Source: Synced

Image Source: Generated by Wujie AI
Even with obstruction, it can render high-fidelity 3D human bodies.

AR/VR, film, and medical fields widely apply video rendering of human figures. Due to the ease of video capture with a single camera, rendering human bodies from a single camera has been a primary research method. Methods such as Vid2Avatar, MonoHuman, and NeuMan have achieved remarkable results. Despite having only one camera angle, these methods can accurately render human bodies from new perspectives.
However, most existing methods for rendering human bodies are designed for relatively ideal experimental scenarios. In these scenarios, obstacles are almost non-existent, and all parts of the human body are fully displayed in each frame. This is quite different from real-life scenarios. In real-life scenarios, there are often multiple obstacles, and the human body may be obstructed while in motion.
Most neural rendering methods encounter significant difficulties when dealing with real-world scenes due to obstructions, with a major reason being the lack of supervision. Real-life scenarios often cannot provide authentic supervised data regarding human body appearance, shape, and posture. Therefore, models need to infer other information based on limited evidence, which is highly challenging, especially in cases where most of the human body is obstructed.
As many neural methods adopt point-based rendering schemes, when one point is obstructed and another is not, two very close coordinates will produce a significant difference in the rendering output. Therefore, methods not adapted to obstructed scenes often display incomplete human bodies or render floating objects and other visual errors when encountering obstructions.
Recently, renowned AI professor Fei-Fei Li released new progress on 3D human body rendering work on X — a new model called Wild2Avatar, which can render human bodies completely and with high fidelity even in obstructed scenarios.
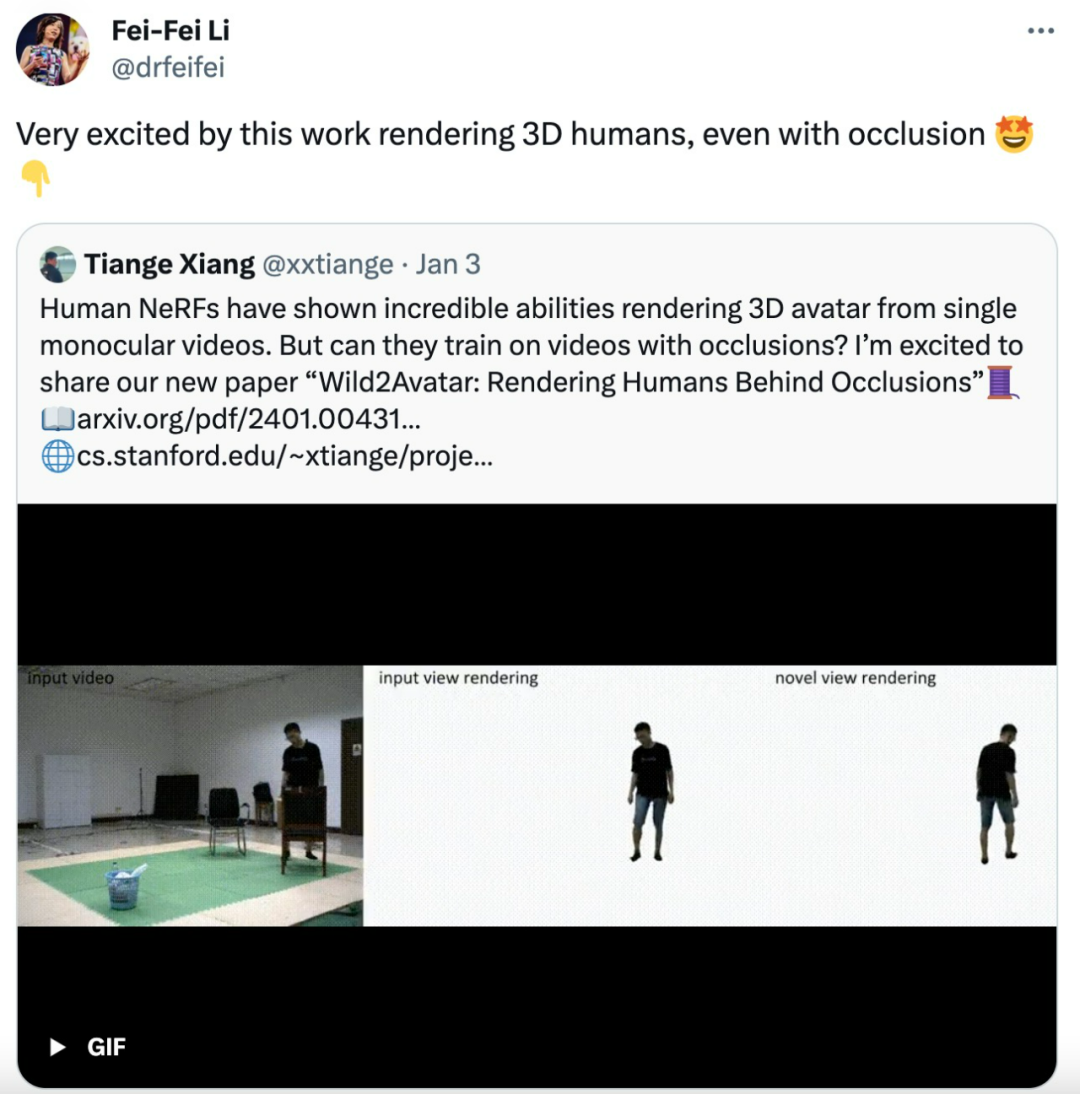
Wild2Avatar is a neural rendering method suitable for obstructed outdoor monocular videos. The research team proposed obstruction-aware scene parameterization, decoupling the scene into three parts — obstruction, human body, and background, and rendering these three parts separately, designing novel optimization objectives.

