
Blockchain oracles act as a bridge between the blockchain and the external world, allowing smart contracts to access off-chain data.
Oracles are a type of third-party service tool used to retrieve, verify external information, and transmit it to smart contracts running on the blockchain.
They do this by providing a mechanism for interacting with off-chain data to perform valuable tasks and services, thereby extending the functionality of smart contracts.
Without oracles, smart contracts would be confined to on-chain data and unable to access external information.
For a basic example: Alice and Bob bet on a horse race, and both players can lock their funds in a smart contract, which will distribute the funds to the winner based on the real-world race results.
While smart contracts cannot directly interact with the external world, a third-party oracle can retrieve the results of the race by querying a trusted API and transmit the results to the smart contract to determine the winner and allocate the funds accordingly.

Oracles serve as a bridge between the external world and the world of smart contracts.
Please note that the oracle itself is not a data source, but a tool for retrieving, verifying external data, and forwarding it to smart contracts. They can transmit various types of information, such as price data, payment confirmation, or sensor measurements.
In addition, oracles must preserve the inherent characteristics of smart contracts while transmitting this data: trustlessness and decentralization.
This is essentially the problem that oracles need to solve: ensuring the reliability, authenticity, and trustworthiness of off-chain data for smart contract services while eliminating single points of failure and vulnerabilities.
Types of Oracles
There are many types of blockchain oracles on the market, each serving different purposes.
Oracles can be classified based on the type of data source (hardware or software), the direction of information transmission (input or output), and the trust model (centralized or decentralized). Each type of oracle has unique functions and advantages.
Hardware Oracles: Collect data from the physical world, such as information from motion sensors or RFID sensors.
Software Oracles: Collect data from digital sources such as websites, servers, or databases. They are typically used to provide real-time data, such as exchange rates or price changes.
Input Oracles: Primarily transmit off-chain or real-world data to the blockchain. They can be used to trigger specific operations based on off-chain events.
Output Oracles: Send blockchain data to the external world. They can provide updates on on-chain events to external systems.
Centralized Oracles: Managed and operated by a single entity, relying on a single source of information. This may introduce risks as they introduce single points of failure, making smart contracts vulnerable to attacks.
Decentralized Oracles: Utilize multiple data sources and consensus mechanisms to provide more reliable and tamper-resistant data. They can minimize counterparty risk and increase the credibility of information used by smart contracts.
Human Oracles: Individuals with specialized knowledge act as sources of data. They can collect information, verify its validity, and feed it into smart contracts. Human oracles can use cryptographic techniques to verify their identity and provide trusted data.
Custom Smart Contract Oracles: Designed for specific smart contracts to meet their unique requirements. However, they require additional work to operate and maintain and may not have universality.
Computational Oracles: Perform complex computational operations and return the results to the blockchain. These computations are often difficult or costly to perform on-chain, making such oracles particularly valuable in networks with gas constraints and high computational costs.
Decentralized Oracles
Blockchain oracles are essential for any complex and valuable smart contract service.
The use cases of blockchain oracles span across various industries, including geolocation tracking (supply chain analytics, IoT), sports (prediction markets), weather (travel, agriculture), time and interval data (automation), and our primary focus of research - financial and capital market-related data.
Decentralized Finance (DeFi) industry is poised to bring more efficient, transparent, and fairer financial markets to the world.
To achieve this, DeFi applications need to reliably and trustlessly access a wide range of data: asset prices (from cryptocurrencies to real estate), benchmark reference data (interest rates, funding rates), volatility and market impact data, and more.
In fact, the rapid expansion of the DeFi industry since the "DeFi Summer" of 2020 has highlighted the urgent need for comprehensive, accessible, and robust oracle market data.
Furthermore, oracle infrastructure needs to provide high-quality data, seamlessly integrate with any L1/L2 blockchains, and be ready to scale according to the growing demands of the increasingly complex DeFi ecosystem.
In DeFi, price feed oracles remain the predominant and most discussed type of oracles. The history of price feed oracles is almost as long as that of smart contracts, but existing architectures still show their limitations.
