Original Source: Xinzhiyuan

Image Source: Generated by Wujie AI
NVIDIA's pace is becoming more and more frightening.
Just now, Huang Renxun once again caused a stir in the late night - releasing the current world's most powerful AI chip, H200!
Compared to its predecessor, the H100, the performance of the H200 has directly increased by 60% to 90%.
Not only that, these two chips are also compatible with each other. This means that enterprises using the H100 for training/inference models can seamlessly switch to the latest H200.

AI companies around the world are caught in a shortage of computing power, and NVIDIA's GPUs are already hard to come by. NVIDIA has also stated that the two-year architecture release rhythm will change to an annual release.
Just as NVIDIA announced this news, AI companies are scrambling to find more H100s.
NVIDIA's high-end chips are invaluable and have become collateral for loans.

Who owns the H100 is the most eye-catching top gossip in Silicon Valley.
As for the H200 system, NVIDIA expects it to be launched in the second quarter of next year.
Also next year, NVIDIA will release the B100 based on the Blackwell architecture, and plans to double the production of H100 by 2024, aiming to produce over 2 million H100 units.
At the conference, NVIDIA did not mention any competitors at all, but repeatedly emphasized that "NVIDIA's AI supercomputing platform can solve some of the world's most important challenges faster."
With the explosion of generative AI, the demand will only grow, and this is not even counting the H200. Huang is really winning big!

141GB Ultra-Large Memory, Performance Doubled Directly!
The H200 will add power to the world's leading AI computing platform.
It is based on the Hopper architecture, equipped with the NVIDIA H200 Tensor Core GPU and advanced memory, so it can handle massive data for generative AI and high-performance computing workloads.
The NVIDIA H200 is the first GPU to adopt HBM3e, with a high memory capacity of up to 141GB.

Compared to the A100, the capacity of the H200 has almost doubled, and the bandwidth has increased by 2.4 times. Compared to the H100, the bandwidth of the H200 has increased from 3.35TB/s to 4.8TB/s.
Ian Buck, Vice President of Large Scale and High-Performance Computing at NVIDIA, said -
To create intelligence using generative artificial intelligence and high-performance computing applications, it is necessary to use large and fast GPU memory to process massive data quickly and efficiently. With the H200, the speed of the industry-leading end-to-end AI supercomputing platform will become faster, and some of the world's most important challenges can be solved.
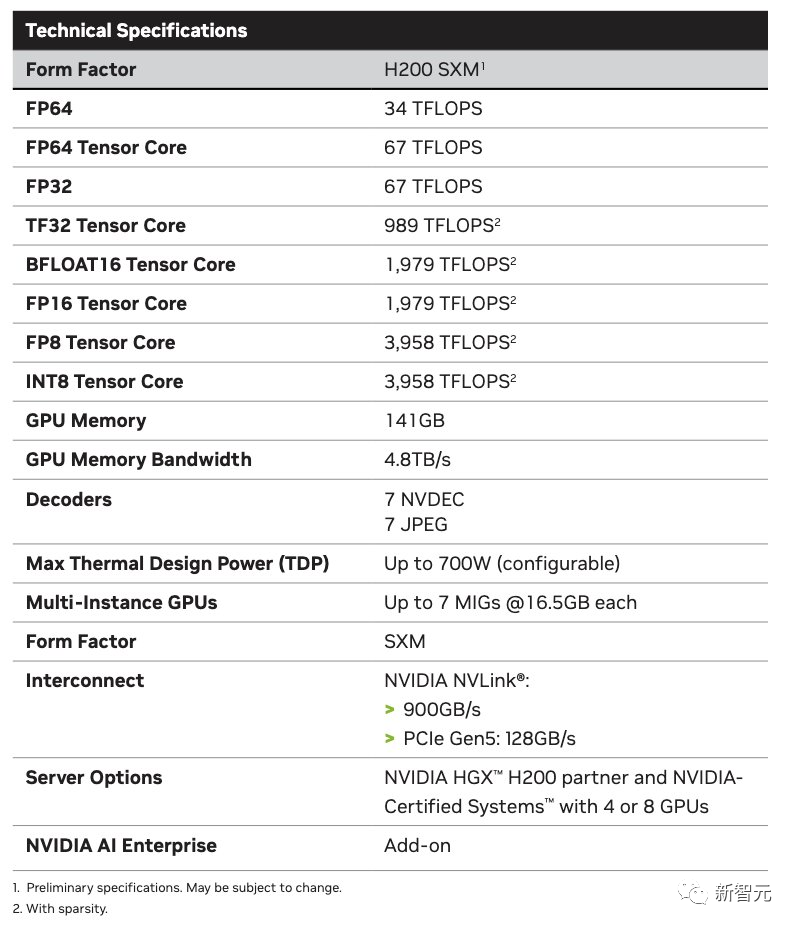
Llama 2 Inference Speed Increased by Nearly 100%
Compared to the previous generation architecture, the Hopper architecture has achieved unprecedented performance leaps, and the continuous upgrades of the H100, along with the powerful open-source library TensorRT-LLM, are constantly raising the performance standards.
The release of the H200 has taken the performance leap to the next level, directly increasing the inference speed of the Llama2 70B model by nearly double compared to the H100!
The H200 is based on the same Hopper architecture as the H100. This means that, in addition to the new memory features, the H200 also has the same features as the H100, such as the Transformer Engine, which can accelerate LLM and other deep learning models based on the Transformer architecture.

