Source: AIGC Open Community

Image Source: Generated by Wujie AI
With the rapid development of generative models, a large number of outstanding text-to-image models such as Midjourney, DALL·E 3, and Stable Difusion have emerged. However, progress in the field of text-to-video generation has been slow, as most text-to-video methods generate frames sequentially, leading to low computational efficiency and high costs.
Even with the new method of generating keyframes first and then generating intermediate frames, there are still many technical challenges in interpolating frames to ensure the coherence of the generated video.
Meta, a technology and social media giant, has proposed a new text-to-video generation model called Emu Video. This model uses a decomposed generation method, first generating an image, and then using this image and text as conditions to generate the video, resulting in not only realistic videos that match the text description, but also significantly lower computational costs.
Paper: https://emu-video.metademolab.com/assets/emu_video.pdf
Online demo: https://emu-video.metademolab.com/#/demo
The core technological innovation of Emu Video lies in the use of a decomposed generation method. Previously, other text-to-video models directly mapped from text descriptions to high-dimensional video space.
However, due to the high dimensionality of video, direct mapping is extremely difficult. Emu Video's strategy is to first generate an image, and then use this image and text as conditions to generate subsequent video frames.
As the dimensionality of the image space is lower, generating the first frame is easier, and predicting how the image changes for the subsequent frames significantly reduces the overall task difficulty.

In terms of the technical process, Emu Video uses a pre-trained text-to-image model to fix spatial parameters and initialize the video model.
Then, only the training time parameters are needed to perform the text-to-video task. During training, the model learns from video segments and their corresponding text descriptions as samples.

During inference, given a piece of text, the model first uses the text-to-image part to generate the first image, and then inputs this image and text into the video part to generate the complete video.
Text-to-Image
Emu Video uses a well-trained text-to-image model that can generate highly realistic images. To make the generated images more creative, this model is pre-trained on a massive amount of images and text descriptions, learning various styles of images, such as punk, sketch, oil painting, and color painting.

The text-to-image model adopts a U-Net structure, which includes an encoder and a decoder. The encoder consists of multiple convolutional blocks and downsamples to obtain lower-resolution feature maps.
The decoder consists of symmetrical upsampling and convolutional layers, ultimately outputting the image. Two text encoders (T5 and CLIP models) are parallelly incorporated to encode the text and produce text features.
Image-to-Video
This module uses a structure similar to the text-to-image module, also employing an encoder-decoder structure. The difference lies in the addition of a module that handles temporal information, meaning it can learn how to transform the content of an image into a video.
During training, researchers input a short video segment, randomly extract a frame from it, and let this module learn to generate the entire video based on this image and its corresponding text.
In practical use, the first module is used to generate the first image, and then this image and text are input into the second module to generate the entire video.

This decomposed method simplifies the task of the second module, as it only needs to predict how the image changes and moves over time to generate a smooth and realistic video.
To generate higher-quality and more realistic videos, researchers have made some technical optimizations: 1) adopting a zero-terminal signal-to-noise ratio divergence noise plan, which can directly generate high-definition videos without the need for cascading multiple models. Previous plans had biases in signal-to-noise ratio during training and testing, leading to decreased generation quality.
2) Utilizing pre-trained text-to-image model to fix parameters, preserving image quality and diversity, and eliminating the need for additional training data and computational costs when generating the first frame.
3) Designing a multi-stage training strategy, first training on low-resolution to quickly sample video information, and then fine-tuning on high-resolution to avoid the high computational cost of full-resolution computation.
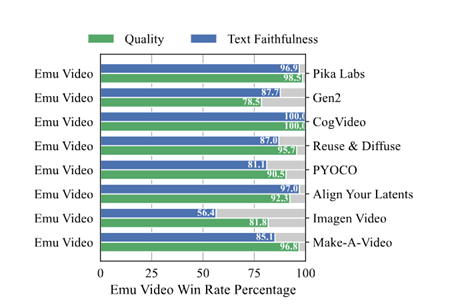
Human evaluations have shown that the 4-second videos generated by Emu Video exhibit higher quality and better adherence to text requirements compared to other methods. Semantic consistency exceeds 86%, and quality consistency exceeds 91%, significantly surpassing well-known commercial models such as Gen-2, Pika Labs, and Make-A Video.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







