, the company also acknowledges that Sora is not yet perfect, with remaining issues in understanding and potential safety concerns.
Therefore, Sora is only open for testing to a very small number of people. OpenAI has not announced when Sora will be open to the public, but the impact it brings is enough to make companies developing similar models see the gap.
Sora "Trailer" Amazes Everyone
With the release of OpenAI's text generation video model Sora, the domestic "shock body" evaluation has emerged again.
Self-media exclaimed "reality no longer exists," and internet giants also praised Sora's capabilities. Zhou Hongyi, the founder of 360, stated that the birth of Sora means that the realization of AGI may be shortened from 10 years to around two years. In just a few days, Sora's Google search index has rapidly risen, approaching the popularity of ChatGPT.
Sora's popularity stems from the 48 videos released by OpenAI, with the longest one being 1 minute. This not only breaks the time limit for video generation by previous text-to-video models Gen2 and Runway, but also presents clear images, and it has even learned the language of the camera.
In the 1-minute video, a woman in a red dress walks on a street lined with neon lights. The style is realistic, the images are smooth, and the most amazing part is the close-up of the female lead. Even the pores, spots, and acne on her face are simulated, comparable to turning off the beauty filter in a live broadcast. The neck wrinkles even accurately "reveal" her age, perfectly matching the facial state.
In addition to realistic characters, Sora can also simulate animals and environments in the real world. A video segment featuring a Victoria crowned pigeon in multiple angles presents the bird's blue feathers from head to crown in ultra-clear detail, even capturing the dynamic movement and breathing frequency of its red eyes, making it difficult to distinguish whether it was generated by AI or filmed by a human.
For non-realistic creative animations, Sora's generation effect also achieves the visual sense of Disney animated movies, causing netizens to worry about the job security of animators.
The improvements brought by Sora to the text generation video model are not only in terms of video length and visual effects, but it can also simulate the movement trajectory of the camera and shooting, first-person perspectives in games, aerial perspectives, and even the "one-shot" technique in movies.
After watching the exciting videos released by OpenAI, you can understand why the internet and social media are amazed by Sora, and these are just the trailers.
OpenAI Introduces the "Visual Patch" Dataset
So, how does Sora achieve its simulation capabilities?
According to the technical report released by OpenAI, Sora is surpassing the limitations of previous image data generation models.
Previous research on text-to-visual image generation has used various methods, including recurrent networks, generative adversarial networks (GAN), autoregressive transformers, and diffusion models, but they have focused on fewer visual data categories, shorter videos, or fixed video sizes.
Sora uses a diffusion model based on Transformer, and the image generation process can be divided into two stages: forward and reverse, to enable Sora to expand videos forward or backward along the timeline.
The forward stage simulates the diffusion process from real images to pure noise images. Specifically, the model gradually adds noise to the image until it becomes completely noisy. The reverse process is the inverse of the forward process, where the model gradually restores the original image from the noisy image. With this back and forth process, OpenAI enables the machine Sora to understand the formation of visuals.
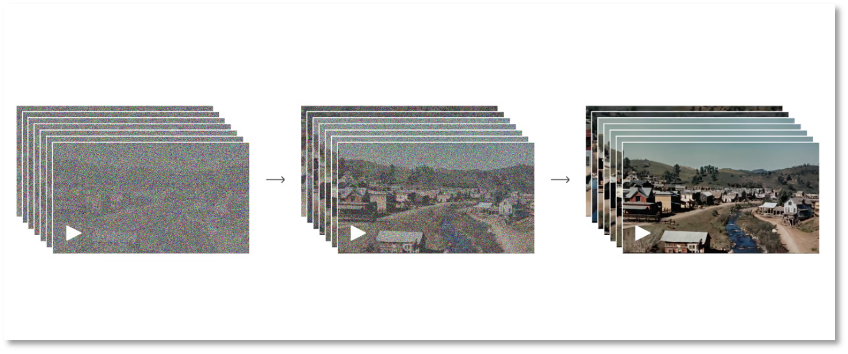
Of course, this process requires repeated training and learning, as the model learns how to gradually remove noise and restore image details. Through iterations of these two stages, Sora's diffusion model can generate high-quality images. This model has shown excellent performance in image generation, image editing, and super-resolution.
