Source: Synced

Image Source: Generated by Wujie AI
This review delves into the issue of resource efficiency of large language models.
In recent years, large language models (LLMs) such as OpenAI's GPT-3 have made significant progress in the field of artificial intelligence. These models, with massive parameter counts (e.g., 175 billion parameters), have achieved leaps in complexity and capability. As the trend of LLM development continues towards ever larger model scales, these models are being applied more widely, from intelligent chatbots to complex data analysis, and even in multi-domain research. However, the exponential growth in model scale has brought about significant resource demands, particularly in terms of computation, energy, and memory.
The enormous demand for these resources makes the training or deployment of such large models costly, especially in resource-constrained environments such as academic labs or the medical field. Additionally, as training these models requires a large number of GPUs, their environmental impact has become an increasingly pressing issue, particularly in terms of power consumption and carbon emissions. Effectively deploying and applying these models in resource-constrained environments has become an urgent issue.
A research team from Emory University, University of Virginia, and Penn State University has comprehensively reviewed and analyzed the latest research in the LLM field, systematically summarizing various techniques to improve model resource efficiency and deeply discussing future research directions. These efforts not only cover the entire lifecycle of LLM (pre-training, fine-tuning, prompting, etc.), but also include the classification and comparison of various resource optimization methods, as well as the standardization of evaluation metrics and datasets. This review aims to provide scholars and practitioners with a clear guidance framework to help them effectively develop and deploy large language models in resource-constrained environments.

Paper link: https://arxiv.org/pdf/2401.00625
I. Introduction
Resource-efficient LLMs require an understanding of the key resources involved in the LLM lifecycle. In this review, the authors systematically classify these resources into five main categories: computation, memory, energy, funding, and communication costs. Efficiency here is defined as the ratio of input resources to output, with a more efficient system being able to produce the same level of output while consuming fewer resources. Therefore, a resource-efficient LLM aims to maximize performance and capability across all these dimensions while minimizing resource expenditure, thus achieving more sustainable and accessible AI solutions.
Resource efficiency in LLM is a crucial and complex area that requires innovative solutions to address significant challenges. These challenges encompass five levels:
- Model level: The low parallelism of autoregressive generation leads to significant latency issues, particularly prominent in large models or with long input lengths, affecting the efficient processing of training and inference. In addition, the quadratic complexity of self-attention layers significantly increases with input length, becoming a computational bottleneck.
- Theoretical level: Scaling laws and diminishing returns indicate that as the model grows larger, the performance improvement brought by adding each parameter decreases. Additionally, theoretical challenges regarding generalization and overfitting in machine learning also pose challenges to the resource efficiency of LLMs.
- System level: Given the large model size and training datasets of LLMs, putting them all into the memory of a single GPU/TPU becomes impractical. Therefore, complex system design to optimize the training process for LLMs becomes crucial.
- Ethical level: Many LLMs rely on large and proprietary training datasets, limiting the application of certain efficiency-improving techniques. Additionally, many advanced LLMs are closed-source, making it more complex to improve efficiency without a deep understanding of the model's internal workings.
- Evaluation metric level: The diversity and complexity of LLMs pose unique challenges in developing comprehensive resource efficiency evaluation metrics. Compared to optimizing a few resources for smaller models, LLMs present multi-objective problems, requiring optimization across multiple key resources simultaneously.
To address the above challenges, this review provides the following contributions:
- Comprehensive overview of resource-efficient LLM technologies: A comprehensive overview of techniques to enhance LLM resource efficiency, covering various methods and strategies throughout the entire lifecycle of LLMs.
- Systematic classification and taxonomy of technologies by resource type: Establishing a systematic classification and taxonomy based on the types of resources optimized for resource-efficient LLM technologies.
- Standardization of evaluation metrics and datasets: Proposing a set of evaluation metrics and standardization of datasets specifically for evaluating LLM resource efficiency.
- Identifying gaps and future research directions: In-depth discussion of current bottlenecks and unresolved challenges in creating resource-efficient LLMs, and pointing out potential avenues for future research.
