Grass combines multiple bullish narratives: DePin+AI+Solana.
Written by: AYLO
Translated by: DeepTechFlow
Grass is a very exciting project that is expected to launch its mainnet in the first or second quarter. Grass already has over 500,000 users. When Grass network goes live, it will be one of the largest crypto protocols in the market in terms of user count alone, creating new sources of income for everyone with internet access.
Grass combines multiple bullish narratives: DePin+AI+Solana. In this article, you will have the opportunity to hear from Grass founder 0xdrej, who reveals a lot of important information. This is a lengthy but very worthwhile article to read, where we will discuss what Grass is, how it works, why it chose Solana, and more.
What attracted you to the cryptocurrency field?
Yes, I guess I missed out on many opportunities when I first entered the cryptocurrency field. I think that's the case for many people. I first heard about cryptocurrency in high school because a classmate of mine was mining Bitcoin on his laptop. I haven't heard from him since, but I'm sure he's doing well now. And I actually participated in a Doge faucet activity in 2014, when Doge had just launched, but I lost access to that account. So I guess those were my two early experiences with cryptocurrency, but it wasn't until a few years ago that I really got involved in development work when I started getting into DeFi.
I worked in the financial field for a while and was very familiar with the operation of the traditional financial industry. It's very exciting to see a group of ordinary people rebuilding the entire infrastructure on the blockchain. You know, anything that happens from traditional finance to on-chain has a lot of similarities, which is crazy, mainly because it's a huge immutable ledger. So yes, a few years ago I started getting involved in some DeFi protocols.
What is Grass's elevator pitch? How do you explain it at a high level?
We like to call it the "decentralized data provisioning layer for artificial intelligence." This actually means that we have a network of over 500,000 network extensions that are crawling the public internet, capturing website snapshots, and uploading them to a database.
The idea here is that because we can parallel process and distribute all this computing power, as well as these residential views of the internet (which is important because websites often show consumers what they want the public to see, not data centers or traditional products), we can actually create datasets that are impossible to create in other repositories.
So there are some comparisons. One is like a decentralized oracle for artificial intelligence, and the other is a decentralized version of regular crawling. But yes, ultimately, it's a massive data protocol focused on public network data.
So, by allowing anyone to participate in this network and integrating with the blockchain, you find that you can compete with existing solutions, right?
We tried several different business models. Obviously, when you're building such a protocol, you can just pay people a small fee for their unused bandwidth. For example, you can give them a fixed rate per gigabyte and use that bandwidth to crawl large datasets, extract insights from them, and monetize those insights. From the crawling layer to the dataset layer to the insight layer, you can capture a little profit at each step.
Typically, this is done by different entities, and the users providing the bandwidth (driving all of this) can only see the tiny fixed fee per gigabyte, or often none at all, because they installed an SDK on a free app that just cycles through the bandwidth. We think this is unfair.
We thought, well, how do we create a value pool mechanism to compensate users across the entire vertical? So, if someone uses the data crawled from your Grass node to infer an AI model, your Grass node should be compensated, not just for the raw data. Hopefully, this makes sense. This is one of the major problems we want to solve on-chain.
Another issue that is becoming increasingly prominent is the problem of polluted datasets. This is a newly emerging issue, but it has existed in the e-commerce field for many years.
For example, if you're crawling an e-commerce website like eBay and you want to fetch the prices of all their inventory every day, you need to fetch about 30 million SKUs daily. eBay knows that if they block your IP address, you will switch IPs. So, what they do is they set price traps. If they detect that you're trying to crawl them and undercut their pricing, they will give you fake prices. We experienced this in the early days of using Grass and compared it to using data centers.
These e-commerce strategies have slowly seeped into advertising technology. Since the explosive growth of HoloLens in the past year and a half, it has actually also flowed into the NLP (natural language processing) dataset field.
So, if you're a politician and you know that a specific dataset will be used to train a model, you might contact the person managing that dataset and ask them to insert, for example, a thousand sentences favorable to a specific candidate. Similarly, companies providing funding will insert fake reviews into datasets already crawled from the internet.
Now, solving this problem is very difficult, right? Because, as you may know, LLM training datasets are not just GB or TB, but PB data, actually millions of GB.
