Robots are a technology with endless possibilities, especially when combined with intelligent technology. Recently, a large model that has created many revolutionary applications is expected to become the intelligent brain of robots, helping robots perceive and understand the world, make decisions, and plan. Recently, a joint team led by Yonatan Bisk from CMU and Fei Xia from Google DeepMind published a review report introducing the application and development of foundational models in the field of robotics.
Original source: Synced
Image source: Generated by Wujie AI
Developing robots that can adapt to different environments autonomously has always been a dream of humanity, but it is a long and challenging road.
Previously, robot perception systems using traditional deep learning methods typically required a large amount of annotated data to train supervised learning models. If large datasets were annotated through crowdsourcing, the cost would be very high.
In addition, due to the limited generalization ability of classical supervised learning methods, in order to deploy these models to specific scenarios or tasks, these trained models usually require carefully designed domain adaptation techniques, which often require further data collection and annotation steps. Similarly, classical robot planning and control methods usually require careful modeling of the world, the dynamics of the agent itself, and/or the dynamics of other agents. These models are usually built for specific environments or tasks, and when the situation changes, the models need to be rebuilt. This indicates that the transfer performance of classical models is also limited.
In fact, for many use cases, the cost of building effective models is either too high or completely unattainable. Although motion planning and control methods based on deep (reinforcement) learning help alleviate these problems, they are still affected by distribution shift and reduced generalization ability.
While facing many challenges in developing general-purpose robot systems, the fields of natural language processing (NLP) and computer vision (CV) have made rapid progress, including powerful vision models and vision-language models for NLP, diffusion models for high-fidelity image generation, and powerful vision models for zero-shot/few-shot generation for CV tasks.
The so-called "foundation models" are actually large pre-trained models (LPTM). They possess powerful visual and language capabilities. These models have recently been applied in the field of robotics and are expected to endow robot systems with open-world perception, task planning, and even motion control capabilities. In addition to using existing visual and/or language foundation models in the field of robotics, research teams are also developing foundation models for robot tasks, such as action models for manipulation or motion planning models for navigation. These robot foundation models demonstrate strong generalization capabilities, being able to adapt to different tasks and even embodiments.
Some researchers directly apply visual/language foundation models to robot tasks, demonstrating the possibility of integrating different robot modules into a single unified model.
Although visual and language foundation models hold promise in the field of robotics, new robot foundation models are still under development, but there are still many challenges in the field of robotics that are difficult to solve.
From the perspective of practical deployment, models are often not reproducible and cannot generalize to different robot forms (multi-embodiment generalization) or have difficulty accurately understanding which behaviors in the environment are feasible (or acceptable). In addition, most research uses Transformer-based architectures, focusing on semantic perception of objects and scenes, task-level planning, and control. Other parts of robot systems are rarely studied, such as foundation models for world dynamics or foundation models for executing symbolic reasoning. These all require interdisciplinary generalization capabilities.
Finally, we also need more large-scale real-world data and high-fidelity simulators that support diverse robot tasks.
This review paper summarizes the foundational models used in the field of robotics, aiming to understand how foundational models can help address or alleviate the core challenges in the field of robotics.
Paper link: https://arxiv.org/pdf/2312.08782.pdf
In this review, the term "foundation models for robotics" used by the researchers covers two aspects: (1) existing (mainly) visual and language models used for robots, mainly through zero-shot and context learning; (2) the development and utilization of robot foundation models specifically using robot-generated data to solve robot tasks. They summarized the methods in the relevant papers on foundation models for robotics and conducted a meta-analysis of the experimental results of these papers.
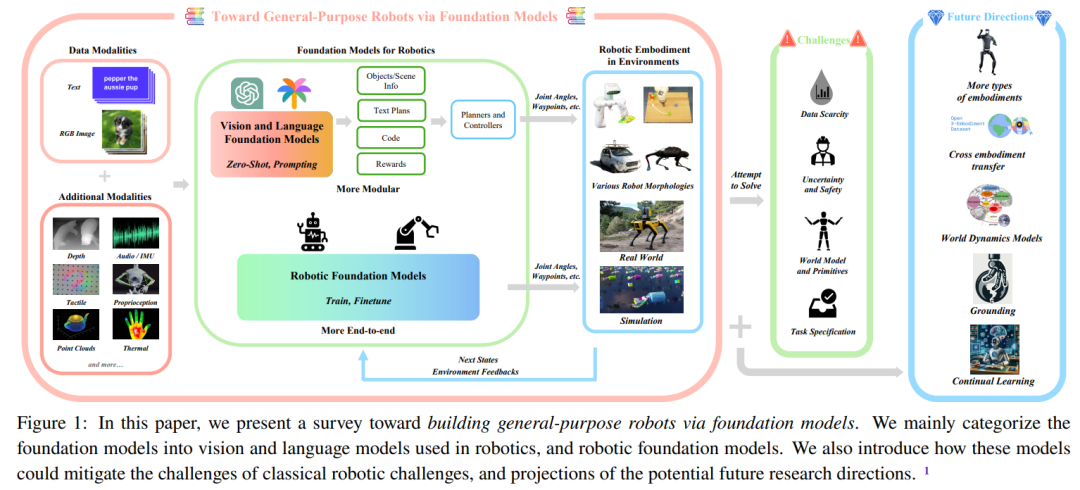
Figure 1 shows the main components of this review report.