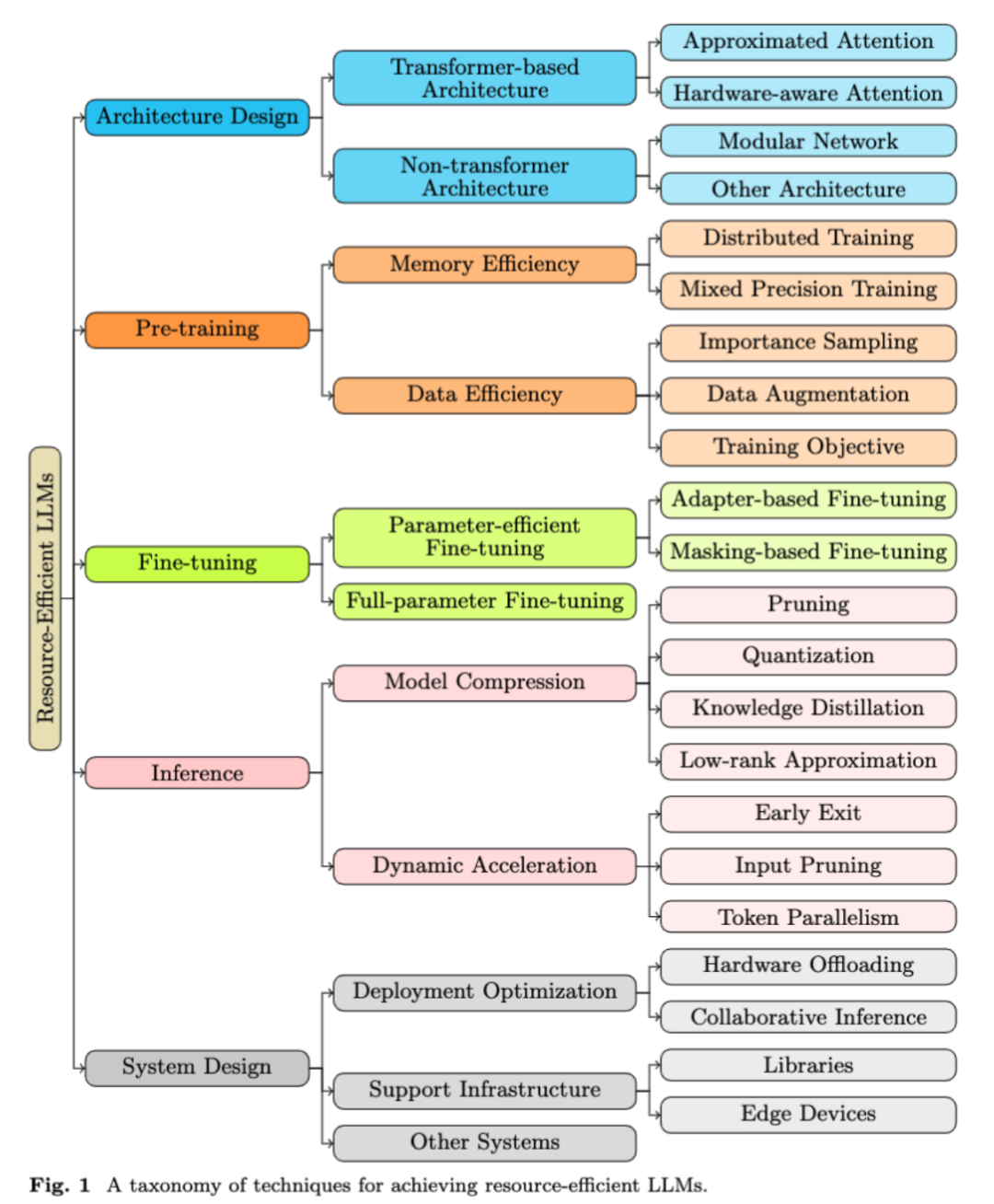
II. A Novel Classification of Resource-Efficient Large Language Models
This review proposes a comprehensive classification to systematically understand and optimize the key resources involved in large language models (LLMs). This classification includes five key areas: computation, memory, energy, funding, and network communication, each addressing different aspects of resource utilization:
1. Resource Classification
- Computation: Involves the processing power required for training, fine-tuning, and executing LLMs. Evaluation of computational efficiency includes considerations of operation count (e.g., floating-point operations), algorithm efficiency, and utilization of processing units (e.g., GPU or TPU).
- Memory: Memory efficiency involves the required RAM and storage. Especially for LLMs with billions of parameters, a large amount of memory is needed to store model weights and process large datasets.