In the following discussion, we will focus on several issues:
-
Why do we need blockchain and price feed oracles, and why are they important?
-
What do current oracle designs need, and are they effective?
-
What alternative design solutions can address existing issues?
It is evident that oracles will continue to play a critical role in blockchain, but existing oracle networks have shown flaws and are unable to scale DeFi to the heights it needs.
Traditional oracle solutions often rely on intermediaries (nodes) to validate and aggregate data, leading to time delays, opaque data sources, and cross-chain scalability issues due to cost.
Currently, a new oracle network architecture is emerging, focusing on a "pull" rather than "push" model and incentivizing highly trusted data owners and creators to publish their data.
Why Do We Need Price Oracles?
The primary category of this oracle is known as price feed oracles, which provide price data for assets such as cryptocurrencies, stocks, and commodities.
To illustrate their importance, let's look at a few examples:
Derivatives Protocols: Accurate asset prices must be provided to traders, and timely liquidation must occur when collateral is insufficient.
DEX Aggregators: Liquidity comes from various decentralized exchanges, meaning accurate oracle price data is needed to determine the best price and execute trades with minimal slippage.
Stablecoins: Stablecoins collateralized by cryptocurrencies require oracle data to ensure sufficient collateralization and maintain their peg to the underlying assets.
Lending Protocols: These protocols often rely on dynamic borrowing rates, which are a function of current asset prices. Delayed or inaccurate price data can harm the overall liquidity health of the protocol, especially during periods of price volatility.
We cannot rely on a single data source to provide this data, as it would create a central point of failure, contrary to the spirit of DeFi. Instead, what we need is tamper-resistant, timely data.
Easier said than done, as the importance of oracles in DeFi often makes them a prime target for attacks. However, having reliable and robust data sources is crucial for any DeFi project.
This is why oracles are often referred to as the backbone of DeFi. As the DeFi space continues to evolve and expand, the need for rapid and reliable access to attack-resistant data will become increasingly important.
Now that we have an understanding of the background of oracles, let's take a look at the existing oracle architectures.
Current State of Price Oracles
A common oracle network design is known as the "reporter oracle network," which relies on multiple independent nodes that act as intermediaries between data sources and blockchain applications (end users).
In a reporter network, intermediary nodes are responsible for fetching data from off-chain data sources (such as market data providers or public APIs) and then "last-mile" delivering that information to the final destination blockchain.
These nodes are also responsible for performing data aggregation, validation, and attestation.
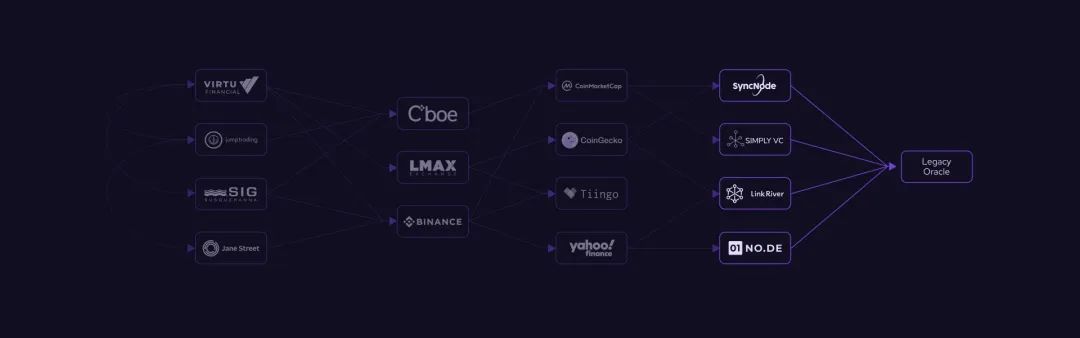
For example, let's say there are 100 nodes tasked with fetching the price of BTC at a given point in time.
They will fetch prices from various data sources (e.g., on average each node might use 30 data sources), and then aggregate the prices they fetched to output a single average or median price data.
Most nodes may end up with the correct price, while a small portion of nodes may provide incorrect price data due to using poor data sources.
Finally, the oracle network will aggregate the feedback data from the majority of nodes and publish it as the correct data.