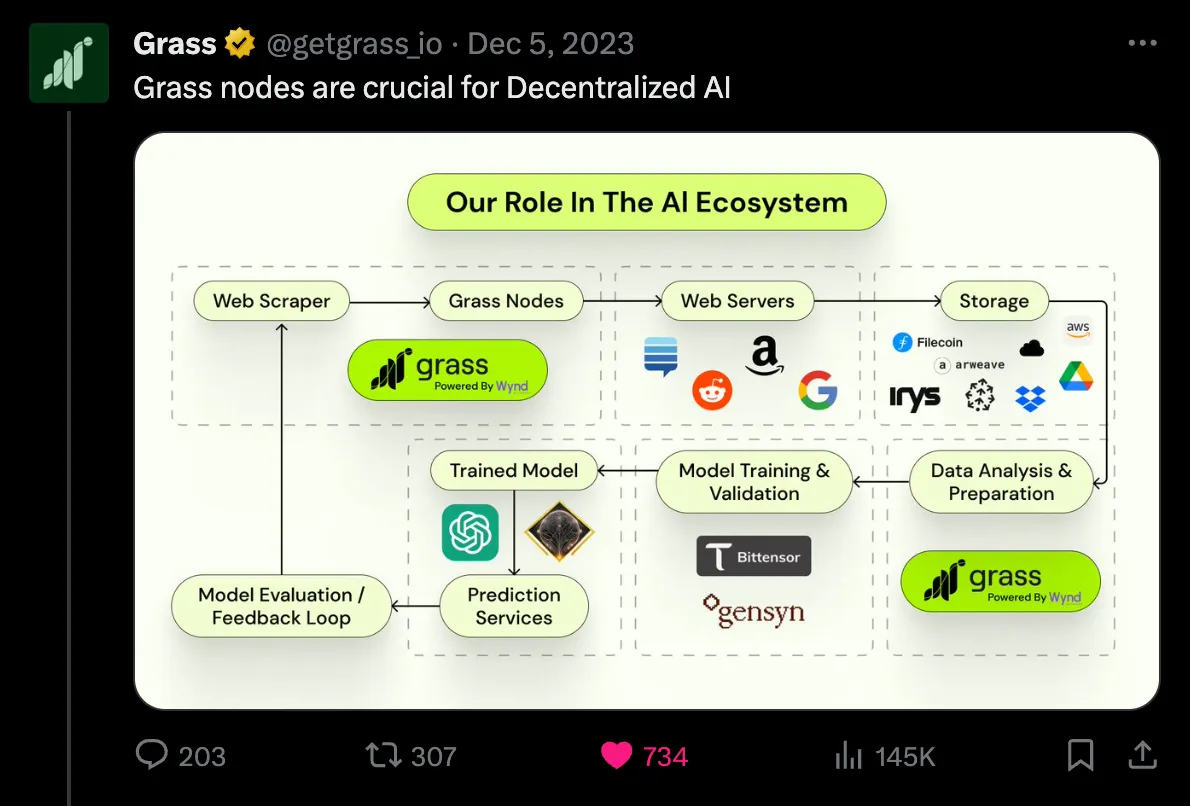
So, expecting anyone to train LLM to verify if a dataset really comes from the claimed website is very unrealistic. For example, if I claim to have crawled all the content of Medium, that's about 50 million articles, but there's no guarantee that this content is actually from those Medium articles.
To solve this problem, zk-TLS (zero-knowledge transport layer security) provides a good solution. Honestly, this is only possible on a high-throughput blockchain.
The idea is that once we decentralize, these nodes will submit proof of request when crawling the internet. They submit proof of request, and then our sorter (currently centralized, but we plan to decentralize) will delegate a certain amount of tokens to a smart contract.
This contract unlocks upon approval of the request. Now, you can actually link that proof of request to the network response from that crawling work, and then directly link it to the dataset. Suddenly, you have cryptographic proof showing that these rows in this dataset actually come from those websites and were crawled at a specific date and time.
This is powerful because such a mechanism doesn't even exist in Web 2.0 and is only possible using blockchain.
Can you talk about what the "data war" is and how Grass is involved?

