Article Source: Synced

Image Source: Generated by Wujie AI
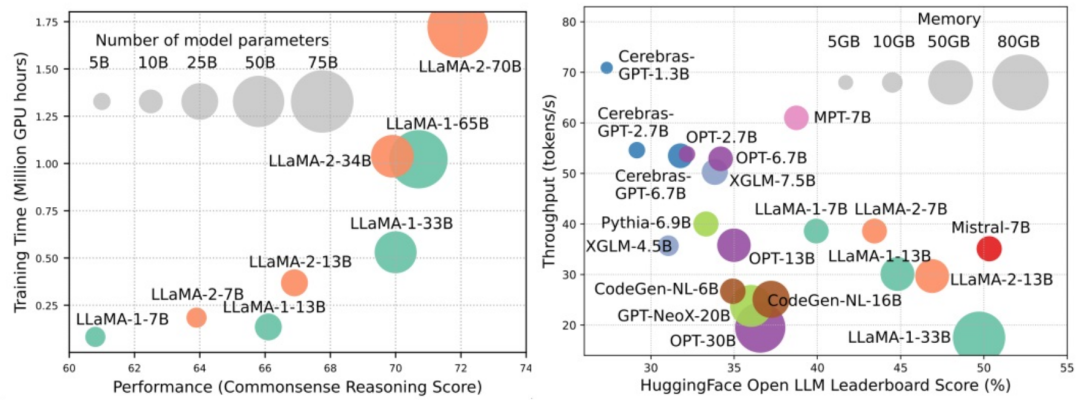
Large-scale language models (LLMs) have demonstrated significant capabilities in many critical tasks, such as natural language understanding, language generation, and complex reasoning, and have profound impacts on society. However, these outstanding capabilities come with the need for massive training resources (as shown on the left in the figure below) and longer inference latency (as shown on the right in the figure below). Therefore, researchers need to develop effective technical means to address their efficiency issues.
At the same time, as we can see from the figure on the right, recently popular efficient LLMs, such as Mistral-7B, can significantly reduce inference memory and latency while ensuring accuracy similar to LLaMA1-33B, indicating that some feasible efficient methods have been successfully applied to the design and deployment of LLMs.
In this review, researchers from The Ohio State University, Imperial College London, Michigan State University, University of Michigan, Amazon, Google, Boson AI, and Microsoft Research Asia provide a comprehensive investigation of efficient LLMs research. They categorize existing techniques for optimizing LLMs efficiency into three categories, including model-centric, data-centric, and framework-centric, and summarize and discuss the most cutting-edge related technologies.

- Paper: https://arxiv.org/abs/2312.03863
- GitHub: https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
At the same time, the researchers have established a GitHub repository to organize the papers involved in the review and will actively maintain this repository, continuously updating it as new research emerges. The researchers hope that this review can help researchers and practitioners systematically understand the research and development of efficient LLMs and inspire them to make contributions to this important and exciting field.
Repository URL: https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
Model-Centric
Model-centric methods focus on efficient techniques at the algorithmic and system levels, with the model itself as the focus. Due to the unique features of LLMs, which have tens of billions or even trillions of parameters, compared to smaller models, they require the development of new technologies to optimize the efficiency of LLMs. This paper discusses in detail five categories of model-centric methods, including model compression, efficient pre-training, efficient fine-tuning, efficient inference, and efficient model architecture design.
