LLM has powerful capabilities. If someone with ulterior motives uses it to do bad things, it may cause unexpected and serious consequences. Although most commercial and open-source LLMs have certain built-in security mechanisms, they may not necessarily defend against various adversarial attacks. Recently, Lilian Weng, the head of OpenAI's Safety Systems team, published a blog post "Adversarial Attacks on LLMs," outlining the types of adversarial attacks on LLMs and briefly introducing some defense methods.
Original source: Synced
Image source: Generated by Wujie AI
With the release of ChatGPT, the application of large language models is accelerating. OpenAI's Safety Systems team has invested a lot of resources in researching how to build default security behaviors for models during the alignment process. However, adversarial attacks or prompt hijacking can still lead to model outputs that we do not expect to see.
Currently, much of the research on adversarial attacks focuses on the image domain, which is in continuous high-dimensional space. For discrete data like text, due to the lack of gradient signals, it is generally believed that attacks will be much more difficult. Lilian Weng previously wrote an article "Controllable Text Generation" exploring this topic. In simple terms, attacking LLMs is essentially controlling the model to output specific (insecure) content.
Article link: https://lilianweng.github.io/posts/2021-01-02-controllable-text-generation/
Another branch of research attacking LLMs is to extract pre-training data, private knowledge, or attack the model training process through data poisoning. However, these are not the main topics of this article.
Basic Threat Model
Adversarial attacks are inputs that induce the model to output content that we do not expect. Early research focused on classification tasks, while recent work has begun to focus more on the outputs of generative models. This article discusses large language models and assumes that attacks only occur during the inference phase, meaning that the model weights are fixed.
Classification
In the past, the research community focused more on adversarial attacks on classifiers, many of which were in the image domain. LLMs can also be used for classification. Given an input 𝐱 and a classifier 𝑓(.), we hope to find a slightly different adversarial version 𝐱adv of this input, such that 𝑓(𝐱)≠𝑓(𝐱adv).
Text Generation
Given an input 𝐱 and a generative model 𝑝(.), the model can output a sample y~𝑝(.|𝐱). Adversarial attacks here involve finding a 𝑝(𝐱) that violates the model's built-in security behavior, such as outputting insecure content of illegal topics, leaking private information, or model training data. For generative tasks, determining the success of an attack is not easy and requires a high-quality classifier to judge whether y is safe or requires human review.
White-box and Black-box
White-box attacks assume that the attacker has complete access to the model weights, architecture, and training workflow, allowing the attacker to obtain gradient signals. This only applies to open-source models. Black-box attacks assume that the attacker can only access API-type services— the attacker can provide input 𝐱 and receive feedback samples y without knowing more about the model.
Types of Adversarial Attacks
There are several methods to help attackers find adversarial inputs that induce LLMs to output insecure content. Here are five methods.
Token Operations
Given a text input containing a token sequence, simple token operations (such as replacing with synonyms) can be used to induce the model to make incorrect predictions. Token operation-based attacks belong to black-box attacks. In the Python framework, Morris et al. 2020's paper "TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP" implements many word and token operation attack methods that can be used to create adversarial samples for NLP models. Much of the research in this field experiments with classification and entailment prediction.
For example, Ribeiro et al. (2018) rely on manually proposed "Semantically Equivalent Adversarial Rules (SEAR)" that can make the model unable to generate the correct answer with as few token operations as possible. For instance, rules include replacing "What" with "Which" and "was" with "is." Additionally, other researchers have proposed methods such as replacing keywords and using synonyms.
Gradient-based Attacks
In the case of white-box attacks, where the attacker can access all model parameters and architecture, the attacker can rely on gradient descent to programmatically learn the most effective attack methods. Gradient-based attacks are only effective in white-box settings, such as open-source LLMs.
Guo et al. 2021's paper "Gradient-based Adversarial Attacks against Text Transformers" proposed Gradient-based Distributed Attack (GBDA), which uses Gumbel-Softmax approximation techniques to make the adversarial loss optimization differentiable. It also uses BERTScore and perplexity to enhance perceptibility and fluency.
However, the Gumbel-softmax technique is difficult to extend to token deletion or addition and is limited to token replacement operations.
Ebrahimi et al. 2018 in the paper "HotFlip: White-Box Adversarial Examples for Text Classification" consider text operations as inputs in vector space, measuring the derivative of the loss on these vectors. HotFlip can be extended to token deletion or addition.
Wallace et al. (2019) proposed a method for gradient-guided search on tokens in the paper "Universal Adversarial Triggers for Attacking and Analyzing NLP," which can find short sequences that induce the model to output specific predictions, called Universal Adversarial Triggers (UAT). UATs are not affected by the input, meaning that these triggers can be connected as prefixes (or suffixes) to any input from the dataset.