As I hinted at earlier, the industry that first started locking data was actually e-commerce, because those were the most directly monetizable datasets at the time. With the advancement of technology and our increasingly advanced understanding of language data, this type of data has become extremely valuable. However, until now, language data has not provided as much value as it does now. So, many websites have only recently found ways to monetize this language data. Then, they began to realize how powerful this data is and started locking down the internet.
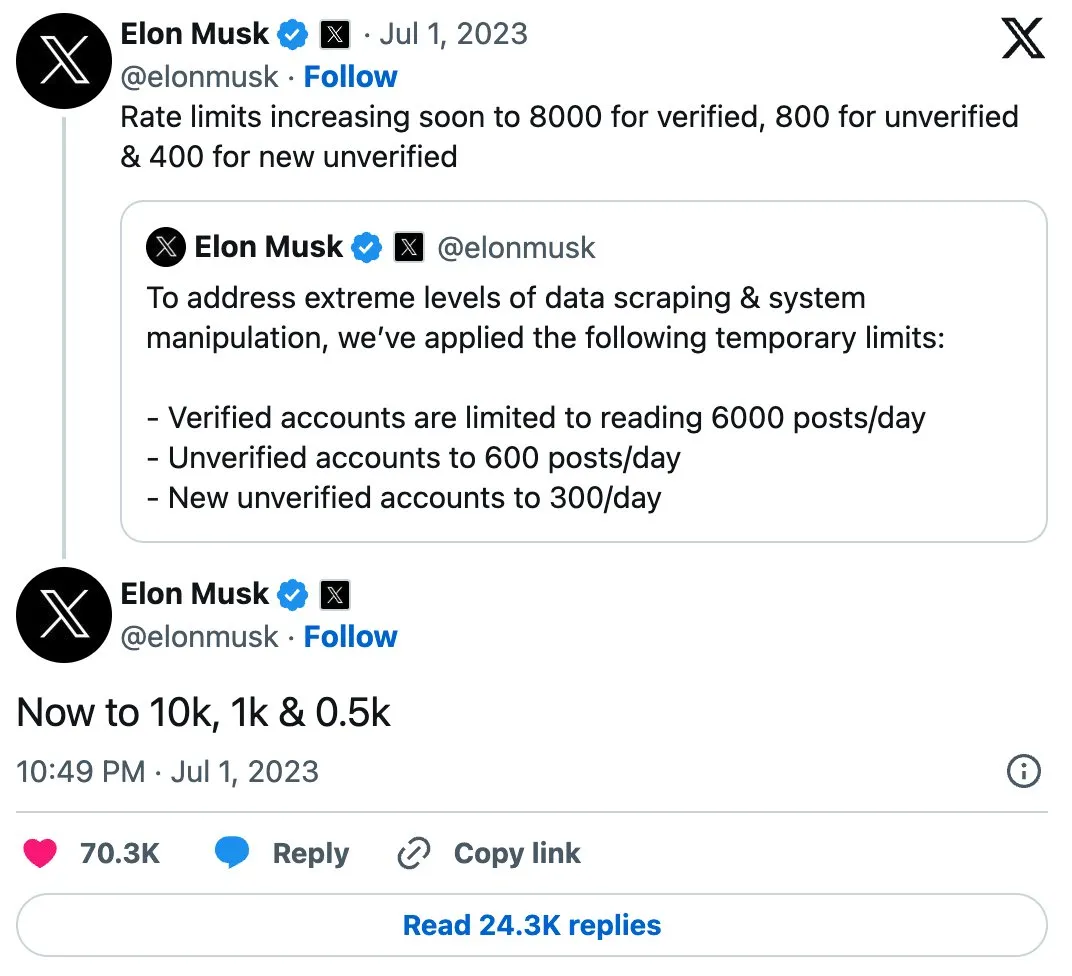
For example, about six months ago, Elon Musk began rate-limiting everyone's Twitter because it was being crawled. Previously, Twitter didn't really block web crawlers, but Elon Musk realized the value of Twitter data and wanted to use it to train his own AI. This is exactly what we predicted, and it has indeed developed that way.
Another example is Reddit, which has imposed various restrictions on its API. You may not know this, but two-thirds of the general crawling library trained by GPT is actually crawled from Reddit.