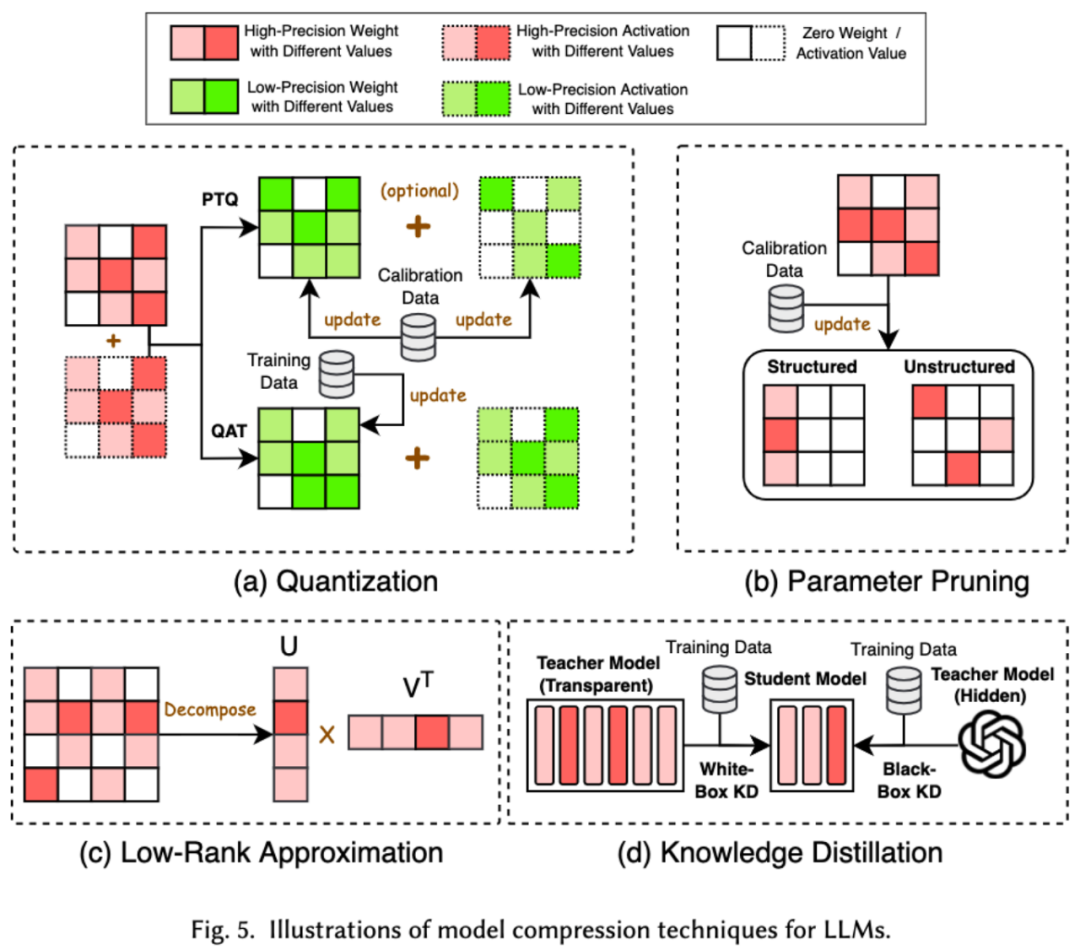
1. Model Compression
Model compression techniques are mainly divided into four categories: quantization, parameter pruning, low-rank estimation, and knowledge distillation (see the figure below), where quantization compresses the weights or activation values of the model from high precision to low precision, parameter pruning searches and removes the relatively redundant parts of the model weights, low-rank estimation transforms the weight matrix of the model into the product of several low-rank small matrices, and knowledge distillation directly trains a small model with a large model, enabling the small model to have the ability to substitute for the large model in certain tasks.