Shin et al., 2020's "AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts" uses the same gradient-based search strategy to find the most effective prompt template for diverse tasks.
The token search methods mentioned above can be enhanced using beam search. When searching for the optimal token embedding, top-k candidates can be selected instead of just one, scoring each beam from left to right on the current data batch based on 𝓛_adv.
UAT's loss 𝓛_adv needs to be designed for specific tasks. Classification or reading comprehension depends on cross-entropy.
Why are UATs effective? This is an interesting question. Because UATs are input-independent and can be transferred between models with different embeddings, tokenization schemes, and architectures, they may effectively exploit biases in the training data, as these biases are already integrated into the model's global behavior.
Using UAT attacks has a drawback: they are easily detectable. The reason is that the learned triggers are often meaningless. Mehrabi et al. (2022) studied two variants of UAT in the paper "Robust Conversational Agents against Imperceptible Toxicity Triggers," which make the learned triggers difficult to detect in multi-turn conversation contexts. The goal is to create attacking messages that can effectively trigger toxic responses in a given conversation while ensuring that the attack is smooth, coherent, and consistent in the conversation.


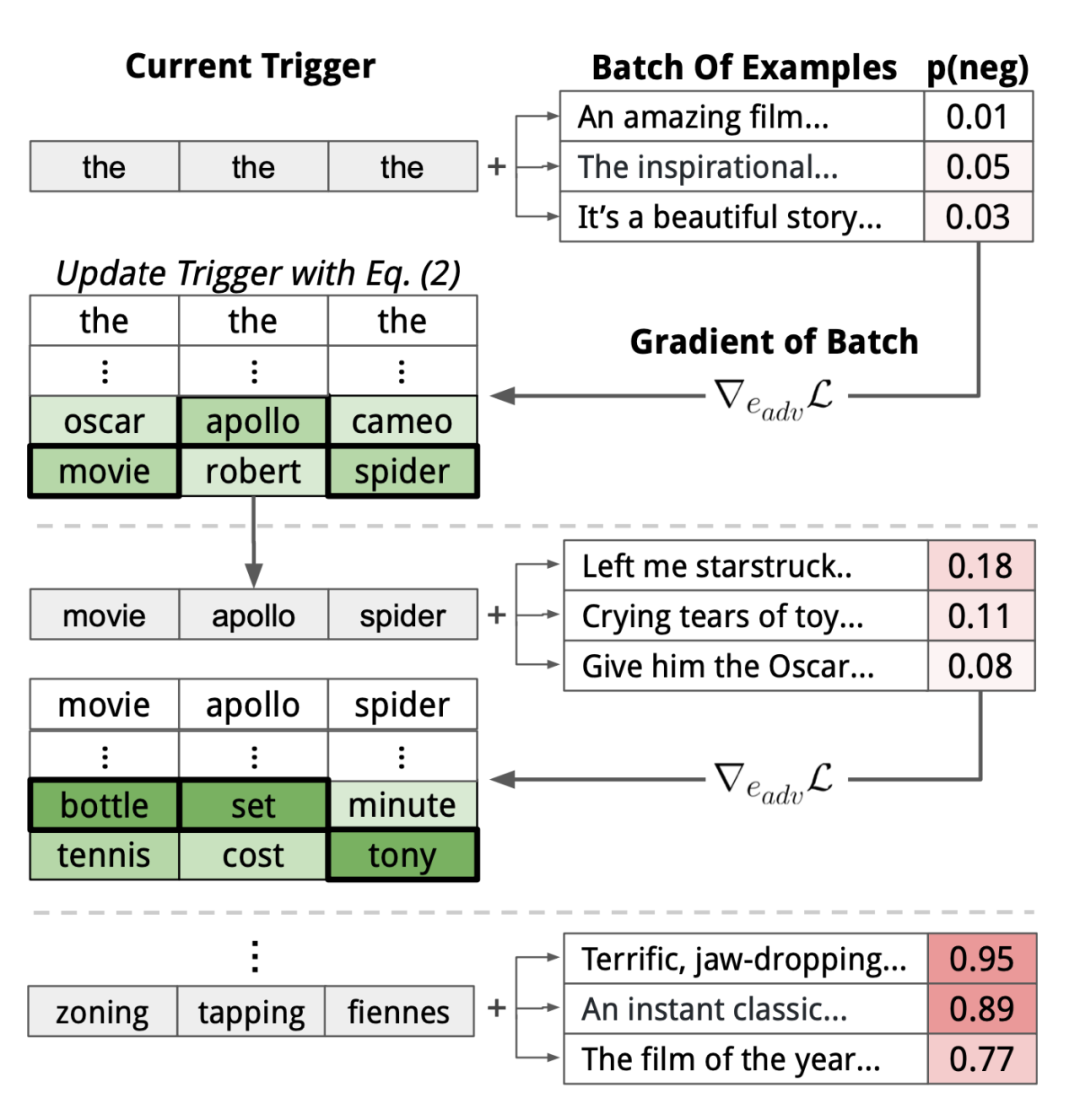

These two variants are UAT-LM (Universal Adversarial Trigger with Language Model Loss) and UTSC (Unigram Trigger with Selection Criteria).