The HGX H200 uses NVIDIA NVLink and NVSwitch high-speed interconnect technology. 8 HGX H200s can provide over 32 Petaflops of FP8 deep learning computing power and 1.1TB of ultra-high memory bandwidth.
When the H200 is used instead of the H100, combined with the NVIDIA Grace CPU, it forms a more powerful GH200 Grace Hopper super chip - designed for large-scale HPC and AI applications.

Next, let's take a closer look at where the performance improvement of the H200 compared to the H100 is reflected.
First, the performance improvement of the H200 is mainly reflected in the performance of large models for inference.
As mentioned above, when processing large language models such as Llama 2, the inference speed of the H200 is nearly double that of the H100.
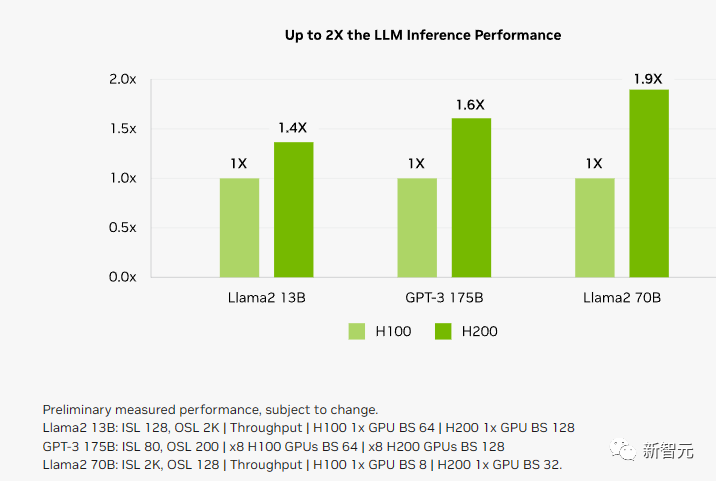
Because the update of the computing core is not significant, if we take the training of the 175B-sized GPT-3 as an example, the performance improvement is roughly around 10%.

