Source: Machine Power

Image source: Generated by Wujie AI
Another sleepless night, the gods are showing off their skills.
On December 6th local time, Google CEO Sundar Pichai officially announced the launch of Gemini 1.0. Prior to this, the release of this weapon that Google had high hopes for in the fight against OpenAI had been delayed.
Never expected it to come so unexpectedly.
Demis Hassabis, the head of development and CEO of Google DeepMind, officially introduced the large model Gemini at the press conference. It has "vision" and "hearing," as well as learning and reasoning abilities.
As Google's most powerful and comprehensive model to date, Gemini's performance surpasses GPT-4 in most benchmark tests.

Hassabis referred to Gemini as a "new species of AI" in an interview with Wired magazine before the press conference.
Currently, most models are trained in separate modules and then spliced together to approximate multimodal capabilities, but they are unable to perform deep and complex reasoning in multimodal spaces.
One of Gemini's major highlights is its native multimodal large model—designed to natively support multimodal capabilities, handling different forms of data (language + auditory + visual); it is pre-trained on different modalities from the beginning and fine-tuned using additional multimodal data to enhance effectiveness.
Therefore, Gemini can generalize and seamlessly understand, manipulate, and combine different types of information, including text, code, audio, images, and videos, far surpassing existing (approximate) multimodal models, and its capabilities are the strongest in almost every field.
Hassabis revealed that Google DeepMind is already researching how to integrate Gemini with robotics technology for physical interaction with the world. After all, to truly be multimodal, it also needs touch and tactile feedback.
This uncharted path may bring significant breakthroughs in the future. He told Wired magazine that the new multimodal model will become the foundation for rapid innovation in intelligent agents, planning and reasoning, games, and even physical robots.
In addition to the native multimodal highlight, Google stated that Gemini is their most flexible model to date, capable of efficiently running on various platforms such as data centers and mobile devices.
Gemini includes three levels of capability: the most powerful Gemini Ultra, the multitasking Gemini Pro, and the task-specific and edge-side Gemini Nano.

Currently, Gemini offers three different versions.
In particular, Gemini Nano can run on terminal devices with special chips, rather than on certain servers in the cloud, allowing Google to bring AI generation to Android phones around the world.
Using the generated AI model without a network connection will also make users feel secure, as their personal data will not leave their devices. This has been the direction of Apple's privacy practices for many years.