- Energy: Refers to the electricity consumed throughout the model lifecycle. Given environmental impact and operational costs, energy efficiency is crucial. This includes strategies to reduce energy consumption, such as optimizing hardware utilization and using energy-efficient hardware.
- Funding: Financial resources are a key consideration, especially for small organizations and researchers. This includes hardware acquisition costs, model operation electricity costs, and potential cloud computing expenses.
- Network communication: Becomes important in distributed training and cloud-based deployment, where network bandwidth and latency are crucial. Efficient network communication means reducing the amount of data transmitted between distributed system nodes or between the cloud and users, significantly impacting training time and real-time application responsiveness.
2. Technology Classification
Additionally, this review introduces a structured classification, categorizing technologies that enhance LLM resource efficiency into clear, defined levels. This includes five main categories: architecture design, pre-training, fine-tuning, inference, and system design. Each category plays an indispensable role in the lifecycle of developing and deploying resource-efficient LLMs.
- Architecture design: Examines the foundational structure of LLMs, divided into Transformer-based and non-Transformer architecture.
- Pre-training: Examines the initial stage of LLM development, including memory efficiency and data efficiency.
- Fine-tuning: Optimizes pre-trained models, divided into parameter-efficient fine-tuning and full-parameter fine-tuning.
- Inference: Adopts various strategies during the operational phase, such as model compression and dynamic acceleration.
- System design: Focuses on system-level considerations, including deployment optimization and supporting infrastructure.
This classification aims to provide a structured and detailed understanding of diverse methods and strategies used to enhance the efficiency and acceleration of LLMs, offering a comprehensive perspective for the current research field.
III. Methodology
1. New Advances in Large Language Model Architecture Design
This review focuses on two major directions in the architecture design of large language models (LLMs): efficient Transformer structures and non-Transformer architectures.
- Efficient Transformer structures: This category includes innovative techniques to optimize the architecture of Transformer models, aiming to reduce computational and memory requirements. For example, Reformer improves attention mechanisms through locality-sensitive hashing, while Linear Transformer uses linear mapping to reduce computational complexity. Other methods such as AFT and KDEFormer achieve significant improvements in time and memory efficiency through different approaches.
- Non-Transformer architectures: This category explores alternative architectures to the Transformer. For example, Modularized Networks (MoE) technology combines multiple specialized models to handle complex tasks, while Switch Transformer and GLaM use sparse routing techniques to increase model parameters while maintaining efficiency. Additionally, architectures like RWKV combine the training efficiency of Transformers with the inference efficiency of RNNs.
These innovative directions not only optimize the resource efficiency of LLMs but also drive the overall development of language model technology.
2. Large Language Model Pre-training: Efficiency and Innovation
This review explores efficient pre-training strategies for large language models (LLMs) such as GPT-4, which focus not only on speed but also on optimal utilization of computational resources and innovative data management.
Memory efficiency
Distributed training: Distributing model training tasks to multiple nodes to accelerate the training process. Data parallelism (DP) and model parallelism (MP) are two main strategies. DP involves partitioning the initial dataset and training in parallel on multiple accelerators, while MP distributes model layers or tensors across multiple accelerators.
Mixed precision training: This technique accelerates the training of deep learning models by simultaneously using 16-bit and 32-bit floating-point types, particularly suitable for training large language models.
Data efficiency
Importance sampling: This method improves data efficiency by prioritizing information-rich training instances for processing.
Data augmentation: Creating modified copies of existing data to fully utilize the current data.
Training objectives: The choice of pre-training objectives is another factor determining data efficiency. This typically involves the design of model architecture, input/target construction, and masking strategies.
Through these strategies, the review aims to demonstrate how to pre-train large language models in a resource-efficient manner, not only accelerating the training process but also ensuring the sustainable and cost-effective development of advanced LLMs.
3. Fine-tuning of Large Language Models: Balancing Performance and Resources
This review discusses fine-tuning strategies for specific tasks using large language models such as GPT-4. These strategies aim to find a balance between achieving task-specific performance and maintaining resource efficiency.
Parameter-efficient fine-tuning
Mask-based fine-tuning: Updating only a subset of model parameters, while other parameters are "frozen" or masked during the backpropagation process.