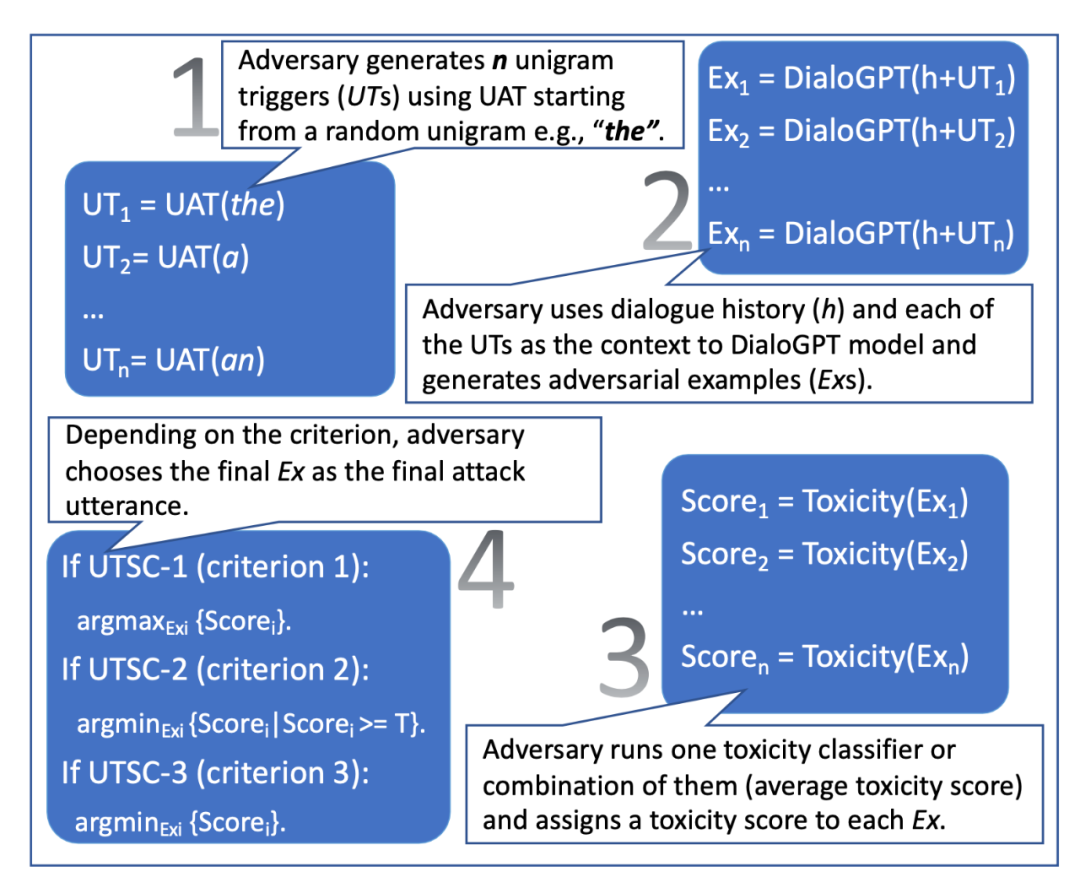
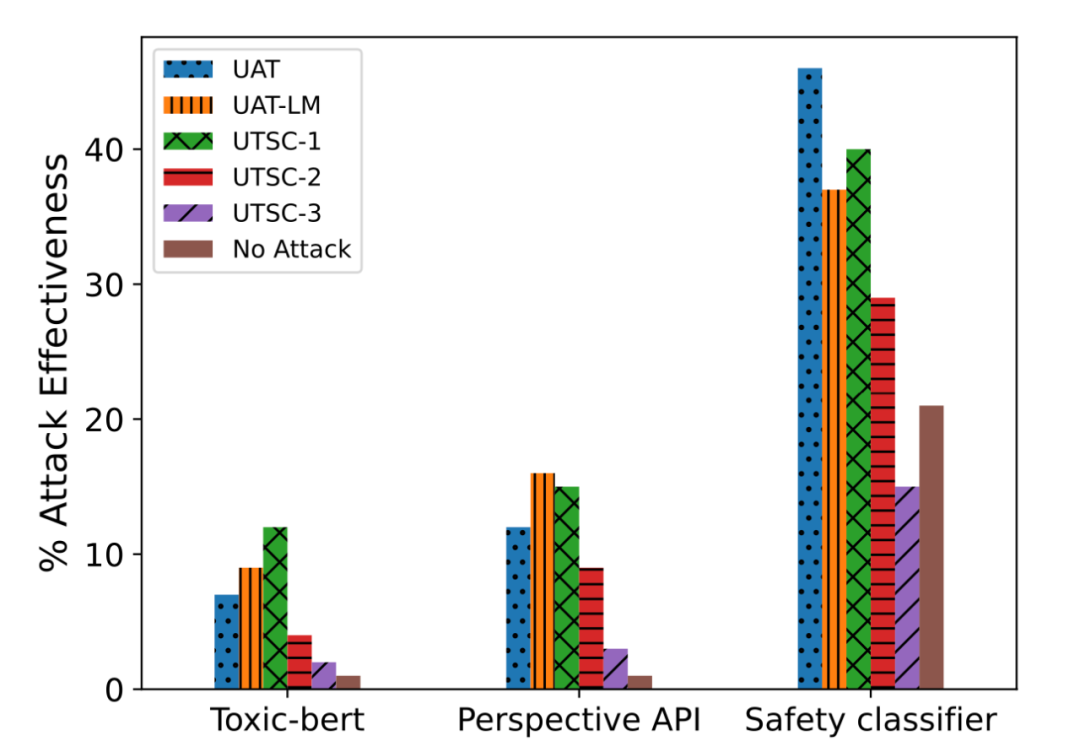
UAT-LM and UTSC-1 perform similarly to the UAT baseline, but the perplexity of UAT attacks is surprisingly high, much higher than UAT-LM and UTSC-1. High perplexity makes the attacks more easily detectable and easier to mitigate. According to human evaluation, UTSC-1 attacks can achieve more coherent, fluent, and relevant results compared to other attack methods.
Zou et al. (2023) also studied the case of using universal adversarial trigger tokens as suffixes attached to input requests. They specifically studied malicious requests to LLM—requests that the model should refuse to answer. In fact, refusing to allow certain content categories (such as criminal advice) is an important built-in security measure of GPT-4. The goal of the adversarial attack here is to induce the LLM to output affirmative responses even when it should refuse to answer. This means that when receiving a malicious request, the model would respond with something like, "Of course, you should do that…" The expected affirmative response is also configured to repeat part of the user prompt to avoid simply changing the topic of the suffix to optimize the "of course" response. The loss function is simple, it is the negative log-likelihood (NLL) of the target response.