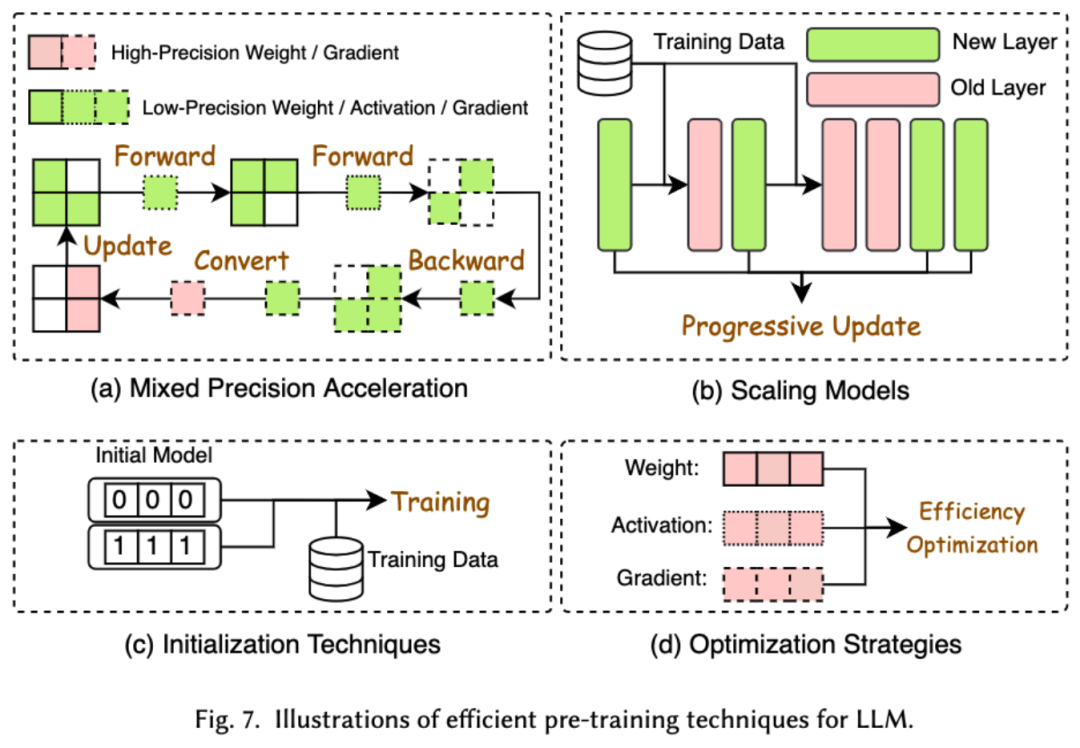
2. Efficient Pre-Training
Pre-training LLMs is very costly. Efficient pre-training aims to improve efficiency and reduce the cost of LLMs pre-training. Efficient pre-training can be further divided into mixed-precision acceleration, model scaling, initialization techniques, optimization strategies, and system-level acceleration.
Mixed-precision acceleration improves the efficiency of pre-training by using low-precision weights to calculate gradients, weights, and activation values, and then converting them back to high precision and applying them to update the original weights. Model scaling extends the parameters of a small model to a large model to accelerate pre-training convergence and reduce training costs. Initialization techniques design the initial values of the model to speed up the convergence of the model. Optimization strategies focus on designing lightweight optimizers to reduce memory consumption during model training, and system-level acceleration accelerates model pre-training from a system-level perspective using distributed technologies, among others.
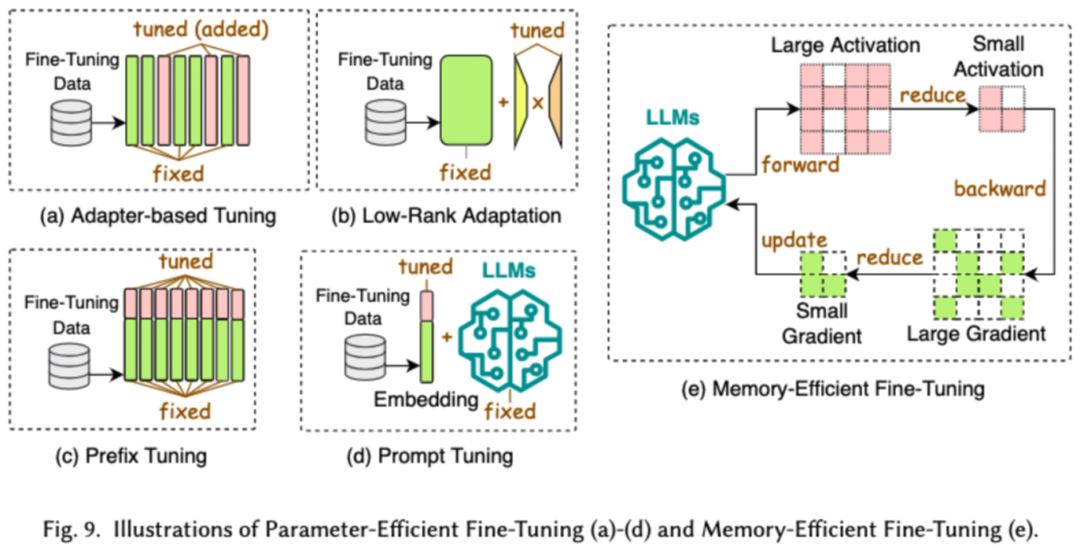
3. Efficient Fine-Tuning
Efficient fine-tuning aims to improve the efficiency of LLMs fine-tuning process. Common efficient fine-tuning techniques are divided into two categories: parameter-efficient fine-tuning and memory-efficient fine-tuning.
