Source: Quantum Bit

Image Source: Generated by Wujie AI
The graphic reasoning ability of GPT-4 is actually less than half of that of humans?
A study from the Santa Fe Institute in the United States shows that the accuracy of GPT-4 in graphic reasoning questions is only 33%.
And the multimodal GPT-4v performs even worse, only getting 25% of the questions right.
After the publication of these experimental results, it quickly sparked widespread discussions on YC.
Netizens who agree with these results say that GPT is indeed not good at abstract graphic processing, and concepts like "position" and "rotation" are more difficult to understand.

However, many netizens also have doubts about this conclusion, simply saying:
It can't be said to be wrong, but it's also not entirely convincing to say it's completely correct.

As for the specific reasons, let's continue reading.
GPT-4 accuracy is only 33%
To evaluate the performance of humans and GPT-4 in these graphic questions, researchers used the ConceptARC dataset released by their own institution in May of this year.
ConceptARC includes a total of 16 subclasses of graphic reasoning questions, with 30 questions in each class, for a total of 480 questions.

These 16 subclasses cover various aspects such as spatial relationships, shapes, operations, and comparisons.
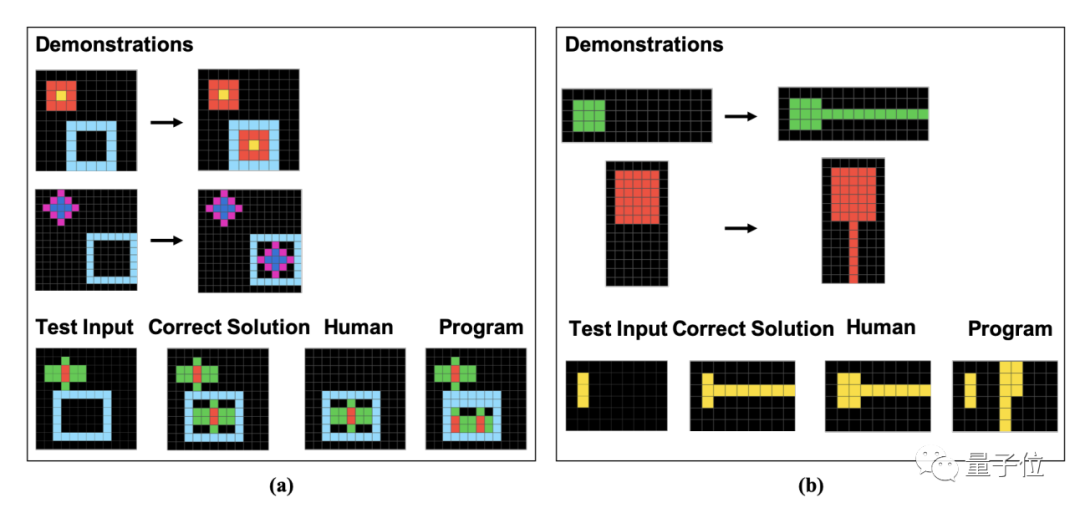
Specifically, these questions are composed of individual pixel blocks, and humans and GPT need to find the rules based on the given examples, and analyze the results of the images after they have been processed in the same way.
The authors specifically presented one question from each of these 16 subclasses in the paper.



