Article Source: Xinzhiyuan

Image Source: Generated by Wujie AI
The world's longest context window is here! Today, Baichuan Intelligence released the Baichuan2-192K large model, with a context window length of up to 192K (350,000 Chinese characters), which is 4.4 times that of Claude 2 and 14 times that of GPT-4!
A new benchmark in the field of long context windows has arrived!
Today, Baichuan Intelligence officially released the world's longest context window large model - Baichuan2-192K.
Unlike in the past, this model has a context window length of up to 192K, equivalent to about 350,000 Chinese characters.
More specifically, Baichuan2-192K can handle 14 times the number of Chinese characters in GPT-4 (32K context, approximately 25,000 characters in practice), and 4.4 times that of Claude 2 (100K context, approximately 80,000 characters in practice), enough to read "The Three-Body Problem" in one go.

Claude's long context window record has been redefined today
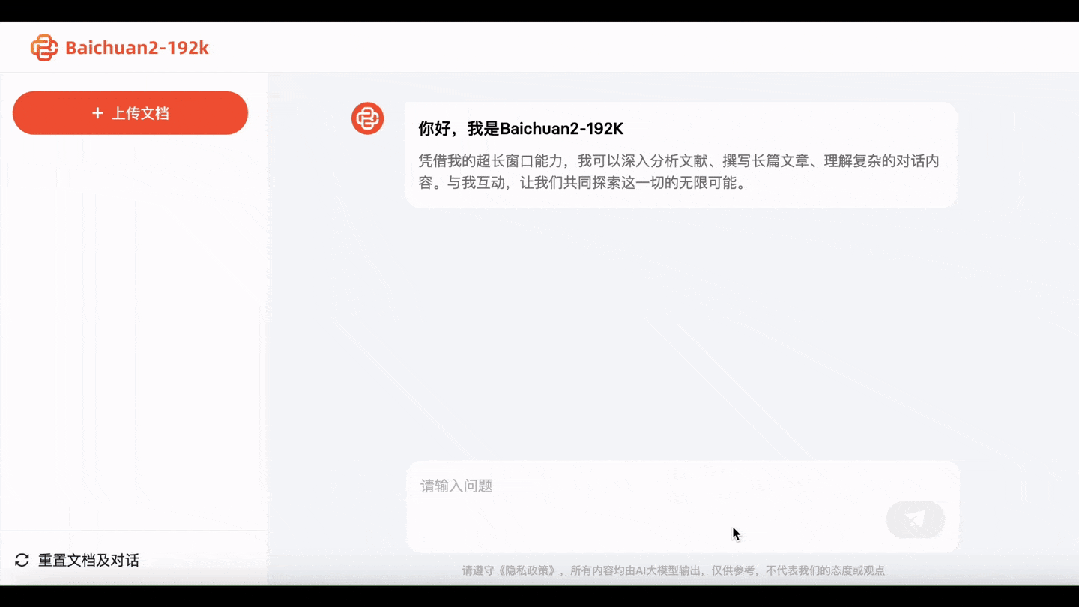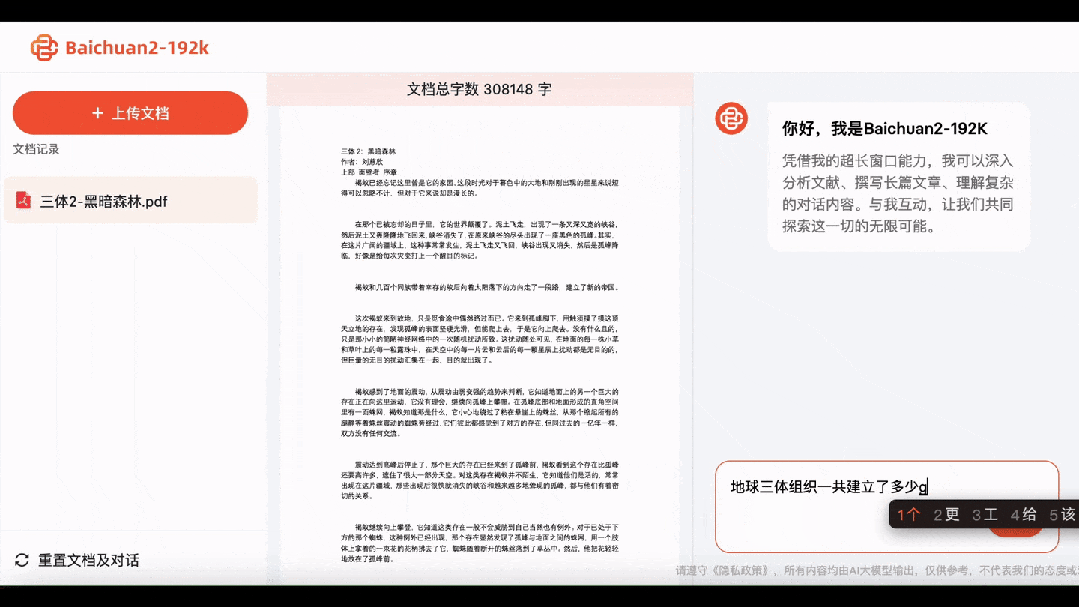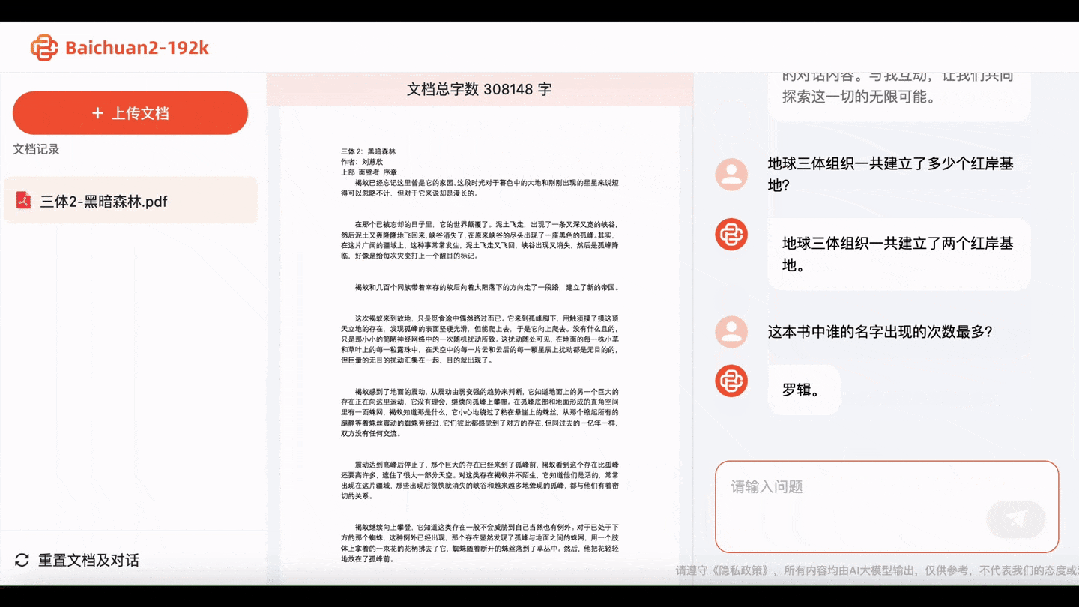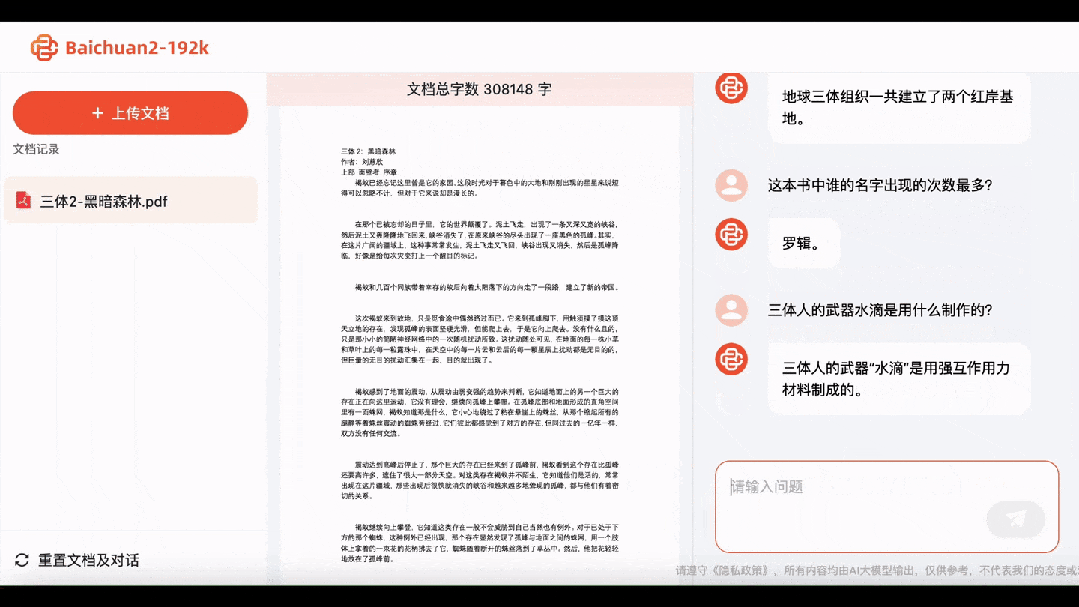
Throw the first part of "The Three-Body Problem" to it, and Baichuan2-192K will immediately have a thorough understanding of the entire story.
What is the number on the 36th photo in Wang Miao's countdown? Answer: 1194:16:37. What model of camera did he use? Answer: Leica M2. How many times did he and Da Shi drink together? Answer: Twice.