Parameter-efficient fine-tuning (PEFT) aims to fine-tune the LLM by freezing the entire LLM backbone and updating only a small group of additional parameters for downstream tasks. In the paper, PEFT is further detailed into adapter-based fine-tuning, low-rank adaptation, prefix fine-tuning, and prompt fine-tuning.
Memory-efficient fine-tuning focuses on reducing the memory consumption during the entire LLM fine-tuning process, such as reducing the memory consumption of optimizer states and activation values.
4. Efficient Inference
Efficient inference aims to improve the efficiency of LLMs inference process. Researchers categorize common efficient inference techniques into two major categories: algorithm-level inference acceleration and system-level inference acceleration.
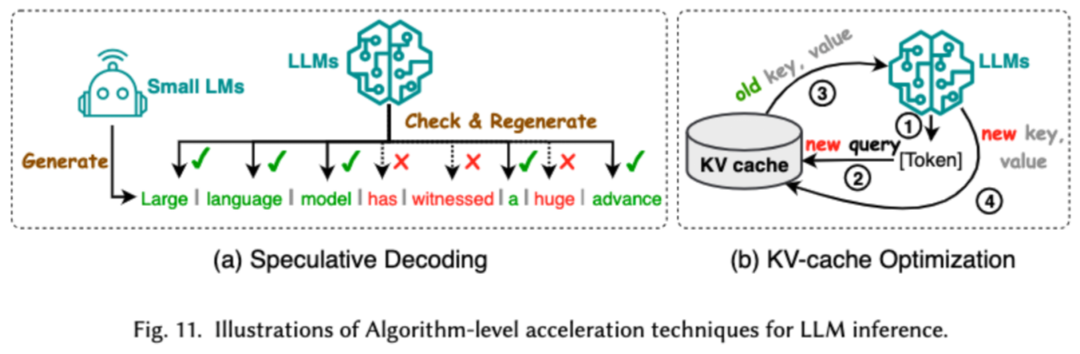
Algorithm-level inference acceleration can be further divided into speculative decoding and KV-cache optimization. Speculative decoding accelerates the sampling process by using a smaller draft model to parallelly compute tokens, creating speculative prefixes for a larger target model. KV-cache optimization optimizes the repeated calculation of Key-Value (KV) pairs during the LLMs inference process.
System-level inference acceleration optimizes memory access times on specific hardware, increases algorithm parallelism, and so on to accelerate LLM inference.