Pixel 8 Pro uses Gemini Nano in the voice recorder app to summarize meeting audio, even without a network connection.
It is said that the Pixel 8 Pro will be the first smartphone to run Gemini Nano. Although Google has integrated it with the Pixel 8 Pro's operating system, it has not yet fully integrated all its functions into Google Assistant.
Sissie Hsiao, Vice President and General Manager of Bard and Assistant at Google, said at the press conference that the current integration is undergoing "early testing."
At this point, we can almost smell the future battle between Google and Apple in the terminal.
In the coming months, Google's chatbot Bard will receive a major upgrade—using a fine-tuned version of Gemini Pro to perform more advanced reasoning, planning, understanding, and other tasks. In the near future, Bard will also expand to more modalities and support more languages.
The company stated that Gemini will be introduced into other Google products in the coming months, including generated search, advertising, and Chrome.
The security testing work for the most powerful Ultra version is still ongoing and is scheduled to be launched next year. It scored 90% in large-scale multitask language understanding (MMLU) benchmark tests, higher than any other competitor, including GPT-4.
However, Google has not completely stolen the spotlight of artificial intelligence. Meta and AMD have coincidentally had new releases.
To avoid being surpassed, virtual assistant Meta AI also had a significant update last night.
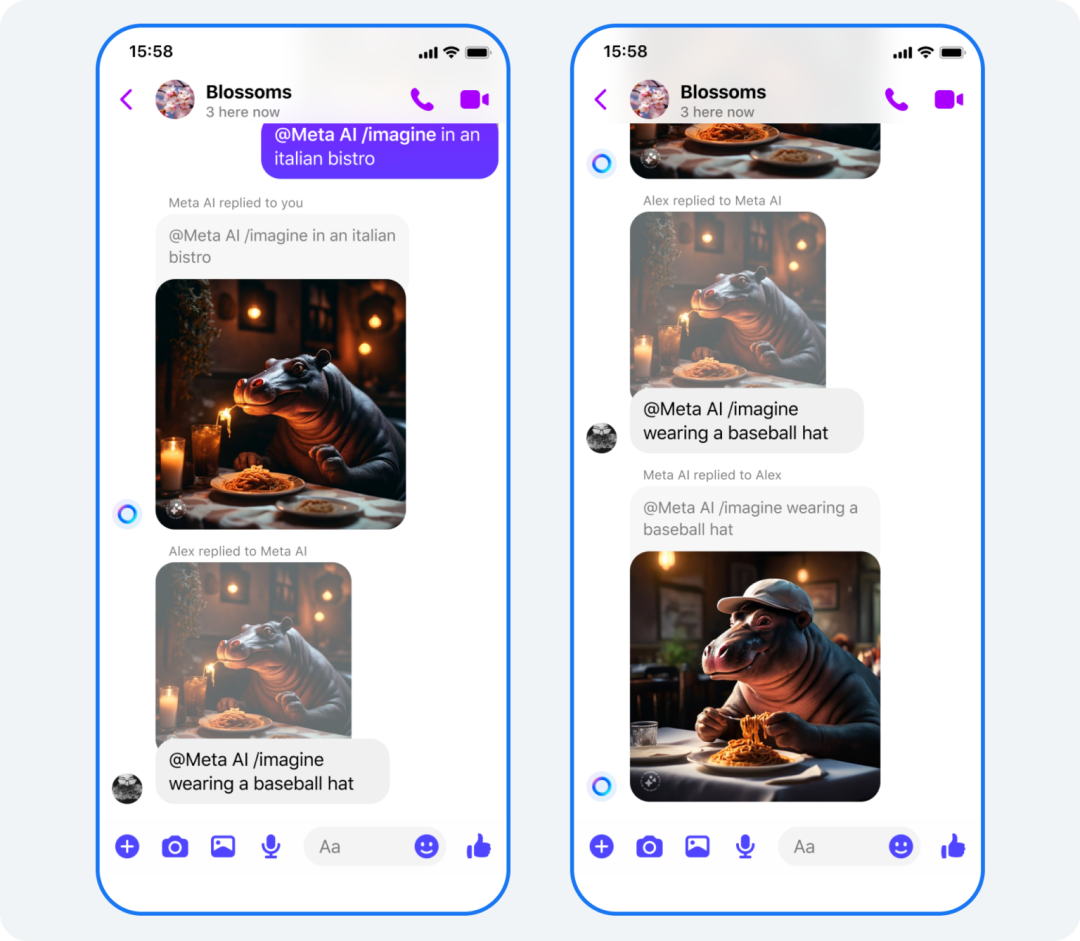
One of the most commonly used features, Imagine—text-to-image generation, now has a new "reimagine" capability, taking chat battles to new heights:
Using Imagine to generate an image, your chat partner can hold down the image and make modifications through simple text prompts, and the new feature will generate a new image. Netizens can continuously modify the image like a chain reaction, creating hilarious results.
Meta also launched a free web tool, Imagine with Meta AI—an online AI image generator (https://imagine.meta.com/), capable of creating high-resolution AI images in seconds. It is trained using public Facebook data.
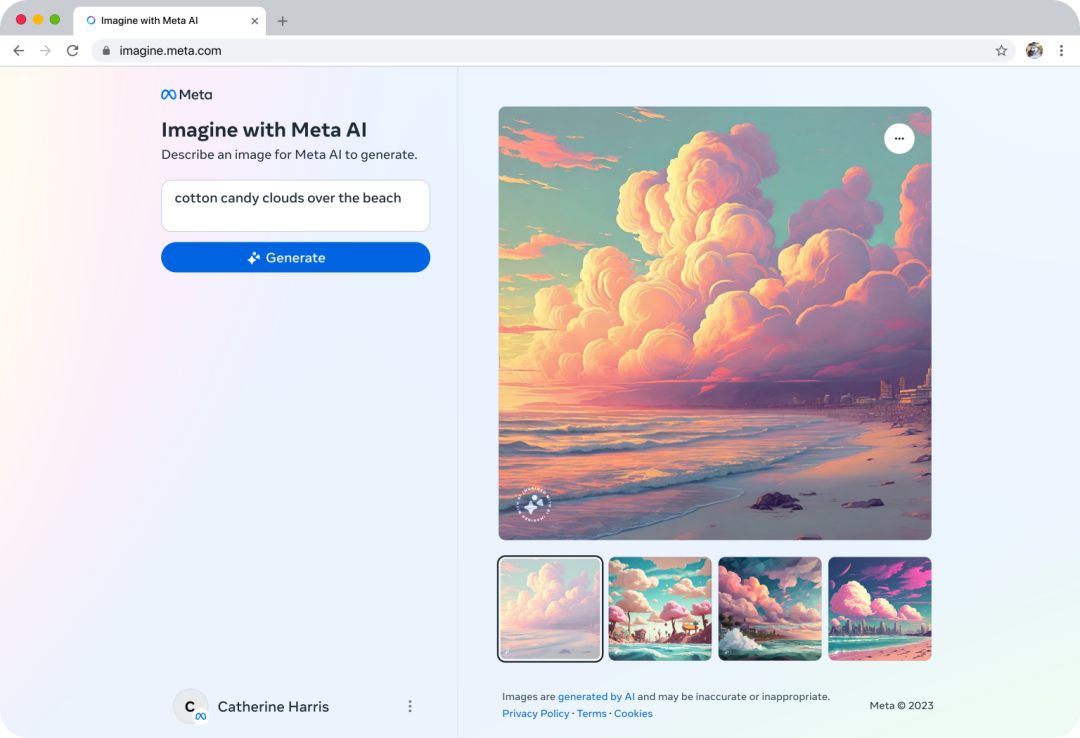
Each time it is used, the generator creates four 1280×1280 pixel images, which can be saved in JPEG format, with a small "Imagined with AI" watermark in the lower left corner of the image.
Screenshot by Lance Whitney via Imagine/ZDNET