- Paper link: https://arxiv.org/pdf/2401.00431.pdf
- Project link: https://cs.stanford.edu/~xtiange/projects/wild2avatar/
Method Introduction
Wild2Avatar can render complete geometric shapes and high-fidelity appearances of 3D human bodies in obstructed outdoor monocular videos. The overall architecture of the Wild2Avatar model is shown in Figure 2:

Specifically, Wild2Avatar models obstructions, human bodies, and backgrounds as three independent neural scenes, enabling clear 3D reconstruction of human bodies regardless of obstructions. To achieve this, the research employed scene self-decomposition technology and proposed obstruction-aware scene parameterization based on inverted sphere parametrization.
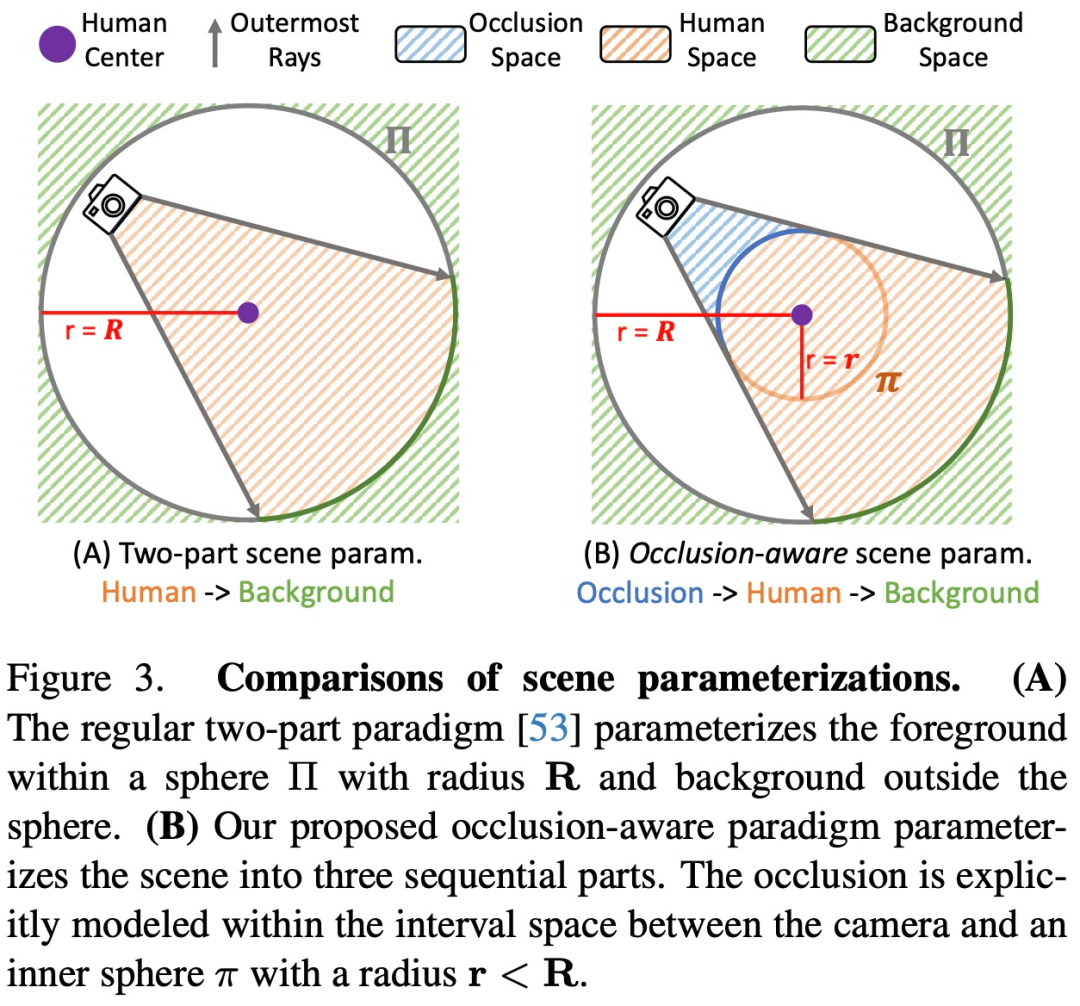
In addition to the first sphere defined by inverted sphere parametrization, the study also introduced a second inner sphere and defined the region from the camera to the edge of the inner sphere as the obstruction area. By separately rendering this area, Wild2Avatar successfully separated obstructions from other parts of the scene.
Furthermore, to ensure high-fidelity and complete rendering of human bodies, the study proposed a combination of pixel photometric loss, scene decomposition loss, obstruction decoupling loss, and geometric integrity loss to summarize the three renderings.