Take a look at the second part, "The Dark Forest," and Baichuan2-192K not only immediately answers that the Earth-Trisolaris Organization established two Red Coast bases, but also knows that "Waterdrop" is made of strong interaction material.
Moreover, even obscure questions that not even "Level Ten Scholars of Three-Body" can necessarily answer, Baichuan2-192K effortlessly responds to.
Whose name appears the most? Answer: Luo Ji.
It can be said that when the context window expands to 350,000 characters, the experience of using large models suddenly opens up a new world!
The world's longest context, comprehensively leading Claude 2
What will bottleneck large models?
Take ChatGPT as an example, although its capabilities are amazing, this "universal" model has an unavoidable constraint - it only supports a maximum of 32K tokens (25,000 Chinese characters) of context. However, professions such as lawyers and analysts often need to deal with much longer texts.

A larger context window allows the model to obtain richer semantic information from the input, and even directly process questions and information based on a full understanding of the text.
As a result, the model can better capture the relevance of the context, eliminate ambiguity, and generate content more accurately, alleviating the "hallucination" problem and improving performance. Moreover, with the blessing of a long context, it can be more deeply integrated into various vertical scenarios, truly playing a role in people's work, life, and learning.
Recently, Silicon Valley unicorn Anthropic has received investments of $4 billion from Amazon and $2 billion from Google. Its favor from the two giants is certainly related to Claude's leading position in long context capabilities.
And this time, the Baichuan-192K long window large model released by Baichuan Intelligence far exceeds Claude 2-100K in the length of the context window, and also achieves comprehensive leadership in text generation quality, context understanding, and question-answering capabilities.
10 authoritative evaluations, winning 7 SOTA
LongEval is a list of evaluations for long window models jointly released by the University of California, Berkeley and other universities, mainly measuring the model's memory and understanding of long window content.
In terms of context understanding, Baichuan2-192K significantly outperforms other models on the authoritative LongEval list for long window text understanding evaluations, maintaining very strong performance even with a window length exceeding 100K.
In contrast, the overall performance of Claude 2 drops significantly when the window length exceeds 80K.