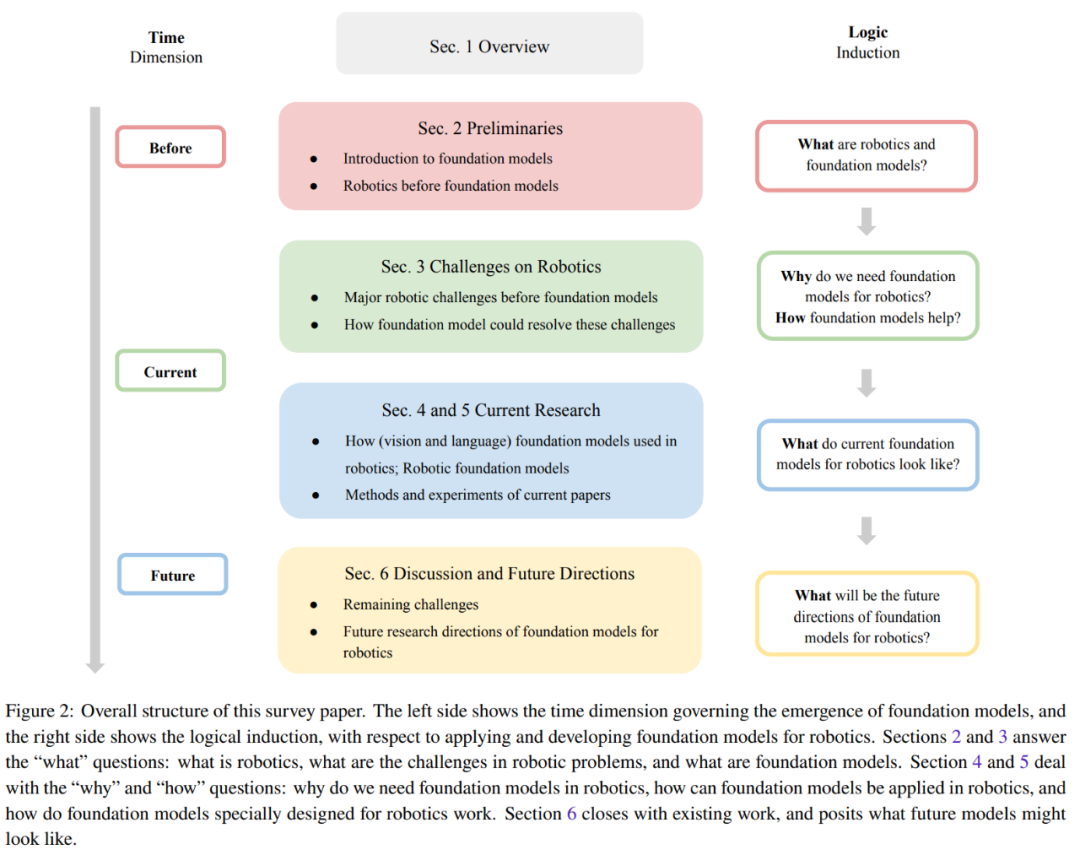
Figure 2 provides the overall structure of this review.
Background Knowledge
To help readers better understand the content of this review, the team first provides a section of background knowledge.
They will first introduce the basic knowledge of robotics and the current state-of-the-art technologies. This mainly focuses on the methods used in the field of robotics before the era of foundation models. Here is a brief explanation, for details please refer to the original paper.
The main components of robots can be divided into perception, decision and planning, and action generation.
The team divides robot perception into passive perception, active perception, and state estimation.
In the section on robot decision and planning, researchers introduce classical planning methods and learning-based planning methods.
Robot action generation also includes classical control methods and learning-based control methods.
Next, the team will introduce foundation models, mainly focusing on the NLP and CV fields, involving models such as LLM, VLM, visual foundation models, and text-conditioned image generation models.
Challenges in the Field of Robotics
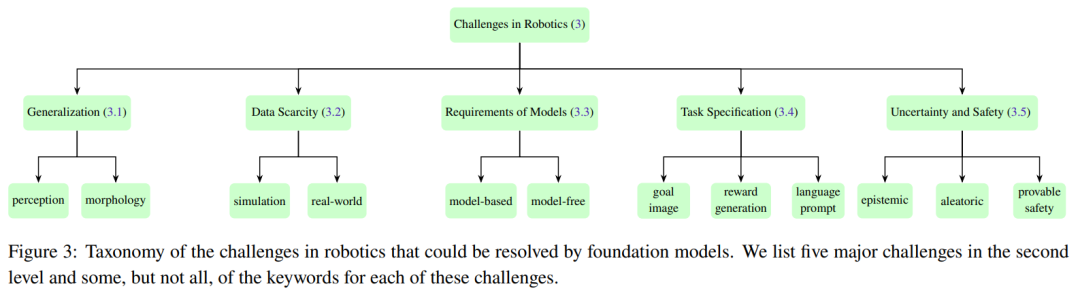
This section summarizes the five core challenges faced by typical robot systems in different modules. Figure 3 shows the classification of these five major challenges.
Generalization
Robot systems often have difficulty accurately perceiving and understanding their environment. They also lack the ability to generalize training outcomes from one task to another, further limiting their practicality in the real world. In addition, due to different robot hardware, it is very difficult to transfer models to different forms of robots. By using foundation models for robots, part of the generalization problem can be partially solved.
However, the further problem of generalizing across different robot forms remains to be addressed.