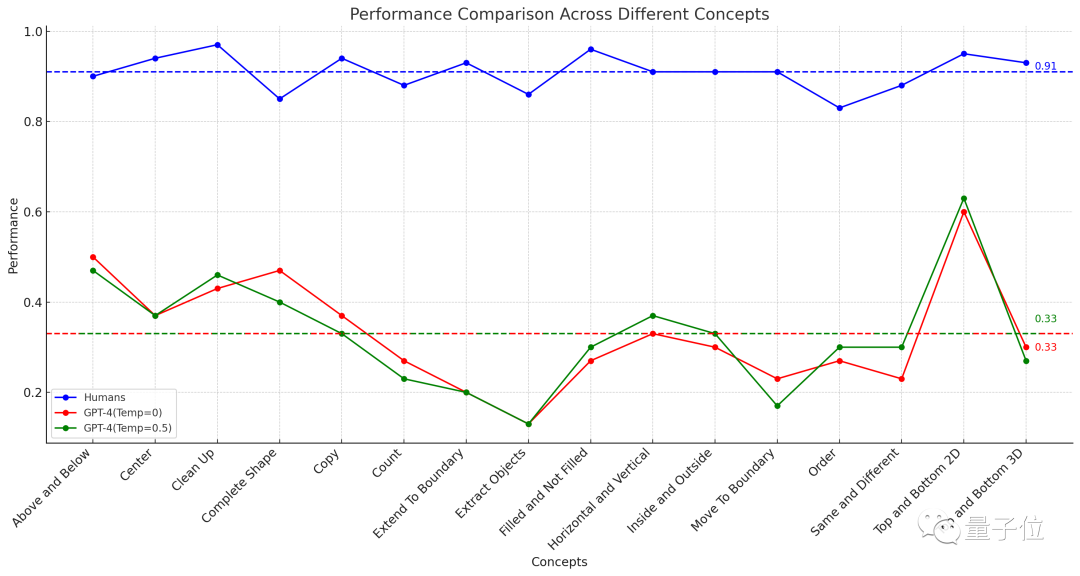
The average accuracy of 451 human subjects in each subclass is no less than 83%, and the average accuracy for the 16 tasks is 91%.
In contrast, GPT-4 (single sample) can only achieve an accuracy of no more than 60% when given three chances to answer a question (getting one correct answer counts as correct), with an average accuracy of only 33%.
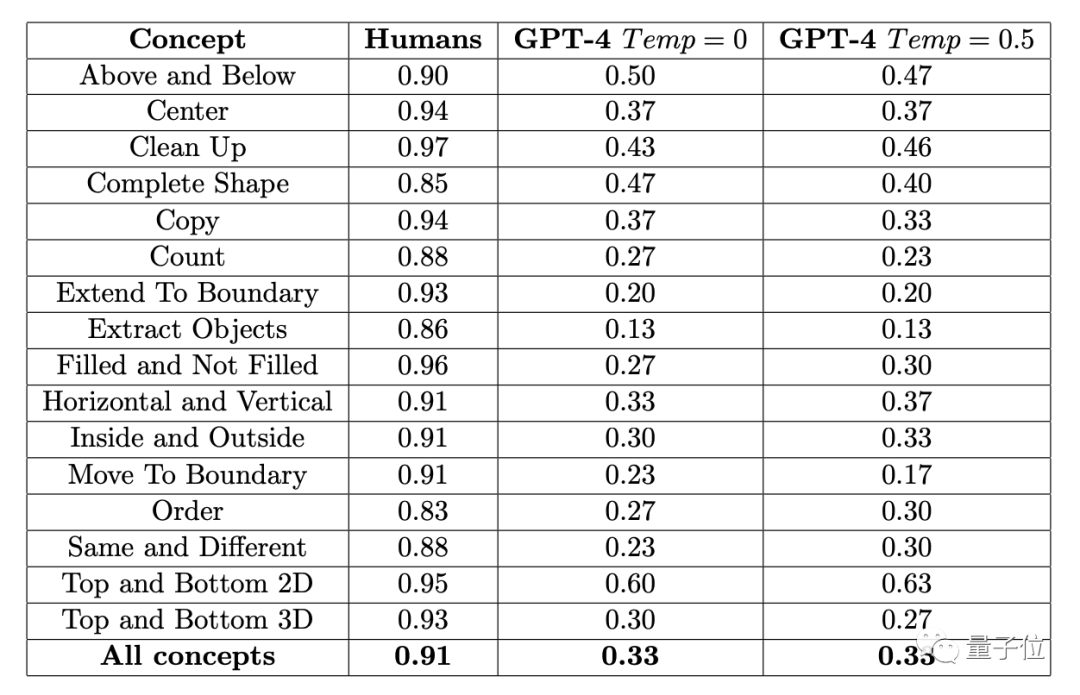
Earlier, the authors of the ConceptARC Benchmark, which was involved in this experiment, also conducted a similar experiment, but the zero-shot testing in GPT-4 resulted in an average accuracy of only 19% for the 16 tasks.