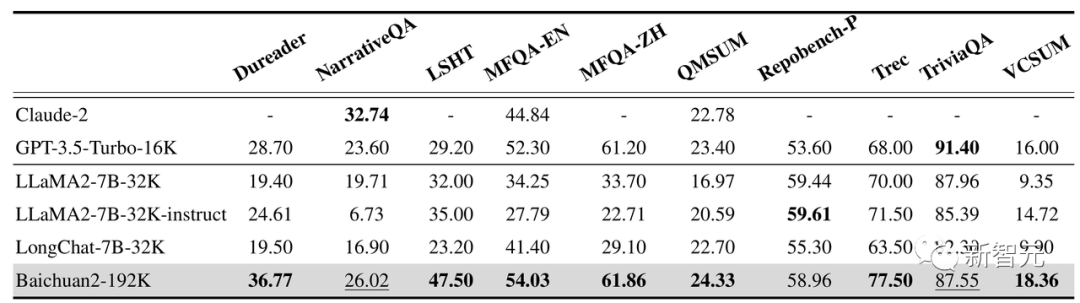
In addition, Baichuan2-192K performs equally well on 10 Chinese and English long text question-answering and summarization evaluation sets such as Dureader, NarrativeQA, LSHT, and TriviaQA.
Among them, 7 have achieved SOTA, significantly outperforming other long window models.
In terms of text generation quality, perplexity is a very important criterion.
Simply put, the lower the perplexity, the better the model, as it indicates a higher probability of the model generating text in the test set that conforms to human natural language habits.
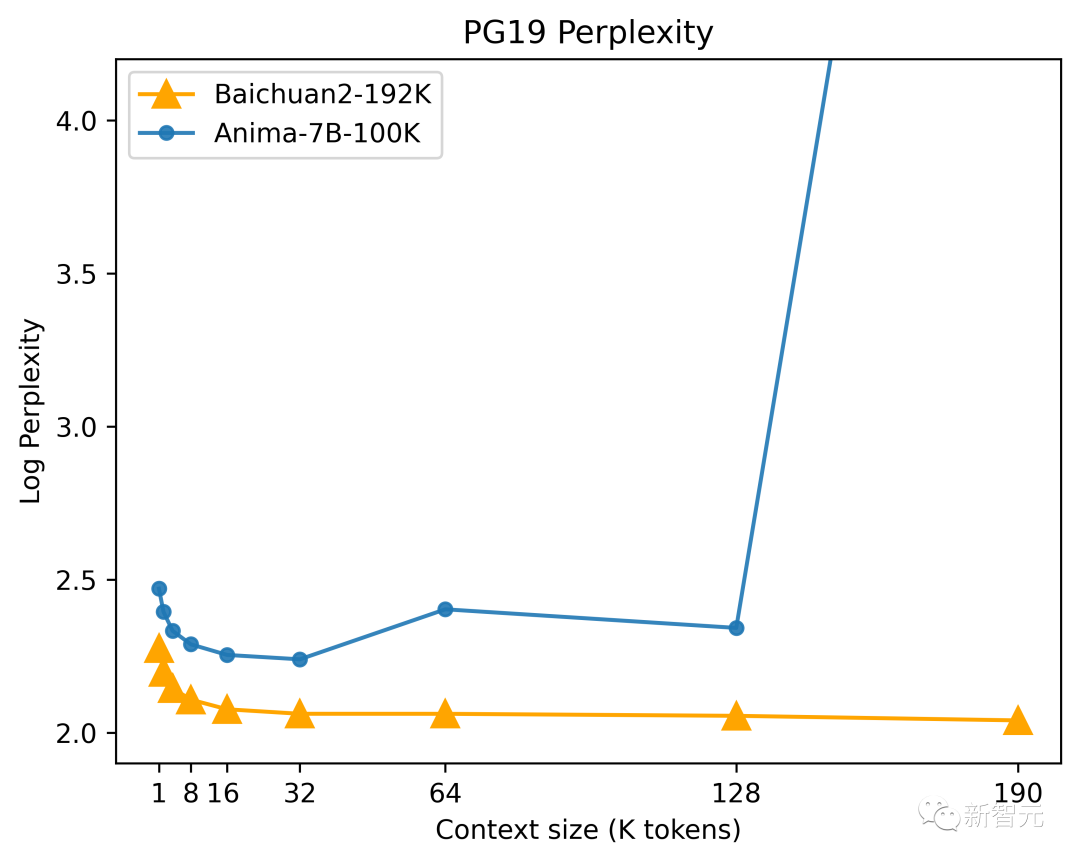
According to the test results of "Language Modeling Benchmark Dataset PG-19" released by DeepMind, Baichuan2-192K's perplexity is excellent from the initial stage, and its sequence modeling ability continues to strengthen as the window length increases.