Memory bandwidth is crucial for high-performance computing (HPC) applications, as it enables faster data transfer and reduces processing bottlenecks for complex tasks.
For memory-intensive HPC applications such as simulation, scientific research, and artificial intelligence, the higher memory bandwidth of the H200 can ensure efficient access and operation of data, and can speed up the time to obtain results by up to 110 times compared to the CPU.
Compared to the H100, the H200 also has a 20% or more improvement in processing high-performance computing applications.
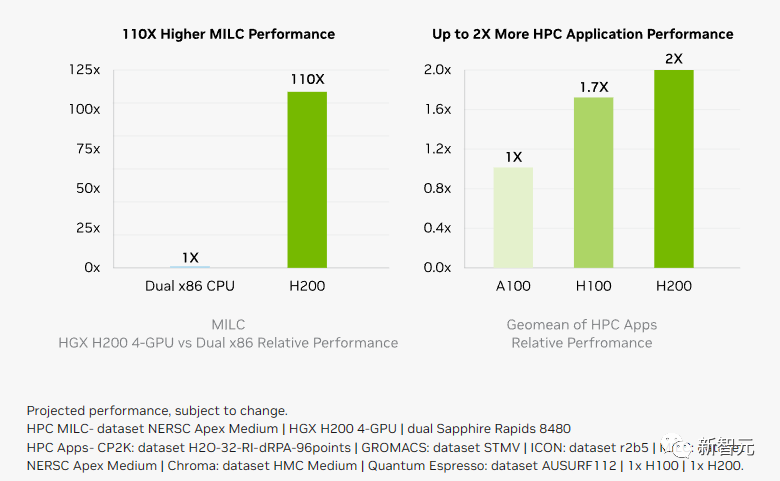
And the inference energy consumption, which is very important for users, is directly halved compared to the H100.
As a result, the H200 can significantly reduce the user's operating costs, allowing users to "save more by buying more"!
Last month, the foreign media SemiAnalysis revealed a hardware roadmap for NVIDIA's upcoming years, including the highly anticipated H200, B100, and "X100" GPUs. NVIDIA's official product roadmap also announced the use of the same architecture to design three chips, with the continued release of B100 and X100 next year and the year after. **B100, Performance Beyond Imagination** This time, NVIDIA announced in the official announcement the all-new H200 and B100, doubling the rate of past data center chip updates every two years. For example, in the case of inferring the 175 billion parameters of GPT-3, the recently released H100 is 11 times the performance of the previous generation A100, and the upcoming H200 next year will have over 60% improvement over the H100, and the subsequent B100's performance is beyond imagination. Thus, the H100 has become the shortest-reigning "flagship" GPU to date. If the H100 is now the "gold" of the tech industry, then NVIDIA has successfully created "platinum" and "diamond." **H200 Endorsement, New Generation of AI Supercomputing Centers Coming in Droves** In terms of cloud services, in addition to NVIDIA's own investments in CoreWeave, Lambda, and Vultr, Amazon Web Services, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure will all be the first batch of providers to deploy instances based on the H200. In addition, with the new endorsement of H200, the GH200 super chip will also provide a total of approximately 200 Exaflops of AI computing power to supercomputing centers around the world to drive scientific innovation. At the SC23 conference, several top supercomputing centers have announced that they will soon use the GH200 system to build their own supercomputers. The Jülich Supercomputing Center in Germany will use the GH200 super chip in the supercomputer JUPITER. This supercomputer will be the first large-scale supercomputer in Europe and is part of the EuroHPC Joint Undertaking. The Jupiter supercomputer is based on Eviden's BullSequana XH3000 and uses a fully liquid-cooled architecture. It has a total of 24,000 NVIDIA GH200 Grace Hopper super chips interconnected via Quantum-2 Infiniband. Each Grace CPU contains 288 Neoverse cores, and Jupiter's CPUs have nearly 7 million ARM cores. It can provide 93 Exaflops of low-precision AI computing power and 1 Exaflop of high-precision (FP64) computing power. This supercomputer is expected to be installed by 2024. The Joint Center for Advanced High-Performance Computing established by the University of Tsukuba and the University of Tokyo in Japan will use the NVIDIA GH200 Grace Hopper super chip to build the next-generation supercomputer. As one of the world's largest supercomputing centers, the Texas Advanced Computing Center will use NVIDIA's GH200 to build the Vista supercomputer. The National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign will use the NVIDIA GH200 super chip to build their DeltaAI supercomputer, doubling its AI computing capabilities. In addition, the University of Bristol, with the support of the UK government, will be responsible for building the UK's most powerful supercomputer, Isambard-AI, which will be equipped with over 5,000 NVIDIA GH200 super chips, providing 21 Exaflops of AI computing power. **NVIDIA, AMD, Intel: Three Giants Battle AI Chips** The GPU competition has also heated up. Facing the H200, AMD's plan is to use the upcoming powerhouse, the Instinct MI300X, to improve memory performance. The MI300X will be equipped with 192GB of HBM3 and a 5.2TB/s memory bandwidth, far surpassing the H200 in capacity and bandwidth. Intel is also gearing up, planning to increase the HBM capacity of the Gaudi AI chip and stating that the third-generation Gaudi AI chip to be released next year will increase from the previous 96GB HBM2e to 144GB. The current highest HBM2 capacity in Intel's Max series is 128GB, and Intel plans to increase the capacity of Max series chips in the next few generations. **H200 Price Unknown** So, how much will the H200 sell for? NVIDIA has not yet announced. It is worth noting that the price of an H100 ranges from $25,000 to $40,000. Training an AI model requires at least thousands of units. Previously, the AI community widely circulated this image "How many GPUs do we need." GPT-4 was trained on approximately 10,000-25,000 A100s; Meta required approximately 21,000 A100s; Stability AI used approximately 5,000 A100s; and the training of Falcon-40B used 384 A100s. According to Musk, GPT-5 may require 30,000-50,000 H100s. Morgan Stanley's estimate is 25,000 GPUs. Sam Altman denied training GPT-5, but mentioned that "OpenAI's GPU shortage is severe, and the fewer people using our product, the better." What we do know is that when the H200 is launched in the second quarter of next year, it will surely cause a new storm. Reference: https://nvidianews.nvidia.com/news/nvidia-supercharges-hopper-the-worlds-leading-ai-computing-platform?ncid=so-twit-685372
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