5. Efficient Model Architecture Design
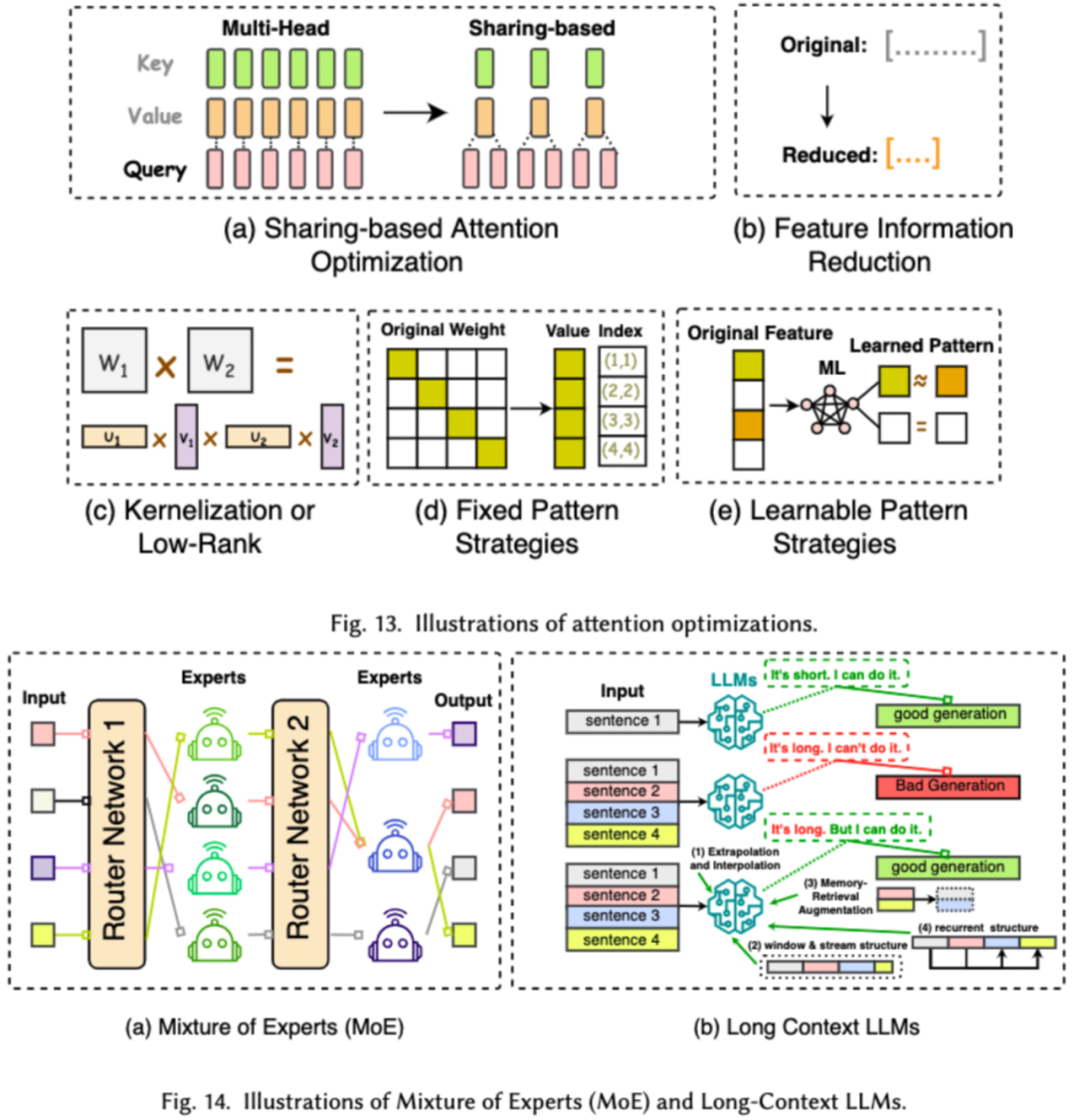
Efficient model architecture design for LLMs involves strategically optimizing model structure and computation processes to improve performance and scalability while minimizing resource consumption. Efficient model architecture design is categorized into four major types based on the type of model: efficient attention modules, mixed-expert models, large models for long text, and architectures that can replace transformers.
Efficient attention modules aim to optimize the complex calculations and memory usage in the attention modules, while the mixture of experts (MoE) replaces the inference decisions of certain modules in LLMs with multiple small expert models to achieve overall sparsity. Large models for long text are specifically designed to efficiently handle ultra-long text in LLMs, and architectures that can replace transformers aim to reduce the complexity of the model and achieve inference capabilities comparable to the transformer architecture.
Data-Centric
Data-centric methods focus on the role of data quality and structure in improving the efficiency of LLMs. In this paper, researchers discuss two data-centric methods in detail, including data selection and prompt engineering.