To ensure the ongoing operation and honesty of these nodes, economic incentive mechanisms are often adopted.
Nodes that provide accurate price data can be rewarded in the form of token incentives, while nodes reporting inaccurate data may be penalized through mechanisms such as scoring deductions.
This oracle design has several key advantages:
Security: Having various data sources and intermediary nodes means that it is difficult for any party to manipulate the network and influence the final price output.
Data Sources: Wide-ranging data sources can ensure that oracles have access to a broad range of price information, typically improving accuracy and reliability.
Blockchain Agnostic: This design can be adopted by any blockchain network as they already have deployed nodes for block validation.
However, this design also has some drawbacks.
Having multiple nodes validate data, then aggregate and execute consensus on the data is inefficient. Existing oracle deployments update data approximately every 15 minutes, which is inefficient and slow for globally scalable blockchains.
If there are frequent price updates for a large number of assets, the associated network costs (e.g., ETH gas fees) will increase rapidly, leading to a decrease in the number of available asset pairs.
Without substantial gas subsidies, the issue of network congestion cannot be addressed. The increasing gas costs required to support a growing network of nodes ultimately need to be borne by users or subsidized.
This limitation makes the scalability of reporter networks very poor in supporting more data or users.
Additionally, the data sources in reporter networks are often opaque. In these networks, data is typically aggregated off-chain in an opaque manner and published on-chain in an opaque manner, contrasting with the transparency goals of blockchain.
As a result, while the entities providing the data are known, their ultimate data sources are unknown. This is particularly concerning in periods of infrequent updates or high volatility with a lack of granularity in various data sources.
In fact, upstream data sources may not even be aware that their data is being used to secure the value of smart contracts, leading to further loss of data quality and reliability.
This is not to mention the issue of data legality: some data providers do not allow their data to be reported to public ledgers as they wish to restrict the ability to distribute data to subscribers.
The design of reporter networks is specifically tailored for on-chain publicly accessible data — a solution that has played a crucial role in advancing DeFi to its current stage.
However, addressing the limitations of traditional oracle architectures is crucial as we strive to bring DeFi to billions of users worldwide.
In a previous article, we compared reporter oracle networks with newer oracle architectures, emphasizing the need for more transparent, cost-effective, and scalable oracle solutions.
Future price oracles need to be prepared to scale to all trading pairs we are accustomed to in traditional finance (TradFi) and support all blockchains that developers choose to build on.
The Pyth oracle network introduces a publisher oracle network design that rethinks the types of data price oracles should fetch, the data sources for data selection, and the relationship between data owners and data users.
Let's take a look at this new architecture.
Rethinking Price Oracles
The financial data industry is massive. The largest exchanges in the United States alone generate billions of dollars in revenue from selling market data. Given this observation, it may be wise to reconsider some of our fundamental assumptions about the sources of price oracle data.
For example, there is publicly available price data on the internet provided by free price aggregation services like Yahoo! Finance or Google Finance. This data does not need to be very granular and, for U.S. stock prices, is often delayed by 15 minutes or more due to regulatory reasons.
There is also a wealth of valuable data in the world that is tightly guarded by various institutions: accurate and timely information holds immense value. Exchange and data terminal service companies like Bloomberg or Refinitiv know this and charge substantial subscription fees for it.
The implicit assumption underlying reporter oracle networks is that all the data required by blockchains can be obtained for free on the internet. By incentivizing intermediary nodes to collect, validate, and transmit data, DeFi can track movements in global markets.
In reality, however, valuable financial data is limited to a few privileged parties and not easily accessible. Incentivizing nodes to retrieve and transmit data is effective for certain types of data, but ineffective for capital market data where speed is crucial and information is a fundamental advantage.
This approach is also impacted by the quality, efficiency, and even legal restrictions of supporting a larger node network.