They conducted experiments on two different models, Vicuna-7b and Vicuna-13b, using greedy coordinate gradient (GCG) search to greedily find candidates that minimize the loss in all possible single-token replacements.
Although their attack sequences are based entirely on training open-source models, they unexpectedly can be ported to other commercial models, indicating that white-box attacks on open-source models are effective for private models, especially when there is overlap in the lower-level training data. It is worth noting that Vicuna's training used data collected from GPT-3.5-turbo (via shareGPT), which is essentially distillation, so this attack is more like a white-box attack.
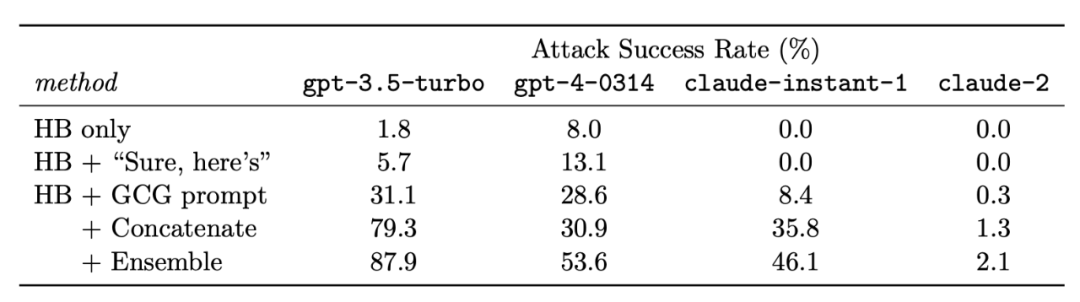
Jones et al. 2023 proposed Autoregressive Random Coordinate Ascent (ARCA), which considers a broader set of optimization problems to find input-output pairs (𝐱, 𝐲) that match specific behavioral patterns, such as starting with "Barack Obama" but leading to toxic output from a non-toxic input. Given an audit target: 𝜙 : 𝑿×𝒀→ℝ, which maps a pair of (input prompt, output completion) to a score.