Data Scarcity


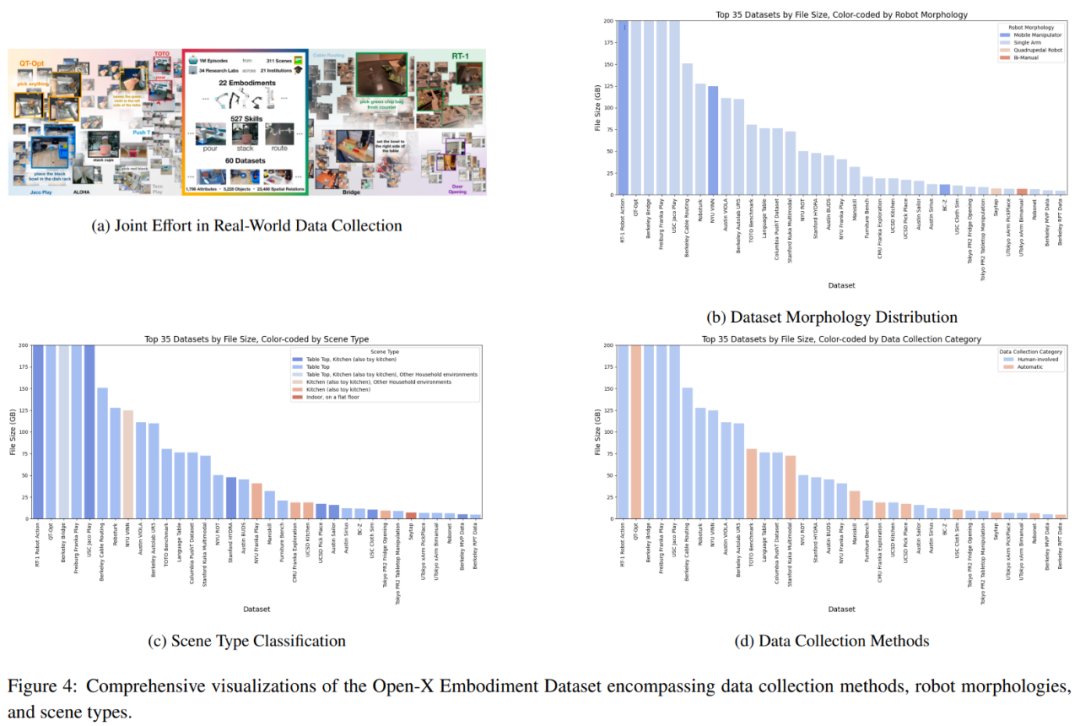
In order to develop reliable robot models, large-scale high-quality data is crucial. Efforts have been made to collect large-scale datasets from the real world, including automatic valuing and robot operation trajectories. However, collecting robot data from human demonstrations is costly. Additionally, collecting sufficient and diverse data from the real world is even more complex due to the diversity of tasks and environments. Furthermore, there are safety concerns associated with collecting data in the real world.
To address these challenges, many research efforts have attempted to generate synthetic data in simulated environments. These simulations can provide a highly realistic virtual world, allowing robots to learn and apply their skills in scenes that closely resemble real-world scenarios. However, using simulated environments has limitations, especially in terms of object diversity, making it difficult for learned skills to be directly applied to real-world situations.
Moreover, collecting data on a large scale in the real world is very difficult, and it is even more challenging to collect internet-scale image/text data used to train foundational models.
A promising approach is collaborative data collection, which involves collecting data from different laboratory environments and robot types, as shown in Figure 4a. However, the team conducted in-depth research on the Open-X Embodiment Dataset and found some limitations in the availability of data types.
Model and Primitives Requirements
Classical planning and control methods often require carefully designed environment and robot models. Previous learning-based methods (such as imitation learning and reinforcement learning) have been trained in an end-to-end manner, meaning they directly obtain control outputs based on sensory inputs, thus avoiding the construction and use of models. These methods can partially address the problem of relying on explicit models, but they often struggle to generalize to different environments and tasks.
This raises two questions: (1) How to learn model-agnostic policies that generalize well? (2) How to learn good world models to apply classical model-based methods?
Task Specification
To obtain a general intelligent agent, a key challenge is understanding task specifications and embedding them in the robot's current understanding of the world. Typically, these task specifications are provided by users, but users have limited understanding of the cognitive and physical limitations of the robot. This poses many problems, including not only what best practices can be provided for these task specifications, but also whether drafting these specifications is natural and simple enough. Understanding and addressing the ambiguity in task specifications based on the robot's understanding of its own capabilities is also challenging.
Uncertainty and Safety
A key challenge in deploying robots in the real world is dealing with the inherent uncertainty in the environment and task specifications. Depending on the source, uncertainty can be divided into cognitive uncertainty (caused by lack of knowledge) and aleatoric uncertainty (inherent noise in the environment).
The cost of uncertainty quantification (UQ) may be so high that it makes it difficult for research and applications to continue, and it may also prevent downstream tasks from being optimally addressed. Given the nature of large-scale over-parameterized foundational models, it is crucial to provide UQ methods that preserve training schemes while making minimal changes to the underlying architecture, in order to achieve scalability without sacrificing model generalization performance. Designing methods that provide reliable confidence estimates for their own behavior and intelligently request clear feedback is still an unsolved challenge.
While there has been some progress recently, ensuring that robots have the ability to learn from experience, fine-tune their strategies in completely new environments, and ensure safety remains challenging.