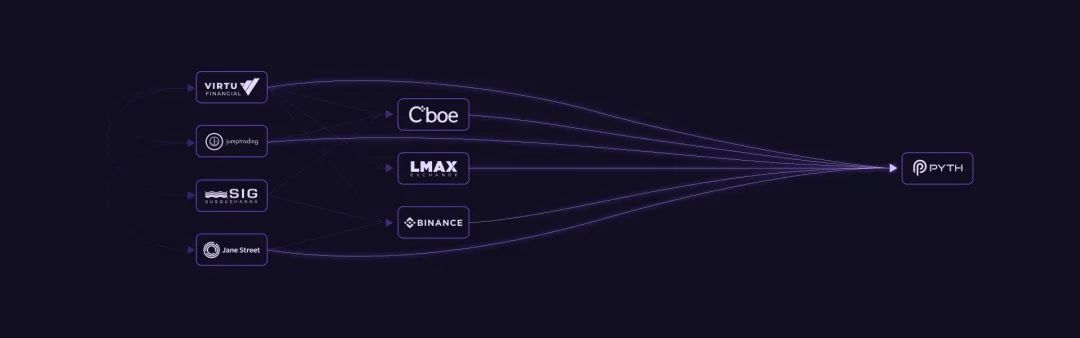
The Pyth Network takes a completely different approach: oracle networks can incentivize highly trusted parties — the owners and creators of valuable data — to voluntarily and directly publish their data to the oracle network.
On-chain programs eliminate outliers through price aggregation mechanisms, and cross-chain bridges sign and verify all price data sent to their target blockchains.
In this reporter oracle network, data providers run their own nodes and publish data directly on-chain.
This design eliminates the reliance on intermediary nodes, resulting in higher quality data and greater gas efficiency, ultimately providing higher scalability for the oracle network to expand to thousands of price feeds.
First-Hand Data Sources
Trusted institutions providing data to the Pyth Network are referred to as data providers or "publishers." Data providers are typically mature institutions with a wealth of high-quality data, including global exchanges, market makers, and trading firms.
Some of the most notable institutions include Cboe, Jane Street, Optiver, Binance, OKX, QCP Capital, Two Sigma, Wintermute, and CMS. There are currently over 80 data providers in the network.
All of these data providers are first-hand data sources: they create and therefore own the price data they provide, as they are either the trading venues accepting orders (the prices at which traders intend to trade) or the traders themselves (executing trades at specified prices).
In reporter networks, nodes must search for or purchase data from other intermediaries or first-hand data sources, making them third-party data sources.
First-hand data means a guarantee of data quality and network security. The contribution of all data providers to any Pyth price feed implies individual data sources are accountable for the quality of the data they input.
Additionally, the reputation of these data providers and the detrimental impact of malicious attacks on their entire business serve as a strong additional deterrent against traditional oracle attack vectors.It is quite obvious that the data quality held by these institutions is much higher than data obtained through simple web scraping or from public aggregators and service providers.
Furthermore, since these data sources are the owners of their data, they can distribute the data to blockchain applications without having to worry about intellectual property issues.
## In-depth Study: How Pyth Works
The Pyth Network protocol allows first-hand data providers to publish their unique price information on-chain for public use.
The protocol is an interaction between three parties:
**Data Providers**: Reputable institutions submit price data directly to Pyth's on-chain oracle program. For any price feed product (e.g., BTC/USD), there are multiple data providers publishing data to ensure accuracy and robustness.
**Pyth Oracle Program**: The Pyth oracle program runs on the Pythnet application chain. This program securely and transparently aggregates the submitted data to output aggregated prices.
**Users**: Data users of Pyth utilize the aggregated price data. Users are typically decentralized applications such as Synthetix, Ribbon, and CAP Finance.

## Pythnet Application Chain
In August 2022, Pyth Network released [Pythnet](http://mp.weixin.qq.com/s?__biz=Mzg3Mzc3ODEwMQ==&mid=2247483824&idx=1&sn=79a6a24e658cfd848ad87d6dbf205b45&chksm=cedb9f6af9ac167c5068a0df4ab9f2200d80e6a35bc6eb8e1131232a2387c0cc9c772496d211&scene=21#wechat_redirect), a blockchain tailored for applications, enabling Pyth data to be aggregated and published to other blockchains via the Wormhole cross-chain bridge.