Joint optimization of engineering algorithms, simultaneous improvement in length and performance
Although long context can effectively improve model performance, an extremely long window also means the need for stronger computing power and more memory.
Currently, the common practice in the industry is to use sliding windows, reduce sampling, and shrink models, among other methods.
However, these approaches all sacrifice model performance to varying degrees.
To address this issue, Baichuan2-192K achieves a balance between window length and model performance through the ultimate optimization of algorithms and engineering, achieving simultaneous improvement in window length and model performance.
First, in terms of algorithms, Baichuan Intelligence has proposed an extrapolation solution for RoPE and ALiBi dynamic position encoding - it can dynamically interpolate different lengths of ALiBi position encoding with different degrees of attention-mask, enhancing the model's ability to model long sequences while maintaining resolution.
Next, in terms of engineering, Baichuan Intelligence has integrated almost all advanced optimization technologies on the market, including tensor parallelism, pipeline parallelism, sequence parallelism, recomputation, and Offload, based on its independently developed distributed training framework. It has created a comprehensive 4D parallel distributed solution - which can automatically find the most suitable distributed strategy based on the specific load of the model, greatly reducing the memory usage during long window training and inference.
Internal testing officially begins, first-hand experience unveiled
Now, Baichuan2-192K has officially started internal testing!
