Source: GenAI New World
Author | You Vinegar

Image Source: Generated by Unbounded AI
From OpenAI's GPT-4V to Google's Gemini, there are fewer people forcing AI to write poetry, and multimodal large models (MLLM) have become the new favorite. A review of multimodal large models succinctly summarizes their superiority compared to LLM:
- MLLM is more in line with the way humans perceive the world. Humans naturally accept multisensory inputs, which are often complementary and cooperative. Therefore, multimodal information is expected to make MLLM more intelligent;
- MLLM provides a more user-friendly interface. Thanks to the support of multimodal inputs, users can interact and communicate with intelligent assistants in a more flexible way;
- MLLM is a more comprehensive task solver. While LLMs can usually perform NLP tasks, MLLMs can typically support a wider range of tasks.
So compared to pure coding ability, people are more looking forward to AI directly turning a mathematical formula on a whiteboard into code, dismantling a complex circuit diagram and turning it into an assembly instruction, or even providing commentary for a segment of football video.
Recently, the Smart Source Research Institute released a new generation of multimodal basic model—Emu2.
In the words of Lin Yonghua, the chief engineer of the Smart Source Artificial Intelligence Research Institute, this eye-catching open-source project is the "annual finale" of the Smart Source Visual Large Model team.
In August of this year, the Smart Source Research Institute proposed a new training paradigm for multimodal large models, and released and open-sourced the first unified multimodal pre-training model Emu that bridges from multimodal input to multimodal output. Four months after the release of Emu, it accumulated 720 stars on GitHub, and the recent release of Emu2 garnered 300 stars in less than a week. The current star rating for this project has already exceeded a thousand.
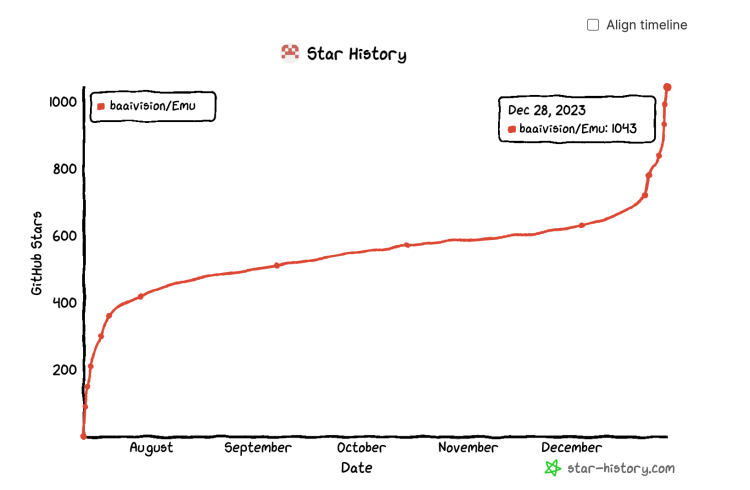
Image Source: GitHub
Compared to the first generation "multimodal to multimodal" Emu model released in July 2023 (open-sourced in August), Emu2 uses a simpler modeling framework, trains a decoder that reconstructs images from the semantic space of the encoder, and scales the model to 37 billion parameters to achieve breakthroughs in model capabilities and universality.
It is worth mentioning that Emu2 is currently the largest open-source generative multimodal model.
It continues to use a large number of sequences of images, text, and videos on a large scale for unified autoregressive target training, directly interleaving token sequences of modalities such as images and videos with text token sequences for training. In terms of model performance, Emu2 demonstrates strong multimodal contextual learning capabilities, and can even handle tasks requiring real-time reasoning, such as visual prompts and object-based generation. In a few-shot setting, Emu2 has set new records in multiple multimodal understanding tasks.
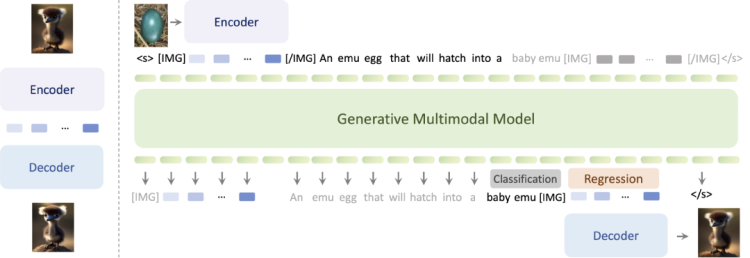
Image Source: Smart Source Research Institute
The test results from the Smart Source Research Institute show that Emu2 significantly outperforms mainstream multimodal pre-training large models such as Flamingo-80B and IDEFICS-80B in tasks including VQAv2, OKVQA, MSVD, MM-Vet, and TouchStone in various few-shot understanding, visual question answering, and subject-driven image generation tasks.
When adjusted according to specific instructions, Emu2 has further achieved new optimal states in challenging tasks such as question answering benchmarks for large multimodal models and open-topic-driven generation.
Based on the fine-tuning of Emu2, the Emu2-Chat and Emu2-Gen models are currently the most powerful open-source visual understanding model and the most versatile visual generation model. Emu2-Chat can accurately understand image-text instructions, achieving better information perception, intent understanding, and decision planning. Emu2-Gen can accept mixed sequences of images, text, and positions as input, achieving flexible, controllable, and high-quality image and video generation.