Adapter-based fine-tuning: Inserting additional lightweight layers (adapters) between the existing layers of the pre-trained model. During fine-tuning, only the parameters of these adapter layers are updated, while the original model parameters remain fixed.
Full-parameter fine-tuning: In contrast to parameter-efficient fine-tuning, full-parameter fine-tuning involves modifying all parameters. While it may incur higher training costs, it often achieves better performance than parameter-efficient methods. However, this approach may not always be effective on simple datasets and faces challenges in terms of training costs and GPU memory consumption.
Through these strategies, the review aims to demonstrate methods for achieving a balance between optimizing the performance of large language models and adhering to resource constraints.
4. Inference of Large Language Models: Pursuing Efficiency and Quality
This review discusses optimization techniques for the inference phase of large language models such as the GPT series, focusing on reducing computational load and memory usage while maintaining high-quality output.
Model compression
Pruning: Reducing complexity by removing specific parameters from the model. This includes structured pruning (targeting overall structures such as neurons or channels) and unstructured pruning (targeting individual weights or connections).
Quantization: Converting floating-point numbers in the model to representations with fewer bits (e.g., integers) to reduce model storage requirements and accelerate computation.
Knowledge distillation: Transferring knowledge from a large model to a more compact network to reduce inference latency and enhance task-specific capabilities.
Dynamic acceleration
Early exit: Terminating the computation of certain layers of the model based on certain criteria to simplify the processing of input samples.
Input pruning: Dynamically reducing the length of input sequences and allocating different computational resources to different input tokens based on content.
Token parallelism: Using techniques such as speculative execution to generate multiple tokens in parallel, rather than the traditional sequential approach.
Through these strategies, the review aims to demonstrate how to efficiently deploy large language models in practical applications, considering both resource constraints and performance requirements.
5. System Design of Large Language Models: Optimization and Application
This review discusses key strategies for the system design of large language models such as the GPT series, particularly in achieving efficient inference in resource-constrained environments.
Deployment optimization
Hardware offloading: Optimizing the operation of large LLMs by transferring temporarily unnecessary data from fast accelerators to slower but larger main and auxiliary storage (e.g., CPU memory and disk). Effective offloading strategies are crucial for overall system efficiency.
Collaborative inference: Multiple users or systems collaborate to complete the inference tasks of LLMs, with each participant contributing their resources such as computational power or data to overcome individual user or system limitations, achieving more efficient and accurate inference.
Supporting infrastructure
Libraries: Introduces several well-known large language model frameworks such as DeepSpeed, Megatron-LM, Colossal-AI, Mesh-TensorFlow, and GPT-NeoX, which provide multi-level parallel strategies for large-scale distributed training.
Edge devices: Explores the research trend of deploying LLMs on edge devices, which typically have limited computational resources. For example, techniques such as low-rank adaptation and noise-contrastive estimation are used to reduce the memory requirements of LLMs on edge devices.
Other systems
Tabi: Proposes an inference system with a multi-level inference engine, reducing the inference latency of LLMs by using multiple DNNs to process heterogeneous queries in tasks.
Near-duplicate sequence search: Improves the efficiency and scalability of near-duplicate sequence search for LLMs using techniques such as minhash.
Through these strategies, the review aims to demonstrate how system design of large language models achieves maximized efficiency and scalability in various deployment scenarios.