Core partners of Baichuan Intelligence have already integrated Baichuan2-192K into their applications and businesses through API calls. Collaborations have been established with financial media, law firms, and other institutions.
It can be imagined that with Baichuan2-192K's globally leading long context capabilities applied to specific scenarios such as media, finance, and law, it will undoubtedly open up broader possibilities for the application of large models.
Through the API, Baichuan2-192K can effectively integrate into more vertical scenarios and deeply combine with them.
In the past, documents with a large amount of content often became mountains that were difficult to cross in our work and study.

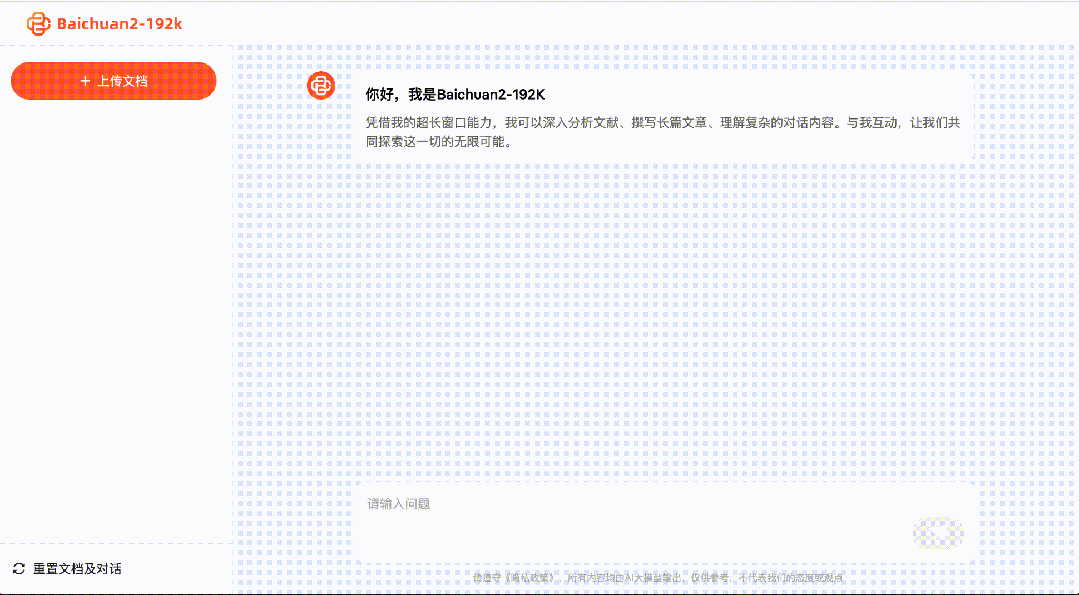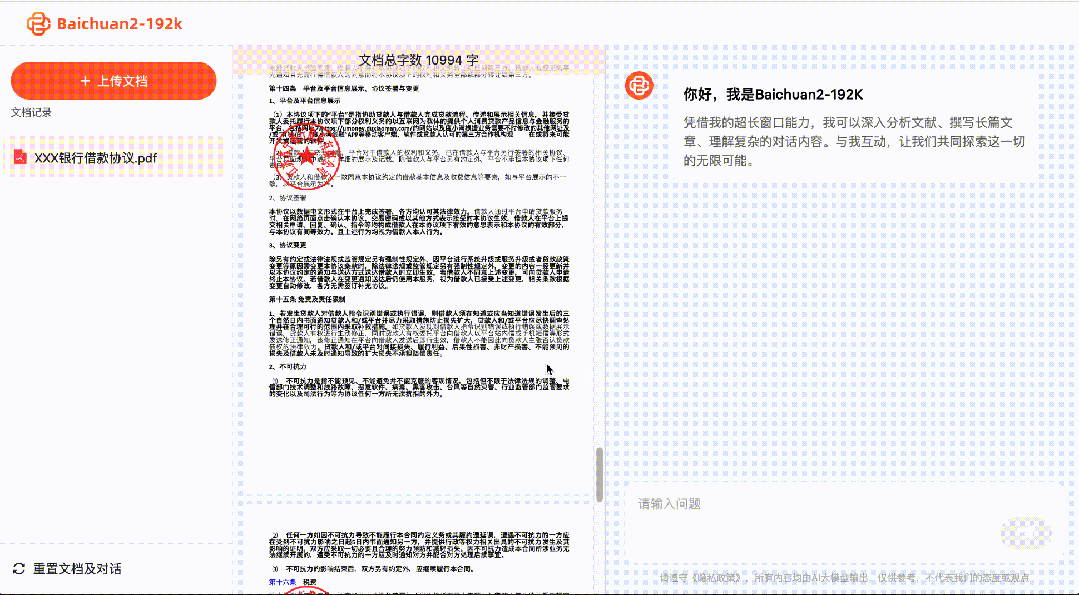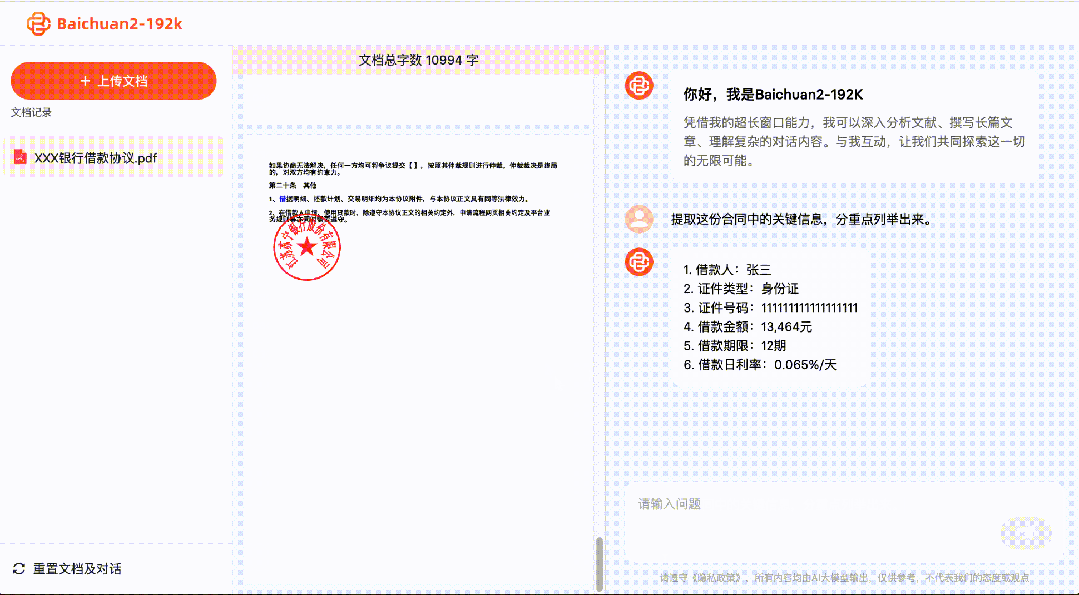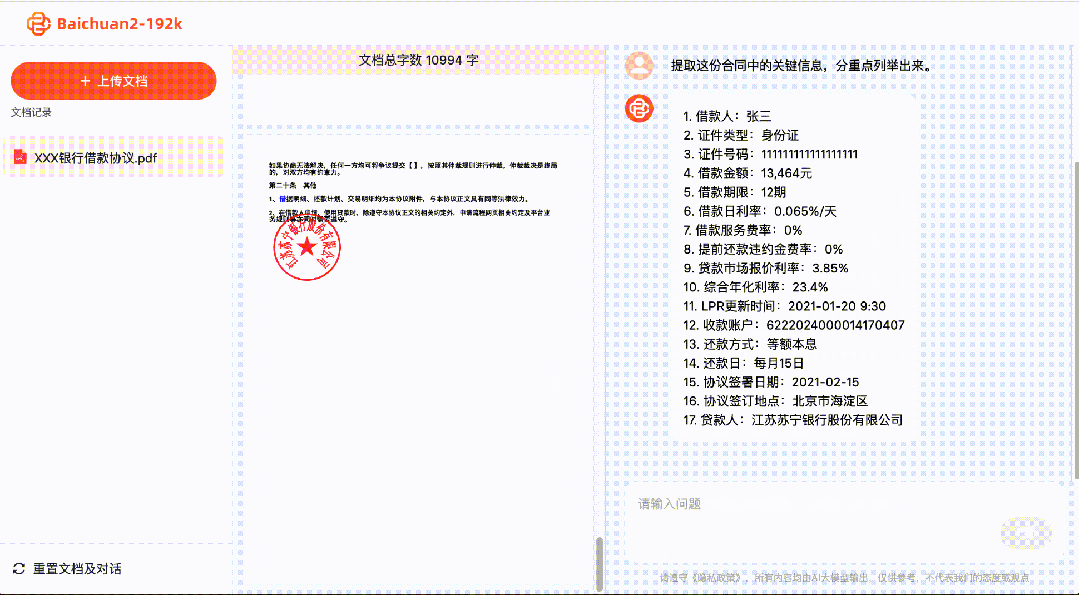
With Baichuan2-192K, it is possible to process and analyze hundreds of pages of material at once, extracting and analyzing key information.
Whether it's long document summarization/review, writing long articles or reports, or complex programming assistance, Baichuan2-192K will provide tremendous assistance.
For fund managers, it can help summarize and explain financial statements and analyze company risks and opportunities.
For lawyers, it can help identify risks in multiple legal documents, review contracts, and legal documents.
For developers, it can help read hundreds of pages of development documents and answer technical questions.
And for researchers, they now have a research tool that can quickly browse through a large number of papers and summarize the latest cutting-edge developments.
In addition, longer context also holds even greater potential.
