Source: New Smart Element

Image Source: Generated by Wujie AI
Researchers at the Santa Fe Institute used very rigorous quantitative research methods to test that GPT-4 still has a significant gap in reasoning and abstraction compared to human levels. It is still a long way to go to develop AGI from the level of GPT-4!
GPT-4 may be the most powerful general language model currently available. Once released, in addition to marveling at its outstanding performance in various tasks, many have also raised questions: Is GPT-4 AGI? Does it really herald the day when AI will replace humans?
There are also many netizens on Twitter who have initiated polls:
Among them, the opposing views mainly focus on:
Limited reasoning ability: GPT-4 is most criticized for its inability to perform "reverse reasoning" and its difficulty in forming abstract models of the world for estimation.
Task-specific generalization: Although GPT-4 can generalize formally, it may encounter difficulties in cross-task objectives.
So how big is the gap between GPT-4's reasoning and abstraction abilities compared to humans? This kind of intuition seems to have lacked quantitative research support.
Recently, researchers at the Santa Fe Institute systematically compared the gap between humans and GPT-4 in reasoning and abstract generalization.

Paper link: https://arxiv.org/abs/2311.09247
In terms of GPT-4's abstract reasoning ability, researchers evaluated the performance of GPT-4's text version and multimodal version through the ConceptARC benchmark test. The results indicate that GPT-4 still has a significant gap compared to humans.
How does ConceptARC test work?
ConceptARC is based on ARC, a set of 1000 manually created analogy puzzles (tasks), each containing a small part (usually 2-4) of demonstrations of transformations on a grid, and a "test input" grid.
The challenger's task is to induce the underlying abstract rule from the demonstration and apply that rule to the test input to generate a transformed grid.
As shown in the figure below, by observing the rules of the demonstration, the challenger needs to generate a new grid.

The purpose of ARC is to emphasize capturing the core of abstract reasoning: inducing general rules or patterns from a small number of examples and being able to flexibly apply them to new, previously unseen situations; and to weaken language or learned symbolic knowledge to avoid reliance on "approximate retrieval" and pattern matching based on previous training data, which may be the reason for superficial success in language-based reasoning tasks.
Building on this, ConceptARC has been improved to include 480 tasks organized into systematic variations of specific core spaces and semantic concepts, such as Top and Bottom, Inside and Outside, Center, and Same and Different. Each task instantiates the concept in different ways and has different levels of abstraction.
With these changes, the concepts become more abstract, making them easier for humans to understand, and the results can better illustrate the comparison of GPT-4 and humans in abstract reasoning abilities.
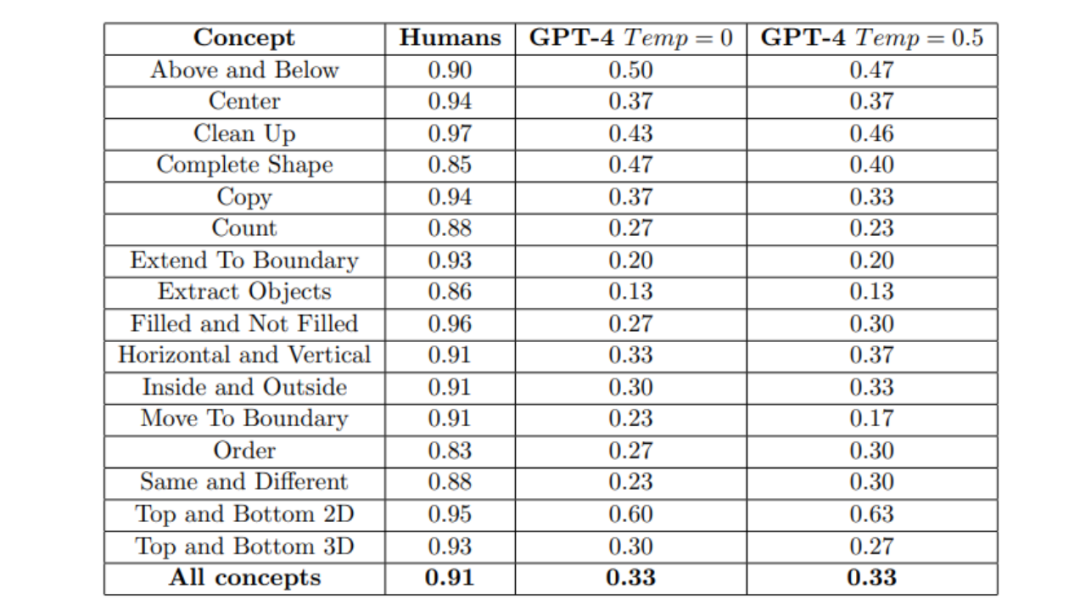
Test results show that GPT-4 still lags behind humans significantly
Researchers tested both the pure text version of GPT-4 and the multimodal version of GPT-4.
For the pure text version of GPT-4, researchers evaluated its performance using more expressive prompts, including explanations and examples of solved tasks. If GPT-4 answered incorrectly, it was asked to provide a different answer, with up to three attempts.
However, under different temperature settings (temperature is an adjustable parameter used to adjust the diversity and uncertainty of the generated text. The higher the temperature, the more random and diverse the generated text, which may contain more misspellings and uncertainties), for the complete set of 480 tasks, GPT-4's accuracy performance was far inferior to that of humans, as shown in the figure below.
In the multimodal experiment, researchers evaluated GPT-4V on the visual version of the simplest ConceptARC tasks (only 48 tasks), providing it with similar prompts as in the first experiment, but using images instead of text to represent the tasks.
The results, as shown in the figure below, indicate that the performance of providing extremely simple tasks as images to multimodal GPT-4 is even significantly lower than in the text-only case.