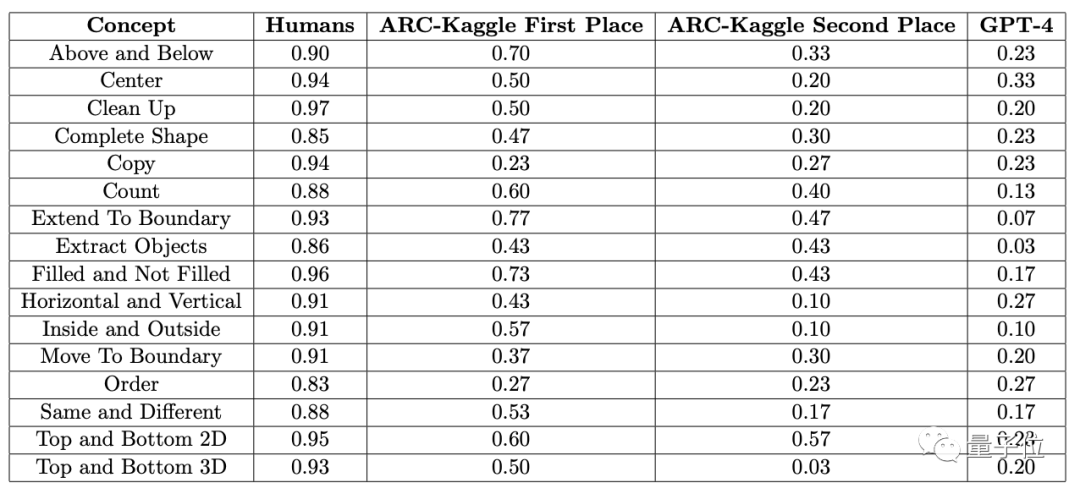
On the other hand, the multimodal GPT-4v has even lower accuracy, with zero-shot and single-sample testing achieving accuracies of only 25% and 23% respectively in a small-scale ConceptARC dataset consisting of 48 questions.

Furthermore, after further analyzing the incorrect answers, the researchers found that some of the human errors seemed likely to be due to "carelessness," while GPT simply did not understand the rules in the questions.
Regarding this data, there is generally no doubt among netizens. However, what has caused this experiment to be widely questioned is the recruited subjects and the input method given to GPT.
Questioning the method of subject selection
Initially, the researchers recruited subjects on a crowdsourcing platform on Amazon.
The researchers extracted some simple questions from the dataset as an entry test, and the subjects needed to answer at least two out of three random questions correctly to enter the formal test.
As a result, the researchers found that some people were just trying to get money and did not follow the requirements at all.