Agent, multimodal applications, these are the current industry's cutting-edge hotspots. With the longer context capabilities of large models, they can better handle and understand complex multimodal inputs, achieving better transfer learning.
Context length, a battleground for all
It can be said that context window length is one of the core technologies of large models.
Now, many teams are starting with "long text input" to create differentiated competitive advantages for large models. If the number of parameters determines how complex calculations a large model can perform, then the context window length determines how much "memory" a large model has.
Sam Altman once said, "We thought we wanted flying cars, but what we really wanted was 32,000 tokens."

Both domestically and internationally, research and products for expanding the context window are emerging one after another.
In May of this year, GPT-4 with a 32K context sparked intense discussions.
At the time, netizens who had already unlocked this version praised GPT-4 32K as the best product manager in the world.
Soon after, the startup company Anthropic announced that Claude could support a 100K context token length, which is about 75,000 words.
In other words, it takes the average person about 5 hours to read the same amount of content, and even more time to digest, memorize, and analyze it. For Claude, it takes less than 1 minute.

In the open-source community, Meta has proposed a method that can effectively expand the context capabilities, allowing the base model's context window to reach 32,768 tokens and achieving significant performance improvements in various synthetic context detection and language modeling tasks.
The results show that a 70B parameter model has already surpassed the performance of gpt-3.5-turbo-16k in various long context tasks.