It is not difficult to conclude that GPT-4, possibly the most powerful general LLM currently, still cannot robustly form abstractions and reason about fundamental core concepts that appear in contexts not seen in its training data.
Analysis by netizens
A well-known netizen made a total of 5 comments on GPT-4's performance on ConceptARC. One of the main reasons explained:
The benchmark testing of large language models based on Transformers made a serious mistake. The testing usually guides the model to produce answers by providing brief descriptions, but in reality, these models are not designed solely to generate the next most likely token.
If the model is not properly guided with propositional logic to guide and lock in relevant concepts, it may fall into patterns of re-generating training data or providing the closest answer related to concepts that are not fully developed or correctly anchored in logic.
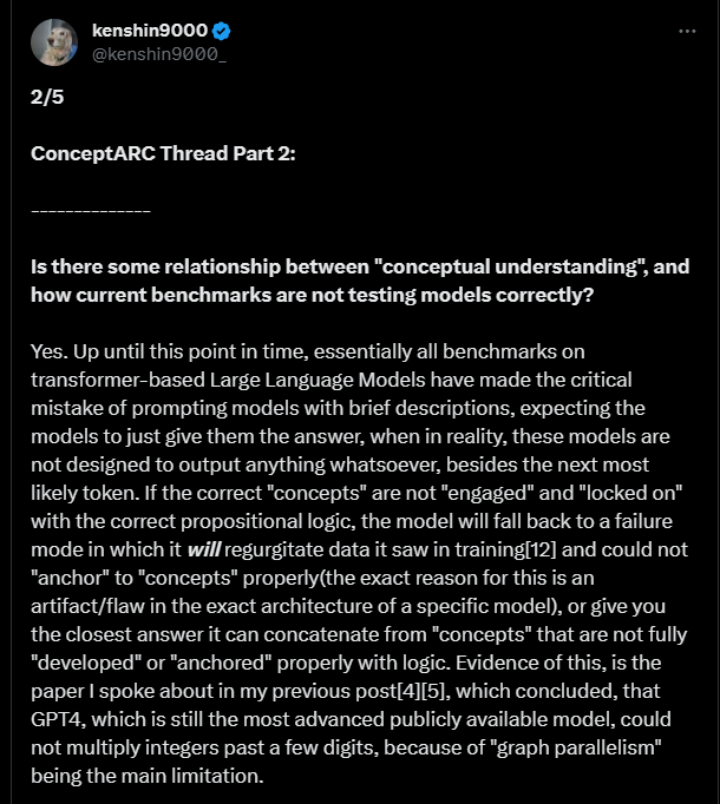
In other words, if the problem-solving approach of large models is as shown in the above image, the actual problem that needs to be solved may be as shown in the following images.


The researchers said that the next step to improve the abstract reasoning abilities of GPT-4 and GPT-4V may be to try other prompts or task representation methods.
It can only be said that the road to achieving human-level capabilities for large models is still a long and arduous one.
Reference: https://arxiv.org/abs/2311.09247
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