IV. Summary of Resource-Efficient Techniques for Large Language Models
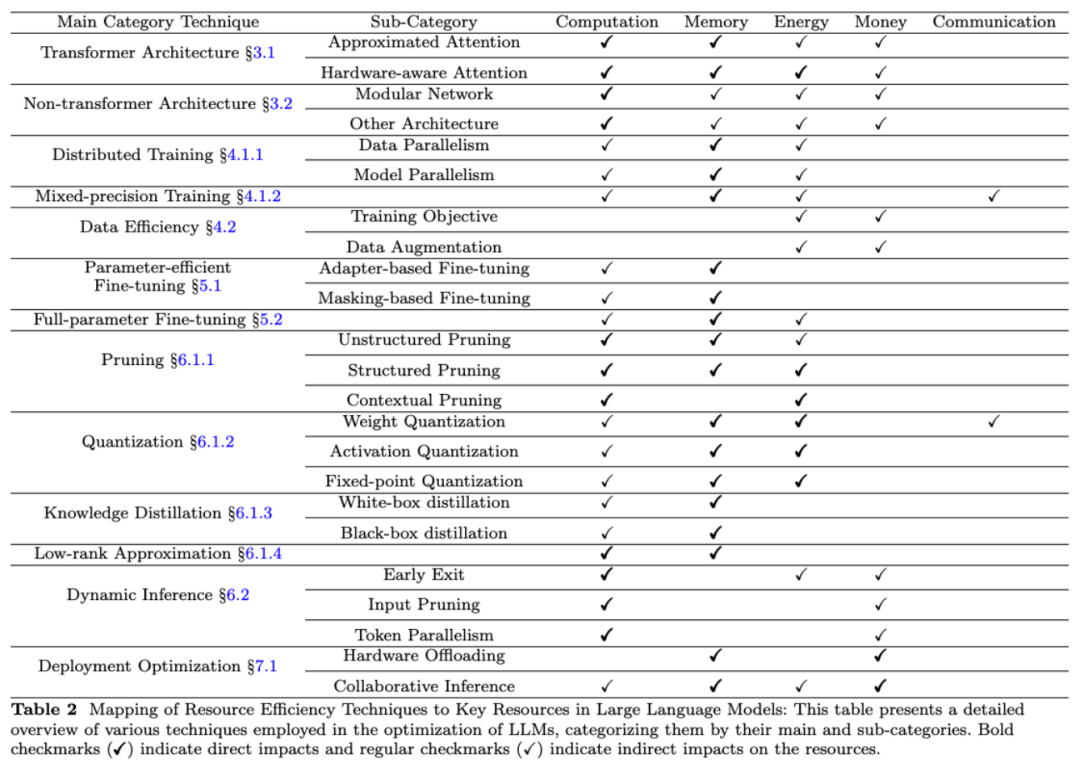
This review discusses various techniques applied to large language models (LLMs) to enhance their efficiency across different resources. These resources include computation, memory, energy, financial costs, and network communication. Each technique plays a crucial role in optimizing the resource efficiency of LLMs.
Computation Efficiency
- Direct impact: Pruning and quantization significantly save memory by reducing the model size; knowledge distillation trains a smaller model to mimic a larger model.
- Indirect impact: Distributed training, such as data and model parallelism, effectively manages memory usage across multiple devices, alleviating the burden on individual devices.
Energy Efficiency
- Direct impact: Structured pruning and quantization reduce the number of operations and data size, lowering the energy consumption of training and inference; context pruning saves energy by minimizing unnecessary computations.
- Indirect impact: Mainly focused on computational efficiency, techniques such as approximate attention mechanisms indirectly promote energy savings by reducing computational load.
Financial Cost Efficiency
Indirect impact: Data-efficient methods, such as optimized training objectives and data augmentation, may shorten training time and reduce computational resource usage by improving data utilization; dynamic inference techniques, such as early exit and input pruning, reduce computational requirements during the inference phase, lowering overall deployment costs.
Network Communication Efficiency
- Direct impact: Mixed precision training directly affects data transmission efficiency by reducing the data size that needs to be communicated between processors; weight quantization minimizes data payload during communication.
- Indirect impact: Collaborative inference improves network communication efficiency by optimizing data transmission and processing.
Through these strategies, the review aims to demonstrate how to improve the efficiency of large language models across various resources using multiple techniques. The detailed correspondence between techniques and resources can be seen in the table below.
V. Evaluation Datasets and Metrics for Large Language Models
This review provides a detailed analysis of diverse metrics for evaluating the resource efficiency of large language models (LLMs), offering crucial guidance for a comprehensive understanding of LLM resource efficiency.
Computational Efficiency Metrics
- FLOPs: Floating-point operations, quantifying computational efficiency.
- Training time: Total time required for training LLM, reflecting model complexity.
- Inference time/delay: Time required for LLM to generate output, crucial for assessing practical utility in real-world applications.
- Throughput: Efficiency of LLM in processing requests, measured by the speed of generating tokens per second or completing tasks.
- Speedup: Improvement in inference speed compared to a baseline model.
- Memory Efficiency Metrics
- Parameter count: Number of adjustable variables in the LLM neural network.
- Model size: Storage space required for the entire model.
Energy Efficiency Metrics
- Energy consumption: Represented in watt-hours or joules, reflecting the electricity usage over the lifecycle of LLM.
- Carbon emissions: Greenhouse gas emissions associated with model energy usage.