Reddit doesn't really understand how valuable their data is. It's particularly valuable because of how the Reddit system works: someone asks a question, people answer, and the best answers are pushed up while the bad ones are pushed down. Reddit has a group of people manually training data that can enter the model.
We predict that a data war is currently unfolding, with all these websites trying to lock down their data. They even have backdoors for a few large tech companies, making AI inaccessible to ordinary open-source developers, which is a bit scary and brings a lot of centralization risks.
Another good example is Medium. A few months ago, Medium's CEO wrote a blog post about how web crawlers are feeding Medium articles into AI models. He talked about how they are polluting these datasets, blocking crawlers, and making them as inaccessible as possible. This is why it's difficult to browse Medium without registering for an account.
This makes it difficult for ordinary people to use the internet because companies are trying to isolate their data.
Medium's CEO also mentioned that they allow Google access to their data. Ordinary people cannot browse their website properly, but Google can crawl it for free to train their AI models. He explained the reason: Google will prioritize Medium in Google search in exchange for access. This shows how valuable having a search engine is, and you can pay for language data by prioritizing SEO. This is the next big wave of the data war.
All these companies are fighting for data, trying to lock it down, and trying to get the right price for something that has never been priced in human history. Ordinary people are becoming accessories, and only a few institutions can access this data, which is unfair.
What's crazy is that some established companies are now crawling sites like Reddit by installing SDKs in apps downloaded for free by millions of people. Suppose you download the Roku TV screensaver or some free mobile game. Developers get paid by placing an SDK in it, allowing these big companies to use your bandwidth from your residential IP address to crawl websites because their IP addresses have been blocked. Ironically, we always agree to these terms and conditions, and their reasoning is, "Hey, you get an ad-free product experience." They claim that this is how you get compensated. But we are very clear that the value of advertising is far lower than the value of the data being used.
Our idea for Grass is that if a data war happens, we may not be able to stop it, but we should at least have the opportunity to participate. We should have the choice to either sell weapons in the data war or create a huge open dataset for the internet, which anyone can use to train their own AI models.
Is it easy for people to participate in Grass and get some benefits?

The network is currently in beta testing and is very simple. Because the hardware you need is already on your device. All you need to do is get a referral code. Then you just need to create an account or the Saga mobile app, and you can get started, the onboarding process is very smooth.
One issue we recently faced is that the growth in the number of users is much faster than we expected. Therefore, as we expand the infrastructure, people may encounter some minor issues.
How big do you think the market is for this?
We are currently targeting two or maybe three verticals, each with different market sizes.
The first is the alternative data industry, which I believe is a $20 billion market. When I say alternative data, I mainly mean data used by hedge funds. For example, if you search for the prices and inventory of certain stores, you can estimate a company's quarterly earnings. Hedge funds will pay for this type of information.

The web crawling market itself, while still in its early stages, is currently worth tens of billions of dollars and is growing significantly. The reason for such massive growth is the third market, which is artificial intelligence.
The size of the AI data market is currently very difficult to quantify. Its market size may be growing exponentially every day, making it difficult for us to estimate. But when you see people discussing selling data to AI datasets, you realize what a huge opportunity this is.
So, as the network grows, do you think user rewards will be diluted? Or will a balance be found as the network becomes more profitable?
I will try not to make any forward-looking statements to answer this question. The first variable is that the network is now very close to being usable, which is why during this beta testing period, we chose to compensate for normal uptime. We don't intend to reward users for their uptime indefinitely.
So, right now is the only time you can earn points just for keeping your device online. In the future, nodes will only be compensated for actual bandwidth usage. As for balance, the travel example I mentioned earlier is a good one.
In that field, you can never have enough nodes. For travel aggregation websites to remain competitive, the most competitive aggregator is actually the one with the most nodes. So, if you can unlock that, they will only put more content and more throughput through the network.
What prompted you to decide to develop on Solana?
For what we are trying to do, having a high-throughput chain is obviously very important. When the Grass network goes live, it will be one of the most heavily used crypto protocols, which requires very low gas fees to incentivize users. Solana is currently the most cost-effective in terms of gas fees and possibly the fastest chain. Some upcoming updates (such as FireDancer) are very exciting because parallel transactions are exactly what we need.