Overview of Current Research Methods
This section summarizes the current research methods for foundational models used in robotics. The team divides the foundational models used in the field of robotics into two categories: foundational models for robots and robot foundational models (RFM).
Foundational models for robots mainly refer to deploying visual and language foundational models for robots in a zero-shot manner, meaning no additional fine-tuning or training is required. Robot foundational models may use visual-language pre-training initialization for warm-starting and/or directly training models on robot datasets.
Figure 5 provides details of the classification.
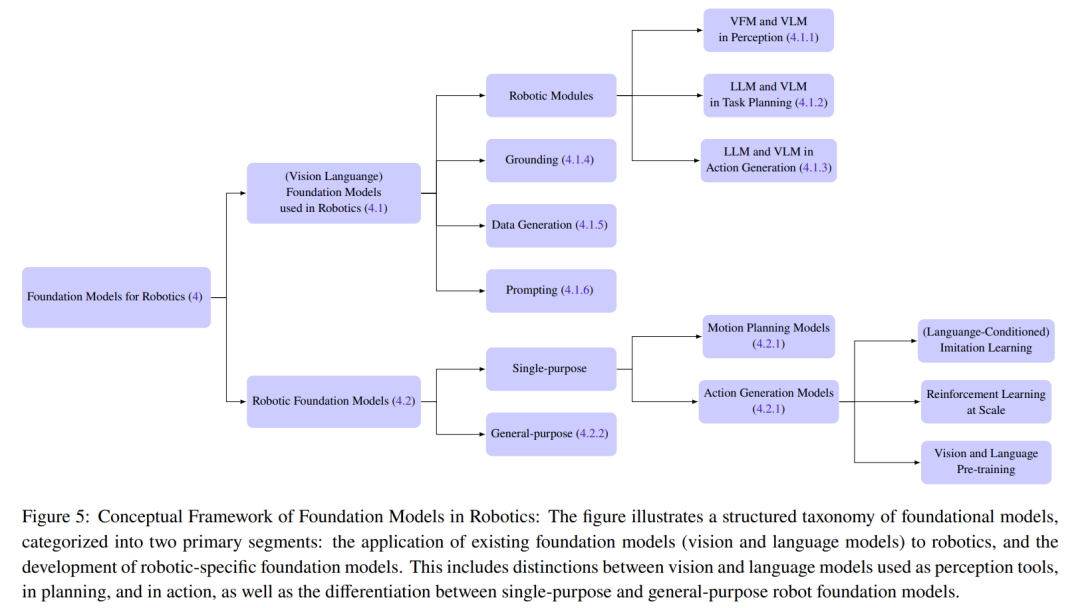
Foundational Models for Robots
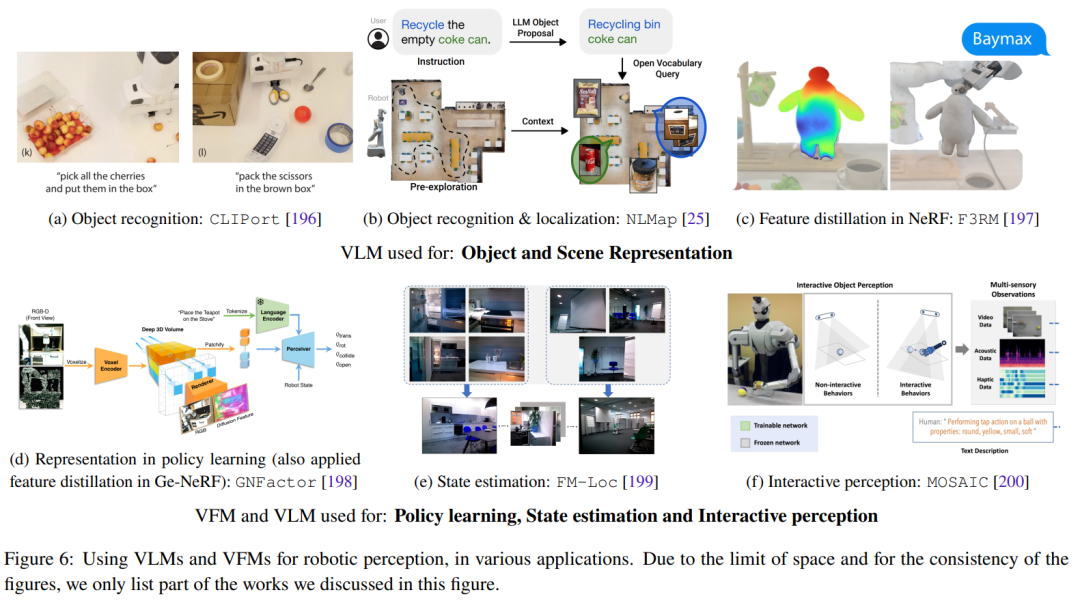
This section focuses on the zero-shot application of visual and language foundational models in the field of robotics. This mainly includes deploying VLM in robot perception applications in a zero-shot manner, using LLM's context learning capabilities for task-level and motion-level planning, and action generation. Figure 6 shows some representative research work.