Paper link: https://arxiv.org/abs/2309.16039
The LongLoRA method proposed by researchers from the University of Hong Kong and MIT team only requires two lines of code and an 8-card A100 machine to extend the text length of a 7B model to 100k tokens and a 70B model to 32k tokens.

Paper link: https://arxiv.org/abs/2309.12307
Researchers from DeepPavlov, AIRI, and the London Institute of Mathematical Sciences have used the Recurrent Memory Transformer (RMT) method to increase the effective context length of BERT to an "unprecedented 2 million tokens" while maintaining high memory retrieval accuracy.
However, although RMT can expand the sequence length to nearly infinite without increasing memory consumption, it still has the problem of memory decay in RNN and requires longer inference time.

Paper link: https://arxiv.org/abs/2304.11062
Currently, the context window length of LLM is mainly concentrated in the range of 4,000-100,000 tokens and is still growing.
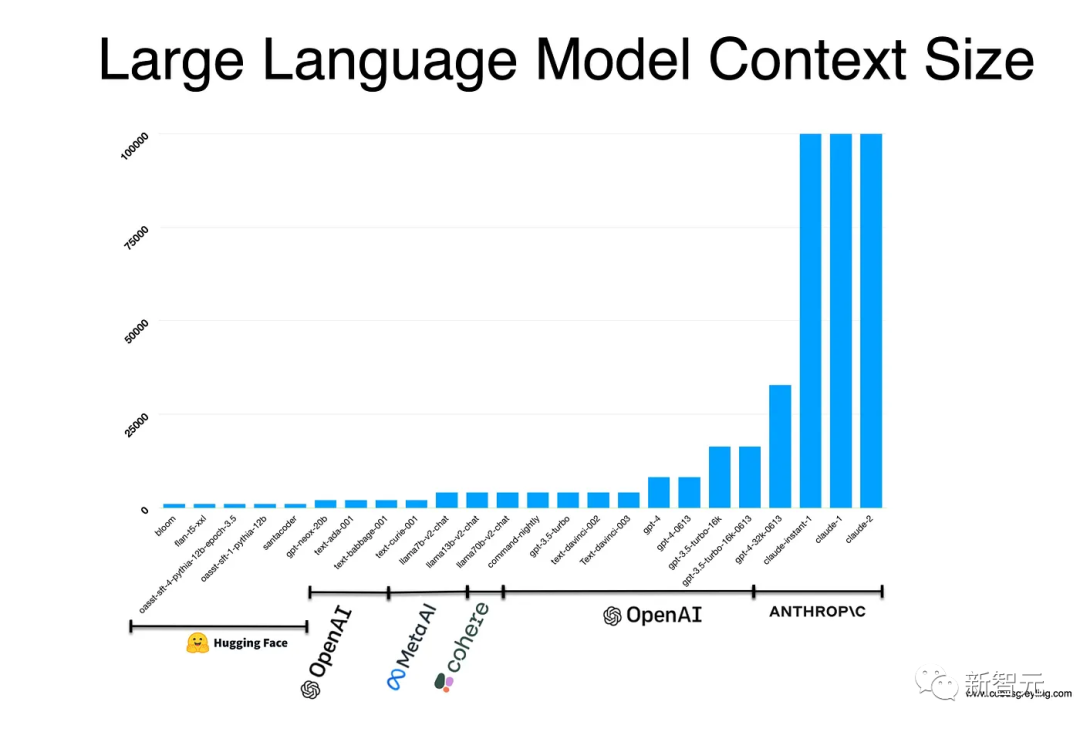
Through the multi-faceted research on the context window by the AI industry and academia, it is evident how important it is for LLM.
And this time, domestic large models have ushered in the historic highlight of the longest context window.
The 192K context window that breaks industry records not only represents another breakthrough in large model technology for Baichuan Intelligence, a star company, but also marks another milestone in the development of large models. This will undoubtedly bring about a new round of product form reform.

Established in April 2023, Baichuan Intelligence has released Baichuan-7B/13B, Baichuan2-7B/13B, four open-source large models that can be used for free, as well as Baichuan-53B and Baichuan2-53B, two closed-source large models, in just 6 months. Basically, it's an LLM update every month.
Now, with the release of Baichuan2-192K, large model long context window technology will also fully enter the Chinese era!
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