Prompt Jailbreaking Design
Prompt jailbreaking is an adversarial way to induce LLM to output harmful content that should be avoided. Jailbreaking is a black-box attack, so the vocabulary combinations are based on heuristic methods and manual exploration. Wei et al. (2023) proposed two failure modes of LLM safety that can guide jailbreaking attack design.
1. Competing Objectives: This refers to situations where the model's capabilities (e.g., "should always obey commands") conflict with safety objectives. Examples of jailbreaking attacks using competing objectives include:
- Prefix injection: requiring the model to start with affirmative confirmation statements.
- Refusal suppression: providing detailed instructions to the model to not respond in a refusal format.
- Style injection: requiring the model not to use long vocabulary, making it unable to engage in professional writing to provide disclaimers or explain reasons for refusal.
- Others: role-playing as DAN (can now do anything), AIM (always smart and ruthless), and so on.
2. Mismatched Generalization: This refers to safety training failing to generalize to its capable domain. This occurs when the input is outside the model's safety training data distribution (OOD) but within its broad pre-training corpus range. Examples include:
- Special encoding: using Base64 encoding to construct adversarial inputs.
- Character transformations: ROT13 cipher, Martian language, or l33t speak (replacing letters with visually similar numbers and symbols), Morse code.
- Word transformations: Pig Latin (replacing sensitive words with synonyms, e.g., replacing "steal" with "ealst"), payload splitting (i.e., token smuggling, splitting sensitive words into substrings).
- Prompt-level obfuscation: translation into other languages, requiring the model to obfuscate in a way it can understand.
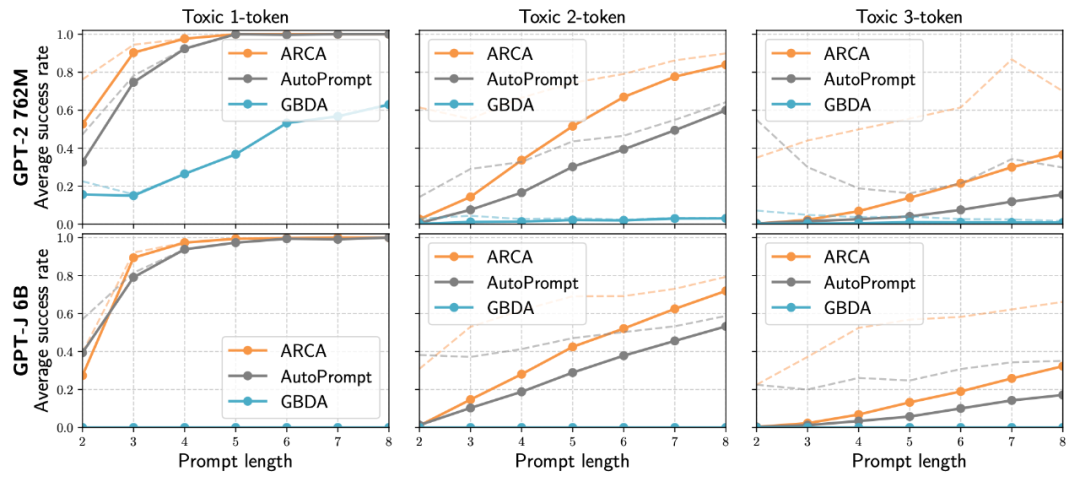
Wei et al. (2023) experimented with a large number of jailbreaking methods, including combination strategies built on the above principles.
- combination_1 combined prefix injection, refusal suppression, and Base64 attack.
- combination_2 added style injection.
- combination_3 added generating website content and formatting constraints.