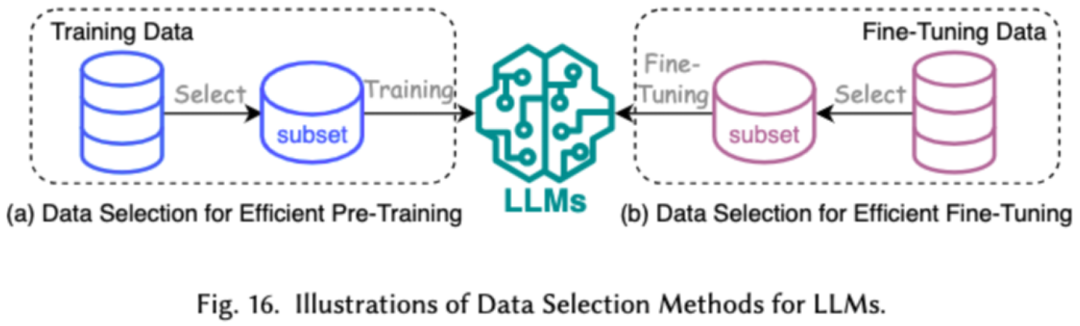
1. Data Selection
Data selection for LLMs aims to clean and select pre-training/fine-tuning data, such as removing redundant and invalid data to speed up the training process.
2. Prompt Engineering
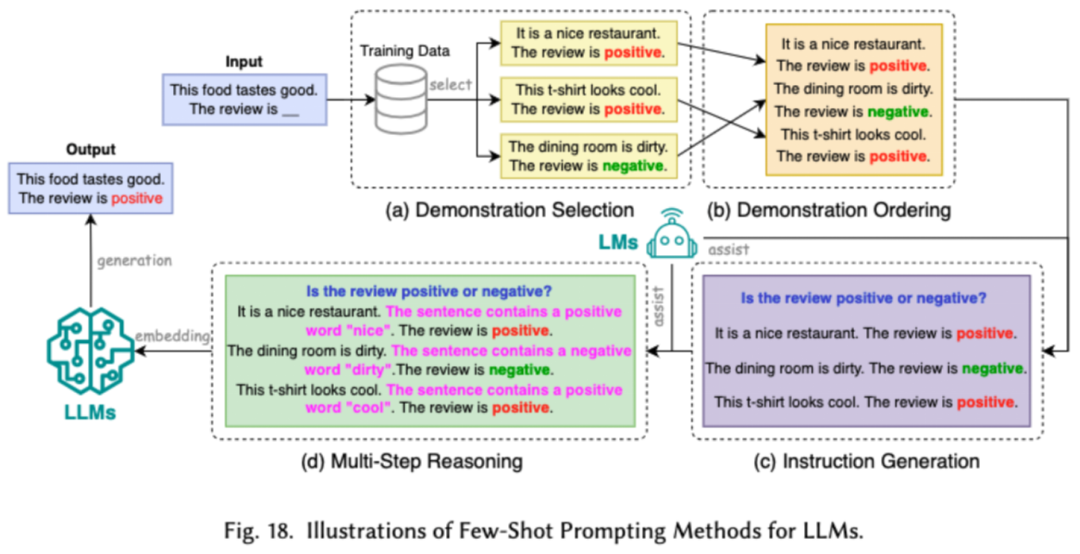
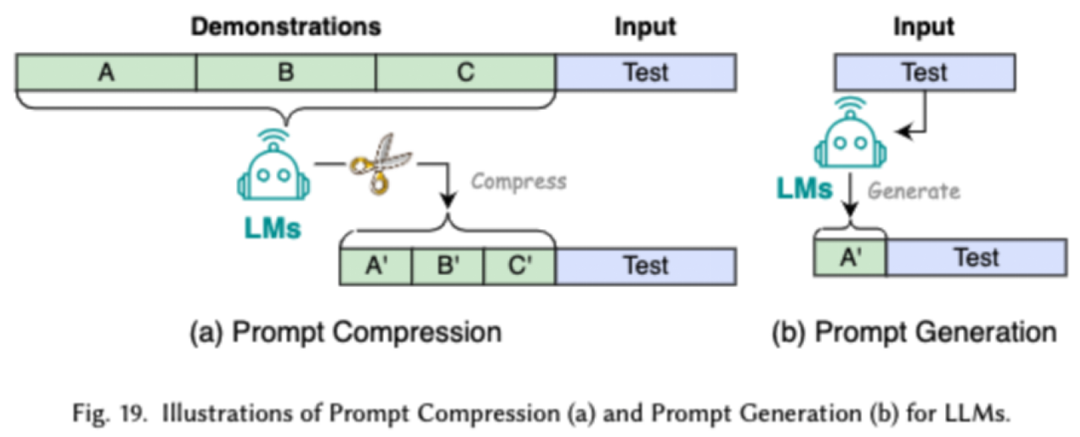
Prompt engineering guides LLMs to generate the desired output by designing effective inputs (prompts). Its efficiency lies in achieving model performance equivalent to laborious fine-tuning through prompt design. Researchers categorize common prompt engineering techniques into three major types: low-resource prompt engineering, prompt compression, and prompt generation.