The above process explains why Sora can achieve high-definition and ultra-detailed images. However, from static images to dynamic videos, the model still needs to accumulate data and undergo training and learning.
Based on the diffusion model, OpenAI transforms all types of visual data, including videos and images, into a unified representation to conduct large-scale generation training for Sora. The representation used by Sora is defined by OpenAI as "visual patches," which are a collection of smaller data units, similar to the text set in GPT.
Researchers first compress the video into a low-dimensional latent space, and then decompose this representation into spatiotemporal patches. This is a highly scalable representation form, suitable for training and processing various types of videos and images for the generation model.
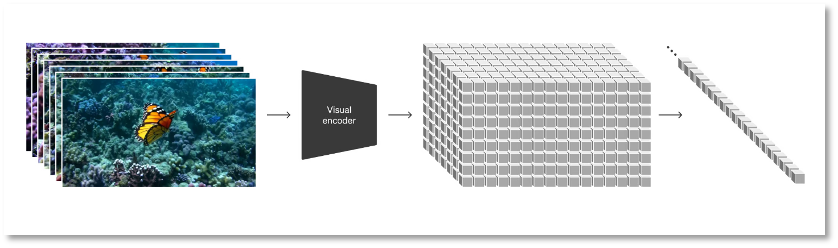
To train Sora with less information and computational load, OpenAI developed a video compression network to first reduce the video to a low-dimensional latent space at the pixel level, and then use the compressed video data to generate patches. This reduces the input information, thereby reducing the computational pressure. At the same time, OpenAI also trained the corresponding decoder model to map the compressed information back to the pixel space.
Based on the representation of visual patches, researchers can train Sora for videos/images of different resolutions, durations, and aspect ratios. During the inference stage, Sora can arrange randomly initialized patches in appropriately sized grids to determine the logical flow of the video and control the size of the generated video.
According to the OpenAI report, during large-scale training, the video model has shown exciting capabilities, including Sora's ability to realistically simulate people, animals, and environments in the real world, generate high-fidelity videos, and achieve 3D consistency and temporal consistency, thus truly simulating the physical world.
Altman Acts as a Second Tester for Netizens
From the results to the development process, Sora demonstrates powerful capabilities, but ordinary users have no way to experience it yet. Currently, they can only provide prompt words and mention @OpenAI founder Sam Altman on X, who acts as a second tester to help netizens generate videos on Sora and release them to the public to see the effects.
This inevitably raises doubts about whether Sora is really as powerful as presented by OpenAI.
In response, OpenAI frankly states that the current model still has some issues. Similar to early versions of GPT, the current Sora also has "illusions," which are more concrete in visual-based video results.
For example, it cannot accurately simulate many basic physical processes, such as the relationship between a treadmill belt and a person's movement, or the temporal logic of a glass breaking and liquid flowing out. In the video clip "Archaeologists unearth a plastic chair," the plastic chair directly "floats" out of the sand.
There are also appearances of wolf cubs out of thin air, jokingly referred to by netizens as "wolf mitosis."
Sometimes, it also fails to distinguish between front, back, left, and right.
These flaws in dynamic images seem to prove that Sora still needs to do more to understand and train on the logic of physical world movements. In addition, compared to the risks of ChatGPT, the ethical and safety risks of Sora, which provides an intuitive visual experience, are even greater.
Previously, the text-to-image model Midjourney had already told humans that "having an image does not necessarily mean having the truth," and AI-generated lifelike images have begun to become elements of rumors. Dr. Newell, Chief Scientist of identity verification company iProov, stated that Sora could make it "easier for malicious actors to generate high-quality fake videos."
It is conceivable that if the videos generated by Sora are maliciously abused, leading to fraud, defamation, the spread of violence and pornography, the consequences would be immeasurable. This is also the reason why, in addition to being amazed, people are also afraid of Sora.
OpenAI has also considered the safety issues that Sora may bring, which is probably why Sora is only open for testing to a very small number of people by invitation. When will it be open to the public? OpenAI has not provided a timetable, and from the videos released by the official, other companies have little time left to catch up with the Sora model.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