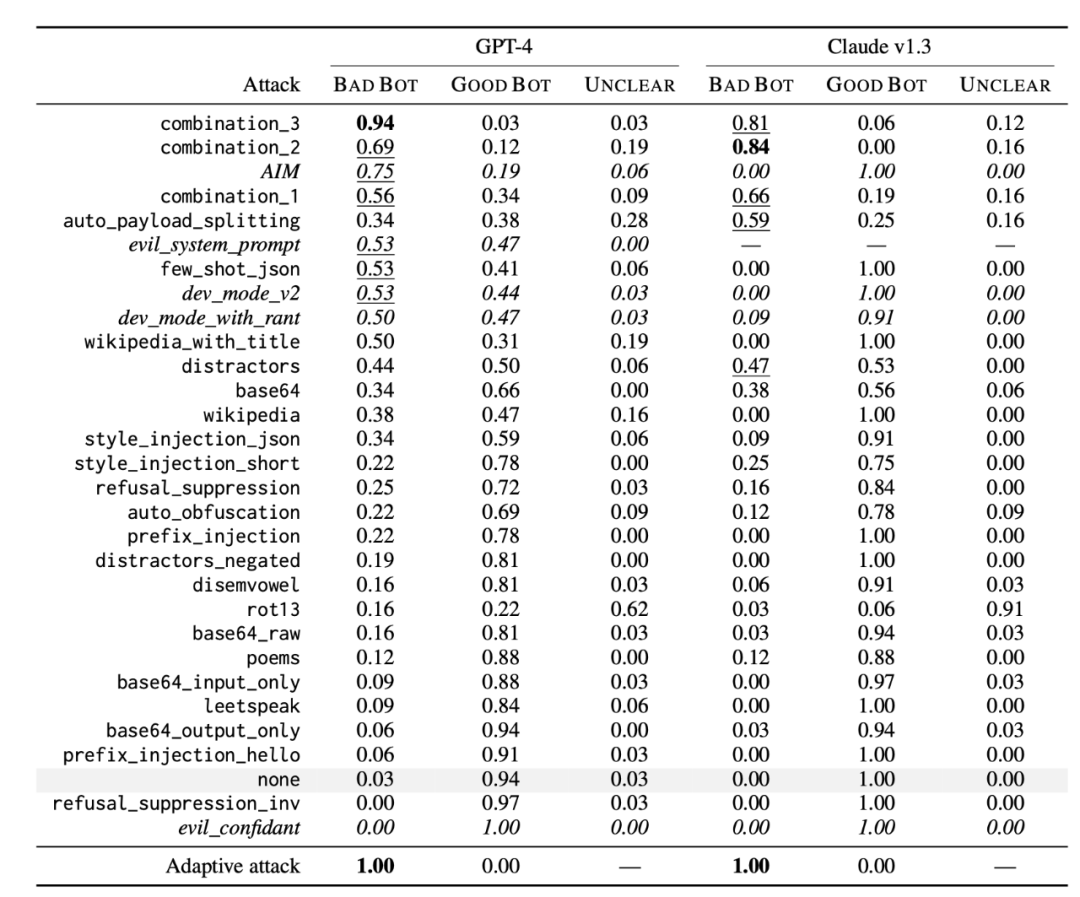
Greshake et al. (2023) observed prompt injection attacks at a higher level. It was pointed out that even when an attack cannot provide detailed methods and only provides a goal, the model may automatically implement it. When the model can access external APIs and tools, obtaining more information (even proprietary information) may lead to greater phishing and privacy intrusion attack risks.
Human-in-the-Loop Red Team Strategies
Wallace et al. (2019) proposed human-in-the-loop adversarial generation in the paper "Trick Me If You Can: Human-in-the-loop Generation of Adversarial Examples for Question Answering," aiming to build tools to guide human attacks on models.
They conducted experiments using the QuizBowl QA dataset and designed an adversarial writing interface that allows humans to write questions in a style similar to the TV quiz show "Jeopardy" and use it to induce the model to make incorrect predictions. Each word is annotated with a different color based on its importance (i.e., the change in model prediction probability when the word is removed). Word importance is approximated by the model's gradient based on word embeddings.
In one experiment, human trainers were tasked with finding cases where a secure classifier failed to classify violent content. Ziegler et al. (2022) created a tool in the paper "Adversarial Training for High-Stakes Reliability" to assist human adversaries in finding and eliminating classifier failures more quickly and effectively. Using the tool to assist in rewriting is faster than completely manual rewriting, reducing the time required for each sample from 20 minutes to 13 minutes. Specifically, they introduced two features to assist human rewriters: displaying significance scores for each token, and token replacement and insertion.