Robot Foundational Models (RFM)
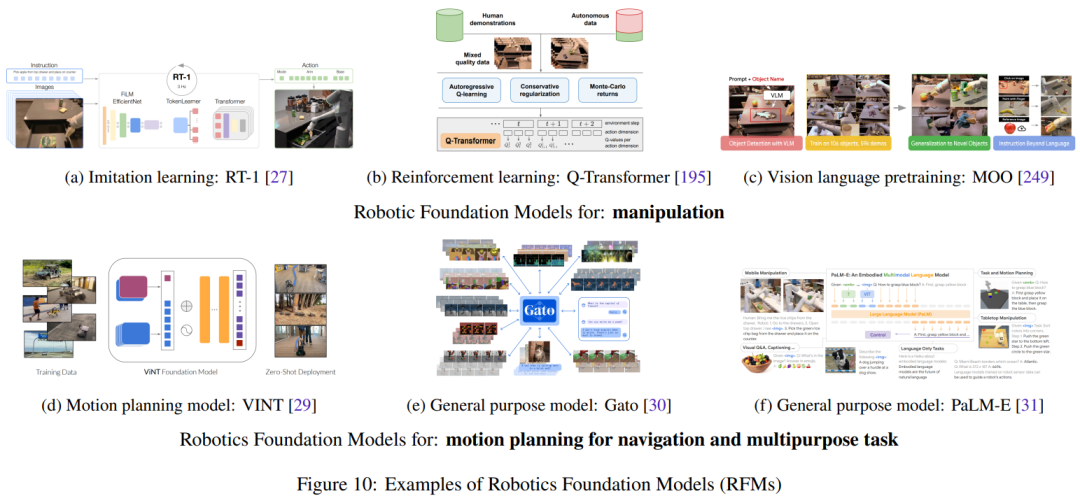
With the growth of robot datasets containing state-action pairs from real robots, the category of robot foundational models (RFM) is becoming increasingly likely to succeed. These models are characterized by using robot data to train models to solve robot tasks.
This section will summarize and discuss different types of RFM. First, there are RFM that can perform a class of tasks within a single robot module, also known as single-goal robot foundational models. For example, models that can generate low-level actions to control robots or models that can generate higher-level motion planning.
Next, there are RFM that can perform tasks across multiple robot modules, meaning they can perform perception, control, and even non-robot tasks.
How Can Foundational Models Help Address Robot Challenges?
The previous section listed the five major challenges faced in the field of robotics. This section will describe how foundational models can help address these challenges.
All foundational models related to visual information (such as VFM, VLM, and VGM) can be used in the robot's perception module. The functionality of LLM is more diverse and can be used for planning and control. Robot foundational models (RFM) are typically used in the planning and action generation modules. Table 1 summarizes the foundational models' ability to address different robot challenges.
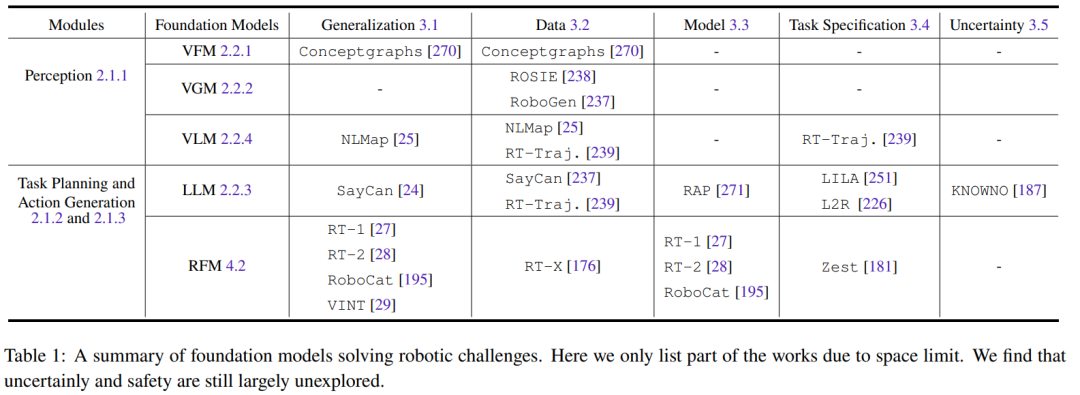
From the table, it can be seen that all foundational models excel in generalizing tasks across various robot modules. LLM is particularly adept at task specification. On the other hand, RFM excels in addressing challenges related to dynamic models, as most RFM are model-free methods. For robot perception, the challenges of generalization and model are coupled, as if the perception model already has good generalization capabilities, there is no need to acquire more data for domain adaptation or additional fine-tuning.
Additionally, there is a lack of research in the area of safety challenges, which will be an important future research direction.
Overview of Current Experiments and Evaluations
This section summarizes the datasets, benchmarks, and experiments of current research results.
Datasets and Benchmarks
Relying solely on knowledge learned from language and visual datasets has limitations. As some research results have shown, concepts such as friction and weight cannot be easily learned through these modalities alone.
Therefore, to enable intelligent agents to better understand the world, the research community is not only adapting foundational models from the language and visual domains but also advancing the development of large, diverse, multimodal robot datasets for training and fine-tuning these models.
Currently, this work is divided into two main directions: collecting data from the real world and collecting data from the simulated world and then transferring it to the real world. Each direction has its own advantages and disadvantages. The datasets collected from the real world include RoboNet, Bridge Dataset V1, Bridge-V2, Language-Table, and RT-1. The commonly used simulators include Habitat, AI2THOR, Mujoco, AirSim, Arrival Autonomous Racing Simulator, and Issac Gym.