Work from arstechnica
In addition to the image generation function, Meta AI's text generation capabilities have also been enhanced. For example, it can help with writing birthday wishes, posts, and even self-introductions for dating profiles.
Meta AI has also launched the Reels feature. If you are planning a trip with friends in a group chat, you can ask Meta AI to recommend the best tourist destinations and share popular attractions, helping to decide which ones are must-visit.
Now it can also help convert images from landscape to portrait, making it easier to share in text.
On the other side of the coin in the competition of large models is the intense competition for the most powerful computing power among various companies.
At the conference, alongside Gemini 1.0, Google also unveiled its most powerful, efficient, and scalable TPU system to date—Cloud TPU v5p, designed for training cutting-edge AI models, capable of training large models faster than TPU v4.
Google stated that TPU is crucial for its research and engineering work on cutting-edge models like Gemini.
Also last night, AMD's "most powerful computing power" chip, the pure GPU product Instinct MI300X accelerator designed for AIGC and large model scenarios, made a grand appearance.
AMD stated that compared to the Nvidia H100 HGX, the Instinct MI300X accelerator has significantly higher throughput and lower latency when running large language model inferences.
AMD MI300X AI Accelerator
AMD CEO Lisa Su expects the AI chip market to reach $400 billion or more by 2027, and hopes that AMD can capture a significant share of that market.
AMD has signed contracts with some of the biggest buyers of GPUs, including Meta and Microsoft in 2023 for the Nvidia H100 GPU.
Meta stated that it will use the MI300X GPU to handle AI inference workloads, such as processing AI stickers, image editing, and AI assistants.
Microsoft's Chief Technology Officer Kevin Scott stated that the company will provide access to the MI300X chip through Azure.
Oracle's cloud services will also use these chips. OpenAI stated that the GPU programming language Triton developed by the company will support AMD chips such as MI300 starting from the upcoming 3.0 version.
Reference links:
https://about.fb.com/news/2023/12/meta-ai-updates/
https://www.wired.com/story/google-deepmind-demis-hassabis-gemini-ai/
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