These achievements demonstrate that Emu2 can serve a wide range of multimodal tasks as a basic model and a universal interface. The code and models are now open-source and available for demo use.
Strong Understanding and Generation Capabilities
Through quantitative evaluation of its multimodal understanding and generation capabilities, Emu2 has achieved optimal performance in multiple tasks including few-shot understanding, visual question answering, and subject-driven image generation. In few-shot evaluations, Emu2 significantly outperforms Flamingo-80B in various scenarios, such as exceeding Flamingo-80B by 12.7 points in 16-shot TextVQA.
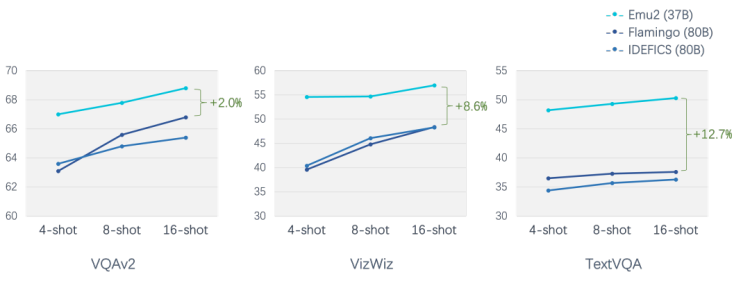
Image Source: Smart Source Research Institute
Emu2, fine-tuned according to instructions, can freely answer questions about image and video inputs, achieving optimal performance on more than ten image and video question answering evaluation sets such as VQAv2, OKVQA, MSVD, MM-Vet, and TouchStone.
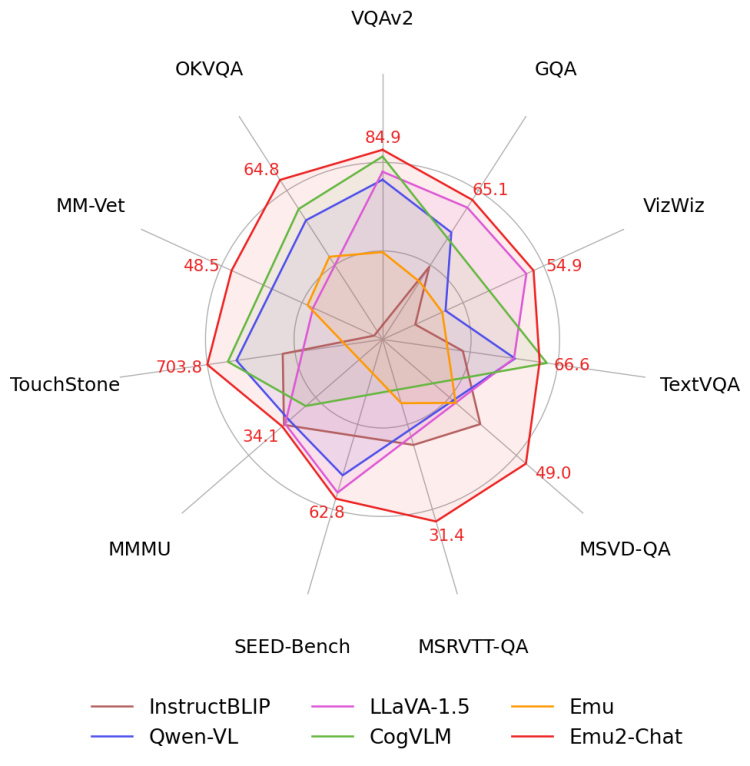
Image Source: Smart Source Research Institute
In the zero-shot DreamBench subject-driven image generation test, Emu2 has significantly improved compared to previous methods, achieving images that are visually closer to reality, as well as greater diversity and creativity in subject and style. For example, it outperforms Salesforce's BLIP-Diffusion's CLIP-I score by 7.1% and Microsoft's Kosmos-G's DINO score by 7.2%.
DreamBench is a benchmark test for evaluating text-to-image generation models, which includes various types of image editing tasks such as recontextualization, stylization, modification, region-controllable generation, and multi-entity composition.
Emu2-Gen demonstrates its multimodal generation capabilities in a zero-shot setting on DreamBench. It can accept mixed inputs of text, position, and images, and generate images in context. Emu2-Gen's performance on DreamBench demonstrates its superior performance in multimodal generation tasks, such as its ability to faithfully reconstruct subjects based on a single image input and demonstrate excellent subject fidelity in a zero-shot setting through powerful visual decoding capabilities.
Subject fidelity is an indicator that measures the accuracy of a generated image model in maintaining the fidelity of subject features in the input image. In image editing or generation tasks, if a model can accurately retain or reproduce subject elements such as people, animals, objects, etc., from the input image, it can be considered to have high subject fidelity.
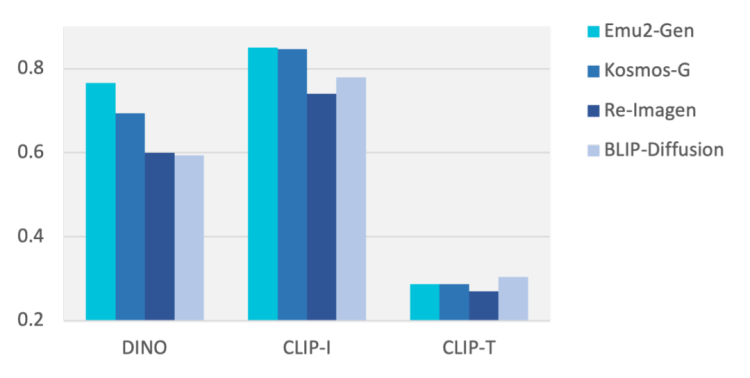
Image Source: Smart Source Research Institute
Multimodal Contextual Learning
Contextual learning ability is one of the important abilities that emerged with LLM, and when we talk about multimodal large models, ICL has also expanded to multimodal ICL (M-ICL).
After completing generative pre-training, Emu2 possesses comprehensive and powerful multimodal contextual learning abilities. Several examples are presented in the paper about Emu2, showing that the model can complete corresponding understanding and generation tasks with precision. For example, describing images in context, understanding visual prompts in context (covering a red circle on an image), generating images with similar styles in context, and generating images corresponding to subjects in context.
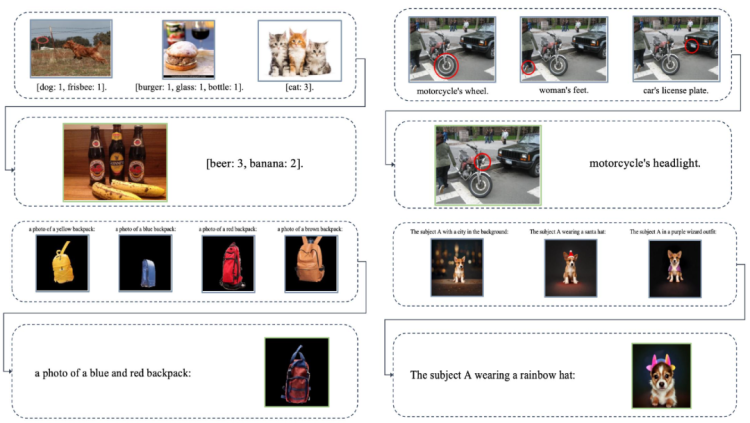
App Agent looks great
It is worth mentioning that during the training process, Emu2 used diverse datasets, including image-text pairs, video-text pairs, and interleaved image-text data. The diversity of this data helps the model learn a broader range of multimodal representations and improves its adaptability to different tasks. By using average pooling to segment images into small blocks and interleaving them with text tokens, Emu2's model structure is simplified and efficiency is improved.
Powerful Image Captioning Ability
Now let's talk about Emu2-Chat.
The design goal of Emu2-Chat is to be an intelligent agent capable of multimodal dialogue, and it is currently the most familiar form of multimodal large model that we can understand. After fine-tuning with conversational data instructions, Emu2-Chat can accurately understand image-text instructions and perform better in multimodal understanding tasks.
For example, it can distinguish polygons:

Image Source: Smart Source Research Institute
Read airport guidance:

Image Source: Smart Source Research Institute
And even evaluate the severity of a car accident:

Image Source: Smart Source Research Institute
Surprises in Image Generation with Emu2-Gen
After fine-tuning with high-quality images, Emu2-Gen can accept mixed sequences of images, text, and positions as input, generating corresponding high-quality images, providing flexibility and controllability. For example, generating a bear and sunflower at specified positions and subjects:

Image Source: Smart Source Research Institute
Generating a group photo of a pet dog and a kiwi at specified positions, subjects, and styles:

Image Source: Smart Source Research Institute
More examples of generation based on image-text sequences:

Image Source: Smart Source Research Institute
Even Video Generation is Possible
Furthermore, Emu2 supports video generation based on arbitrary prompt sequences.
Specifically, Emu2 generates videos by training a video decoder based on a diffusion model. This decoder is trained within a diffusion model framework, and it can decode the continuous vector representation obtained by the visual encoder processing images into a sequence of video frames. This training method allows the model to learn how to transform visual information into continuous video frames without relying on a language model.
Based on sequences of text, image-text interleaving, and image-text position interleaving, Emu2 can generate corresponding high-quality videos.

Image Source: Smart Source Research Institute
How do AI enthusiasts feel about this New Year's gift?
*Reference:
Generative Multimodal Models are In-Context Learnershttps ,arxiv.org/abs/2312.13286
"Emu2: A New Generation of Generative Multimodal Models," Smart Source Research Institute
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