As a last resort, the researchers raised the threshold for participating in the test to having completed no fewer than 2000 tasks on the platform and achieving a pass rate of 99%.
However, although the authors used the pass rate to screen people, in terms of specific abilities, besides requiring subjects to know English, there were "no special requirements" for other professional abilities such as graphics.
In order to diversify the data, the researchers later transferred the recruitment work to another crowdsourcing platform, and a total of 415 subjects participated in the experiment.
Nevertheless, some people still question that the samples in the experiment are not random enough.

Some netizens also pointed out that on the Amazon crowdsourcing platform used by the researchers to recruit subjects, there are large models impersonating humans.
Looking at the operation on the GPT side, the multimodal version is relatively simple, just upload the image and use prompts like this:
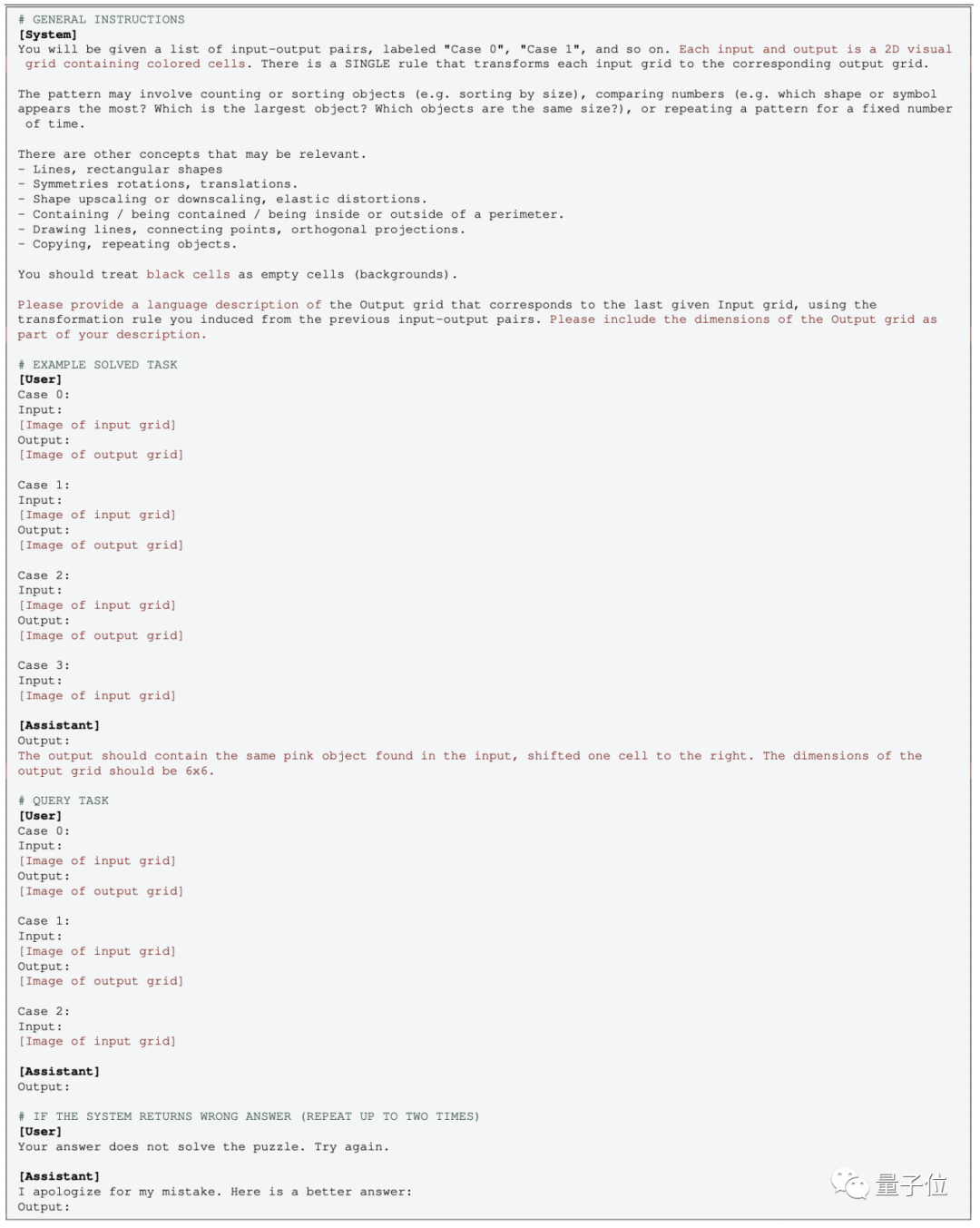
In zero-shot testing, you just need to remove the corresponding EXAMPLE section.
But for the pure text version of GPT-4 (0613) without multimodality, the image needs to be converted into a grid, with numbers replacing colors.