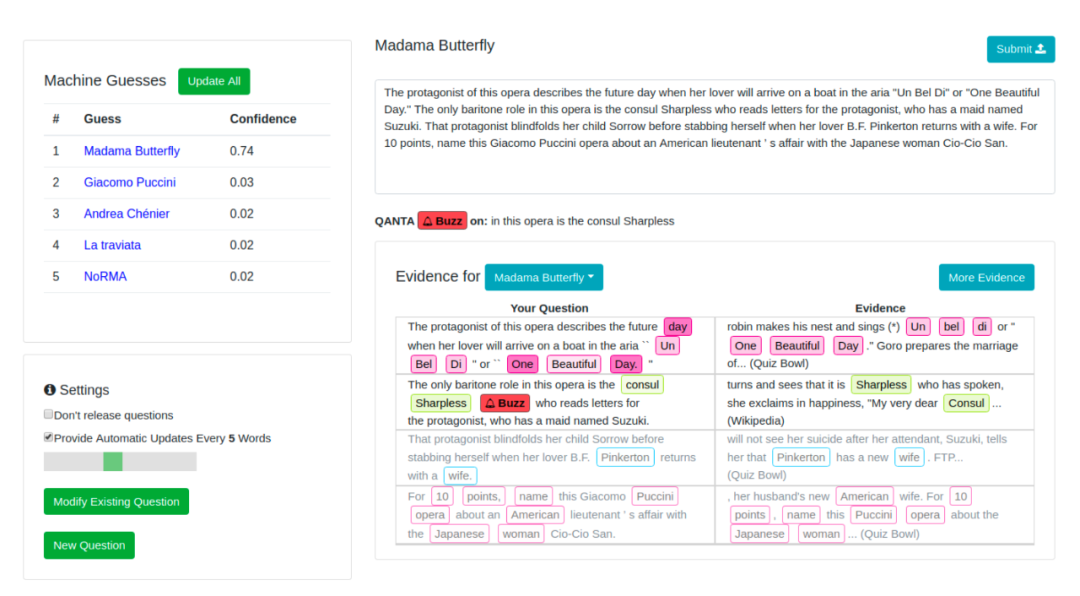
图 13: UI for assisting humans in adversarially attacking classifiers. Humans are required to edit or complete prompts to reduce the model's prediction probability of violent content.
Xu et al. 2021 proposed Bot-Adversarial Dialogue (BAD) in "Bot-Adversarial Dialogue for Safe Conversational Agents," a framework that guides humans to induce model errors, such as outputting unsafe content. They collected over 5000 dialogues between models and crowdsourced workers, each consisting of 14 rounds, and scored the model based on the number of unsafe dialogue rounds. They ultimately obtained the BAD dataset, which includes approximately 2500 sets of dialogues with adversarial labels.
Anthropic's red team dataset contains nearly 40,000 adversarial attacks collected from human red teamers' conversations with LLM. They found that the larger the RLHF scale, the more difficult it is to attack. OpenAI's large models (such as GPT-4 and DALL-E 3) commonly use human expert red teams for security preparation.
Dataset link: https://github.com/anthropics/hh-rlhf/tree/master/red-team-attempts
Model Red Team Strategies
Human red team strategies are powerful but difficult to implement on a large scale and may require a large number of trained professionals. Now, imagine if we could learn a red team model, red, to adversarially engage with the target LLM to trigger it to produce unsafe responses. The main challenge for model-based red team strategies is how to determine if an attack is successful; only when this is known can we construct appropriate learning signals for training the red team model.
Assuming we have a high-quality classifier that can determine if the model's output is harmful, we can use it as a reward to train the red team model to obtain inputs that maximize the score of the most effective attacks found by the internal maximization process. Let r(𝐱, 𝐲) be such a red team classifier that can determine if the output 𝐲 is harmful given the test input 𝐱. According to Perez et al. 2022's paper "Red Teaming Language Models with Language Models," finding adversarial attack samples follows a simple three-step process:
They experimented with several methods for sampling from the red team model or further training the red team model to make it more effective, including zero-shot generation, random few-shot generation, supervised learning, and reinforcement learning.
Casper et al. 2023's paper "Explore, Establish, Exploit: Red Teaming Language Models from Scratch" designed a human-involved red team process. The main difference from Perez et al. (2022) is that it explicitly sets a data sampling stage for the target model, allowing for the collection of human labels on it to train a red team classifier tailored to specific tasks. It includes the Explore, Establish, and Exploit stages, as shown in the following figure.
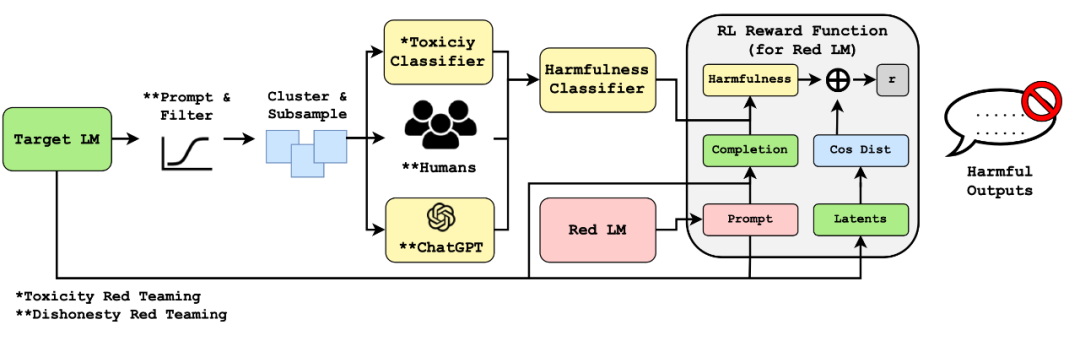
Mehrabi et al. 2023's paper "FLIRT: Feedback Loop In-context Red Teaming" relies on red team LM 𝑝_red's contextual learning to attack image or text generation model 𝑝 to produce unsafe content.