Pythnet is built on Solana technology but eventually separates from the Solana mainnet. Data providers submit data to Pythnet for aggregation; through Wormhole, aggregated prices can be transmitted to over 20 blockchains. This architectural choice brings **incredible scalability advantages**.
New price feed data published on the Pyth Network can go live on all 20+ blockchains supported by Pyth instantly.
This is extremely helpful for builders looking to expand their applications to new blockchains, allowing them to provide instant market and asset support similar to the original blockchain.
Additionally, Pyth's unique architecture allows it to be rapidly deployed on new blockchains supported by Wormhole, at a rate of approximately one new blockchain per month.
In contrast, competitors' oracle networks often face technological delays, limiting their expansion to new blockchains. For example, it took nearly two years for an oracle network to go live on Solana from its initial announcement. The Pyth Network operates through a "pull" oracle model, where users can actively request or "pull" the data they need into their local blockchain environment from Pyth. In contrast, traditional oracle solutions use a "push" model, where price data is automatically "pushed" on-chain at a preset frequency, even if no one is actually using these price updates. The pull oracle design of Pyth has the following advantages: Gas Efficiency: Users only need to pay for data when they "have demand." Gas is not wasted on unused price updates. Additionally, if another entity pulls Pyth price data on-chain, every individual on that chain can use that price update. High-Frequency Price Updates: Pyth's price feed data updates at a rate of over once per second—faster than most block times. Achieving this frequency of price updates would be impossible if every price had to be pushed on-chain. Low Latency: Users can use the latest pulled price data without being forced to use the most recently pushed price data. Reliability: During market fluctuations, pushed price updates may compete with other transactions for blockchain network bandwidth. Pull updates from Pyth can be incorporated into users' valuable transactions. Scalability: Pyth can scale to thousands of new price feeds without increasing gas costs. Costs are only incurred when users pull data. The advantages of the pull model are numerous, but the most important point is that the pull oracle (on-demand updates) model brings the scalability advantage needed for the future of DeFi. While Pyth has proven to consistently provide high-quality data for over 20 blockchain networks, a recurring criticism suggests that the architecture described by Pyth may have issues of over-centralization due to reliance on institutional data sources. It is important to note that Pyth has a large number of data providers, meaning that the impact of any given data provider's error on any price feed data is minimal. Manipulating price feed data would require the majority of data providers to publish incorrect data. Our whitepaper discusses the network's resistance to collusion among data providers in more detail. While the reliance on "trusted" institutions by Pyth Network is a valid criticism, Pyth's approach brings significant advantages for DeFi while preventing manipulation or collusion of data sources by oracles. We will continue to drive innovation and improvement in oracle solutions in terms of performance, security, and decentralization—achieving this balance is not an easy task—and we hope to continue to lead in this regard. Price feed oracles are the backbone of DeFi, responsible for providing accurate and timely data to enable critical applications to transact, secure, and transfer assets safely and accurately. Past designs were built on the premise that it can incentivize intermediaries to collect and agree on public information in a trustless manner and submit aggregated results. This approach has its advantages, but also has some drawbacks, such as transmission delays, opaque data sources, considerations of distribution rights, and overall limitations on the scalability of the oracle network. Continuous innovation in decentralized finance (even if the public needs time to realize what the industry is creating), especially in DeFi infrastructure, has made significant progress. Pyth Network has introduced a faster, more reliable, and more secure way to access financial data that most blockchain developers cannot obtain. Pyth Network has experienced significant growth in the following areas: 250+ usable price feeds 25+ million daily price update counts $500+ billion total secured transaction volume 150+ integrated applications 20+ supported blockchains Pyth price feed data is permissionless. Developers can start integrating directly from the developer documentation and explore use cases, such as how Synthetix perpetual contracts use Pyth price data. Other notable users of Pyth include Ribbon Finance, Venus, and CAP Finance, among others. As the DeFi ecosystem continues to evolve, the role of Pyth Network in providing trusted and real-time data becomes increasingly important for ensuring the security and stability of these blockchain networks and the expansion of the entire industry. 免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。Pull, Don't Push
Further Improvement Considerations
The Path Forward