Financial Cost Efficiency Metrics
Cost per parameter: Ratio of total cost to train (or run) LLM to the number of parameters.
Network Communication Efficiency Metrics
Communication volume: Total amount of data transmitted between networks during specific LLM execution or training processes.
Other Metrics
- Compression ratio: Ratio of compressed model size to original model size.
- Fidelity and faithfulness: Measures of prediction consistency and alignment of probability distributions between teacher and student models.
- Robustness: Measures the performance and query count of LLM after attacks.
- Pareto optimality: Achieving the best balance between competing factors.
Datasets and Benchmarks
- Dynaboard: Dynamic benchmarks evaluating memory usage, throughput, fairness, and robustness metrics.
- EfficientQA: Focuses on building accurate, memory-efficient open-domain question-answering systems.
- SustaiNLP 2020: Challenges participants to develop energy-efficient NLP models.
- ELUE and VLUE: Focus on evaluating the efficiency and performance of NLP and vision language models.
- Long-Range Arena: Designed for evaluating efficient Transformer models on long-form tasks.
- Efficiency-aware MS MARCO: Introduces efficiency metrics to the MS MARCO information retrieval benchmark.
Through these strategies, the review aims to provide a comprehensive methodology for evaluating the resource efficiency of large language models.
VI. Future Challenges and Research Directions for Large Language Models
As the field of large language models (LLMs) continues to advance, we face various open challenges that provide rich opportunities for future research directions.
Handling conflicts of resource types: There exist performance trade-offs between different optimization techniques, such as the conflict between computational efficiency and model parameter count. The key challenge is to develop comprehensive optimization strategies that balance multiple objectives, including computational efficiency, parameter count, and memory usage.
Integration of resource efficiency technologies: Effectively integrating multiple LLM optimization methods to enhance overall resource efficiency is a significant challenge. Currently, there is a lack of research on how these methods interact, necessitating a systematic combination of different strategies to significantly improve model efficiency.
Standardization and unified evaluation: There is currently a lack of unified benchmarks specifically for evaluating the resource efficiency of LLMs. This hinders the comprehensive and consistent evaluation of the performance of various LLMs in resource utilization, highlighting the urgent need for standardized benchmarks focused on resource efficiency.
Interpretability and robustness: While pursuing efficiency, attention should also be given to the interpretability and robustness of LLMs. Developing methods that optimize resource usage while maintaining transparency and resilience is essential to ensure that these models are reliable and easy to understand in different deployment scenarios.
Application of automated machine learning (AutoML) in resource-efficient LLMs: Integrating AutoML into the development of resource-efficient LLMs is an emerging area. By applying meta-learning and neural architecture search (NAS), automating parts of model optimization is expected to reduce the need for manual hyperparameter tuning and custom model design.
LLMs in edge computing: Deploying LLMs in edge computing environments presents unique challenges, such as device computational and memory resource constraints. There is a need to develop LLM technologies that are both resource-efficient and privacy-aware to adapt to edge computing scenarios.
Theoretical insights into the scaling laws of LLMs: A deeper understanding of how LLM performance scales with its size and complexity is a crucial and underexplored area. This understanding is essential for developing methods that focus not only on model compression but on improving the overall resource efficiency of LLMs.
VII. Conclusion
This review delves into the resource efficiency issues of large language models (LLMs), analyzing current research achievements and challenges, and envisioning future development directions. It also discusses high-efficiency techniques for LLMs across key resources such as computation, memory, energy, financial costs, and network communication, and how these techniques interact to improve overall efficiency. By comparing various techniques, the review reveals their potential and limitations in different application environments.
The authors also emphasize the importance of establishing a standardized and unified evaluation system for resource efficiency assessment. This not only helps to more accurately compare the performance of different LLMs but also provides a solid foundation for further research and development.
Finally, the review discusses a range of open challenges in the field of LLMs and potential research directions, including managing conflicts of resource types, integrating resource efficiency technologies, interpretability and robustness, the application of AutoML, and deploying LLMs in edge computing environments. These challenges provide rich opportunities for future research, crucial for driving LLMs towards higher efficiency, reliability, and sustainability.
This review provides a comprehensive perspective on understanding and optimizing the resource efficiency of LLMs, offering guidance and inspiration for future research in this important field.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