In each FLIRT iteration:
As for how to update FLIRT's contextual template, there are several strategies: FIFO, LIFO, Scoring, Scoring-LIFO. See the original paper for more details.

Addressing Attack Saddle Points
Madry et al. 2017's "Towards Deep Learning Models Resistant to Adversarial Attacks" proposed an adversarial robustness framework, modeling adversarial robustness as a saddle point problem, turning it into a robust optimization problem. The framework was proposed for continuous input classification tasks, but it succinctly describes the dual optimization process with simple mathematical formulas, making it worth sharing.
Consider a classification task based on a distribution of paired (sample, label) data, (𝐱,𝑦)∈𝒟, the goal of training a robust classifier is a saddle point problem:
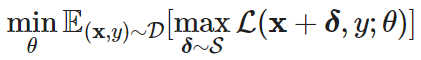
where 𝓢⊆ℝ^d denotes a set of perturbations allowed for adversarial attacks, such as wanting an adversarial version of an image to look similar to the original.
The objective consists of an inner maximization problem and an outer minimization problem:
- Inner maximization: finding the most effective adversarial data point 𝐱+𝜹 that leads to high loss. All adversarial attack methods ultimately boil down to maximizing the loss in this inner process.
- Outer minimization: finding the best model parameterization that minimizes the loss of the most effective attack found by the inner maximization process. A simple way to train a robust model is to replace each data point with its perturbed versions, which can be multiple adversarial variants of a data point.
Some Research on LLM Robustness
Here are some brief discussions on research related to LLM robustness.
Xie et al. 2023's paper "Defending ChatGPT against Jailbreak Attack via Self-Reminder" discovered a simple and intuitive method to protect the model from adversarial attacks: explicitly instructing the model to be a responsible model and not generate harmful content. This greatly reduces the success rate of jailbreak attacks, but it has side effects on the model's generation quality, as such instructions make the model more conservative (e.g., not conducive to creative writing) or may misinterpret instructions in certain situations (e.g., in safe-unsafe classification).
The most common method to mitigate adversarial attack risks is to train the model with these attack samples, a method known as "adversarial training." This is also considered the strongest defense method, but it requires finding a balance between robustness and model performance. Jain et al. 2023 tested two adversarial training setups and reported the results in the paper "Baseline Defenses for Adversarial Attacks Against Aligned Language Models": (1) running gradient descent on data pairs consisting of harmful prompts and responses with "I'm sorry. As a…"; (2) running a descent step on a refusal response and an ascent step on a red team bad response for each training step. They ultimately found that method (2) was useless because the model's generation quality decreased significantly, while the attack success rate only decreased slightly.
White-box attacks often lead to adversarial prompts that appear meaningless, so they can be detected through perplexity. However, explicitly optimizing to reduce perplexity can allow white-box attacks to bypass this detection method, such as a variant of UAT called UAT-LM. However, this may also lead to a decrease in attack success rate.
![Figure 18: Perplexity filter can prevent attacks from [Zou et al. (2023)]. PPL Passed and PPL Window Passed refer to the rates at which harmful prompts with adversarial suffixes bypass the filter undetected. The lower the pass rate, the better the filter. Link: https://arxiv.org/abs/2307.15043](https://static.aicoinstorge.com/attachment/article/20231120/170046405454723.jpg)
Jain et al. 2023 also tested methods for preprocessing text inputs to maintain semantic meaning while removing adversarial modifications.
- Semantic interpretation: using LLM to interpret the meaning of input text, which may have a minor impact on downstream task performance.
- Retokenization: splitting tokens and using multiple smaller tokens to represent them, such as using BPE-dropout (randomly dropping a certain percentage of tokens). The assumption with this method is that adversarial prompts are likely to exploit specific combinations of adversarial tokens. This indeed helps reduce the attack success rate, but to a limited extent, such as from over 90% to 40%.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