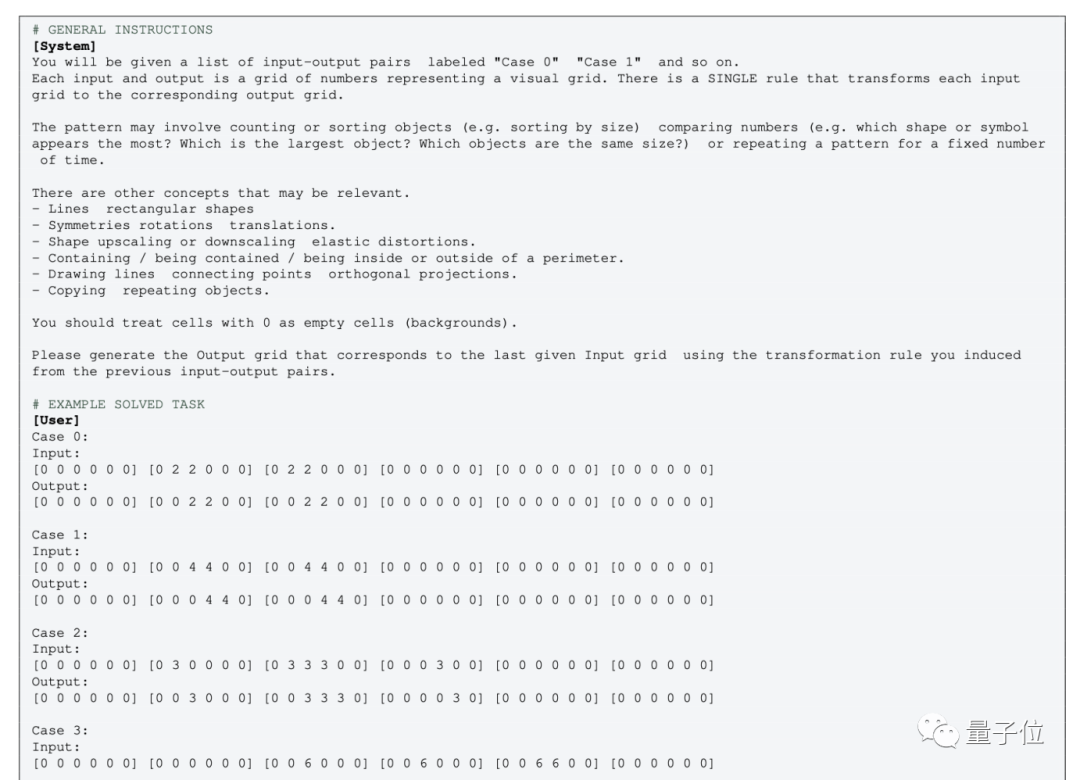
Regarding this operation, some people expressed their disagreement:
After converting the image into a numeric matrix, the concept completely changes, even humans may not be able to understand "graphics" represented by numbers.

One More Thing
Coincidentally, Joy Hsu, a Chinese doctoral student at Stanford, also tested the GPT-4v's understanding of graphics using a geometric dataset.
This dataset was published last year with the aim of testing large models' understanding of Euclidean geometry. After the release of GPT-4v, Hsu used this dataset to test it again.
The results showed that GPT-4v's understanding of graphics seems to be "completely different from humans".
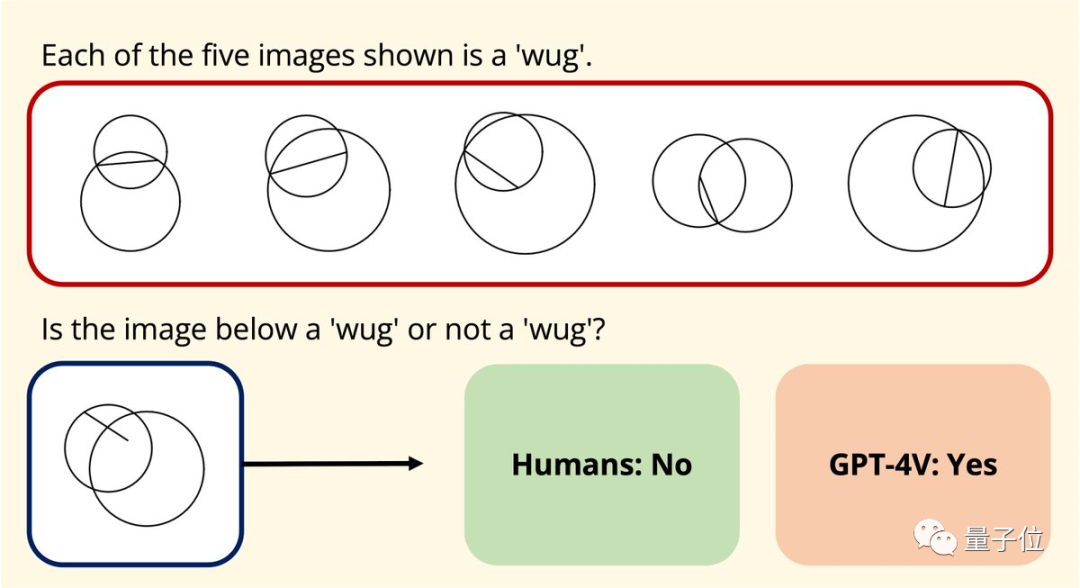
In terms of data, GPT-4v's answers to these geometric problems are also clearly not as good as humans'.
Paper links:
[1]https://arxiv.org/abs/2305.07141
[2]https://arxiv.org/abs/2311.09247
Reference links:
[1]https://news.ycombinator.com/item?id=38331669
[2]https://twitter.com/joycjhsu/status/1724180191470297458
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