Low-resource prompt engineering guides LLMs to understand the task to be performed by providing a limited set of examples. Prompt compression accelerates LLMs' processing of inputs by compressing lengthy prompt inputs or learning and using prompt representations. Prompt generation aims to automatically create effective prompts to guide the model to generate specific and relevant responses, rather than using manually annotated data.
Framework-Centric
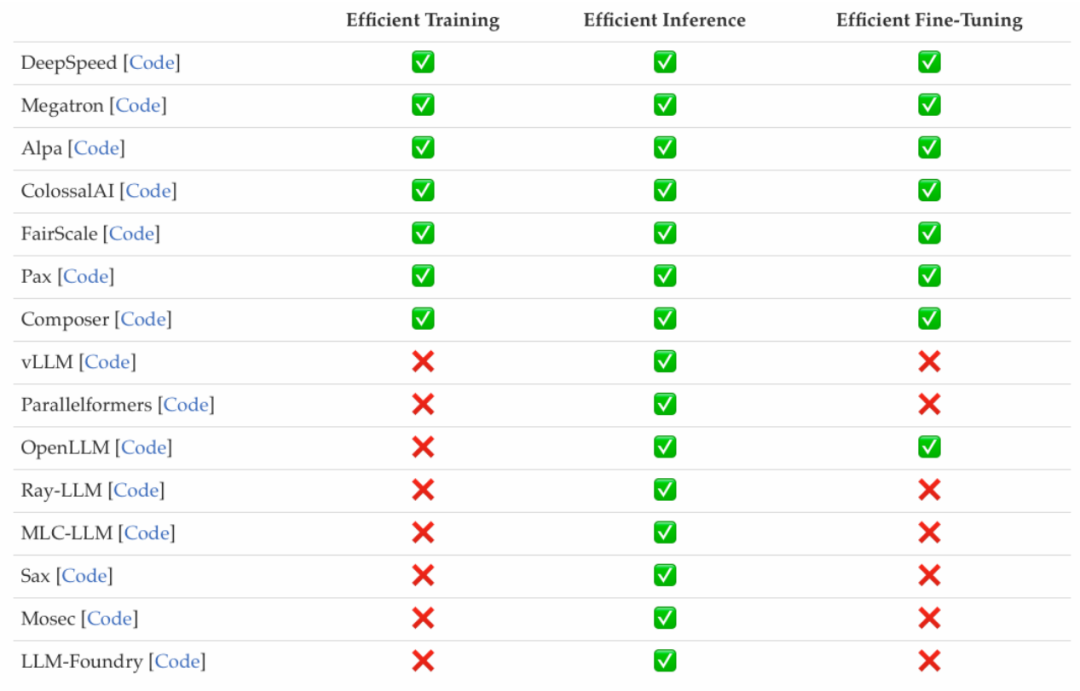
Researchers have investigated popular efficient LLMs frameworks and listed the efficient tasks they can optimize, including pre-training, fine-tuning, and inference (as shown in the figure below).
Summary
In this survey, researchers provide a systematic review of efficient LLMs, an important research area dedicated to making LLMs more democratic. They initially explain the need for efficient LLMs. In an organized framework, this paper investigates efficient techniques for LLMs from the perspectives of model-centric, data-centric, and framework-centric at both the algorithmic and system levels.
Researchers believe that efficiency will play an increasingly important role in LLMs and LLMs-oriented systems. They hope that this survey will help researchers and practitioners quickly enter this field and become a catalyst for inspiring new efficient LLMs research.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