Evaluation and Analysis of Current Methods
Another major contribution of the team is the meta-analysis of the experiments mentioned in this review report, which can help the authors clarify the following questions:
- What tasks are the researchers studying to solve?
- What datasets or simulators are used to train the models? What are the robot platforms used for testing?
- What foundational models are used by the research community? How effective are they in solving tasks?
- Which foundational models are more commonly used in these methods?
Tables 2-7 and Figure 11 provide the analysis results.
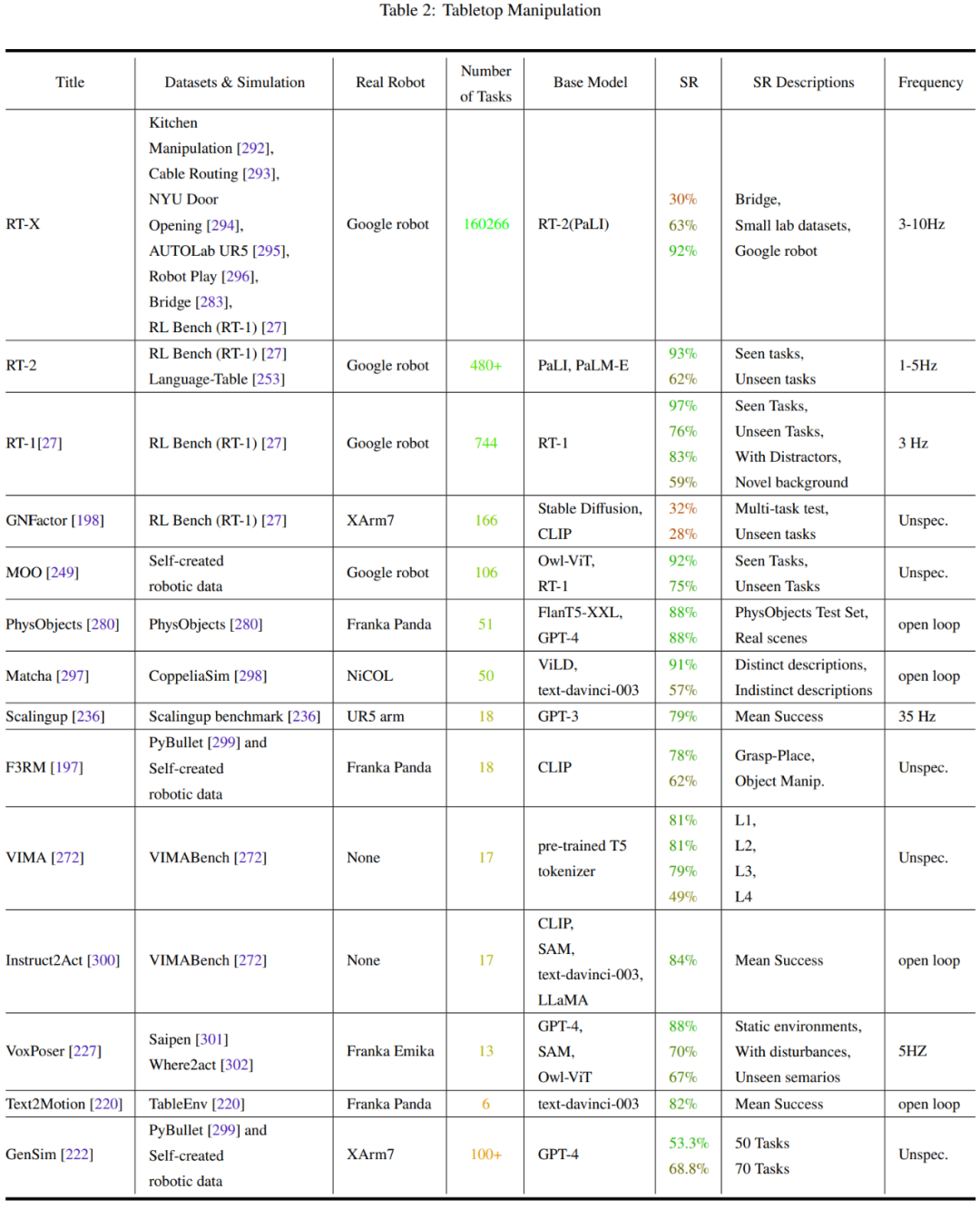
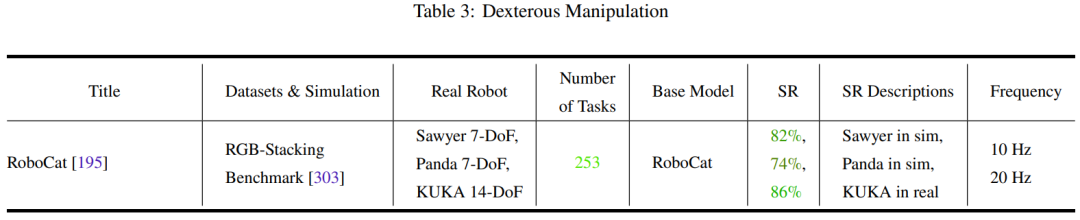
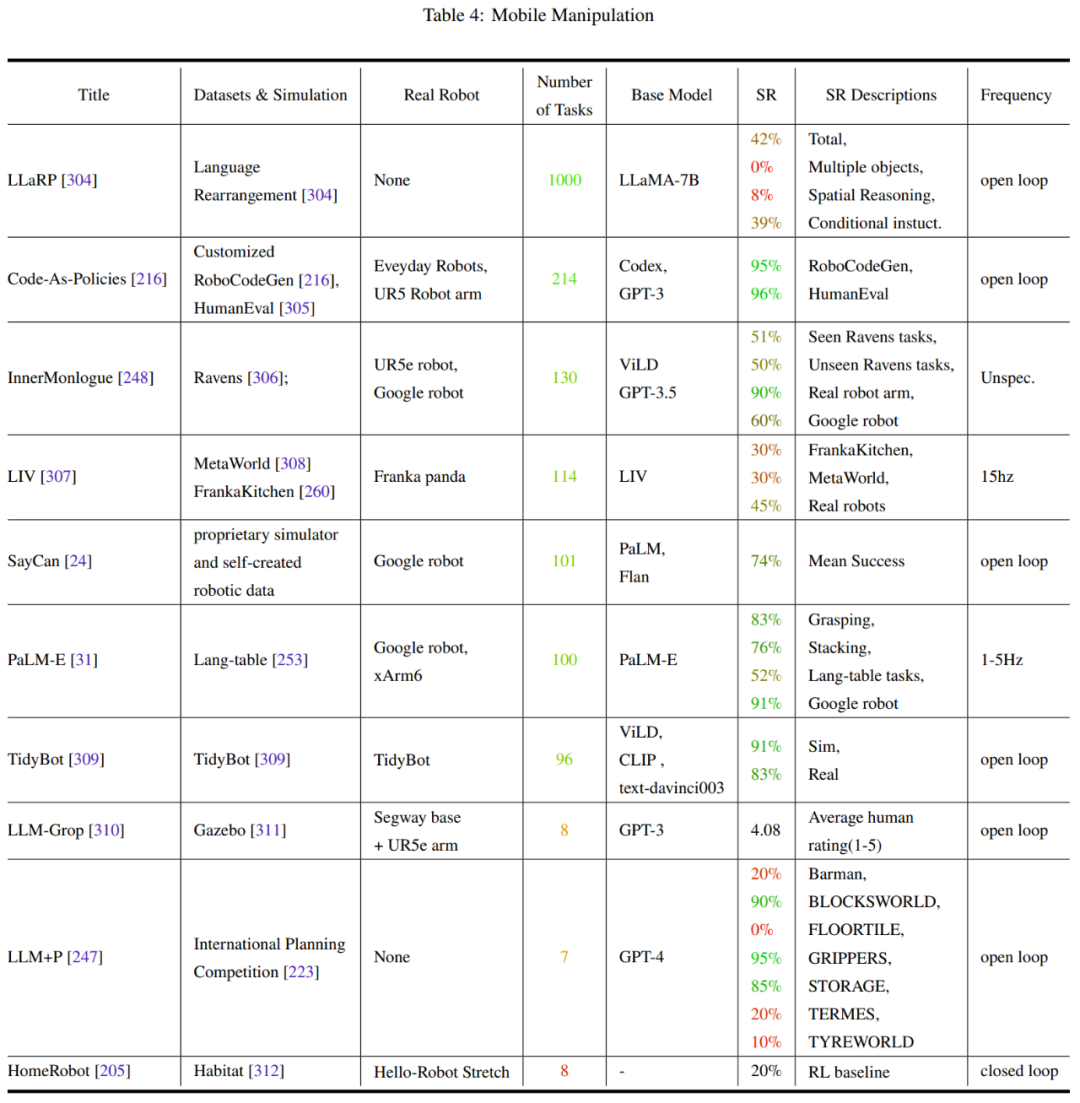
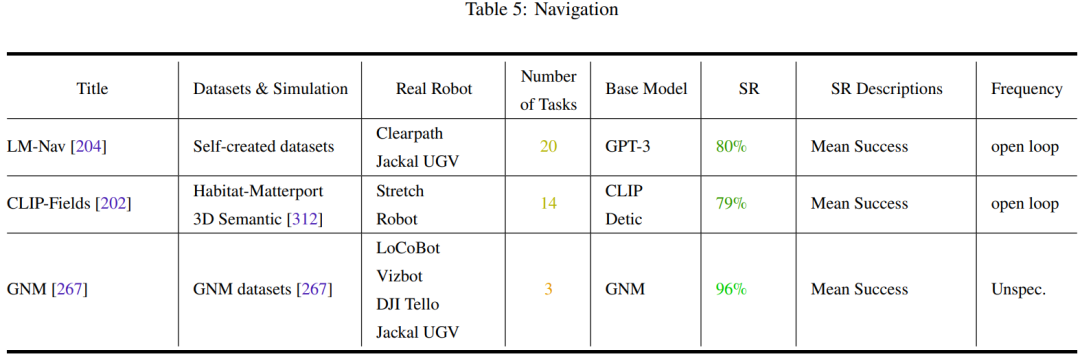

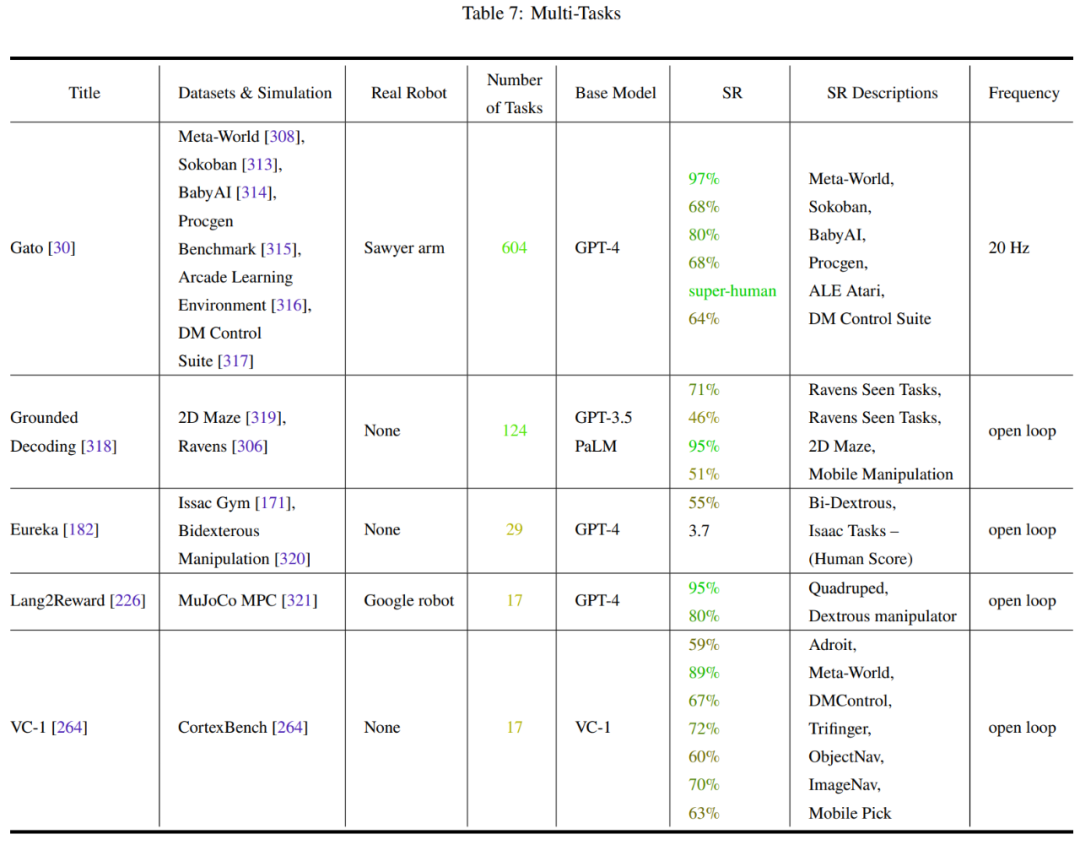
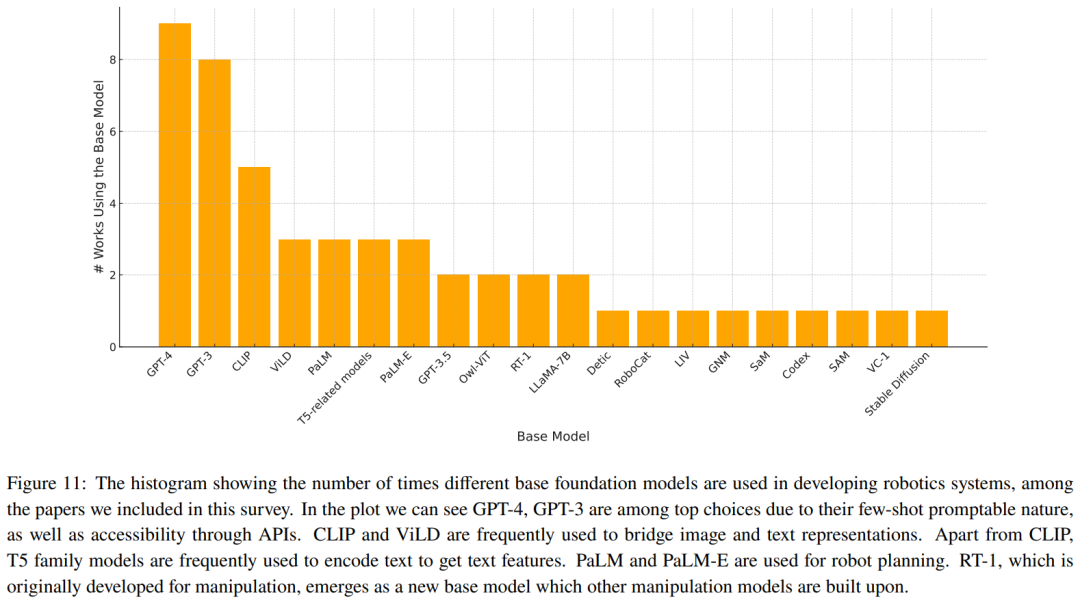
The team has summarized some key trends:
- The research community's focus on robot manipulation tasks is unbalanced.
- Generalization ability and robustness need to be improved.
- There is limited exploration of low-level actions.
- Control frequency is too low to be deployed in real robots.
- There is a lack of unified testing benchmarks.
Discussion and Future Directions
The team has summarized some unresolved challenges and research directions worth discussing:
- Establishing standard grounding for robot embodiment.
- Safety and uncertainty.
- Are end-to-end methods and modular methods incompatible?
- Adaptability to embodied physical changes.
- World model methods or model-agnostic methods?
- New robot platforms and multi-sensory information.
- Continuous learning.
- Standardization and reproducibility.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