There are many DePin protocols on Solana, and from a business development perspective, we are happy to collaborate with some other DePin protocols. One cool thing we found is that Solana has its own phone, and we believe the adoption of Solana phones will only increase. This is something that no other chain can offer. For us, it's a no-brainer to have an app installed on a Solana phone.
Have you drawn inspiration from other projects in the DePin field, such as Helium?
Certainly, the whole idea behind DePin is about yourself. Not only are you paying too much for many things in life, but you are also being deprived of something that you could have earned.
Recent DePin pushes for decentralization, and some things like what Helium Mobile and Saga Mobile are doing, have opened everyone's eyes. It's like, I have so many resources, but in many cases, these resources are being taken away from me. But now, people see another path where you have the right to choose not to accept this situation. It's very empowering, and I don't want to miss out on it. So, we have gained a lot of inspiration from it.
Looking ahead to the future, what will Grass look like in 2024? Can you give us some insights into your roadmap?
We plan to fully launch the network at some point in 2024, and I don't think anyone will be surprised.
In addition, on the roadmap, we want to implement request proofs using zk-TLS, binding network requests to datasets, which may happen in the second half of the year. We also plan to decentralize many of our sorters. How this will be implemented is still to be determined, but we have many exciting ideas that will allow people to run Grass infrastructure more easily.
We are also considering the issue of hardware. Right now, the cost of using Grass is zero, and we like it that way and intend to keep it that way. But suppose you don't want your device to be online all the time, or for some reason, you don't want to run the node on your device. We want to give people an option to simply buy a box, connect it to their internet, and let it run in the background. Besides personal preferences, an exciting aspect of having hardware is that we can actually put AI agents in the hardware and allow them to run in it. They can do a lot of network crawling and crawling work for you. All you have to do is sit back and let those AI agents do the work, just like having a self-driving car that can map out routes.
If you want to contribute more to the network, we hope to have a device available that can do that.
We are developing some small features, such as gamification features for the dashboard. We also want to add some Easter egg features specifically for Saga users, and we are currently exploring ideas in that area. In addition, we are looking into the release of other devices. Right now, we are not only considering network expansion but also making it available to those who need it. For example, many people don't like installing extensions, and that's perfectly fine. So, we plan to expand it to other platforms such as Android, iOS, Raspberry Pi, Linux, and more.
Overall, we want to give people more choices to easily join the Grass network.
How do you view the governance structure of Grass? Will it be a fully community-owned decentralized network?
We are moving towards decentralization in several different stages. The first is the authentication mechanism, where we can reward users for their contributions on-chain.
The second stage involves the decentralization of our sorters and some content approval for crawling requests. Governance plays a crucial role here. Essentially, we want to be a massive data supply network where community members can say, "Hey, I'm training this AI model, I need these types of datasets, and I want to propose that we shift the crawling work towards fetching this data." Then, the sorters can also act as validators to ensure the correct data is being crawled.
One of the few governance functions we want to include is protecting the network. In a decentralized network, market efficiency is usually achieved over time if executed properly. There are many applications that can be monetized through unused CPU, GPU, etc., usually traded in fiat currency. They may initially pay a certain fee to onboard members, then decrease the fee over time, and eventually the returns become minimal.
Through the governance structure, you can protect the community because those who contribute to the network actually own a part of the network. This is the state we want to achieve, where everyone running nodes in the Grass network owns a part of the network itself.
Do you think you currently have enough scale in theory to launch the network? Or do you still want to increase the number of nodes before launching?
In terms of the overall number of nodes, we are very close to our target. However, in specific geographical locations, we are actually not as close. In some locations, people want to crawl specific types of content, and the demand there is actually higher than the supply. We want to ensure that we have the capability to meet all demands, which is our goal for launching the network.
As you know, we are in the testing phase, so we are working to ensure that the network is scalable. Due to our growth being faster than expected, people have encountered some issues with accessing the network and dashboard display. These are issues we plan to address before the full network launch. That's why we are still in the testing phase. So, in terms of the number of nodes, we are considering many factors. Overall, we are quite satisfied with the current situation.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