Experiments and Results
Datasets
OcMotion: This dataset consists of indoor scenes where human bodies are partially obstructed by various objects. The researchers selected 5 out of 48 videos from this dataset, showcasing different degrees of obstruction. They trained the model using only 100 frames extracted from each video and used the provided camera matrix, human posture, and SMPL parameters to initialize the optimization process. Binary human body segmentation masks within frames were obtained through "Segment Anything (SAM)."
Outdoor Videos: The researchers conducted additional experiments on two real-world videos, one downloaded from YouTube and the other captured by the research team using a mobile phone camera. They trained the model using 150 frames extracted from these two videos and obtained camera matrices, human postures, and SMPL parameters using SLAHMR. As real postures were not provided, the evaluation of these videos also demonstrated the robustness of various methods against inaccurate estimations.
Results on Obstructed Monocular Camera Videos
Figure 5 compares the rendering results of Vid2Avatar and Wild2Avatar on two datasets.

In Table 1, the researchers reported quantitative results of the two methods and observed that their rendering performance in visible parts was comparable. However, it is noteworthy that Wild2Avatar consistently outperformed Vid2Avatar in rendering the geometric shape of the body and obstructed parts.

Comparison with OccNeRF
The researchers compared Wild2Avatar with the recently introduced obstructed human body rendering software OccNeRF. The comparison results are shown in Figure 6.

To make a fair comparison, they trained OccNeRF on 500 frames and 100 frames of images, respectively. Due to the lack of implicit SDF representation, OccNeRF suffers from common defects such as floating artifacts and ghosting. Although OccNeRF can also recover obstructed parts of the human body, the human body tends to be accidentally distorted, resulting in lower rendering quality.
Visualization of Scene Decomposition
Wild2Avatar renders the three scene components in a combined manner. The human and background/obstruction are modeled in two separate neural scenes. Figure 7 shows the separately rendered images of these three scene components. It is important to note that since this work focuses solely on human body rendering, the artifact-free rendering of the background and obstruction is not within the scope of this work.

Ablation Experiments
Although Wild2Avatar can still recover obstructed appearances, without the proposed parameterization, many artifacts may appear in the rendered results, as shown in the first row of Figure 8.
Without using the suggested loss functions, it is not possible to fully recover the obstructed areas, as seen in the second row of Figure 8.
The proposed loss functions act as a regularizer, enforcing consistency between human body geometry and the SMPL mesh prior, preventing the rendering of incorrect postures, as shown in the third row of Figure 8.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







